CN114363617A - Network lightweight video stream transmission method, system and equipment - Google Patents
Network lightweight video stream transmission method, system and equipment Download PDFInfo
- Publication number
- CN114363617A CN114363617A CN202210266889.2A CN202210266889A CN114363617A CN 114363617 A CN114363617 A CN 114363617A CN 202210266889 A CN202210266889 A CN 202210266889A CN 114363617 A CN114363617 A CN 114363617A
- Authority
- CN
- China
- Prior art keywords
- video
- frame
- key
- resolution
- super
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034 method Methods 0.000 title claims abstract description 47
- 230000005540 biological transmission Effects 0.000 title claims abstract description 17
- 238000005070 sampling Methods 0.000 claims abstract description 16
- 239000013598 vector Substances 0.000 claims description 22
- 208000037170 Delayed Emergence from Anesthesia Diseases 0.000 claims description 16
- 230000008569 process Effects 0.000 claims description 16
- 230000003321 amplification Effects 0.000 claims description 7
- 238000000605 extraction Methods 0.000 claims description 7
- 230000007787 long-term memory Effects 0.000 claims description 7
- 230000015654 memory Effects 0.000 claims description 7
- 238000003199 nucleic acid amplification method Methods 0.000 claims description 7
- 230000006403 short-term memory Effects 0.000 claims description 7
- 230000006870 function Effects 0.000 claims description 6
- 230000004927 fusion Effects 0.000 claims description 6
- 230000003139 buffering effect Effects 0.000 claims description 5
- 238000004806 packaging method and process Methods 0.000 claims description 3
- 101100001673 Emericella variicolor andH gene Proteins 0.000 claims description 2
- 230000004913 activation Effects 0.000 claims description 2
- 238000004321 preservation Methods 0.000 claims description 2
- 238000006243 chemical reaction Methods 0.000 claims 1
- 230000009286 beneficial effect Effects 0.000 abstract 1
- 230000008859 change Effects 0.000 description 5
- 238000013135 deep learning Methods 0.000 description 4
- 238000004364 calculation method Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 206010035664 Pneumonia Diseases 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 238000013527 convolutional neural network Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 230000008092 positive effect Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 230000017105 transposition Effects 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images


Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
- H04N19/137—Motion inside a coding unit, e.g. average field, frame or block difference
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
- H04N19/137—Motion inside a coding unit, e.g. average field, frame or block difference
- H04N19/139—Analysis of motion vectors, e.g. their magnitude, direction, variance or reliability
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/42—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/70—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by syntax aspects related to video coding, e.g. related to compression standards
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
The invention discloses a method, a system and equipment for transmitting network lightweight video stream.A coding end carries out spatial resolution down-sampling on an original video and then codes the down-sampled video, and the method specifically comprises five steps of key frame judgment, video down-sampling, key frame coding, non-key frame coding and code stream multiplexing; the decoding end restores the corresponding spatial resolution of the video through super-resolution reconstruction on the decoded video, and specifically comprises three steps of code stream demultiplexing, video decoding and video super-resolution reconstruction and a video frame delay buffer area. The method judges the key frame through the inter-frame motion complexity, performs spatial sampling on the video frame through edge-retained downsampling, and reconstructs the high-resolution video frame through a video super-resolution reconstruction network. The invention basically does not sacrifice video definition, but obviously reduces the data volume of the video stream, and is beneficial to network transmission of compressed video.
Description
Technical Field
The invention belongs to the technical field of multimedia, and relates to a network video stream transmission method, a system and equipment, in particular to a network lightweight video stream transmission method, a system and equipment.
Background
The sudden new coronary pneumonia enables most countries around the world to adopt social isolation measures, and the life, work, study and social contact of people are suddenly transferred to a network space, so that the network flow is suddenly increased, and the application of remote visual office work, network lessons and the like which depend on serious videos is challenged. As society is already used to and enjoys the advantages and convenience of network space work and study, networked remote office, study, conference and social contact become a normal state in the future, and the traffic congestion caused by the long-term overloading of the network also becomes a normal state.
An effective way to improve the efficiency of video streaming is video coding. Since the 80 s, the international standards organization established a series of video coding standards, forming a hybrid coding framework of block-wise prediction plus transform. However, the compression efficiency of video coding techniques can be doubled by almost ten years, and the evolution cycle of the international video coding standard also takes ten years. For example, the entire decade has passed from the release of the h.264 standard in 2003 to the release of the h.265 standard in 2013. Therefore, the progress of the coding efficiency can not obviously keep up with the increasing trend of the video data volume, and therefore, a new solution must be found for the era of high-load network video service.
Super-Resolution (SR) refers to a technique for recovering a high-Resolution image from a low-Resolution image or a sequence of images. The current super-resolution technology of video images based on deep learning has achieved great success. 2017, seoul university in korea developed an enhanced deep super-resolution network whose performance outperformed the previous SR method. In the same year, the RAISR (Rapid and Accurate Image Super-Resolution) technology proposed by google converts a low-Resolution Image into a high-Resolution Image by using machine learning, and the effect can reach or even exceed that of an original Image under the condition of saving 75% of bandwidth. In 2019, a HiSR (high-Resolution Super-Resolution) Super-Resolution technology was developed, a low-Resolution picture is converted into a high-definition picture by means of a deep learning algorithm, and an effect of quickly previewing the high-definition picture is achieved at a mobile terminal.
Disclosure of Invention
The invention aims to provide a network lightweight video stream transmission method, system and equipment based on the strong image detail reconstruction capability of a super-resolution technology. The spatial resolution of an original video frame is reduced through spatial domain down-sampling, the down-sampled video is compressed to enable the amount of compressed code fluid to be smaller, and then the original spatial resolution of the video frame is restored through super-resolution reconstruction, so that the bandwidth occupation is obviously reduced on the premise of basically not sacrificing the definition of the video.
The method adopts the technical scheme that: a network lightweight video stream transmission method comprises an encoding process and a decoding process;
the encoding process is specifically realized by the following steps:
step 1: judging key frames aiming at an input video;
inter-frame motion complexityCExceeds a preset thresholdTIf so, judging the frame as a key frame, otherwise, judging the frame as a non-key frame;
step 2: directly coding the key frame; aiming at a non-key frame, firstly carrying out down sampling, and then coding by combining a motion vector;
and step 3: packaging the compressed code streams of the key frames and the non-key frames before transmission so that a receiving end can distinguish the key frames and the non-key frames;
the decoding process is specifically realized by the following steps:
and 4, step 4: splitting the code stream of the key frame and the non-key frame;
and 5: decoding the video to obtain key frames and non-key frames;
the decoded video frames are sent to a video frame delay buffer area for buffering and are used for providing a plurality of continuous video frames required by video super-resolution reconstruction; meanwhile, the analyzed motion vector parameters are sent to a video super-resolution reconstruction network;
step 6: utilizing a video super-resolution reconstruction network to carry out video super-resolution reconstruction to obtain a super-resolution non-key frame;
and 7: and restoring and outputting the video according to the key frame obtained by decoding in the step 5 and the super-resolution non-key frame in the step 6.
The technical scheme adopted by the system of the invention is as follows: a network lightweight video stream transmission system comprises an encoding end and a decoding end;
the encoding end comprises the following modules:
the module 1 is used for judging key frames aiming at input videos;
inter-frame motion complexityCExceeds a preset thresholdTIf so, judging the frame as a key frame, otherwise, judging the frame as a non-key frame;
a module 2, configured to directly perform encoding on the key frame; aiming at a non-key frame, firstly carrying out down sampling, and then coding by combining a motion vector;
the module 3 is used for encapsulating the compressed code streams of the key frames and the non-key frames before transmission so that a receiving end can distinguish the key frames and the non-key frames;
the decoding end comprises the following modules:
the module 4 is used for splitting the code stream of the key frame and the non-key frame;
a module 5, for video decoding, obtaining key frames and non-key frames;
the decoded video frames are sent to a video frame delay buffer area for buffering and are used for providing a plurality of continuous video frames required by video super-resolution reconstruction; meanwhile, the analyzed motion vector parameters are sent to a video super-resolution reconstruction network;
the module 6 is used for carrying out super-resolution reconstruction on the video by utilizing a super-resolution reconstruction network to obtain a super-resolution non-key frame;
and the module 7 is used for recovering and outputting the video according to the key frame obtained by decoding in the module 5 and the super-resolution non-key frame in the module 6.
The technical scheme adopted by the equipment of the invention is as follows: a network lightweight video streaming device, comprising:
one or more processors;
a storage device to store one or more programs that, when executed by the one or more processors, cause the one or more processors to implement the network lightweight video streaming method.
The invention has the advantages and positive effects that:
(1) according to the invention, the original video frame is coded after being sampled according to the spatial resolution, so that the amount of compressed code streams is remarkably reduced, and the network transmission is smoother; meanwhile, the original resolution is restored by adopting super-resolution reconstruction at a decoding end, and compared with the traditional mode of direct encoding and decoding, the video quality is basically not sacrificed.
(2) The invention has the advantages that the downsampling method and the video super-resolution reconstruction network are originally designed, the designed edge-preserving downsampling strategy and the super-resolution network based on deep learning have excellent performance, and the reduction quality of the target edge and texture details is ensured from two aspects of sampling and reconstruction.
Drawings
FIG. 1 is a flow chart of a method of an embodiment of the present invention;
fig. 2 is a schematic structural diagram of a video super-resolution reconstruction network according to an embodiment of the present invention.
Detailed Description
In order to facilitate the understanding and implementation of the present invention for those of ordinary skill in the art, the present invention is further described in detail with reference to the accompanying drawings and examples, it is to be understood that the embodiments described herein are merely illustrative and explanatory of the present invention and are not restrictive thereof.
Referring to fig. 1, the method for transmitting a network lightweight video stream provided by the present invention includes an encoding process and a decoding process;
the encoding process of this embodiment is specifically implemented by the following steps:
step 1: judging key frames aiming at an input video;
inter-frame motion complexityCExceeds a preset thresholdTIf so, judging the frame as a key frame, otherwise, judging the frame as a non-key frame;
the key frame of the compressed video does not relate to inter-frame prediction, so that the accumulation of inter-frame prediction errors can be prevented, and the video decoding and restoring quality can be improved. There are generally two strategies to start key frame encoding, timing key frames and mandatory key frames for scene cuts. The timing interval for timing the key frames is typically 10 s; scene change refers to whether a video picture has a large amount of violent motion. When a scene is switched, the efficiency of inter-frame coding is not high, which is not as good as improving the fault-tolerant performance of a code stream by adopting intra-frame coding, so that key frame coding is often adopted when the scene is switched. The judgment basis of scene switching is interframe motion complexity, including motion change amplitude and content change strength, wherein the motion change amplitude is measured based on an accumulated motion vector, and the content change strength is measured through accumulated frame difference. To this end, inter-frame motion complexityCThe calculation is as follows:

wherein,Nthe number of macroblocks of size 16 x 16 pixels,xMV i 、yMV i respectively representing horizontal and vertical motion vectors of the macroblock,SAD i represents the inter-frame motion estimation error of the macroblock, is a predetermined weight.
is a predetermined weight.
The motion vector and the inter-frame error of the macro block are obtained by the existing motion estimation algorithm. Motion vectors are also used in non-key frame coding, while motion vectors are provided to non-key frame coding operations to avoid the computational cost of unnecessarily repeating motion estimation.
Step 2: directly coding the key frame; aiming at a non-key frame, firstly carrying out down sampling, and then coding by combining a motion vector;
considering that the traditional down-sampling algorithm is easy to blur the edge of an object and has too much damage to the definition of a target, the embodiment adopts a down-sampling algorithm for image edge preservation.
Order tof 0, f 1, f 2, f 3Investigating pixel points for a spatially continuous group of pixelsf 0, f 1, f 2, f 3The correlation between them is divided into two groups I (a), (b), (c), (d) and (d)f 0, f 1, f 2) And II (a)f 1, f 2, f 3) The second order differences are calculated as follows:
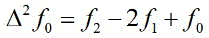

the absolute value of the second-order difference of the adjacent 3 points is used as a standard for measuring the correlation size, and the smaller the absolute value is, the larger the correlation is, and vice versa. The greater the correlation, the greater the likelihood that the pixel is in a homogeneous image region. Therefore, it is more reasonable to select the neighboring pixels with large correlation for interpolation. Based on this principle, the interpolated pixel is calculated by the following second-order interpolation formulaI:

Here, ,tfor interpolation of pixel pointsIAnd source pixel point The distance between the two is less than or equal to 1tLess than or equal to 2; first order difference
The distance between the two is less than or equal to 1tLess than or equal to 2; first order difference 。
。
In this embodiment, the key frames and the non-key frames are encoded by using a mature h.264 or h.265 encoding technique, where the key frames correspond to intra frames in the encoding standard, and the non-key frames correspond to predicted frames. The key frames are encoded with the original spatial resolution and the non-key frames are encoded with the reduced spatial resolution. The non-key frame coding module does not repeat the calculation of motion vectors, and the required motion vectors come from the key frame judgment step.
And step 3: packaging the compressed code streams of the key frames and the non-key frames before transmission so that a receiving end can distinguish the key frames and the non-key frames; in the embodiment, when the network transmission bandwidth resources are in shortage, the key frames are encapsulated preferentially.
The decoding process of this embodiment is specifically implemented by the following steps:
and 4, step 4: splitting the code stream of the key frame and the non-key frame;
the embodiment splits the code stream of the key frame and the non-key frame, so that the decoding and super-resolution reconstruction of the non-key frame can be conveniently carried out in the back, and the non-key frame is directly decoded and output.
And 5: decoding the video to obtain key frames and non-key frames;
the present embodiment performs decoding of a corresponding standard according to an encoding standard of a compressed code stream. And sending the decoded video frames into a video frame delay buffer area for buffering, and supplying a plurality of continuous video frames required by video super-resolution reconstruction. Meanwhile, the motion vector parameters analyzed by the video decoder are sent to a video super-resolution reconstruction network, so that the calculated amount is saved.
The video super-resolution reconstruction network of the embodiment is responsible for recovering the spatial resolution of the decoded non-key frames so as to make up for the loss of details caused by sampling the non-key frames by the encoding end. And reconstructing a corresponding high-resolution frame from a series of adjacent low-resolution frames by adopting a video super-resolution scheme based on deep learning.
Referring to fig. 2, the video super-resolution reconstruction network of the present embodiment includes Bicubic upsampling, a motion estimation layer, a motion compensation layer, a feature extraction layer, a multi-memory detail fusion layer, a feature reconstruction layer, a sub-pixel amplification layer, and a residual stacking operation. Firstly, converting an input low-resolution frame into compensation frames through motion estimation and motion compensation, then sequentially performing feature extraction, multi-memory detail fusion, feature reconstruction and sub-pixel amplification on the compensation frames, and finally adding up-sampled frames of Bicubic and pixel amplification results to obtain reconstructed high-resolution frames.
The motion estimation and compensation of the present embodiment is used to handle temporal correlation between successive low resolution frames. Here, new motion estimation is not performed, and motion compensation is performed directly using the motion vector obtained by decoding, thereby saving the computational overhead of complex motion estimation.
The feature extraction function of this embodiment is implemented using a residual block structure, which is composed of a series of convolution layers. The process is described as follows:

wherein,Conv n represents the second in the residual blocknA plurality of convolution layers, each of which is wound,I n andO n represents the firstnInput and output of each convolutional layer. The residual block retains information from the previous convolutional layer and passes it to all subsequent convolutional layers. The residual blocks used in feature reconstruction are also the structure of feature extraction residual blocks, but their positions in the network are different, and thus their roles are different.
The multi-memory detail fusion function of the embodiment is realized by adopting a multi-memory residual block structure, and the residual block is composed of a series of convolution long-term and short-term memory layers. When a low resolution frame passes through the residual block, the cell state of the convolution long-term and short-term memory layer retains the characteristic image information of the frame; when the next frame enters the residual block, it will receive the feature map inherited from the previous frame. In this way, the convolutional long-short term memory layer learns which part of valid information should be remembered and which invalid information should be forgotten. The process of convolving the long and short term memory layers is represented as:

wherein,i t ,f t , C t , o t andH t respectively representing an input gate, a forgetting gate, a cell state, an output gate and a hidden state;X t -representing a characteristic map, representing a hadamard product;I(⋅), F(⋅), C(. charpy) andO(. dash) represents functions of the input gate, the forgetting gate, the cell state, and the output gate, respectively, as defined by the standard long-short term memory network LSTM,tanh(dash) represents the hyperbolic tangent activation function;
a multi-memory residual block contains 3 convolutional long-short term memory layers, each layer using a convolutional kernel of size 3 x 3, but in different numbers. Since convolution of long and short term memory layers consumes large GPU memory (about 4 times that of a normal convolution layer), the input feature map is first mapped from 64 layers to 16 layers to reduce GPU memory cost and computational complexity.
In a convolutional neural network, the most common method for amplifying a feature map is convolution transposition, and Cabilllero et al propose a sub-pixel amplification method for amplifying the feature map. The present embodiment chooses sub-pixel magnification because this approach requires less computational cost and performs better in similar networks.
Step 6: utilizing a video super-resolution reconstruction network to carry out video super-resolution reconstruction to obtain a super-resolution non-key frame;
and 7: and restoring and outputting the video according to the key frame obtained by decoding in the step 5 and the super-resolution non-key frame in the step 6.
It should be understood that the above description of the preferred embodiments is given for clarity and not for any purpose of limitation, and that various changes, substitutions and alterations can be made herein without departing from the spirit and scope of the invention as defined by the appended claims.
Claims (10)
1. A network lightweight video stream transmission method is characterized by comprising an encoding process and a decoding process;
the encoding process is specifically realized by the following steps:
step 1: judging key frames aiming at an input video;
inter-frame motion complexityCExceeds a preset thresholdTIf so, judging the frame as a key frame, otherwise, judging the frame as a non-key frame;
step 2: directly coding the key frame; aiming at a non-key frame, firstly carrying out down sampling, and then coding by combining a motion vector;
and step 3: packaging the compressed code streams of the key frames and the non-key frames before transmission so that a receiving end can distinguish the key frames and the non-key frames;
the decoding process is specifically realized by the following steps:
and 4, step 4: splitting the code stream of the key frame and the non-key frame;
and 5: decoding the video to obtain key frames and non-key frames;
the decoded video frames are sent to a video frame delay buffer area for buffering and are used for providing a plurality of continuous video frames required by video super-resolution reconstruction; meanwhile, the analyzed motion vector parameters are sent to a video super-resolution reconstruction network;
step 6: utilizing a video super-resolution reconstruction network to carry out video super-resolution reconstruction to obtain a super-resolution non-key frame;
and 7: and restoring and outputting the video according to the key frame obtained by decoding in the step 5 and the super-resolution non-key frame in the step 6.
2. According toThe network lightweight video streaming method of claim 1, wherein: the inter-frame motion complexity in step 1 WhereinNthe number of macroblocks of size 16 x 16 pixels,xMV i 、yMV i respectively representing horizontal and vertical motion vectors of the macroblock,SAD i represents the inter-frame motion estimation error of the macroblock,
WhereinNthe number of macroblocks of size 16 x 16 pixels,xMV i 、yMV i respectively representing horizontal and vertical motion vectors of the macroblock,SAD i represents the inter-frame motion estimation error of the macroblock, is a predetermined weight.
is a predetermined weight.
3. The network lightweight video streaming method according to claim 1, wherein: in step 2, the non-key frame is down-sampled by using a down-sampling method for image edge preservation, and firstly, the method comprises the following steps off 0, f 1, f 2, f 3Investigating pixel points for a spatially continuous group of pixelsf 0, f 1, f 2, f 3The correlation between them is divided into two groups I (a), (b), (c), (d) and (d)f 0, f 1, f 2) And II (a)f 1, f 2, f 3) The second order differences are calculated as follows:


taking the absolute value of the second-order difference of the adjacent 3 points as a standard for measuring the correlation size, wherein the smaller the absolute value is, the larger the correlation is, and vice versa; selecting the adjacent pixel with large correlation to carry out interpolation, and calculating by the following second-order interpolation formulaInterpolation pixelI:

Here, ,tfor interpolation of pixel pointsIAnd source pixel point The distance between the two is less than or equal to 1tLess than or equal to 2; first order difference
The distance between the two is less than or equal to 1tLess than or equal to 2; first order difference 。
。
4. The network lightweight video streaming method according to claim 1, wherein: in step 2, firstly, down-sampling is carried out on non-key frames, and then coding is carried out by combining motion vectors; wherein the motion vector is from a key frame determination step.
5. The network lightweight video streaming method according to claim 1, wherein: the video super-resolution reconstruction network in the step 5 comprises Bicubic up-sampling, a motion estimation layer, a motion compensation layer, a feature extraction layer, a multi-memory detail fusion layer, a feature reconstruction layer, a sub-pixel amplification layer and residual superposition operation; firstly, converting an input low-resolution frame into compensation frames through motion estimation and motion compensation, then sequentially performing feature extraction, multi-memory detail fusion, feature reconstruction and sub-pixel amplification on the compensation frames, and finally adding up-sampled frames of Bicubic and pixel amplification results to obtain reconstructed high-resolution frames.
6. The network lightweight video streaming method according to claim 5, wherein: the conversion of the input low resolution frame into the compensation frame is to perform motion compensation directly using the motion vector obtained by decoding.
7. The network lightweight video streaming method according to claim 5, wherein: the characteristic extraction is realized by adopting a residual block structure, wherein the residual block consists of a series of convolution layers; the specific process is as follows:
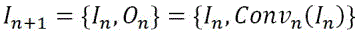
wherein,Conv n represents the second in the residual blocknA plurality of convolution layers, each of which is wound,I n andO n represents the firstnInput and output of each convolutional layer.
8. The network lightweight video streaming method according to claim 5, wherein: the multi-memory detail fusion is realized by adopting a multi-memory residual block structure, wherein the multi-memory residual block consists of a series of convolution long and short term memory layers; when a low resolution frame passes through the residual block, the cell state of the convolution long-term and short-term memory layer retains the characteristic image information of the frame; when the next frame enters the residual block, it will receive the feature map inherited from the previous frame; the process of convolving the long and short term memory layers is represented as:

wherein,i t ,f t , C t , o t andH t respectively representing an input gate, a forgetting gate, a cell state, an output gate and a hidden state;X t -representing a characteristic map, representing a hadamard product;I(⋅), F(⋅), C(. charpy) andO(. dash) represents functions of the input gate, the forgetting gate, the cell state, and the output gate, respectively, as defined by the standard long-short term memory network LSTM,tanh(dash) represents the hyperbolic tangent activation function;
a multi-memory residual block contains 3 convolutional long-short term memory layers, each layer using a convolutional kernel of size 3 x 3.
9. A network lightweight video stream transmission system is characterized by comprising an encoding end and a decoding end;
the encoding end comprises the following modules:
the module 1 is used for judging key frames aiming at input videos;
inter-frame motion complexityCExceeds a preset thresholdTIf so, judging the frame as a key frame, otherwise, judging the frame as a non-key frame;
a module 2, configured to directly perform encoding on the key frame; aiming at a non-key frame, firstly carrying out down sampling, and then coding by combining a motion vector;
the module 3 is used for encapsulating the compressed code streams of the key frames and the non-key frames before transmission so that a receiving end can distinguish the key frames and the non-key frames;
the decoding end comprises the following modules:
the module 4 is used for splitting the code stream of the key frame and the non-key frame;
a module 5, for video decoding, obtaining key frames and non-key frames;
the decoded video frames are sent to a video frame delay buffer area for buffering and are used for providing a plurality of continuous video frames required by video super-resolution reconstruction; meanwhile, the analyzed motion vector parameters are sent to a video super-resolution reconstruction network;
the module 6 is used for carrying out super-resolution reconstruction on the video by utilizing a super-resolution reconstruction network to obtain a super-resolution non-key frame;
and the module 7 is used for recovering and outputting the video according to the key frame obtained by decoding in the module 5 and the super-resolution non-key frame in the module 6.
10. A network lightweight video streaming device, comprising:
one or more processors;
storage means for storing one or more programs which, when executed by the one or more processors, cause the one or more processors to implement the network lightweight video streaming method of any of claims 1 to 8.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210266889.2A CN114363617A (en) | 2022-03-18 | 2022-03-18 | Network lightweight video stream transmission method, system and equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210266889.2A CN114363617A (en) | 2022-03-18 | 2022-03-18 | Network lightweight video stream transmission method, system and equipment |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN114363617A true CN114363617A (en) | 2022-04-15 |
Family
ID=81094906
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210266889.2A Pending CN114363617A (en) | 2022-03-18 | 2022-03-18 | Network lightweight video stream transmission method, system and equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114363617A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115361582A (en) * | 2022-07-19 | 2022-11-18 | 鹏城实验室 | Video real-time super-resolution processing method and device, terminal and storage medium |
| CN115834922A (en) * | 2022-12-20 | 2023-03-21 | 南京大学 | Picture enhancement type decoding method facing real-time video analysis |
| CN116523758A (en) * | 2023-07-03 | 2023-08-01 | 清华大学 | End cloud combined super-resolution video reconstruction method and system based on key frames |
Citations (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101710993A (en) * | 2009-11-30 | 2010-05-19 | 北京大学 | Block-based self-adaptive super-resolution video processing method and system |
| CN101938656A (en) * | 2010-09-27 | 2011-01-05 | 上海交通大学 | Video coding and decoding system based on keyframe super-resolution reconstruction |
| CN102800047A (en) * | 2012-06-20 | 2012-11-28 | 天津工业大学 | Method for reconstructing super resolution of single-frame image |
| CN103632359A (en) * | 2013-12-13 | 2014-03-12 | 清华大学深圳研究生院 | Super-resolution processing method for videos |
| CN103813174A (en) * | 2012-11-12 | 2014-05-21 | 腾讯科技(深圳)有限公司 | Mixture resolution encoding and decoding method and device |
| CN103905769A (en) * | 2012-12-26 | 2014-07-02 | 苏州赛源微电子有限公司 | Video deinterlacing algorithm without local frame buffer and solution thereof |
| US20170334066A1 (en) * | 2016-05-20 | 2017-11-23 | Google Inc. | Machine learning methods and apparatus related to predicting motion(s) of object(s) in a robot's environment based on image(s) capturing the object(s) and based on parameter(s) for future robot movement in the environment |
| CN109068134A (en) * | 2018-09-17 | 2018-12-21 | 鲍金龙 | Method for video coding and device |
| CN109118431A (en) * | 2018-09-05 | 2019-01-01 | 武汉大学 | A kind of video super-resolution method for reconstructing based on more memories and losses by mixture |
| CN110349090A (en) * | 2019-07-16 | 2019-10-18 | 合肥工业大学 | A kind of image-scaling method based on newton second order interpolation |
| CN111726614A (en) * | 2019-03-18 | 2020-09-29 | 四川大学 | HEVC (high efficiency video coding) optimization method based on spatial domain downsampling and deep learning reconstruction |
| CN113129212A (en) * | 2019-12-31 | 2021-07-16 | 深圳市联合视觉创新科技有限公司 | Image super-resolution reconstruction method and device, terminal device and storage medium |
| WO2021164176A1 (en) * | 2020-02-20 | 2021-08-26 | 北京大学 | End-to-end video compression method and system based on deep learning, and storage medium |
| CN113674151A (en) * | 2021-07-28 | 2021-11-19 | 南京航空航天大学 | Image super-resolution reconstruction method based on deep neural network |
-
2022
- 2022-03-18 CN CN202210266889.2A patent/CN114363617A/en active Pending
Patent Citations (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101710993A (en) * | 2009-11-30 | 2010-05-19 | 北京大学 | Block-based self-adaptive super-resolution video processing method and system |
| CN101938656A (en) * | 2010-09-27 | 2011-01-05 | 上海交通大学 | Video coding and decoding system based on keyframe super-resolution reconstruction |
| CN102800047A (en) * | 2012-06-20 | 2012-11-28 | 天津工业大学 | Method for reconstructing super resolution of single-frame image |
| CN103813174A (en) * | 2012-11-12 | 2014-05-21 | 腾讯科技(深圳)有限公司 | Mixture resolution encoding and decoding method and device |
| CN103905769A (en) * | 2012-12-26 | 2014-07-02 | 苏州赛源微电子有限公司 | Video deinterlacing algorithm without local frame buffer and solution thereof |
| CN103632359A (en) * | 2013-12-13 | 2014-03-12 | 清华大学深圳研究生院 | Super-resolution processing method for videos |
| US20170334066A1 (en) * | 2016-05-20 | 2017-11-23 | Google Inc. | Machine learning methods and apparatus related to predicting motion(s) of object(s) in a robot's environment based on image(s) capturing the object(s) and based on parameter(s) for future robot movement in the environment |
| CN109118431A (en) * | 2018-09-05 | 2019-01-01 | 武汉大学 | A kind of video super-resolution method for reconstructing based on more memories and losses by mixture |
| CN109068134A (en) * | 2018-09-17 | 2018-12-21 | 鲍金龙 | Method for video coding and device |
| CN111726614A (en) * | 2019-03-18 | 2020-09-29 | 四川大学 | HEVC (high efficiency video coding) optimization method based on spatial domain downsampling and deep learning reconstruction |
| CN110349090A (en) * | 2019-07-16 | 2019-10-18 | 合肥工业大学 | A kind of image-scaling method based on newton second order interpolation |
| CN113129212A (en) * | 2019-12-31 | 2021-07-16 | 深圳市联合视觉创新科技有限公司 | Image super-resolution reconstruction method and device, terminal device and storage medium |
| WO2021164176A1 (en) * | 2020-02-20 | 2021-08-26 | 北京大学 | End-to-end video compression method and system based on deep learning, and storage medium |
| CN113674151A (en) * | 2021-07-28 | 2021-11-19 | 南京航空航天大学 | Image super-resolution reconstruction method based on deep neural network |
Non-Patent Citations (2)
| Title |
|---|
| Z. WANG ET AL.: "Multi-Memory Convolutional Neural Network for Video Super-Resolution", 《IEEE TRANSACTIONS ON IMAGE PROCESSING》 * |
| 刘政林,肖建平,邹雪城,郭旭: "基于边缘的实时图像缩放算法研究", 《中国图象图形学报》 * |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115361582A (en) * | 2022-07-19 | 2022-11-18 | 鹏城实验室 | Video real-time super-resolution processing method and device, terminal and storage medium |
| CN115361582B (en) * | 2022-07-19 | 2023-04-25 | 鹏城实验室 | Video real-time super-resolution processing method, device, terminal and storage medium |
| CN115834922A (en) * | 2022-12-20 | 2023-03-21 | 南京大学 | Picture enhancement type decoding method facing real-time video analysis |
| CN116523758A (en) * | 2023-07-03 | 2023-08-01 | 清华大学 | End cloud combined super-resolution video reconstruction method and system based on key frames |
| CN116523758B (en) * | 2023-07-03 | 2023-09-19 | 清华大学 | End cloud combined super-resolution video reconstruction method and system based on key frames |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114363617A (en) | Network lightweight video stream transmission method, system and equipment | |
| CN108769682B (en) | Video encoding method, video decoding method, video encoding apparatus, video decoding apparatus, computer device, and storage medium | |
| WO2019242491A1 (en) | Video encoding and decoding method and device, computer device, and storage medium | |
| WO2019242486A1 (en) | Video encoding method, video decoding method, apparatuses, computer device, and storage medium | |
| CN101511017B (en) | Hierarchical encoder of stereo video space based on grid and decoding method thereof | |
| CN110493596B (en) | Video coding system and method based on neural network | |
| KR100913088B1 (en) | Method and apparatus for encoding/decoding video signal using prediction information of intra-mode macro blocks of base layer | |
| CN110087087A (en) | VVC interframe encode unit prediction mode shifts to an earlier date decision and block divides and shifts to an earlier date terminating method | |
| WO2022068682A1 (en) | Image processing method and apparatus | |
| WO2021036795A1 (en) | Video super-resolution processing method and device | |
| KR100703788B1 (en) | Video encoding method, video decoding method, video encoder, and video decoder, which use smoothing prediction | |
| MX2007000254A (en) | Method and apparatus for using frame rate up conversion techniques in scalable video coding. | |
| CN101860748A (en) | Side information generating system and method based on distribution type video encoding | |
| SG183888A1 (en) | Method and device for video predictive encoding | |
| CN113810763A (en) | Video processing method, device and storage medium | |
| CN117730338A (en) | Video super-resolution network and video super-resolution, encoding and decoding processing method and device | |
| WO2022067805A1 (en) | Image prediction method, encoder, decoder, and computer storage medium | |
| CN109361919A (en) | A kind of image coding efficiency method for improving combined super-resolution and remove pinch effect | |
| CN116437102B (en) | Method, system, equipment and storage medium for learning universal video coding | |
| CN111726614A (en) | HEVC (high efficiency video coding) optimization method based on spatial domain downsampling and deep learning reconstruction | |
| WO2011063747A1 (en) | Video encoding method and device, video decoding method and device | |
| JP5860337B2 (en) | Video encoding method and apparatus | |
| CN114202463B (en) | Cloud fusion-oriented video super-resolution method and system | |
| CN112929629B (en) | Intelligent virtual reference frame generation method | |
| CN112601095A (en) | Method and system for creating fractional interpolation model of video brightness and chrominance |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| RJ01 | Rejection of invention patent application after publication | ||
| RJ01 | Rejection of invention patent application after publication |
Application publication date: 20220415 |