CN111931910A - Investment method and intelligent agent based on reinforcement learning and deep learning - Google Patents
Investment method and intelligent agent based on reinforcement learning and deep learning Download PDFInfo
- Publication number
- CN111931910A CN111931910A CN202010735083.4A CN202010735083A CN111931910A CN 111931910 A CN111931910 A CN 111931910A CN 202010735083 A CN202010735083 A CN 202010735083A CN 111931910 A CN111931910 A CN 111931910A
- Authority
- CN
- China
- Prior art keywords
- neural network
- layer
- dqn
- vector
- value
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034 method Methods 0.000 title claims abstract description 54
- 230000002787 reinforcement Effects 0.000 title claims abstract description 25
- 238000013135 deep learning Methods 0.000 title claims abstract description 23
- 238000013528 artificial neural network Methods 0.000 claims abstract description 126
- 230000009471 action Effects 0.000 claims abstract description 42
- 238000012549 training Methods 0.000 claims abstract description 24
- 239000013598 vector Substances 0.000 claims description 74
- 230000008569 process Effects 0.000 claims description 24
- 230000000875 corresponding effect Effects 0.000 claims description 22
- 230000006870 function Effects 0.000 claims description 22
- 239000003795 chemical substances by application Substances 0.000 claims description 19
- 210000002569 neuron Anatomy 0.000 claims description 10
- 235000004257 Cordia myxa Nutrition 0.000 claims description 9
- 244000157795 Cordia myxa Species 0.000 claims description 9
- 230000004913 activation Effects 0.000 claims description 9
- 239000011159 matrix material Substances 0.000 claims description 9
- 238000000605 extraction Methods 0.000 claims description 6
- 239000004576 sand Substances 0.000 claims description 6
- 238000013527 convolutional neural network Methods 0.000 claims description 3
- 238000012360 testing method Methods 0.000 description 6
- 238000007726 management method Methods 0.000 description 5
- 238000010586 diagram Methods 0.000 description 4
- 230000009466 transformation Effects 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- 238000013473 artificial intelligence Methods 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 238000010801 machine learning Methods 0.000 description 1
- 238000013526 transfer learning Methods 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q40/00—Finance; Insurance; Tax strategies; Processing of corporate or income taxes
- G06Q40/04—Trading; Exchange, e.g. stocks, commodities, derivatives or currency exchange
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q40/00—Finance; Insurance; Tax strategies; Processing of corporate or income taxes
- G06Q40/06—Asset management; Financial planning or analysis
Landscapes
- Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Finance (AREA)
- Accounting & Taxation (AREA)
- Development Economics (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Business, Economics & Management (AREA)
- Health & Medical Sciences (AREA)
- Technology Law (AREA)
- Strategic Management (AREA)
- Marketing (AREA)
- Economics (AREA)
- Operations Research (AREA)
- Human Resources & Organizations (AREA)
- Game Theory and Decision Science (AREA)
- Entrepreneurship & Innovation (AREA)
- Financial Or Insurance-Related Operations Such As Payment And Settlement (AREA)
Abstract
The invention discloses an investment method and an intelligent agent based on reinforcement learning and Deep learning, wherein the method comprises the steps of constructing a multilayer Deep Q-network model, except a bottom DQN neural network, the high-layer DQN neural network is used for distributing assets managed by the high-layer DQN neural network to a next-layer DQN neural network and cash, and the bottom DQN neural network is used for distributing assets managed by the low-layer DQN neural network to stocks and cash managed by the low-layer DQN neural network, so that the profit of the stocks is the highest in the next transaction period; and obtaining the asset allocation weight at the beginning of the next trading period by using the trained model, and adjusting the allocation of the assets in the stock market so as to obtain the optimal investment strategy. The scheme adopts a layered structure to carry out modeling, reduces the scale of the action space and the number of the over-parameters to a certain extent, greatly improves the exploration efficiency of the action space, simplifies the structure of the neural network, reduces the training difficulty of the neural network, enables the neural network to be effectively trained, and finds out the optimal action in each state.
Description
Technical Field
The invention relates to the technical field of deep learning and reinforcement learning in machine learning, in particular to an investment method and an intelligent agent based on reinforcement learning and deep learning.
Background
With the development of artificial intelligence technology, reinforcement learning algorithms have been applied to the financial field. Currently, the Q Learning-based reinforcement Learning Deep Q-network (DQN) model has been applied primarily to asset management by building a suitable interactive environment, such as the method shown in application No. 201810030006.1.
However, since the asset management has a huge operation space and a single DQN cannot sufficiently search for the operation space, the yield of a single DQN model is not excellent.
In the DQN model of asset management, actions are defined as assigning weights to assets determined at the beginning of each transaction period, and under this definition, a discretized action space can be obtained by specifying the minimum weight unit. However, if the minimum weight unit is too small or the number of assets is too large, the number of asset weight vectors (actions) is too large, which results in the inability of the agent to fully explore each action during the random action exploration phase and a large number of neurons at the fully connected layer of Deep Q-network. Thus, not only the search efficiency for the motion space is low, but also the training of the neural network becomes very difficult.
Therefore, if a single DQN model is used for asset management, it is usually necessary to limit the number of assets and ignore the commission to reduce the number of weight vectors. This seriously affects the application value and generalization ability of the model. Therefore, the invention provides a stock trading method and a stock trading system based on a layered Deep Q-network algorithm to be applied to a complex financial market.
Disclosure of Invention
The invention aims to solve the problems in the prior art and provide an investment method and an intelligent agent based on reinforcement learning and deep learning.
The purpose of the invention is realized by the following technical scheme:
the investment method based on reinforcement learning and deep learning comprises the following steps:
s1, constructing a multi-layer Deep Q-network model of a stock trading scene;
building an intelligent agent through a deep neural network, the intelligent agent interacting with an environment built using time series data for stock opening, closing, highest and lowest prices,
state space of Intelligent Agents SnDefining a two-dimensional array formed by the price tensor of the nth transaction period and the fund allocation proportion condition of the previous transaction period;
the action a of the intelligent agent is defined as the distribution proportion of the assets after transaction, and the size of the action space is defined as the random combination of the evenly distributed T assets and M +1 investment (including cash)
The multi-layer Deep Q-network model comprises a plurality of layers of DQN neural networks, wherein except for the bottom DQN neural network, the high-layer DQN neural network is used for distributing the assets managed by the high-layer DQN neural network to the DQN neural network and cash of the next layer, and each bottom DQN neural network is used for distributing the assets managed by the low-layer DQN neural network to the stocks and cash managed by the low-layer DQN neural network, so that the profit of the stocks in the next transaction period is the highest.
Each DQN neural network corresponds to a Markov decision process, and the action space of each Markov decision process is Or
Or The input of each DQN neural network is the price tensor of the nth transaction period, and the reward r of the Markov decision corresponding to each DQN neural network is as follows:
The input of each DQN neural network is the price tensor of the nth transaction period, and the reward r of the Markov decision corresponding to each DQN neural network is as follows:
r is the total amount of assets responsible for the asset over a transaction period/the total amount of assets responsible for the asset over the previous period;
s2, training the multi-layer Deep Q-network model to optimize parameters;
s3, loading the trained parameters of the multi-layer Deep Q-network model, receiving real-time stock price data, obtaining the asset allocation weight at the beginning of the next trading period through the model, and adjusting the allocation of assets in the stock market according to the asset allocation weight, thereby obtaining the optimal investment strategy.
Preferably, in the investment method based on reinforcement learning and deep learning, in S1, the price tensor of the nth transaction cycle is obtained by:
s11, extracting the opening, closing, highest and lowest prices of the stock to be managed in the previous N days to form four (M x N) matrixes, wherein M is the number of the stock to be managed by the Markov decision and optimized by the combination, and for the data of the non-trading days in the previous N days, the closing price, the opening price, the highest price and the lowest price are respectively filled with the corresponding indexes;
s12, dividing the four matrixes obtained in S11 by the closing price of the last trading day respectively to standardize each matrix;
s13, adopting expansion factor alpha to normalize the matrix Pt *The following operations are carried out:
Pt=α(Pt *-1);
s14, the four matrices obtained in S13 are combined into a (M, N,4) -dimensional price tensor, which is the price tensor of the nth transaction cycle.
Preferably, in the investment method based on reinforcement learning and deep learning, in S2, the training process of each layer of DQN neural network is as follows:
s21, extracting the memory batch
S22, calculating the corresponding target Q value of each memory in the batch

Wherein, indicating a state
indicating a state An estimate of the Q value for each corresponding action;
An estimate of the Q value for each corresponding action;



s23, calculating the estimated Q value corresponding to each memory in the batch

S24, obtaining a target Q value vector and an estimated Q value vector


S25, calculating a real Q value and obtaining a real Q value vector

Qreal=[Qreal(1),Qreal(2),…,Qreal(n)];
S26, for the loss function Using gradient descent to find the optimal parameter theta*Minimizing the loss function value, where θ is the estimated value Qnet QevalThe parameters of (1);
Using gradient descent to find the optimal parameter theta*Minimizing the loss function value, where θ is the estimated value Qnet QevalThe parameters of (1);
s27, assigning the optimal parameter to the target value Q network Qtarget;
And S28, repeating the steps until the loss function converges.
Preferably, in the investment method based on reinforcement learning and Deep learning, the multilayer Deep Q-network model at least includes a top DQN neural network and a bottom DQN neural network, and a final investment strategy is jointly formulated through the top DQN neural network and the bottom DQN neural network.
Preferably, in the investment method based on reinforcement learning and deep learning, in S3, the structure of the top-level DQN neural network and the process of predicting Q value thereof are as follows:
s311, receiving a price tensor of (M, N,4) dimensions;
s312, performing feature extraction on the input tensor through the two layers of convolution layers to form a (64 × M × 1) tensor, wherein M is the number of investment products;
s313, converting the (64 × M × 1) tensor obtained in S312 into one-dimensional data through the scatter layer of the convolutional neural network;
s314, inserting the asset allocation ratio after the end of the previous transaction period into the one-dimensional data obtained in S313 to form a new ((M × 64+2) × 1) vector;
s315, inserting the vector from S314 into the cash offset to form a vector of ((M × 64+3) × 1);
s316, passing the vector formed in S315 through a fully connected layer containing 2046 neurons to form a (1 x 1) state vector QsAnd a (a) 1) Motion vector Q ofaWherein
1) Motion vector Q ofaWherein The number of different actions in the action space;
The number of different actions in the action space;
s317, the 2 vectors obtained in S316 and the formula Q ═ Qs+(Qa-E[Qa]) Calculating the Q value in this state, where E [ Q ]a]The Q value of each defined action in S1 is the mean value of all values in the action vector and is continuously updated in the process of training the model;
and S318, finally, selecting the action with the maximum Q value as the asset weight vector which is initially distributed to the bottom DQN and cash in the next transaction period.
Preferably, in the investment method based on reinforcement learning and deep learning, the step 312 includes
S3121, obtaining 32 (M x 5) feature matrixes through a convolution layer with a convolution kernel scale of 1 x 3, wherein a Selu function is selected as an activation function of a neuron;
and S3122, inputting the 32 feature matrixes obtained in S3121 into a convolution layer with convolution kernel size of 1 × 5, and outputting a (64 × M × 1) tensor, wherein a Selu function is selected as an activation function of the neuron.
Preferably, in the investment method based on reinforcement learning and deep learning, the structure of the underlying DQN neural network and the process of predicting the Q value thereof are as follows:
s321, receiving a (2, N,4) dimensional or (1, N,4) dimensional price tensor;
s322, performing feature extraction on the input price tensor through two convolution layers with the same structure as the S312 to form a vector (64 x 2 x 1);
s323, inserting the asset allocation ratio after the end of the previous transaction period into the vector obtained in S322 to form a new (65 × 2 × 1) vector;
s324, enabling the vector obtained in the S323 to pass through a convolution layer with a convolution kernel of 1 x 1 and an activation function of Selu to form a vector of (128 x 2 x 1), and converting multidimensional data into one-dimensional data through a Flatten layer of a convolution neural network;
s325, inserting the vector obtained in S324 into the cash offset to form a vector of ((2 × 128+1) × 1);
s326, converting the vector obtained in S325 into a (1 x 1) state vector Q through a full-connection layer containing 2046 neuronssAnd a (a) 1) Or (a)
1) Or (a) 1) Motion vector Q ofaWherein
1) Motion vector Q ofaWherein The number of different actions in the action space is respectively;
The number of different actions in the action space is respectively;
s327, using the 2 vectors obtained in S326, according to the formula Q ═ Qs+(Qa-E[Qa]) Calculating a Q value under a specific state, and continuously updating the Q value corresponding to each defined action in S1 in the process of training the model;
and S328, finally, selecting the action with the maximum Q value as the asset weight vector which is initially allocated to the stocks and cash which are responsible for the underlying DQN in the next transaction period.
Preferably, the investment method based on reinforcement learning and Deep learning further includes S4, and the overlay training and parameter fine tuning are performed on the multi-layer Deep Q-network model periodically using different data.
And the intelligent agent comprises a multi-layer Deep Q-network model, the multi-layer Deep Q-network model comprises a multi-layer DQN neural network, the input of the DQN neural network is the price tensor of the nth transaction period, the upper-layer DQN neural network is used for distributing the managed assets to the lower-layer DQN neural network and cash except for the lower-layer DQN neural network, and each lower-layer DQN neural network is used for distributing the managed assets to the managed stocks and cash so as to enable the profit of the stocks to be the highest in the next transaction period.
The technical scheme of the invention has the advantages that:
the scheme adopts a layered structure to carry out modeling, reduces the action space scale and the number of over-parameters to a certain extent, enables the neural network to be effectively trained, finds out the optimal action in each state, greatly improves the exploration efficiency, simplifies the neural network structure and reduces the training difficulty of the neural network.
Drawings
FIG. 1 is a schematic diagram of the general architecture of the layered Deep Q-network model of the present invention;
FIG. 2 is a schematic structural diagram of a layered Deep Q-network model of the present invention comprising a two-layer DQN neural network;
FIG. 3 is a schematic diagram of the structure and operation principle of a top-level DQN neural network;
FIG. 4 is a schematic diagram of the structure and operation of the underlying DQN neural network;
fig. 5-7 are graphs comparing the results of different model tests performed on the test data sets of 2013, 2016 and 2017 in three time periods.
Detailed Description
Objects, advantages and features of the present invention will be illustrated and explained by the following non-limiting description of preferred embodiments. The embodiments are merely exemplary for applying the technical solutions of the present invention, and any technical solution formed by replacing or converting the equivalent thereof falls within the scope of the present invention claimed.
In the description of the schemes, it should be noted that the terms "center", "upper", "lower", "left", "right", "front", "rear", "vertical", "horizontal", "inner", "outer", etc., indicate orientations or positional relationships based on the orientations or positional relationships shown in the drawings, and are only for convenience of description and simplicity of description, but do not indicate or imply that the devices or elements referred to must have a particular orientation, be constructed and operated in a particular orientation, and thus, should not be construed as limiting the present invention. Furthermore, the terms "first," "second," and "third" are used for descriptive purposes only and are not to be construed as indicating or implying relative importance. In the description of the embodiment, the operator is used as a reference, and the direction close to the operator is a proximal end, and the direction away from the operator is a distal end.
The investment method based on reinforcement learning and deep learning disclosed by the invention is explained by combining the accompanying drawings, and comprises the following steps:
s1, constructing a multi-layer Deep Q-network model of a stock trading scene;
in particular, an intelligent agent is constructed through a deep neural network, and the intelligent agent and the stock are used
Opening device
And (3) interacting the environment constructed by the time sequence data of the disk, the closing of the disk, the highest price and the lowest price, generating state transition and instant return by the environment, training the deep neural network through the data of the state transition and the instant return, taking action again, and maximizing the accumulated discount instant return of taking action by the intelligent agent every time according to the process cycle.
Wherein, the state space of the intelligent agent { SnAnd defining a two-dimensional array consisting of the price tensor of the nth transaction period and the fund allocation proportion of the previous transaction period.
The price tensor of the nth transaction period is used as the input of each DQN neural network of the deep neural network, and is obtained by the following method:
s11, extracting the opening, closing, highest and lowest prices of the stock to be managed in the previous N days to form four (M x N) matrixes, wherein M is the number of the stock to be managed by the Markov decision and optimized by the combination, and for the data of the non-trading days in the previous N days, the corresponding indexes are respectively filled with the closing price, the opening price, the highest price and the lowest price of the previous trading day.
S12, the closing price of the previous trading day is divided by the four matrices obtained in S11, and each matrix is standardized.
S13, adopting expansion factor alpha to normalize the matrix Pt *The following operations are carried out:
Pt=α(Pt *-1)。
and S14, combining the four matrixes obtained in the S13 into a (M, N,4) -dimensional price tensor, namely the price tensor of the nth transaction period.
The action a of the intelligent agent is defined as the distribution proportion of the assets after transaction, and the size of the action space is defined as the random combination of the evenly distributed T assets and M +1 investment (including cash)
In order to reduce the motion space of the DQN neural network, a layered Deep Q-network model is adopted as shown in fig. 1, and the layered Deep Q-network model is a model combined by multiple agents, and is mainly characterized by having a very definite layered structure. The layered structure divides a plurality of DQN neural networks in the model into different levels (levels), the DQN neural network at the higher level distributes the held assets to the DQN neural networks at the lower level, and the DQN neural network at the last level distributes the held assets to the stocks and cash managed by the DQN neural network.
Namely, the multi-layer Deep Q-network model comprises a plurality of layers of DQN neural networks, except for the underlying DQN neural network, the upper layer of DQN neural network is used for distributing the assets managed by the upper layer to the underlying DQN neural network and cash, and the underlying each DQN neural network is used for distributing the assets managed by the lower layer of DQN neural network to the stocks and cash managed by the lower layer of DQN neural network, so that the profit of the stocks in the next trading period is the highest.
Specifically, as shown in FIG. 2, the multi-layer Deep Q-network model at least comprises
The top DQN neural network is used for distributing the assets responsible for the top DQN neural network to the next DQN neural network, and the specific structure of the top DQN neural network is shown in FIG. 3;
the underlying DQN neural network, whose role is to distribute the assets it manages (distributed by the previous DQN neural network) to the stocks and cash it manages, is shown in fig. 4.
Of course, in practical applications, due to the large number of stocks to be managed, an intermediate DQN neural network may need to be added between the top DQN neural network and the bottom DQN neural network. The number of layers of the intermediate-layer DQN neural network is designed according to the total number of stocks to be managed, and the structure and the construction method of each DQN neural network of each layer are consistent with those of the top-layer DQN neural network, which is not described herein again.
At the moment, each DQN neural network corresponds to a Markov decision process, and the action space of each Markov decision process is reduced to Or
Or
The reward r of the markov decision corresponding to each DQN neural network is as follows:
r is the total amount of assets responsible for the asset over a transaction period/the total amount of assets responsible for the asset over the previous period.
S2, training the multilayer Deep Q-network model through training set data to optimize parameters, wherein during specific training, the training process of each layer of DQN neural network is as follows:
s21, extracting the memory batch The memory batches are randomly drawn by an experience pool (experience replay).
The memory batches are randomly drawn by an experience pool (experience replay).
S22, calculating the corresponding target Q value of each memory in the batch

Wherein, indicating a state
indicating a state An estimate of the Q value for each corresponding action;
An estimate of the Q value for each corresponding action;



S23, calculating the estimated Q value corresponding to each memory in the batch

S24, obtaining a target Q value vector and an estimated Q value vector


S25, calculating a real Q value and obtaining a real Q value vector

Qreal=[Qreal(1),Qreal(2),…,Qreal(n)]。
S26, for the loss function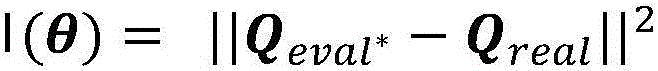 Using gradient descent to find the optimal parameter theta*Minimizing the loss function value, where θ is the estimated value Qnet QevalThe parameter (c) of (c).
Using gradient descent to find the optimal parameter theta*Minimizing the loss function value, where θ is the estimated value Qnet QevalThe parameter (c) of (c).
S27, assigning the optimal parameter to the target value Q network Qtarget。
And S28, repeating the steps until the loss function converges, wherein the specific judgment of the convergence mode can be that the convergence mode is determined according to the image of the loss function, the initial trend is obviously downward, and then the convergence mode is determined after the image is kept at a stable level.
The trained model can be directly used for stock trading, namely, corresponding fund allocation conditions are output according to different real-time stock prices.
S3, loading the trained parameters of the multi-layer Deep Q-network model, receiving real-time stock price data, obtaining the asset allocation weight at the beginning of the next trading period through the model, and adjusting the allocation of assets in the stock market according to the asset allocation weight, thereby obtaining the optimal investment strategy.
Here, for convenience of illustration, the multi-layer Deep Q-network model takes two layers as an example, which includes a top-layer DQN neural network and a bottom-layer DQN neural network, wherein the top-layer DQN neural network is responsible for deciding how to efficiently allocate the total assets to cash, the bottom-layer DQN neural network 1, and the bottom-layer DQN neural network 2; the bottom DQN neural network 1 and the bottom DQN neural network 2 are responsible for deciding how to most efficiently allocate the asset amount allocated to them by the top DQN neural network to cash and the two stocks for which the bottom DQN neural network is responsible, so that the two stocks get the highest profit for the next trading cycle. Of course, each underlying DQN neural network may also manage only one stock.
As shown in fig. 3, the process of predicting Q value by the top DQN neural network is as follows:
s311, a (M, N,4) -dimensional price tensor is received.
S312, performing feature extraction on the input tensor through the two convolution layers to form a (64 × M × 1) tensor, wherein M is the number of investment products; the method specifically comprises the following steps
S3121, obtaining 32 (M x 5) feature matrixes through a convolution layer with a convolution kernel scale of 1 x 3, wherein a Selu function is selected as an activation function of a neuron;
and S3122, inputting the 32 feature matrixes obtained in S3121 into a convolution layer with convolution kernel size of 1 × 5, and outputting a (64 × M × 1) tensor, wherein a Selu function is selected as an activation function of the neuron.
S313, the (64 × M × 1) tensor obtained in S312 is passed through the scatter layer of the convolutional neural network, and the multidimensional data is converted into one-dimensional data.
And S314, inserting the asset allocation ratio after the end of the previous transaction period into the one-dimensional data obtained in the S313 to form a new ((M × 64+2) × 1) vector.
And S315, inserting the vector obtained in the S314 into the cash offset to form a vector of (M64 +3) 1.
S316, passing the vector formed in S315 through a fully connected layer containing 2046 neurons to form a (1 x 1) state vector QsAnd a (a) 1) Motion vector Q ofaWherein
1) Motion vector Q ofaWherein The number of different movements in the movement space.
The number of different movements in the movement space.
S317, the 2 vectors obtained in S316 and the formula Q ═ Qs+(Qa-E[Qa]) Calculating the Q value in this state, where E [ Q ]a]The Q value defining the motion in each S1 is the mean of all the values in the motion vector and is continuously updated during the training of the model.
And S318, finally, selecting the action with the maximum Q value as the asset weight vector which is initially distributed to the bottom DQN and cash in the next transaction period.
As shown in fig. 4, the process of predicting Q value by the underlying DQN neural network is as follows:
s321, receiving a price tensor of (2, N,4) or (1, N,4), wherein the price tensor of (2, N,4) is received when a DQN neural network at the bottom manages two stocks; when an underlying DQN neural network manages a stock, a (1, N,4) -dimensional price tensor is received.
And S322, performing feature extraction on the input price tensor through two convolutional layers with the same structure as the S312 to form a vector (64 x 2 x 1), wherein the specific process is the same as S3121-S3122.
And S323, inserting the asset allocation ratio after the last transaction period is ended into the vector obtained in the step S322 to form a new (65 x 2 x 1) vector.
And S324, passing the vector obtained in the S323 through a convolution layer with a convolution kernel of 1 x 1 and an activation function of Selu to form a vector of (128 x 2 x 1), and converting multidimensional data into one-dimensional data through a Flatten layer of a convolution neural network.
S325, insert the vector from S324 into the cash offset to form a vector of ((2 × 128+1) × 1).
S326, converting the vector obtained in S325 into a (1 x 1) state vector Q through a full-connection layer containing 2046 neuronssAnd a (a) 1) Or (a)
1) Or (a) 1) Motion vector Q ofaWherein
1) Motion vector Q ofaWherein The number of different movements in the movement space.
The number of different movements in the movement space.
S327, using the 2 vectors obtained in S326, according to the formula Q ═ Qs+(Qa-E[Qa]) The Q value at a specific state is calculated, and the Q value corresponding to each defined action in S1 is continuously updated in the process of training the model.
And S328, finally, selecting the action with the maximum Q value as the asset weight vector which is initially allocated to the stocks and cash which are responsible for the underlying DQN in the next transaction period.
The final investment strategy is jointly established by a top-level DQN neural network and a bottom-level DQN neural network, namely, the top-level DQN is responsible for distributing the assets to the bottom-level DQN, and the bottom-level DQN is responsible for investing the distributed assets into the stock market.
After the model training is completed and before the model training is put into use, a test data set can be used for performance detection of the model, specifically, a test data set is formed by taking four stocks with low correlation as an example, and four stock codes are respectively as follows: 600260, 600261, 600262 and 600266. Specifically, time series data of four stocks are downloaded through Yahoo finance, opening, closing, highest prices and lowest prices of the selected stocks on the last N days are respectively extracted, and four 4-x-N price matrixes are formed. The resulting four sets of data were combined with non-risky assets (cash) and processed into a four 5 x N scale price matrix containing five investment products. And (4) filling the data of the non-trading days in the previous N days with indexes corresponding to the opening price, closing price, highest price and lowest price of the last trading day respectively. And the closing price of the transaction day is divided by the four matrixes respectively, so that each matrix is standardized. Thereafter, the difference between the values of the columns of the normalized matrix is made more significant by using the expansion factor α. Actually, the stock time-series data of 2013/1/14-2013/12/19, 2016/1/14-2016/12/19 and 2017/1/13-2017/12/18 are respectively set as the test data set.
The results obtained after inputting the test data set into the model (H-DQN) of the present scheme are presented in the figures 5-7 in comparison with the results of the conventional asset management methods, which involve the following conventional methods:
·Robust Median Reversion(RMR)
·Uniform Buy and Hold(BAH)
·Universal Portfolios(UP)
·Exponential Gradient(EG)
·Online Newton Step(ONS)
·Aniticor(ANTICOR)
·Passive Aggressive Mean Reversion(PAMR)
·Online Moving Average Reversion(OLMAR)
·Confidence Weighted Mean Reversion(CWMR)
·Single DQN(N-DQN)。
compared with other methods, the scheme of the scheme has the advantages that the obtained profit level is optimal, and better effects are obtained.
S4, aiming at a complex and changeable stock market, the model needs to be trained in an incremental mode, therefore, the price time sequence data with different characteristics are regularly used for carrying out superposition training and parameter fine adjustment on the multi-layer Deep Q-network model, which is also a process of transfer learning, so that the model is more perfect and robust, and the model has better expansibility and robustness, wherein the specific training process is the same as the process of S21-S28, and is not repeated herein.
The scheme further discloses an agent, which comprises the multi-layer Deep Q-network model, wherein the multi-layer Deep Q-network model comprises a multi-layer DQN neural network, the input of the DQN neural network is the price tensor of the nth transaction period, the high-layer DQN neural network is used for distributing the managed assets to the DQN neural network and cash of the next layer except the bottom DQN neural network, and each DQN neural network of the bottom layer is used for distributing the managed assets to the managed stocks and cash so that the profit of the stocks in the next transaction period is the highest. Of course, the agent also includes other common structures of various known agents, such as a data acquisition module, an actuator, and the like, which are known in the art and are not described in detail herein.
The invention has various embodiments, and all technical solutions formed by adopting equivalent transformation or equivalent transformation are within the protection scope of the invention.
Claims (9)
1. The investment method based on reinforcement learning and deep learning is characterized in that: the method comprises the following steps:
s1, constructing a multi-layer Deep Q-network model of a stock trading scene;
the multi-layer Deep Q-network model comprises a plurality of layers of DQN neural networks, the input of the DQN neural network is the price tensor of the nth trading period, except for the DQN neural network at the bottom layer, the DQN neural network at the upper layer is used for distributing the assets managed by the DQN neural network to the DQN neural network and cash at the lower layer, each DQN neural network at the bottom layer is used for distributing the assets managed by the DQN neural network to the stocks and cash managed by the DQN neural network so as to enable the profit of the stocks to be the highest in the next trading period, and each DQN neural network corresponds to a Markov decision process;
s2, training the multi-layer Deep Q-network model to optimize parameters;
s3, loading the trained parameters of the multi-layer Deep Q-network model, receiving real-time stock price data, obtaining the asset allocation weight at the beginning of the next trading period through the model, and adjusting the allocation of assets in the stock market according to the asset allocation weight, thereby obtaining the optimal investment strategy.
2. The reinforcement learning and deep learning based investment method according to claim 1, wherein: in S1, the input of each DQN neural network is a price tensor of the nth transaction period, which is obtained by the following method:
s11, extracting the opening price, closing price, highest price and lowest price of the stock to be managed in the previous N days to form four (M x N) matrixes, wherein M is the number of the stock to be managed by the Markov decision and optimized by the combination, and for the data of the non-trading days in the previous N days, filling the corresponding indexes with the opening price, closing price, highest price and lowest price of the previous trading day respectively;
s12, dividing the four matrixes obtained in S11 by the closing price of the last trading day respectively to standardize each matrix;
s13, adopting expansion factor alpha to normalize the matrix Pt *The following operations are carried out:
Pt=α(Pt *-1);
s14, the four matrices obtained in S13 are combined into a (M, N,4) -dimensional price tensor, which is the price tensor of the nth transaction cycle.
3. The reinforcement learning and deep learning based investment method according to claim 1, wherein: in S2, the training process of each layer of DQN neural network is as follows:
s21, extracting the memory batch
S22, calculating the corresponding target Q value of each memory in the batch

Wherein, indicating a state
indicating a state A Q value estimate for each corresponding action;
A Q value estimate for each corresponding action;



s23, calculating the estimated Q value corresponding to each memory in the batch

S24, obtaining a target Q value vector and an estimated Q value vector


S25, calculating a real Q value and obtaining a real Q value vector

Qreal=[Qreal(1),Qreal(2),…,Qreal(n)];
S26, for the loss function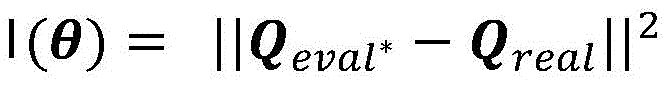 Using gradient descent to find the optimal parameter theta*Minimizing the loss function value, where θ is the estimated value Qnet QevalThe parameters of (1);
Using gradient descent to find the optimal parameter theta*Minimizing the loss function value, where θ is the estimated value Qnet QevalThe parameters of (1);
s27, assigning the optimal parameter to the target value Q network Qtarget;
And S28, repeating the steps until the loss function converges.
4. The reinforcement learning and deep learning based investment method according to any one of claims 1-3, wherein: the multilayer Deep Q-network model at least comprises a top DQN neural network and a bottom DQN neural network, and a final investment strategy is jointly formulated through the top DQN neural network and the bottom DQN neural network.
5. The reinforcement learning and deep learning based investment method of claim 4, wherein: the structure of the top-level DQN neural network and the process of predicting the Q value are as follows:
s311, receiving a price tensor of (M, N,4) dimensions;
s312, performing feature extraction on the input tensor through the two convolution layers to form a (64 × M × 1) tensor, wherein M is the number of investment products;
s313, converting the (64 × M × 1) tensor obtained in S312 into one-dimensional data through the scatter layer of the convolutional neural network;
s314, inserting the asset allocation ratio after the end of the previous transaction period into the one-dimensional data obtained in S313 to form a new ((M × 64+2) × 1) vector;
s315, inserting the vector from S314 into the cash offset to form a vector of ((M × 64+3) × 1);
s316, passing the vector formed in S315 through a fully connected layer containing 2046 neurons to form a (1 x 1) state vector QsAnd a Motion vector Q ofaWherein
Motion vector Q ofaWherein The number of different actions in the action space;
The number of different actions in the action space;
s317, the 2 vectors obtained in S316 and the formula Q ═ Qs+(Qa-E[Qa]) Calculating the Q value in this state, where E [ Q ]a]The Q value of each defined action in S1 is the mean value of all values in the action vector and is continuously updated in the process of training the model;
and S318, finally, selecting the action with the maximum Q value as the asset weight vector which is initially distributed to the bottom DQN and cash in the next transaction period.
6. The reinforcement learning and deep learning based investment method of claim 5, wherein: said 312 comprises
S3121, obtaining 32 (M x 5) feature matrixes through a convolution layer with a convolution kernel scale of 1 x 3, wherein a Selu function is selected as an activation function of a neuron;
and S3122, inputting the 32 feature matrixes obtained in S3121 into a convolution layer with convolution kernel size of 1 × 5, and outputting a (64 × M × 1) tensor, wherein the Selu function is selected as an activation function of the neuron.
7. The reinforcement learning and deep learning based investment method of claim 4, wherein: the structure of the underlying DQN neural network and the process of predicting the Q value thereof are as follows:
s321, receiving a (2, N,4) dimensional or (1, N,4) dimensional price tensor;
s322, performing feature extraction on the input price tensor through two convolution layers with the same structure as the S312 to form a vector (64 x 2 x 1);
s323, inserting the asset allocation ratio after the end of the previous transaction period into the vector obtained in S322 to form a new (65 × 2 × 1) vector;
s324, enabling the vector obtained in the S323 to pass through a convolution layer with a convolution kernel of 1 x 1 and an activation function of Selu to form a vector of (128 x 2 x 1), and converting multidimensional data into one-dimensional data through a Flatten layer of a convolution neural network;
s325, inserting the vector obtained in S324 into the cash offset to form a vector of ((2 × 128+1) × 1);
s326, converting the vector obtained in S325 into a (1 x 1) state vector Q through a full-connection layer containing 2046 neuronssAnd a Or
Or Motion vector Q ofaWherein
Motion vector Q ofaWherein The number of different actions in the action space is respectively;
The number of different actions in the action space is respectively;
s327, using the 2 vectors obtained in S326, according to the formula Q ═ Qs+(Qa-E[Qa]) Calculating a Q value under a specific state, and continuously updating the Q value corresponding to each defined action in S1 in the process of training the model;
and S328, finally, selecting the action with the maximum Q value as the asset weight vector which is initially allocated to the stocks and cash which are responsible for the underlying DQN in the next transaction period.
8. The reinforcement learning and deep learning based investment method according to claim 1, wherein: and S4, performing overlay training and parameter fine adjustment on the multi-layer Deep Q-network model by using different data regularly.
9. The intelligent agent, its characterized in that: the multi-layer Deep Q-network model comprises a multi-layer DQN neural network, the input of the DQN neural network is the price tensor of the nth transaction period, the upper-layer DQN neural network is used for distributing the assets managed by the DQN neural network to the lower-layer DQN neural network and cash, except the lower-layer DQN neural network, and each lower-layer DQN neural network is used for distributing the assets managed by the DQN neural network to the stocks and cash managed by the DQN neural network, so that the profit of the stocks is the highest in the next transaction period.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010735083.4A CN111931910A (en) | 2020-07-28 | 2020-07-28 | Investment method and intelligent agent based on reinforcement learning and deep learning |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010735083.4A CN111931910A (en) | 2020-07-28 | 2020-07-28 | Investment method and intelligent agent based on reinforcement learning and deep learning |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN111931910A true CN111931910A (en) | 2020-11-13 |
Family
ID=73316087
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010735083.4A Pending CN111931910A (en) | 2020-07-28 | 2020-07-28 | Investment method and intelligent agent based on reinforcement learning and deep learning |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111931910A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113211441A (en) * | 2020-11-30 | 2021-08-06 | 湖南太观科技有限公司 | Neural network training and robot control method and device |
-
2020
- 2020-07-28 CN CN202010735083.4A patent/CN111931910A/en active Pending
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113211441A (en) * | 2020-11-30 | 2021-08-06 | 湖南太观科技有限公司 | Neural network training and robot control method and device |
| CN113211441B (en) * | 2020-11-30 | 2022-09-09 | 湖南太观科技有限公司 | Neural network training and robot control method and device |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| DE69217047T2 (en) | IMPROVEMENTS IN NEURONAL NETWORKS | |
| Refenes et al. | Currency exchange rate prediction and neural network design strategies | |
| Boussabaine | The use of artificial neural networks in construction management: a review | |
| CN109697510A (en) | Method and apparatus with neural network | |
| CN106462795A (en) | Systems and methods for allocating capital to trading strategies for big data trading in financial markets | |
| Kumar et al. | Deep Learning as a Frontier of Machine Learning: A | |
| Rauf et al. | Training of artificial neural network using pso with novel initialization technique | |
| Chatterjee et al. | Artificial neural network and the financial markets: A survey | |
| Ji et al. | Forecasting wind speed time series via dendritic neural regression | |
| CN113407820A (en) | Model training method, related system and storage medium | |
| CN111931910A (en) | Investment method and intelligent agent based on reinforcement learning and deep learning | |
| Zhao et al. | Capsule networks with non-iterative cluster routing | |
| Burstein et al. | Artificial neural networks in decision support systems | |
| Yu et al. | Model-based deep reinforcement learning for financial portfolio optimization | |
| Shanmugavadivu et al. | Bio-optimization of deep learning network architectures | |
| Mahedy et al. | Utilizing neural networks for stocks prices prediction in stocks markets | |
| Shahpazov et al. | Artificial intelligence neural networks applications in forecasting financial markets and stock prices | |
| CN112950373A (en) | Investment portfolio management method based on DDPG deep reinforcement learning algorithm | |
| Pawar et al. | Portfolio Management using Deep Reinforcement Learning | |
| Maren | Introduction to neural networks | |
| Wei et al. | Research on portfolio optimization models using deep deterministic policy gradient | |
| CN114677224A (en) | Combined investment method based on deep reinforcement learning and intelligent agent | |
| CN112950374A (en) | Investment method and intelligent agent based on deep reinforcement learning and deep residual error shrinkage network | |
| KR102496501B1 (en) | A method for calculating asset allocation information using simulation data and an apparatus for calculating asset allocation information using simulation data | |
| Yang et al. | Ghost expectation point with deep reinforcement learning in financial portfolio management |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |