CN112836506A - Information source coding and decoding method and device based on context semantics - Google Patents
Information source coding and decoding method and device based on context semantics Download PDFInfo
- Publication number
- CN112836506A CN112836506A CN202110206745.3A CN202110206745A CN112836506A CN 112836506 A CN112836506 A CN 112836506A CN 202110206745 A CN202110206745 A CN 202110206745A CN 112836506 A CN112836506 A CN 112836506A
- Authority
- CN
- China
- Prior art keywords
- leaf node
- word
- value
- obtaining
- speech
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims abstract description 66
- 238000012549 training Methods 0.000 claims abstract description 45
- 238000004590 computer program Methods 0.000 claims description 25
- 238000004422 calculation algorithm Methods 0.000 claims description 10
- 238000012545 processing Methods 0.000 claims description 10
- 238000007906 compression Methods 0.000 claims description 8
- 230000006835 compression Effects 0.000 claims description 8
- 238000003062 neural network model Methods 0.000 claims description 7
- 230000003252 repetitive effect Effects 0.000 claims description 2
- 230000008569 process Effects 0.000 abstract description 13
- 230000005540 biological transmission Effects 0.000 abstract description 9
- 230000006854 communication Effects 0.000 description 11
- 238000004891 communication Methods 0.000 description 10
- 238000012163 sequencing technique Methods 0.000 description 10
- 238000010586 diagram Methods 0.000 description 9
- 230000006870 function Effects 0.000 description 8
- 238000013528 artificial neural network Methods 0.000 description 4
- 230000004913 activation Effects 0.000 description 3
- 238000011084 recovery Methods 0.000 description 3
- 238000011478 gradient descent method Methods 0.000 description 2
- 230000001360 synchronised effect Effects 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 1
- 230000003930 cognitive ability Effects 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 210000002569 neuron Anatomy 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Data Mining & Analysis (AREA)
- Biophysics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Machine Translation (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
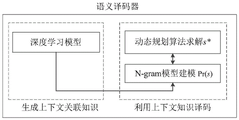
The application relates to a context semantics-based information source coding and decoding method and device. The method comprises the following steps: at the encoding end, words in the training corpus are respectively ordered according to word frequency and word classes, words with the same ordering in different word classes are combined into a leaf node, the weight value of the leaf node is obtained according to the sum of the word frequency of all the words in the leaf node, an optimal binary tree model is generated, and a non-repeated prefix code is distributed to the leaf node. And obtaining the encoded data of the corpus according to the non-repeated prefix code of the leaf node. At the decoding end, a corresponding candidate word sequence set is obtained in the binary tree model according to the coded data, and a word sequence with the closest context relationship is obtained according to the context association relationship and serves as a decoding result. According to the method and the device, the semantic dimension is added in the encoding process, the optimal decoding result is obtained by utilizing the semantic association of the context during decoding, the high-efficiency semantic information expression transmission capability can be realized, and the transmission overhead is saved.
Description
Technical Field
The application relates to the technical field of intelligent body semantic communication, in particular to a method and a device for information source coding and decoding based on context semantics.
Background
With the increasing level of intelligence and external cognitive abilities of communication devices, intelligent semantic communication has become a great research trend in the field of communication. The core of semantic communication is the accurate transmission of data meaning or content communication, rather than targeting the accurate transmission of communication symbols.
At present, data to be transmitted is processed at a sending end according to the understanding and analysis of a communication purpose and a historical communication process, so that a large amount of redundant transmission is avoided at the source. And carrying out intelligent error correction and recovery on the received signal at a receiving end according to the context, the prior information, the purpose of individual communication and other knowledge. However, there are many fundamental problems to be solved in semantic communication, such as how to realize efficient semantic information expression by an efficient coding manner.
Disclosure of Invention
In view of the foregoing, it is desirable to provide a source coding method and apparatus based on context semantics.
A method for source coding and decoding based on context semantics, the method comprising:
at the encoding end:
and acquiring the word frequency value of each word in a preset training corpus.
And sequencing each word with part of speech classification in the training corpus in the part of speech according to the word frequency value to obtain the in-part-of-speech sequencing value of each word.
And classifying the words with the same rank value in each part of speech into the same leaf node, obtaining the weight value of the leaf node according to the sum of the word frequency values of the words corresponding to the leaf node, and establishing an optimal binary tree model.
And allocating non-repeated prefix codes to the leaf nodes to obtain the coded data of the linguistic data to be coded.
At the decoding end:
and obtaining a word sequence set corresponding to the coded data according to the optimal binary tree model.
And processing the word sequence set by using a preset context correlation model to obtain corresponding decoding result data.
In one embodiment, the step of sorting each word classified by part of speech in the training corpus in the part of speech according to the word frequency value to obtain the in-part-of-speech sorting value of each word includes:
and classifying the words in the training corpus according to the parts of speech to obtain corresponding part of speech classifications. Part-of-speech classifications include noun classifications, verb classifications, adjective classifications, adverb classifications, and conjunctive classifications.
And in the part-of-speech classification, obtaining corresponding word sequences according to the sequence of the word frequency values from high to low, and obtaining the in-part-of-speech ranking value of each word according to the word sequences.
In one embodiment, the method for establishing the optimal binary tree model includes:
and acquiring a first leaf node and a second leaf node with the lowest current weight value, and combining the first leaf node and the second leaf node to obtain a third leaf node.
And obtaining the weight value of the third leaf node according to the sum of the weight values of the first leaf node and the second leaf node.
In one embodiment, the method for allocating the no-repeat prefix code to the leaf node includes:
and comparing the weight values of the first leaf node and the second leaf node, and respectively obtaining the label values of the first leaf node and the second leaf node according to the comparison result.
And obtaining the non-repeated prefix code of the first leaf node according to the label value sequences of all the leaf nodes from the root node to the first leaf node in the optimal binary tree model.
In one embodiment, the method for processing the word sequence set by using the preset context correlation model to obtain the corresponding decoding result data includes:
and obtaining context semantic association characteristics among words in the training corpus.
And obtaining a word sequence with the highest joint occurrence probability value from the word sequence set according to the context semantic association characteristics to obtain corresponding decoding result data.
In one embodiment, the manner of obtaining the context and semantic association features between words in the training corpus includes:
the LSTM-based neural network model is used for learning the context semantic association characteristics among words in the training corpus.
In one embodiment, the method for obtaining the word sequence with the highest joint occurrence probability value from the word sequence set includes:
a joint probability distribution of word sequences in the set of word sequences is modeled using an N-gram model.
And when the length of the word sequence is smaller than the preset value of the context window, obtaining the word sequence with the highest joint occurrence probability value by using an enumeration method according to the N-gram model.
And when the length of the word sequence is greater than the preset value of the context window, obtaining the word sequence with the highest joint occurrence probability value by using a state compression dynamic programming algorithm according to the N-gram model.
A source coding/decoding device based on context semantics, comprising:
the encoding module is used for acquiring the word frequency value of each word in a preset training corpus, ordering each word classified by part of speech in the training corpus in the classification according to the word frequency value to obtain an ordering value in the part of speech of each word, classifying the words with the same ordering value in each part of speech into the same leaf node, obtaining the weighted value of the leaf node according to the sum of the word frequency values of the words corresponding to the leaf node, establishing an optimal binary tree model, and distributing a non-repeated prefix code to the leaf node to obtain the encoded data of the corpus to be encoded.
And the decoding module is used for obtaining a word sequence set corresponding to the encoded data according to the optimal binary tree model, and processing the word sequence set by using a preset context association model to obtain corresponding decoding result data.
A computer device comprising a memory and a processor, the memory storing a computer program, the processor implementing the following steps when executing the computer program:
at the encoding end:
and acquiring the word frequency value of each word in a preset training corpus.
And sequencing each word with part of speech classification in the training corpus in the classification according to the word frequency value to obtain the in-word sequencing value of each word.
And classifying the words with the same rank value in each part of speech into the same leaf node, obtaining the weight value of the leaf node according to the sum of the word frequency values of the words corresponding to the leaf node, and establishing an optimal binary tree model.
And allocating non-repeated prefix codes to the leaf nodes to obtain the coded data of the linguistic data to be coded.
At the decoding end:
and obtaining a word sequence set corresponding to the coded data according to the optimal binary tree model.
And processing the word sequence set by using a preset context correlation model to obtain corresponding decoding result data.
A computer-readable storage medium, on which a computer program is stored which, when executed by a processor, carries out the steps of:
at the encoding end:
and acquiring the word frequency value of each word in a preset training corpus.
And sequencing each word with part of speech classification in the training corpus in the part of speech according to the word frequency value to obtain the in-part-of-speech sequencing value of each word.
And classifying the words with the same rank value in each part of speech into the same leaf node, obtaining the weight value of the leaf node according to the sum of the word frequency values of the words corresponding to the leaf node, and establishing an optimal binary tree model.
And allocating non-repeated prefix codes to the leaf nodes to obtain the coded data of the linguistic data to be coded.
At the decoding end:
and obtaining a word sequence set corresponding to the coded data according to the optimal binary tree model.
And processing the word sequence set by using a preset context correlation model to obtain corresponding decoding result data.
Compared with the prior art, the information source coding and decoding method, the information source coding and decoding device, the computer equipment and the storage medium based on the context semantics sequence words of the training corpus in the parts of speech according to the word frequency of the words at the coding end, combine the words with the same sequence in each part of speech into a leaf node, obtain the weight value of the leaf node according to the sum of the word frequencies of all the words in the leaf node, generate the optimal binary tree model, and allocate the non-repetitive prefix code to each leaf node. Obtaining coded data of the corpus to be coded according to the non-repeated prefix code of each leaf node in the optimal binary tree model; and at the decoding end, obtaining a corresponding candidate word set in the binary tree model according to the coded data, and obtaining a corresponding result from the candidate word set as a decoding result according to the context association relation. According to the method and the device, the words are sorted, the semantic dimension is added in the coding and decoding process, the optimal decoding result is obtained by utilizing the semantic association of the context during decoding, the high-efficiency semantic information expression transmission and information recovery capability can be realized, and the transmission overhead is saved.
Drawings
FIG. 1 is a diagram illustrating the steps of a source coding method based on context semantics in one embodiment;
FIG. 2 is a schematic diagram illustrating a data processing flow at a decoding end in a context-based source coding and decoding method according to an embodiment;
FIG. 3 is a schematic diagram of an LSTM-based neural network according to an embodiment;
FIG. 4 is a schematic flow chart illustrating the calculation of word sequence joint probability values using an N-gram model in one embodiment;
fig. 5 is a performance graph of a source coding and decoding method and a Huffman coding method based on context semantics according to the present application;
fig. 6 is a performance curve diagram of a context semantics-based source coding and decoding method provided by the present application when a context window is 3;
fig. 7 is a performance curve diagram of a context semantics-based source coding and decoding method provided by the present application when a context window is 4;
fig. 8 is a performance curve diagram of a context semantics-based source coding and decoding method provided by the present application when a context window is 5;
FIG. 9 is a diagram illustrating an internal structure of a computer device according to an embodiment.
Detailed Description
In order to make the objects, technical solutions and advantages of the present application more apparent, the present application is described in further detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are merely illustrative of the present application and are not intended to limit the present application.
In one embodiment, as shown in fig. 1, a source coding and decoding method based on context semantics is provided for an encoding side and a decoding side.
The method comprises the following steps at the encoding end:
step 102, obtaining a word frequency value of each word in a preset training corpus.
And 104, sequencing each word classified by part of speech in the training corpus in the part of speech according to the word frequency value to obtain the in-part-of-speech sequencing value of each word.
Specifically, the part-of-speech classified words refer to all words in the training corpus: ( Has been divided into according to its part-of-speech tag
Has been divided into according to its part-of-speech tag The part-of-speech classification specifically includes a noun class η, a verb class v, an adjective class a, and the like. Then, the words in each part of speech classification are arranged according to the descending order of the word frequency value of the words, and the ordering value of each word in the part of speech in the corresponding part of speech classification is obtained.
The part-of-speech classification specifically includes a noun class η, a verb class v, an adjective class a, and the like. Then, the words in each part of speech classification are arranged according to the descending order of the word frequency value of the words, and the ordering value of each word in the part of speech in the corresponding part of speech classification is obtained.
And step 106, classifying the words with the same rank value in each part of speech into the same leaf node, obtaining the weight value of the leaf node according to the sum of the word frequency values of the words corresponding to the leaf node, and establishing an optimal binary tree model.
And combining the words at the same position (namely, with the same in-part word ranking value) in the word sequence collection of each part of speech classification, and classifying the words into the same leaf node. Specifically, the words with the highest word frequency value in each part-of-speech classification form a leaf node A0=(η0,v0,a0,..), the next highest of which constitutes a leaf A1=(η1,v1,a1,..), and so on to obtain M leaf nodes Ai=(ηi,vi,ai,...),i=0,...,M-1, The weight of each leaf node is the sum of the word frequency values of all words contained in that leaf node. And establishing an optimal binary tree model according to the obtained leaf nodes.
The weight of each leaf node is the sum of the word frequency values of all words contained in that leaf node. And establishing an optimal binary tree model according to the obtained leaf nodes.
Further, the method for establishing the optimal binary tree model includes: and acquiring a first leaf node and a second leaf node with the lowest current weight value, and combining the first leaf node and the second leaf node to obtain a third leaf node. And obtaining the weight value of the third leaf node according to the sum of the weight values of the first leaf node and the second leaf node.
And 108, distributing the non-repeated prefix codes to the leaf nodes to obtain the coded data of the linguistic data to be coded.
The non-repeated prefix code means that unique coded data corresponding to each leaf node can be obtained according to the non-repeated prefix code of each leaf node in the optimal binary tree model.
For example, all of the corpus will be trained The individual words are divided into parts of speech by their part-of-speech tags
The individual words are divided into parts of speech by their part-of-speech tags The major classes, namely the noun class η, the verb class v, the adjective class a, and the other classes o. Ti of noun class set in training corpusme '(appearing 1597 times), is' (appearing 10108 times) of the moving part of speech, new '(1635 times) of the adjective part of speech and the' (69968 times) of other classes respectively appear most frequently in the four classes to obtain leaf nodes A0Is { time, is, new, the }, and is weighted as the sum 83308 of the frequency sums of the four words. And analogizing in turn to obtain all leaf node nodes, combining two leaf nodes with the lowest weight to generate a new leaf node each time, obtaining the weight of the new leaf node according to the sum of the weights of the two leaf nodes, and constructing the optimal binary tree from bottom to top. Meanwhile, according to the weight values of two leaf nodes to be combined, labels '1' and '0' are respectively set for the two leaf nodes until M leaf nodes of the optimal binary tree are all allocated with code words, the code words are sequences from the root node to the labels of the leaf nodes, and the obtained codes are the non-repeated prefix codes of the leaf nodes.
The major classes, namely the noun class η, the verb class v, the adjective class a, and the other classes o. Ti of noun class set in training corpusme '(appearing 1597 times), is' (appearing 10108 times) of the moving part of speech, new '(1635 times) of the adjective part of speech and the' (69968 times) of other classes respectively appear most frequently in the four classes to obtain leaf nodes A0Is { time, is, new, the }, and is weighted as the sum 83308 of the frequency sums of the four words. And analogizing in turn to obtain all leaf node nodes, combining two leaf nodes with the lowest weight to generate a new leaf node each time, obtaining the weight of the new leaf node according to the sum of the weights of the two leaf nodes, and constructing the optimal binary tree from bottom to top. Meanwhile, according to the weight values of two leaf nodes to be combined, labels '1' and '0' are respectively set for the two leaf nodes until M leaf nodes of the optimal binary tree are all allocated with code words, the code words are sequences from the root node to the labels of the leaf nodes, and the obtained codes are the non-repeated prefix codes of the leaf nodes.
The decoding end comprises the following steps:
and step 110, obtaining a word sequence set corresponding to the encoded data according to the optimal binary tree model.
And step 112, processing the word sequence set by using a preset context correlation model to obtain corresponding decoding result data.
The decoding end receives a group of codes, and corresponding leaf nodes can be obtained in the optimal binary tree model according to the codes. Since each leaf node corresponds to a group of words, each no-repeat prefix code can result in a corresponding set of words. There is a contextual association between contextual words when expressing semantics. Therefore, the context association model can be used to obtain the highest joint probability of the simultaneous occurrence of the context words as the corresponding decoding result.
In the embodiment, the words are sorted, the semantic dimension is added in the coding and decoding process, the context semantic association is used as the prior knowledge to optimize the distribution of the code words and realize the intelligent information recovery during the decoding, the optimal decoding result is obtained from the corresponding word sequence set, the high-efficiency semantic information expression transmission capability can be realized, and the transmission overhead is saved.
In one embodiment, the method for allocating the no-repeat prefix code to the leaf node includes:
and comparing the weight values of the first leaf node and the second leaf node, and respectively obtaining the label values of the first leaf node and the second leaf node according to the comparison result.
And obtaining the non-repeated prefix code of the first leaf node according to the label value sequences of all the leaf nodes from the root node to the first leaf node in the optimal binary tree model.
Specifically, the weights of two leaf nodes to be merged are compared, the label value of the leaf node with a higher weight value is set to 1, and the label value of the leaf node with a lower weight value is set to 0. And (3) iterating the merging process until only two leaf nodes are left to be merged to form a root node, and setting label values for all leaf nodes in the optimal binary tree in the process. According to the label value sequences of all leaf nodes on the path from the root node to a certain leaf node, the non-repeated prefix code of the leaf node can be obtained. The setting mode of the label value can be adjusted according to the coding requirement, as long as the two leaf nodes needing to be combined can be distinguished.
The embodiment provides a simple non-repeated prefix code allocation mode based on the generation process of the optimal binary tree, and has the characteristics of simple coding mode and easy implementation.
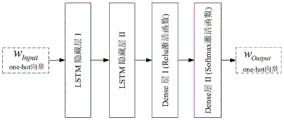
In one embodiment, as shown in fig. 2, the N-gram model and the multi-layer LSTM-based neural network model are used to characterize and learn the correlation between contexts, and a state compression dynamic programming method is used to decode a series of adjacent words as contexts together, so as to obtain a global optimal solution for a situation where one code corresponds to a plurality of words. In this embodiment, the manner of obtaining the word sequence with the highest joint occurrence probability value from the word sequence set includes:
step 202, learning context semantic association features among words in the training corpus by using an LSTM-based neural network model.
And step 204, modeling joint probability distribution of the word sequences in the word sequence set by using an N-gram model.
In particular toCorrespond to Part-of-speech classification, one no-repeat prefix code corresponds at most to
Part-of-speech classification, one no-repeat prefix code corresponds at most to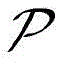 A word, so that a word sequence s of length n, at most, may have
A word, so that a word sequence s of length n, at most, may have And (5) arranging and combining. Calculating probability value P (w) of each permutation combination1,w2,...,wn). This embodiment uses the N-gram model to pair the joint probability Pr (w)1w2...wn) Modeling is carried out, wherein the process is a Markov chain Pr (w)1w2...wn)=Pr(w1)Pr(w2|w1)...Pr(wn|wn-1...w2w1) I.e. by
And (5) arranging and combining. Calculating probability value P (w) of each permutation combination1,w2,...,wn). This embodiment uses the N-gram model to pair the joint probability Pr (w)1w2...wn) Modeling is carried out, wherein the process is a Markov chain Pr (w)1w2...wn)=Pr(w1)Pr(w2|w1)...Pr(wn|wn-1...w2w1) I.e. by Where each word occurrence is associated with a previous historical character. However, as the distance between the word appearance positions increases, the correlation of the appearance probabilities of two words at farther distances gradually decreases. Thus, with the Markov assumption that each character in the word sequence is only relevant to the top N historical characters, the joint probability formulation can be reduced to
Where each word occurrence is associated with a previous historical character. However, as the distance between the word appearance positions increases, the correlation of the appearance probabilities of two words at farther distances gradually decreases. Thus, with the Markov assumption that each character in the word sequence is only relevant to the top N historical characters, the joint probability formulation can be reduced to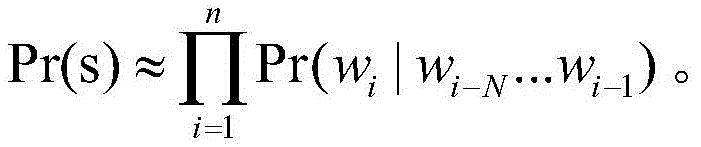
Wherein context semantics relates to characteristics Pr (w)i|wi-N...wi-1) Can be learned by the deep network. As shown in fig. 3, the present embodiment uses a multi-layer LSTM network, which includes LSTM layers I (256 nodes) and II (256 nodes), a sense layer I (256 nodes, the nonlinear activation function is Relu) and a sense layer II (the number of words in the thesaurus is the number of nodes in the layer, and the nonlinear activation function is Softmax). The multi-layer LSTM neural network inputs a one-hot vector (one-hot vector) of several surrounding words of a central word to be predictedFor "one-bit-efficient" coding, i.e. for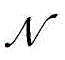 Each state is unique. At any time, only one bit is active (taking 1) and the rest take 0
Each state is unique. At any time, only one bit is active (taking 1) and the rest take 0 A dimension vector. )
A dimension vector. ) The output of the multi-layer LSTM neural network is a one-hot vector w of a prediction objective functionOnput=wi. The principle is that the central word is predicted by utilizing the front and back L context words of the central word. Minimizing the loss function of the multi-layer LSTM network in training by gradient descent method (the loss function is E ═ logPr (w)Output|wInput) The network output layer derives the probability of the core word based on the context. Multi-layer LSTM network utilizing front and back L words of the core word
The output of the multi-layer LSTM neural network is a one-hot vector w of a prediction objective functionOnput=wi. The principle is that the central word is predicted by utilizing the front and back L context words of the central word. Minimizing the loss function of the multi-layer LSTM network in training by gradient descent method (the loss function is E ═ logPr (w)Output|wInput) The network output layer derives the probability of the core word based on the context. Multi-layer LSTM network utilizing front and back L words of the core word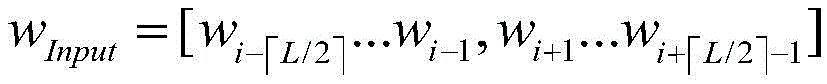 To predict the central word wOnput=wi. The activation function of the network output layer is a Softmax function, the function maps the outputs of the neurons to a (0,1) interval, and the output value is the calculated probability. The network is trained by a gradient descent method to make the loss function E of the multilayer LSTM network equal to-logPr (w)Output|wInput) And (4) minimizing.
To predict the central word wOnput=wi. The activation function of the network output layer is a Softmax function, the function maps the outputs of the neurons to a (0,1) interval, and the output value is the calculated probability. The network is trained by a gradient descent method to make the loss function E of the multilayer LSTM network equal to-logPr (w)Output|wInput) And (4) minimizing.
Step 206, as shown in fig. 4, when the length of the word sequence is smaller than the preset value of the context window, the word sequence with the highest joint occurrence probability value is obtained by using an enumeration method according to the N-gram model.
Setting the size of a context window as N, N belongs to Z+. For a word sequence of length n ═ s (w)1,w2,...,wn),n∈Z+When N is less than or equal to N, an enumeration algorithm is used Finding the S with the strongest context correlation in the permutation and combination S as the decoding result, i.e. S*=argmaxs∈SPr(s). When Pr (w)1w2...wn) When the maximum value of the probability value is P, i.e. the corresponding sequence is the decoding result, the process can be expressed as
Finding the S with the strongest context correlation in the permutation and combination S as the decoding result, i.e. S*=argmaxs∈SPr(s). When Pr (w)1w2...wn) When the maximum value of the probability value is P, i.e. the corresponding sequence is the decoding result, the process can be expressed as
Step 208, when the length N of the word sequence is greater than the preset value N of the size of the context window, according to the N-gram model, obtaining the word sequence with the highest joint occurrence probability value by using a state compression dynamic programming algorithm, wherein the state transition process can be expressed as follows:

when the length of the word sequence is larger than the preset value N & gt N of the size of the context window, a state compression dynamic programming algorithm is used for firstly solving the solution of the minimum subproblem, namely the first N word combination probability values in the word sequence, and then the scale of the subproblems is gradually increased, namely the global optimal combination of the first N +1 words is gradually considered, and the process is as follows:

by analogy, the global optimal combination of the first N +2 words until the sub-problem i considers the global optimal combination of the first i words until the global optimal solution of the sequence N words is solved, and the specific process is as follows:
(1) first all probability values for the smallest subproblem (i.e., i-N) are calculated and recorded as The probability value is calculated by the formula
The probability value is calculated by the formula
(2) When each sub-problem (i > N) is solved recursively, probability values of a plurality of optimal sub-sequences of the previous sub-problem i-1 are needed. I.e. the optimal probability value P S of the state of the ith sub-problemi(k1...kN)]Equal to selecting the word in the ith-N bit Make the optimal probability value P [ S ] of the corresponding sub-problem i-1i-1(l k1...kN-1) And by the previous N words
Make the optimal probability value P [ S ] of the corresponding sub-problem i-1i-1(l k1...kN-1) And by the previous N words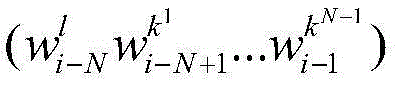 Put out the next word as
Put out the next word as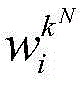 Is the maximum of the sum of the probability values, i.e. the state transition formula is
Is the maximum of the sum of the probability values, i.e. the state transition formula is

Further, word sequence joint probability formula modeling can be expressed as when Markov assumes that each character in a word sequence is relevant only to the top N historical characters The maximum probability value of the minimum sub-problem may be expressed as
The maximum probability value of the minimum sub-problem may be expressed as Maximum probability value of ith sub-problem
Maximum probability value of ith sub-problem Can be written as
Can be written as I.e., the maximum probability value of the ith sub-problem, can be decomposed into smaller sub-problems, and where the sub-problems are overlapping sub-problems, the optimal results of the sub-problems are stored in a table using a state-compressed dynamic programming algorithm,repeated computations can be avoided, reducing the time complexity of finding a globally optimal solution from a large number of potential combinations.
I.e., the maximum probability value of the ith sub-problem, can be decomposed into smaller sub-problems, and where the sub-problems are overlapping sub-problems, the optimal results of the sub-problems are stored in a table using a state-compressed dynamic programming algorithm,repeated computations can be avoided, reducing the time complexity of finding a globally optimal solution from a large number of potential combinations.
To illustrate the technical effects of the present application, the Brown word lexicon was tested based on the method provided in one of the above embodiments. The Brown word lexicon is divided into four classes according to part of speech, and specifically comprises 30632 nouns, 10392 verbs, 8054 adjectives and 4331 other classes of words. The number of encodings required is reduced from 53409 to 30632 compared to encoding each word. Fig. 5 is a performance comparison between the method of the present application and the Huffman coding method, and it can be seen that when words in the same corpus are coded, the coding method of the present application is shorter than the dynamic average code length of Huffman coding, and the difference increases with the increase of the number of characters to be coded, thereby verifying the effectiveness of the algorithm.
Fig. 6 to 8 show simulation results of the context windows of the method of the present application with lengths of 3, 4, and 5, respectively. It can be seen that the semantic similarity of the method provided by the present application can peak and remain stable when the context window size is equal to or larger than the feature window size when learning based on the LSTM neural network. As the contextual window increases, the semantic similarity score increases; as the feature window size increases, the semantic similarity score also increases.
It should be understood that, although the steps in the flowchart of fig. 1 are shown in order as indicated by the arrows, the steps are not necessarily performed in order as indicated by the arrows. The steps are not performed in the exact order shown and described, and may be performed in other orders, unless explicitly stated otherwise. Moreover, at least a portion of the steps in fig. 1 may include multiple sub-steps or multiple stages that are not necessarily performed at the same time, but may be performed at different times, and the order of performance of the sub-steps or stages is not necessarily sequential, but may be performed in turn or alternately with other steps or at least a portion of the sub-steps or stages of other steps.
In one embodiment, a source coding and decoding device based on context semantics is provided, including:
the encoding module is used for obtaining word frequency values of all words in a preset training corpus, ordering the words classified according to word characteristics in the training corpus in word classes according to the word frequency values to obtain ordering values in word classes of all the words, classifying the words with the same ordering values in the word classes into the same leaf node, obtaining a weighted value of the leaf node according to the sum of the word frequency values of the words corresponding to the leaf node, establishing an optimal binary tree model, distributing a non-repeated prefix code to the leaf node, and obtaining encoded data of a corpus to be encoded.
And the decoding module is used for obtaining a word sequence set corresponding to the encoded data according to the optimal binary tree model and obtaining corresponding decoding result data by using a preset context correlation model.
In one embodiment, the encoding module is configured to classify words in the training corpus according to parts of speech to obtain corresponding part of speech classifications. Part-of-speech classifications include noun classifications, verb classifications, adjective classifications, adverb classifications, and conjunctive classifications. And in the part-of-speech classification, obtaining the in-part-of-speech ranking value of each word according to the sequence of the word frequency values from high to low.
In one embodiment, the encoding module is configured to obtain a first leaf node and a second leaf node with a lowest current weight value, and combine the first leaf node and the second leaf node to obtain a third leaf node. And obtaining the weight value of the third leaf node according to the sum of the weight values of the first leaf node and the second leaf node.
In one embodiment, the encoding module is configured to compare the weight values of the first leaf node and the second leaf node, and obtain the tag values of the first leaf node and the second leaf node according to the comparison result. And obtaining the non-repeated prefix code of the first leaf node according to the label value sequences of all the leaf nodes from the root node to the first leaf node in the optimal binary tree model.
In one embodiment, the decoding module is configured to obtain context semantic association features between words in the training corpus. And obtaining a word sequence with the highest joint occurrence probability value according to the context semantic association characteristics to obtain corresponding decoding result data.
In one embodiment, the decoding module is configured to learn the context-semantic association features between words in the training corpus using an LSTM-based neural network model.
In one embodiment, the encoding module is configured to model a joint probability distribution of a sequence of context words using an N-gram model. And when the length of the word sequence is smaller than the preset value of the context window, obtaining the word sequence with the highest joint occurrence probability value by using an enumeration method according to the N-gram model. And when the length of the word sequence is greater than the preset value of the context window, obtaining the word sequence with the highest joint occurrence probability value by using a state compression dynamic programming algorithm according to the N-gram model.
For specific limitation of a source coding and decoding device based on context semantics, refer to the above limitation on a source coding and decoding method based on context semantics, which is not described herein again. The modules in the source coding and decoding device based on the context semantics can be wholly or partially realized by software, hardware and a combination thereof. The modules can be embedded in a hardware form or independent from a processor in the computer device, and can also be stored in a memory in the computer device in a software form, so that the processor can call and execute operations corresponding to the modules.
In one embodiment, a computer device is provided, which may be a server, and its internal structure diagram may be as shown in fig. 9. The computer device includes a processor, a memory, a network interface, and a database connected by a system bus. Wherein the processor of the computer device is configured to provide computing and control capabilities. The memory of the computer device comprises a nonvolatile storage medium and an internal memory. The non-volatile storage medium stores an operating system, a computer program, and a database. The internal memory provides an environment for the operation of an operating system and computer programs in the non-volatile storage medium. The database of the computer device is used for storing the optimal binary tree model and the context association model data. The network interface of the computer device is used for communicating with an external terminal through a network connection. The computer program is executed by a processor to implement a source coding method based on context semantics.
Those skilled in the art will appreciate that the architecture shown in fig. 9 is merely a block diagram of some of the structures associated with the disclosed aspects and is not intended to limit the computing devices to which the disclosed aspects apply, as particular computing devices may include more or less components than those shown, or may combine certain components, or have a different arrangement of components.
In one embodiment, there is provided a computer device comprising a memory storing a computer program and a processor implementing the following steps when the processor executes the computer program:
at the encoding end:
and acquiring the word frequency value of each word in a preset training corpus.
And sequencing each word with part of speech classification in the training corpus in the part of speech according to the word frequency value to obtain the in-part-of-speech sequencing value of each word.
And classifying the words with the same rank value in the part of speech into the same leaf node, obtaining the weight value of the leaf node according to the sum of the word frequency values of the words corresponding to the leaf node, and establishing an optimal binary tree model.
And allocating non-repeated prefix codes to the leaf nodes to obtain the coded data of the linguistic data to be coded.
At the decoding end:
and obtaining a candidate word set corresponding to the coded data according to the optimal binary tree model.
And obtaining corresponding decoding result data by using a preset context correlation model.
In one embodiment, the processor, when executing the computer program, further performs the steps of: and classifying the words in the training corpus according to the parts of speech to obtain corresponding part of speech classifications. Part-of-speech classifications include noun classifications, verb classifications, adjective classifications, adverb classifications, and conjunctive classifications. And in the part-of-speech classification, obtaining the in-part-of-speech ranking value of each word according to the sequence of the word frequency value from high to low.
In one embodiment, the processor, when executing the computer program, further performs the steps of: and acquiring a first leaf node and a second leaf node with the lowest current weight value, and combining the first leaf node and the second leaf node to obtain a third leaf node. And obtaining the weight value of the third leaf node according to the sum of the weight values of the first leaf node and the second leaf node.
In one embodiment, the processor, when executing the computer program, further performs the steps of: and comparing the weight values of the first leaf node and the second leaf node, and respectively obtaining the label values of the first leaf node and the second leaf node according to the comparison result. And obtaining the non-repeated prefix code of the first leaf node according to the label value sequences of all the leaf nodes from the root node to the first leaf node in the optimal binary tree model.
In one embodiment, the processor, when executing the computer program, further performs the steps of: and obtaining context semantic association characteristics among words in the training corpus. And obtaining a word sequence with the highest joint occurrence probability value according to the context semantic association characteristics to obtain corresponding decoding result data.
In one embodiment, the processor, when executing the computer program, further performs the steps of: and learning context semantic association characteristics among words in the training corpus by using an LSTM-based neural network model.
In one embodiment, the processor, when executing the computer program, further performs the steps of: the joint probability distribution of the sequence of context words is modeled using an N-gram model. And when the length of the word sequence is smaller than the preset value of the context window, obtaining the word sequence with the highest joint occurrence probability value by using an enumeration method according to the N-gram model. And when the length of the word sequence is greater than the preset value of the context window, obtaining the word sequence with the highest joint occurrence probability value by using a state compression dynamic programming algorithm according to the N-gram model.
In one embodiment, a computer-readable storage medium is provided, having a computer program stored thereon, which when executed by a processor, performs the steps of:
at the encoding end:
and acquiring the word frequency value of each word in a preset training corpus.
And ordering the words classified by parts of speech in the training corpus in the parts of speech according to the word frequency value to obtain the in-part-of-speech ordering value of each word.
And classifying the words with the same rank value in each part of speech into the same leaf node, obtaining the weight value of the leaf node according to the sum of the word frequency values of the words corresponding to the leaf node, and establishing an optimal binary tree model.
And allocating non-repeated prefix codes to the leaf nodes to obtain the coded data of the linguistic data to be coded.
At the decoding end:
and obtaining a word sequence set corresponding to the coded data according to the optimal binary tree model.
And obtaining corresponding decoding result data by using a preset context correlation model.
In one embodiment, the computer program when executed by the processor further performs the steps of: and classifying the words in the training corpus according to the parts of speech to obtain corresponding part of speech classifications. Part-of-speech classifications include noun classifications, verb classifications, adjective classifications, adverb classifications, and conjunctive classifications. And in the part-of-speech classification, obtaining corresponding word sequences according to the sequence of the word frequency values from high to low, and obtaining the in-part-of-speech ranking value of each word according to the word sequences.
In one embodiment, the computer program when executed by the processor further performs the steps of: and acquiring a first leaf node and a second leaf node with the lowest current weight value, and combining the first leaf node and the second leaf node to obtain a third leaf node. And obtaining the weight value of the third leaf node according to the sum of the weight values of the first leaf node and the second leaf node.
In one embodiment, the computer program when executed by the processor further performs the steps of: and comparing the weight values of the first leaf node and the second leaf node, and respectively obtaining the label values of the first leaf node and the second leaf node according to the comparison result. And obtaining the non-repeated prefix code of the first leaf node according to the label value sequences of all the leaf nodes from the root node to the first leaf node in the optimal binary tree model.
In one embodiment, the computer program when executed by the processor further performs the steps of: and obtaining context semantic association characteristics among words in the training corpus. And obtaining a word sequence with the highest joint occurrence probability value according to the context semantic association characteristics to obtain corresponding decoding result data.
In one embodiment, the computer program when executed by the processor further performs the steps of: the LSTM-based neural network model is used to learn the context semantic association features between the context words in the training corpus.
In one embodiment, the computer program when executed by the processor further performs the steps of: the joint probability distribution of the sequence of context words is modeled using an N-gram model. And when the length of the word sequence is smaller than a preset context window value, obtaining the context word sequence with the highest joint probability value by using an enumeration method according to the N-gram model. And when the length of the word sequence is larger than a preset value, obtaining a context word sequence with the highest joint occurrence probability value by using a state compression dynamic programming algorithm according to the N-gram model.
It will be understood by those skilled in the art that all or part of the processes of the methods of the embodiments described above can be implemented by hardware instructions of a computer program, which can be stored in a non-volatile computer-readable storage medium, and when executed, can include the processes of the embodiments of the methods described above. Any reference to memory, storage, database, or other medium used in the embodiments provided herein may include non-volatile and/or volatile memory, among others. Non-volatile memory can include read-only memory (ROM), Programmable ROM (PROM), Electrically Programmable ROM (EPROM), Electrically Erasable Programmable ROM (EEPROM), or flash memory. Volatile memory can include Random Access Memory (RAM) or external cache memory. By way of illustration and not limitation, RAM is available in a variety of forms such as Static RAM (SRAM), Dynamic RAM (DRAM), Synchronous DRAM (SDRAM), Double Data Rate SDRAM (DDRSDRAM), Enhanced SDRAM (ESDRAM), Synchronous Link DRAM (SLDRAM), Rambus Direct RAM (RDRAM), direct bus dynamic RAM (DRDRAM), and memory bus dynamic RAM (RDRAM).
The technical features of the above embodiments can be arbitrarily combined, and for the sake of brevity, all possible combinations of the technical features in the above embodiments are not described, but should be considered as the scope of the present specification as long as there is no contradiction between the combinations of the technical features.
The above-mentioned embodiments only express several embodiments of the present application, and the description thereof is more specific and detailed, but not construed as limiting the scope of the invention. It should be noted that, for a person skilled in the art, several variations and modifications can be made without departing from the concept of the present application, which falls within the scope of protection of the present application. Therefore, the protection scope of the present patent shall be subject to the appended claims.
Claims (10)
1. A method for source coding and decoding based on context semantics, the method comprising:
at the encoding end:
acquiring a word frequency value of each word in a preset training corpus;
sorting each word with part of speech classification in the training corpus according to the word frequency value to obtain a sorting value in each word;
classifying the words with the same rank value in each part of speech into the same leaf node, obtaining the weight value of the leaf node according to the sum of the word frequency values of the words corresponding to the leaf node, and establishing an optimal binary tree model;
distributing a non-repeated prefix code to the leaf node to obtain coded data of the linguistic data to be coded;
at the decoding end:
obtaining a word sequence set corresponding to the encoded data according to the optimal binary tree model;
and processing the word sequence set by using a preset context correlation model to obtain corresponding decoding result data.
2. The method according to claim 1, wherein the step of ranking each part-of-speech classified word in the training corpus according to the word frequency value within a part-of-speech to obtain a rank value within a part-of-speech of each word comprises:
classifying words in the training corpus according to parts of speech to obtain corresponding part of speech classifications; the part-of-speech classification comprises a noun classification, a verb classification, an adjective classification, an adverb classification and a conjunctive classification;
and in the part of speech classification, obtaining the in-part-of-speech ranking value of each word according to the sequence of the word frequency values from high to low.
3. The method of claim 1, wherein establishing the optimal binary tree model comprises:
acquiring a first leaf node and a second leaf node with the lowest current weight value, and combining the first leaf node and the second leaf node to obtain a third leaf node;
and obtaining the weight value of the third leaf node according to the sum of the weight values of the first leaf node and the second leaf node.
4. The method of claim 3, wherein assigning the leaf node a no-repeat prefix code comprises:
comparing the weight values of the first leaf node and the second leaf node, and respectively obtaining the label values of the first leaf node and the second leaf node according to the comparison result;
and obtaining the no-repeat prefix code of the first leaf node according to the label value sequences of all the leaf nodes experienced from the root node to the first leaf node in the optimal binary tree model.
5. The method of claim 1, wherein the obtaining the corresponding decoding result data by processing the word sequence set using a predetermined context correlation model comprises:
obtaining context semantic association characteristics among words in the training corpus;
and obtaining a word sequence with the highest joint occurrence probability value as decoding result data according to the context semantic association characteristics.
6. The method of claim 5, wherein obtaining the contextual semantic association features between words in the training corpus comprises:
and learning context semantic association features among words in the training corpus by using an LSTM-based neural network model.
7. The method of claim 6, wherein obtaining the word sequence with the highest joint occurrence probability value comprises:
modeling a joint probability distribution of word sequences in the set of word sequences using an N-gram model;
when the length of the word sequence is smaller than a preset value of a context window, obtaining the word sequence with the highest joint occurrence probability value by using an enumeration method according to the N-gram model;
and when the length of the word sequence is greater than the preset value of the context window, obtaining the word sequence with the highest joint occurrence probability value by using a state compression dynamic programming algorithm according to the N-gram model.
8. An apparatus for source coding based on context semantics, the apparatus comprising:
the encoding module is used for acquiring a word frequency value of each word in a preset training corpus, ordering each word classified by part of speech in the training corpus in a part of speech according to the word frequency value to obtain an in-part-of-speech ordering value of each word, classifying the words with equal in-part-of-speech ordering values in the same leaf node, obtaining a weight value of the leaf node according to the sum of the word frequency values of the words corresponding to the leaf node, establishing an optimal binary tree model, and distributing a non-repetitive prefix code to the leaf node to obtain encoded data of a corpus to be encoded;
and the decoding module is used for obtaining a word sequence set corresponding to the encoded data according to the optimal binary tree model, and processing the word sequence set by using a preset context association model to obtain corresponding decoding result data.
9. A computer device comprising a memory and a processor, the memory storing a computer program, wherein the processor implements the steps of the method of any one of claims 1 to 7 when executing the computer program.
10. A computer-readable storage medium, on which a computer program is stored, which, when being executed by a processor, carries out the steps of the method according to any one of claims 1 to 7.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110206745.3A CN112836506B (en) | 2021-02-24 | 2021-02-24 | Information source coding and decoding method and device based on context semantics |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110206745.3A CN112836506B (en) | 2021-02-24 | 2021-02-24 | Information source coding and decoding method and device based on context semantics |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN112836506A true CN112836506A (en) | 2021-05-25 |
| CN112836506B CN112836506B (en) | 2024-06-28 |
Family
ID=75933215
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110206745.3A Active CN112836506B (en) | 2021-02-24 | 2021-02-24 | Information source coding and decoding method and device based on context semantics |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN112836506B (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114328939A (en) * | 2022-03-17 | 2022-04-12 | 天津思睿信息技术有限公司 | Natural language processing model construction method based on big data |
| CN115146125A (en) * | 2022-05-27 | 2022-10-04 | 北京科技大学 | Receiving end data filtering method and device under semantic communication multi-address access scene |
| CN115955297A (en) * | 2023-03-14 | 2023-04-11 | 中国人民解放军国防科技大学 | Semantic coding method, semantic coding device, semantic decoding method and device |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6230168B1 (en) * | 1997-11-26 | 2001-05-08 | International Business Machines Corp. | Method for automatically constructing contexts in a hypertext collection |
| US20070061720A1 (en) * | 2005-08-29 | 2007-03-15 | Kriger Joshua K | System, device, and method for conveying information using a rapid serial presentation technique |
| CN108280064A (en) * | 2018-02-28 | 2018-07-13 | 北京理工大学 | Participle, part-of-speech tagging, Entity recognition and the combination treatment method of syntactic analysis |
| CN108733653A (en) * | 2018-05-18 | 2018-11-02 | 华中科技大学 | A kind of sentiment analysis method of the Skip-gram models based on fusion part of speech and semantic information |
| CN109376235A (en) * | 2018-07-24 | 2019-02-22 | 西安理工大学 | The feature selection approach to be reordered based on document level word frequency |
| CN109858020A (en) * | 2018-12-29 | 2019-06-07 | 航天信息股份有限公司 | A kind of method and system obtaining taxation informatization problem answers based on grapheme |
| CN111125349A (en) * | 2019-12-17 | 2020-05-08 | 辽宁大学 | Graph model text abstract generation method based on word frequency and semantics |
-
2021
- 2021-02-24 CN CN202110206745.3A patent/CN112836506B/en active Active
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6230168B1 (en) * | 1997-11-26 | 2001-05-08 | International Business Machines Corp. | Method for automatically constructing contexts in a hypertext collection |
| US20070061720A1 (en) * | 2005-08-29 | 2007-03-15 | Kriger Joshua K | System, device, and method for conveying information using a rapid serial presentation technique |
| CN108280064A (en) * | 2018-02-28 | 2018-07-13 | 北京理工大学 | Participle, part-of-speech tagging, Entity recognition and the combination treatment method of syntactic analysis |
| CN108733653A (en) * | 2018-05-18 | 2018-11-02 | 华中科技大学 | A kind of sentiment analysis method of the Skip-gram models based on fusion part of speech and semantic information |
| CN109376235A (en) * | 2018-07-24 | 2019-02-22 | 西安理工大学 | The feature selection approach to be reordered based on document level word frequency |
| CN109858020A (en) * | 2018-12-29 | 2019-06-07 | 航天信息股份有限公司 | A kind of method and system obtaining taxation informatization problem answers based on grapheme |
| CN111125349A (en) * | 2019-12-17 | 2020-05-08 | 辽宁大学 | Graph model text abstract generation method based on word frequency and semantics |
Non-Patent Citations (1)
| Title |
|---|
| 金瑜, 陆启明, 高峰: "基于上下文相关的最大概率汉语自动分词算法", 计算机工程, no. 16, 5 April 2005 (2005-04-05), pages 146 - 148 * |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114328939A (en) * | 2022-03-17 | 2022-04-12 | 天津思睿信息技术有限公司 | Natural language processing model construction method based on big data |
| CN114328939B (en) * | 2022-03-17 | 2022-05-27 | 天津思睿信息技术有限公司 | Natural language processing model construction method based on big data |
| CN115146125A (en) * | 2022-05-27 | 2022-10-04 | 北京科技大学 | Receiving end data filtering method and device under semantic communication multi-address access scene |
| CN115146125B (en) * | 2022-05-27 | 2023-02-03 | 北京科技大学 | Receiving end data filtering method and device under semantic communication multi-address access scene |
| CN115955297A (en) * | 2023-03-14 | 2023-04-11 | 中国人民解放军国防科技大学 | Semantic coding method, semantic coding device, semantic decoding method and device |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112836506B (en) | 2024-06-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11941366B2 (en) | Context-based multi-turn dialogue method and storage medium | |
| WO2021027533A1 (en) | Text semantic recognition method and apparatus, computer device, and storage medium | |
| CN112836506B (en) | Information source coding and decoding method and device based on context semantics | |
| US20200117856A1 (en) | A method and apparatus for performing hierarchiacal entity classification | |
| CN110969020A (en) | CNN and attention mechanism-based Chinese named entity identification method, system and medium | |
| CN110377916B (en) | Word prediction method, word prediction device, computer equipment and storage medium | |
| JP2020520492A (en) | Document abstract automatic extraction method, device, computer device and storage medium | |
| CN111226222A (en) | Depth context based syntax error correction using artificial neural networks | |
| US20230244704A1 (en) | Sequenced data processing method and device, and text processing method and device | |
| EP3912042B1 (en) | A deep learning model for learning program embeddings | |
| CN112101042B (en) | Text emotion recognition method, device, terminal equipment and storage medium | |
| US11481560B2 (en) | Information processing device, information processing method, and program | |
| WO2021223882A1 (en) | Prediction explanation in machine learning classifiers | |
| CN113761868A (en) | Text processing method and device, electronic equipment and readable storage medium | |
| CN114357151A (en) | Processing method, device and equipment of text category identification model and storage medium | |
| CN114528835A (en) | Semi-supervised specialized term extraction method, medium and equipment based on interval discrimination | |
| CN111737406A (en) | Text retrieval method, device and equipment and training method of text retrieval model | |
| CN115730597A (en) | Multi-level semantic intention recognition method and related equipment thereof | |
| CN111191439A (en) | Natural sentence generation method and device, computer equipment and storage medium | |
| CN112686306B (en) | ICD operation classification automatic matching method and system based on graph neural network | |
| US11941360B2 (en) | Acronym definition network | |
| Chen et al. | Improving the prediction of therapist behaviors in addiction counseling by exploiting class confusions | |
| CN112069813A (en) | Text processing method, device and equipment and computer readable storage medium | |
| CN111507108A (en) | Alias generation method and device, electronic equipment and computer readable storage medium | |
| CN113918696A (en) | Question-answer matching method, device, equipment and medium based on K-means clustering algorithm |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |