CN111783526B - Cross-domain pedestrian re-identification method using posture invariance and graph structure alignment - Google Patents
Cross-domain pedestrian re-identification method using posture invariance and graph structure alignment Download PDFInfo
- Publication number
- CN111783526B CN111783526B CN202010434344.9A CN202010434344A CN111783526B CN 111783526 B CN111783526 B CN 111783526B CN 202010434344 A CN202010434344 A CN 202010434344A CN 111783526 B CN111783526 B CN 111783526B
- Authority
- CN
- China
- Prior art keywords
- domain
- pedestrian
- representing
- identity
- attribute
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/20—Movements or behaviour, e.g. gesture recognition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/28—Determining representative reference patterns, e.g. by averaging or distorting; Generating dictionaries
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Psychiatry (AREA)
- Social Psychology (AREA)
- Human Computer Interaction (AREA)
- Multimedia (AREA)
- Image Analysis (AREA)
Abstract
The invention provides a cross-domain pedestrian re-identification method by utilizing posture invariance and graph structure alignment, belonging to the field of computer vision. The invention provides a dictionary learning algorithm based on matrix decomposition to eliminate the influence of domain information and pedestrian attitude information among data sets on cross-domain pedestrian re-identification. Specifically, the method is divided into two parts: (1) decomposing original visual features into attitude invariant components, domain information components and interference information components based on the idea of matrix decomposition, and aiming at extracting visual components which are not influenced by domain information and pedestrian attitude information; (2) in order to further improve the generalization capability of the model, the relation between the posture invariant feature and the semantic attribute is established by introducing hypergraph structure alignment constraint so as to accurately predict the pedestrian attribute of the target data set at the later stage, and finally the pedestrian similarity measurement can be carried out by combining the posture invariant feature and the semantic attribute of the pedestrian so as to further improve the recognition performance.
Description
Technical Field
The invention relates to a cross-domain pedestrian re-identification method by utilizing posture invariance and graph structure alignment, belonging to the field of computer vision.
Background
With the rapid development of artificial intelligence, it is a need to apply pedestrian re-identification technology based on high-dimensional features to real life. Therefore, the scholars at home and abroad make a series of great research progresses in the aspect of pedestrian re-identification, and a plurality of methods are developed. Some methods design discriminative artifact features robust to changes in illumination, viewing angle, etc. for a target data set, or cluster unmarked target data. However, the performance of this kind of method is poor, mainly because the target data has no label, and the model is very difficult to mine the discriminant information. Some more advanced approaches view pedestrian re-identification as an unsupervised domain adaptation problem, which focuses on source domain to target domain knowledge migration. Compared to traditional unsupervised domain adaptation methods, pedestrian labels are completely different in the source domain and the target domain, and therefore the challenge is greater. Such methods still suffer from poor performance compared to supervised methods.
Disclosure of Invention
The invention aims to provide a cross-domain pedestrian re-recognition method by utilizing posture invariance and graph structure alignment, which is used for solving the problem that the existing pedestrian re-recognition algorithm is difficult to deploy; introducing an effective hypergraph structure alignment constraint, establishing a conversion relation between the posture invariant feature and the semantic attribute, and fully combining the advantages of the posture invariant feature and the semantic attribute to carry out joint measurement, wherein the specific flow is shown in figure 1. Compared with the existing method, the method can perform cross-domain re-recognition task, namely, the trained model is deployed to a brand-new camera network for pedestrian recognition.
A cross-domain pedestrian re-recognition method using posture invariance and graph structure alignment comprises the following steps:
1) defining data set variables and characteristics and attributes of pedestrians;
2) a design feature decomposition module for determining a target function containing a posture invariant component dictionary, a domain information component dictionary, an interference component dictionary and a conversion matrix;
3) designing a hypergraph structure alignment module by utilizing semantic attribute information;
4) designing a domain adaptation module capable of reducing domain offset;
5) merging the proposed loss functions into a final optimization function;
6) obtaining a dictionary and a conversion matrix by using an alternative optimization algorithm, thereby further obtaining a target domain data coding coefficient;
7) predicting the identity and the attribute of the pedestrian through the target domain coding coefficient;
8) and calculating the similarity between the pedestrians by using the cosine similarity and combining the predicted identity and the attribute.
The method comprises the following specific steps:
step 1, defining that K pedestrians exist in a source data set,






Step 2: the following loss function Feature Decomposition term (FD) L is designed FD The purpose of (1) decomposing a source domain feature set into an attitude invariant component, a domain component and an interference component:

wherein, V s Denotes the total number of source domain views, X s,v,i And (3) representing the features of the ith identity at the v view angle in the training set s. D p ,D d ,D r Respectively representing an attitude invariant component dictionary, a domain information component dictionary, and an interference component dictionary. While Represents X s,v,i Corresponding to the coding coefficients of the three component dictionaries, respectively. I | · | purple wind * Represents the kernel norm, | ·| non-woven phosphor of the matrix 2,1 Representing a structured sparse norm. Eta, lambda 1 ,λ 2 A regularization parameter is represented. Wherein phi (D) r ,C p ,C r ) Regular terms that promote domain separation are represented, specifically as follows:
Represents X s,v,i Corresponding to the coding coefficients of the three component dictionaries, respectively. I | · | purple wind * Represents the kernel norm, | ·| non-woven phosphor of the matrix 2,1 Representing a structured sparse norm. Eta, lambda 1 ,λ 2 A regularization parameter is represented. Wherein phi (D) r ,C p ,C r ) Regular terms that promote domain separation are represented, specifically as follows:

wherein C is p ,C r Representing the data set as a whole coding coefficients. Lambda [ alpha ] 3 And λ 4 Representing a regularization parameter. I and Q represent the identity matrix and identity matrix, respectively.
And step 3: in order to enhance the robustness and the domain invariance of the semantic attributes, the semantic attributes are introduced to assist cross-domain pedestrian re-identification. Loss function Hypergraph Structure Alignment (HSA) L HSA Is represented as follows:

firstly, a hypergraph G (X, E) is constructed through image samples of a source domain and the identity of a pedestrian, and comprises a group of vertexes And a set of super edges
And a set of super edges Wherein | N j I and | N r And | respectively represents the number of vertexes and super edges. For any given hypergraph, its hyper-edges can be easily converted into a correlation matrix
Wherein | N j I and | N r And | respectively represents the number of vertexes and super edges. For any given hypergraph, its hyper-edges can be easily converted into a correlation matrix α 1 ,α 2 ,β 1 The representation of the hyper-parameter is,
α 1 ,α 2 ,β 1 The representation of the hyper-parameter is, representing two hypergraph laplacian regularizations, P and E represent linear transformation coefficient matrices, L-I-W represent hypergraph laplacian matrices,
representing two hypergraph laplacian regularizations, P and E represent linear transformation coefficient matrices, L-I-W represent hypergraph laplacian matrices, a weight matrix representing a hypergraph to measure the degree of correlation between two vertices;
a weight matrix representing a hypergraph to measure the degree of correlation between two vertices;

D x and D e Diagonal matrices representing the degrees of the super edge and the degrees of the vertex, respectively. W e A diagonal matrix representing super-edge weights.
And 4, step 4: in order to solve the Domain deviation, a Domain Adaptation item is introduced, part of unlabeled data of the target Domain participates in the training of a characteristic decomposition model, and a Domain Adaptation (DA) L is lost DA Is represented as follows:

wherein, V t Represents the total number of views of the target domain, N t Representing the number of samples, X, of the target domain t,v,i And (3) representing the pedestrian image feature sequence of the ith identity at the v view angle in the target data set t. While Represents X t,v,i Corresponding to three component dictionaries D respectively p ,D d ,D r The coding coefficients of (1). Lambda [ alpha ] 2 Is a regularization parameter. Finally, the entire objective function is represented as:
Represents X t,v,i Corresponding to three component dictionaries D respectively p ,D d ,D r The coding coefficients of (1). Lambda [ alpha ] 2 Is a regularization parameter. Finally, the entire objective function is represented as:
L=L FD +L HSA +L DA (6)。
and 5: the proposed functions are then consolidated and merged, and the overall loss function L in step 4 can be expanded into the following form:

step 6: and 5, solving 9 variables, solving each variable by using an alternating iterative optimization algorithm, wherein other variables need to be fixed when one variable is solved in the process. Obtaining an attitude invariant component dictionary D by solving p Domain information component dictionary D d Dictionary of interference components D r And transformation matrices P and E. With these dictionaries, the corresponding coding coefficients can be calculated by the following formula

ζ represents a regularization parameter.
And 7: when calculated, get Then, using the transformation matrices P, E found in step 6, h can be found by equations (9) and (10) t,i And a t,i :
Then, using the transformation matrices P, E found in step 6, h can be found by equations (9) and (10) t,i And a t,i :


In the above formula, h t,i And E can be considered constant by finding the optimum a t,i The minimum value is taken after the F norm of the right term is squared, and the a at the moment is obtained t,i . With predicted identity representation h for the test sample t,i And semantic Attribute a t,i 。α 2 The regularization parameters are represented.
And 8: finally, the similarity achievement sim of the pedestrian image pair in the identity space and the semantic space can be respectively calculated through the cosine distance calculation formula of the equation (11) h And sim a 。

Wherein z is a And z b Respectively representing the current pedestrian identity expression vector and the semantic attribute vector and h obtained in the step 7 t,i And a t,i Are represented by the same, with the difference that z a And z b Broadly refers to the identity representation and semantic attributes of the current pedestrian, and h t,i ,a t,i An identity representation and semantic attributes representing the ith pedestrian. ε is a constant of 0.0000001. And (4) weighting and summing the similarity scores respectively obtained by the identity space and the semantic attribute space, and taking the weighted similarity score as a final pedestrian to perform similarity measurement on the similarity score.
sim final =τsim a +(1-τ)sim h (12)
Where τ > 0 represents the weight occupied by each space. In the present invention, τ is set to 0.2. Through the method, the similarity of the pedestrians in the target data set can be finally measured by using the solved variable.
The invention has the following beneficial effects:
(1) by the aid of the proposed decomposition model, influence of domain information and pedestrian posture information among data sets on cross-domain pedestrian re-identification is eliminated, and differences among different domains are reduced. The method is beneficial to the model to extract the more robust characteristics of the pedestrian in the real scene.
(2) By introducing an effective hypergraph structure alignment constraint, a conversion relation between the posture invariant feature and the semantic attribute is established, and the model is more discriminative for different pedestrians by combining a similarity measurement method performed by the two, for example, the appearances of two pedestrians are very similar, but the two pedestrians can be prevented from being identified as the same pedestrian through attribute information, so that misjudgment is avoided.
Drawings
FIG. 1 is a flow chart of a cross-domain pedestrian re-identification method using gesture invariance and graph structure alignment according to the present invention.
Detailed Description
The invention is further described with reference to the following figures and specific examples.
Example 1: as shown in fig. 1, a cross-domain pedestrian re-identification method using posture invariance and graph structure alignment includes the following steps:
1) defining data set variables and characteristics and attributes of pedestrians;
2) a design feature decomposition module for determining a target function containing a posture invariant component dictionary, a domain information component dictionary, an interference component dictionary and a conversion matrix;
3) designing a hypergraph structure alignment module by utilizing semantic attribute information;
4) designing a domain adaptation module capable of reducing domain offset;
5) merging the proposed loss functions into a final optimization function;
6) obtaining a dictionary and a conversion matrix by using an alternative optimization algorithm, thereby further obtaining a target domain data coding coefficient;
7) predicting the identity and the attribute of the pedestrian through the target domain coding coefficient;
8) and calculating the similarity between the pedestrians by using the cosine similarity and combining the predicted identity and the attribute.
The method comprises the following specific steps:
step 1, defining that K pedestrians exist in a source data set,






Step 2: the following loss function Feature Decomposition term (FD) L is designed FD Is to set the source domain features Decomposed into posturesInvariant component, domain component, interference component:
Decomposed into posturesInvariant component, domain component, interference component:

wherein, V s Denotes the total number of source domain views, X s,v,i And (3) representing the features of the ith identity at the v view angle in the training set s. D p ,D d ,D r Respectively representing an attitude invariant component dictionary, a domain information component dictionary, and an interference component dictionary. While Represents X s,v,i Corresponding to the coding coefficients of the three component dictionaries, respectively. I | · | purple wind * Represents the kernel norm, | ·| non-woven phosphor of the matrix 2,1 Representing a structured sparse norm. Eta, lambda 1 ,λ 2 A regularization parameter is represented. Wherein Φ D r ,C p ,C r ) Regular terms that promote domain separation are represented, specifically as follows:
Represents X s,v,i Corresponding to the coding coefficients of the three component dictionaries, respectively. I | · | purple wind * Represents the kernel norm, | ·| non-woven phosphor of the matrix 2,1 Representing a structured sparse norm. Eta, lambda 1 ,λ 2 A regularization parameter is represented. Wherein Φ D r ,C p ,C r ) Regular terms that promote domain separation are represented, specifically as follows:

wherein C is p ,C r Representing the data set as a whole coding coefficients. Lambda [ alpha ] 3 And λ 4 Representing a regularization parameter. I and Q represent the identity matrix and identity matrix, respectively.
And step 3: in order to enhance the robustness and the domain invariance of the semantic attributes, the semantic attributes are introduced to assist cross-domain pedestrian re-identification. Loss function Hypergraph Structure Alignment (HSA) L HSA Is represented as follows:

firstly, a hypergraph G (X, E) is constructed through image samples of a source domain and the identity of a pedestrian, and comprises a group of vertexes And a set of super edges
And a set of super edges Wherein | N j I and | N r And | respectively represents the number of vertexes and super edges. For any given hypergraph, its hyper-edges can be easily converted into a correlation matrix
Wherein | N j I and | N r And | respectively represents the number of vertexes and super edges. For any given hypergraph, its hyper-edges can be easily converted into a correlation matrix α 1 ,α 2 ,β 1 The representation of the hyper-parameter is,
α 1 ,α 2 ,β 1 The representation of the hyper-parameter is, representing two hypergraph laplacian regularizations, P and E represent linear transformation coefficient matrices, L-I-W represent hypergraph laplacian matrices,
representing two hypergraph laplacian regularizations, P and E represent linear transformation coefficient matrices, L-I-W represent hypergraph laplacian matrices, a weight matrix representing a hypergraph to measure the degree of correlation between two vertices;
a weight matrix representing a hypergraph to measure the degree of correlation between two vertices;

D x and D e Diagonal matrices representing the degrees of the super edge and the degrees of the vertex, respectively. W e A diagonal matrix representing super-edge weights.
And 4, step 4: in order to solve the Domain deviation, a Domain Adaptation item is introduced, part of unlabeled data of the target Domain participates in the training of a characteristic decomposition model, and a Domain Adaptation (DA) L is lost DA Is represented as follows:

wherein, V t Represents the total number of views of the target domain, N t Representing the number of samples, X, of the target domain t,v,i Pedestrian image feature sequence representing ith identity at v view angle in target data set t. While Represents X t,v,i Corresponding to three component dictionaries D respectively p ,D d ,D r The coding coefficients of (1). Lambda [ alpha ] 2 Is a regularization parameter. Finally, the entire objective function is represented as:
Represents X t,v,i Corresponding to three component dictionaries D respectively p ,D d ,D r The coding coefficients of (1). Lambda [ alpha ] 2 Is a regularization parameter. Finally, the entire objective function is represented as:
L=L FD +L HSA +L DA (6)。
and 5: the proposed functions are then consolidated and merged, and the overall loss function L in step 4 can be expanded into the following form:

and 6: in the step 5, 9 variables need to be solved, each variable is solved by using an alternating iterative optimization algorithm, and other variables need to be fixed in the process of solving one variable. Obtaining an attitude invariant component dictionary D by solving p Domain information component dictionary D d Dictionary of interference components D r And transformation matrices P and E. With these dictionaries, the corresponding coding coefficients can be calculated by the following formula

ζ represents the regularization parameter.
And 7: when calculated, get Then, using the transformation matrices P, E obtained in step 6, h can be obtained by equations (9) and (10) t,i And a t,i :
Then, using the transformation matrices P, E obtained in step 6, h can be obtained by equations (9) and (10) t,i And a t,i :


In the above formula, h t,i And E can be considered constant by finding the optimum a t,i The minimum value is taken after the F norm of the right term is squared, and the a at the moment is obtained t,i . With predicted identity representation h for the test sample t,i And semantic Attribute a t,i 。α 2 Representing a regularization parameter.
And 8: finally, the similarity achievement sim of the pedestrian image pair in the identity space and the semantic space can be respectively calculated through the cosine distance calculation formula of the equation (11) h And sim a 。

Wherein z is a And z b Respectively representing the current pedestrian identity expression vector and the semantic attribute vector and h obtained in the step 7 t,i And a t,i Are identical, except that z a And z b Broadly refers to the identity representation and semantic attributes of the current pedestrian, and h t,i ,a t,i An identity representation and semantic attributes representing the ith pedestrian. ε is a constant of 0.0000001. And (4) weighting and summing the similarity scores respectively obtained by the identity space and the semantic attribute space, and taking the weighted similarity score as a final pedestrian to perform similarity measurement on the similarity score.
sim final =τsim a +(1-τ)sim h (12)
Where τ > 0 represents the weight occupied by each space. In the present invention, τ is set to 0.2. Through the method, the similarity of the pedestrians in the target data set can be finally measured by using the solved variable.
In the model proposed above, there are 11 parameters to be set, including dictionary D p ,D d ,D r Atom size d of p ,d d ,d r And the regularization term parameter λ 1 ,λ 2 ,λ 3 ,λ 4 ,α 1 ,α 2 β, ζ. In the experiment, these parameters were set to d, respectively p =600,d d =180,d r =180,λ 1 =0.0001,λ 2 =0.0001,λ 3 =0.01,λ 4 =1,α 1 =0.1,α 2 =0.1,β=0.1,ζ=0.1。
The GOG features are used as visual features of pedestrians, and standard semantic attributes which are already represented are used as attributes of the pedestrians. To demonstrate that the algorithm can be deployed in real life, experiments were conducted on the VIPeR dataset. The data set contains two cameras, each capturing one image per person. The data set has various pedestrian attitude changes, as well as visual angles and illumination changes. And taking prid2011 and grid as source data sets, and averagely dividing the model into training and testing. Training was repeated 10 times to obtain the average as the final performance. The comparison results are shown in table 1. The experiment proves that the method can directly deploy the trained model to the VIPer scene for recognition and keep good recognition rate.
TABLE 1 VIPeR data set


The invention also carries out experiments on the CUHK01 data set, the data set is collected from the campus scene of Chinese university in hong Kong, the cameras are respectively arranged in a teaching building and an outdoor scene, and the visual angle is wide step by step. Tests were performed with VIPeR as the source data set and CUHK01 as the target data set. The results are shown in table 2, which also shows the performance of other processes, from which it can be seen that the process achieves a relatively high performance.
TABLE 2 CUHK01 dataset

While the present invention has been described in detail with reference to the embodiments shown in the drawings, the present invention is not limited to the embodiments, and various changes can be made without departing from the spirit and scope of the present invention.
Claims (1)
1. A cross-domain pedestrian re-recognition method using posture invariance and graph structure alignment is characterized in that: the method comprises the following steps:
1) defining data set variables and characteristics and attributes of pedestrians;
2) a design feature decomposition module for determining a target function containing a posture invariant component dictionary, a domain information component dictionary, an interference component dictionary and a conversion matrix;
3) designing a hypergraph structure alignment module by utilizing semantic attribute information;
4) designing a domain adaptation module capable of reducing domain offset;
5) merging the proposed loss functions into a final optimization function;
6) obtaining a dictionary and a conversion matrix by using an alternative optimization algorithm, thereby further obtaining a target domain data coding coefficient;
7) predicting the identity and the attribute of the pedestrian through the target domain coding coefficient;
8) calculating the similarity between the pedestrians by using the cosine similarity in combination with the predicted identity and attribute;
the method comprises the following specific steps:
step 1, defining that K pedestrians exist in a source data set, wherein
wherein Representing the ith pedestrian feature of the source domain s, d representing the feature dimension,
Representing the ith pedestrian feature of the source domain s, d representing the feature dimension, representing the ith pedestrian attribute, c represents the attribute dimension,
representing the ith pedestrian attribute, c represents the attribute dimension, indicates the ith pedestrian label, N s Denotes the number of samples, X s ,A s ,Y s Respectively representing a source domain feature set, a source domain attribute set, a source domain label set and defining a target data set
indicates the ith pedestrian label, N s Denotes the number of samples, X s ,A s ,Y s Respectively representing a source domain feature set, a source domain attribute set, a source domain label set and defining a target data set Contains N in total t The number of the samples is one,
Contains N in total t The number of the samples is one, representing the ith pedestrian feature of the target domain t, using the GOG pedestrian feature on the feature level, and using the attribute of the existing data set as the attribute of the pedestrian;
representing the ith pedestrian feature of the target domain t, using the GOG pedestrian feature on the feature level, and using the attribute of the existing data set as the attribute of the pedestrian;
step 2: the loss function characteristic decomposition term L is designed as follows FD Is to set the source domain features Decomposition into pose-invariant components, domain components, interference components:
Decomposition into pose-invariant components, domain components, interference components:

wherein, V s Denotes the total number of source domain views, X s,v,i Features representing the ith identity at the v view in the training set s, D p ,D d ,D r Respectively represent an attitude invariant component dictionary, a domain information component dictionary, and an interference component dictionary, and represents X s,v,i Corresponding to the coding coefficients of the three-component dictionary, | | · | | non-woven phosphor * Represents the kernel norm, | ·| non-woven phosphor of the matrix 2,1 Indicating knotConstructed sparse norm, η, λ 1 ,λ 2 Represents a regularization parameter, where Φ (D) r ,C p ,C r ) Regular terms that promote domain separation are represented, specifically as follows:
represents X s,v,i Corresponding to the coding coefficients of the three-component dictionary, | | · | | non-woven phosphor * Represents the kernel norm, | ·| non-woven phosphor of the matrix 2,1 Indicating knotConstructed sparse norm, η, λ 1 ,λ 2 Represents a regularization parameter, where Φ (D) r ,C p ,C r ) Regular terms that promote domain separation are represented, specifically as follows:

wherein C is p ,C r Representing the overall coding coefficient, λ, of the data set 3 And λ 4 Representing a regular parameter, wherein I and Q respectively represent an identity matrix and an identity matrix;
and step 3: in order to enhance the robustness and the domain invariance of semantic attributes, the semantic attributes are introduced to assist cross-domain pedestrian re-identification, and a loss function hypergraph structure alignment item L HSA Is represented as follows:

firstly, a hypergraph G (X, E) is constructed through image samples of a source domain and the identity of a pedestrian, and comprises a group of vertexes And a set of super edges
And a set of super edges Wherein | N j I and | N r L respectively represents the number of vertexes and super edges, and for any given super graph, the super edge can be easily converted into a correlation matrix
Wherein | N j I and | N r L respectively represents the number of vertexes and super edges, and for any given super graph, the super edge can be easily converted into a correlation matrix α 1 ,α 2 ,β 1 Denotes a hyperparameter, tr (C) p LC pT ) Representing two hypergraph laplacian regularizations, P and E represent linear transformation coefficient matrices, L-I-W represent hypergraph laplacian matrices,
α 1 ,α 2 ,β 1 Denotes a hyperparameter, tr (C) p LC pT ) Representing two hypergraph laplacian regularizations, P and E represent linear transformation coefficient matrices, L-I-W represent hypergraph laplacian matrices,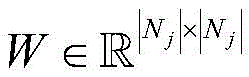 a weight matrix representing a hypergraph to measure the degree of correlation between two vertices;
a weight matrix representing a hypergraph to measure the degree of correlation between two vertices;

D x and D e Diagonal matrices, W, representing the degrees of the super-edges and the degrees of the vertices, respectively e A diagonal matrix representing super-edge weights;
and 4, step 4: in order to solve the domain deviation, a domain adaptation item is introduced, part of unmarked data of the target domain is used for participating in the training of a characteristic decomposition model, and a function domain adaptation item L is lost DA Is represented as follows:


wherein, V t Represents the total number of views of the target domain, N t Representing the number of samples, X, of the target domain t,v,i A sequence of pedestrian image features representing the ith identity at the v view angle in the target data set t, and represents X t,v,i Corresponding to three component dictionaries D respectively p ,D d ,D r A coding coefficient of (a) 2 To regularize the parameters, finally, the entire objective function is expressed as:
represents X t,v,i Corresponding to three component dictionaries D respectively p ,D d ,D r A coding coefficient of (a) 2 To regularize the parameters, finally, the entire objective function is expressed as:
L=L FD +L HSA +L DA (6)
and 5: the proposed functions are then consolidated and merged, and the overall loss function L in step 4 can be expanded into the following form:

step 6: in the step 5, 9 variables need to be solved, each variable is solved by using an alternative iterative optimization algorithm, in the process, one variable needs to be fixed with other variables, and the attitude invariant component dictionary D is obtained by solving p Domain information component dictionary D d Dictionary of interference components D r And transformation matrices P and E, with these dictionaries, whose corresponding coding coefficients can be calculated by the following formula

ζ represents a regularization parameter;
and 7: when calculated, get Then, using the transformation matrices P, E obtained in step 6, h can be obtained by equations (9) and (10) t,i And a t,i :
Then, using the transformation matrices P, E obtained in step 6, h can be obtained by equations (9) and (10) t,i And a t,i :


In the above formula, h t,i And E can be considered constant by finding the optimum a t,i The minimum value is taken after the F norm of the right term is squared, and the a at the moment is obtained t,i For the test sample, there is a predicted identity representation h t,i And semantic Attribute a t,i ,α 2 Representing a regularization parameter;
and 8:finally, the similarity achievement sim of the pedestrian image pair in the identity space and the semantic space can be respectively calculated through the cosine distance calculation formula of the equation (11) h And sim a ,

Wherein z is a And z b Respectively representing the current pedestrian identity expression vector and the semantic attribute vector and h obtained in the step 7 t,i And a t,i Are represented by the same, with the difference that z a And z b Broadly refers to the identity representation and semantic attributes of the current pedestrian, and h t,i ,a t,i Representing the identity representation and semantic attribute of the ith pedestrian, wherein epsilon is a constant of 0.0000001, weighting and summing similarity scores obtained from an identity space and a semantic attribute space respectively, and taking the weighted similarity score as a final pedestrian to perform similarity measurement on the similarity score:
sim final =τsim a +(1-τ)sim h (12)
wherein tau > 0 represents the weight occupied by each space, and tau is set to be 0.2, and finally the similarity of pedestrians in the target data set can be measured by using the solved variable.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010434344.9A CN111783526B (en) | 2020-05-21 | 2020-05-21 | Cross-domain pedestrian re-identification method using posture invariance and graph structure alignment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010434344.9A CN111783526B (en) | 2020-05-21 | 2020-05-21 | Cross-domain pedestrian re-identification method using posture invariance and graph structure alignment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111783526A CN111783526A (en) | 2020-10-16 |
| CN111783526B true CN111783526B (en) | 2022-08-05 |
Family
ID=72754356
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010434344.9A Active CN111783526B (en) | 2020-05-21 | 2020-05-21 | Cross-domain pedestrian re-identification method using posture invariance and graph structure alignment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111783526B (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112528756B (en) * | 2020-11-20 | 2023-06-23 | 华南理工大学 | Unsupervised pedestrian re-identification method based on different composition |
| CN114022901B (en) * | 2021-11-04 | 2024-07-16 | 东南大学 | Cross-modal ReID method based on vision and radio frequency perception |
| CN114443954B (en) * | 2022-01-07 | 2024-09-17 | 中国海洋大学 | One-to-many cross-domain recommendation method and system based on high-order graph structure |
Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104268583A (en) * | 2014-09-16 | 2015-01-07 | 上海交通大学 | Pedestrian re-recognition method and system based on color area features |
| CN105160312A (en) * | 2015-08-27 | 2015-12-16 | 南京信息工程大学 | Recommendation method for star face make up based on facial similarity match |
| CN106778464A (en) * | 2016-11-09 | 2017-05-31 | 深圳市深网视界科技有限公司 | A kind of pedestrian based on deep learning recognition methods and device again |
| CN107563328A (en) * | 2017-09-01 | 2018-01-09 | 广州智慧城市发展研究院 | A kind of face identification method and system based under complex environment |
| CN109101865A (en) * | 2018-05-31 | 2018-12-28 | 湖北工业大学 | A kind of recognition methods again of the pedestrian based on deep learning |
| CN109190470A (en) * | 2018-07-27 | 2019-01-11 | 北京市商汤科技开发有限公司 | Pedestrian recognition methods and device again |
| CN109214442A (en) * | 2018-08-24 | 2019-01-15 | 昆明理工大学 | A kind of pedestrian's weight recognizer constrained based on list and identity coherence |
| CN110046870A (en) * | 2019-04-16 | 2019-07-23 | 中山大学 | A kind of method and system of registering based on geographical location and face characteristic |
| CN110349240A (en) * | 2019-06-26 | 2019-10-18 | 华中科技大学 | It is a kind of it is unsupervised under based on posture conversion pedestrian's picture synthetic method and system |
| CN110826417A (en) * | 2019-10-12 | 2020-02-21 | 昆明理工大学 | Cross-view pedestrian re-identification method based on discriminant dictionary learning |
| CN111177447A (en) * | 2019-12-26 | 2020-05-19 | 南京大学 | Pedestrian image identification method based on depth network model |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20020068842A1 (en) * | 1999-01-29 | 2002-06-06 | Brundage Scott R. | Blending of economic, reduced oxygen, winter gasoline |
| US7270687B2 (en) * | 2001-05-15 | 2007-09-18 | Sunoco, Inc. | Reduced emissions transportation fuel |
-
2020
- 2020-05-21 CN CN202010434344.9A patent/CN111783526B/en active Active
Patent Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104268583A (en) * | 2014-09-16 | 2015-01-07 | 上海交通大学 | Pedestrian re-recognition method and system based on color area features |
| CN105160312A (en) * | 2015-08-27 | 2015-12-16 | 南京信息工程大学 | Recommendation method for star face make up based on facial similarity match |
| CN106778464A (en) * | 2016-11-09 | 2017-05-31 | 深圳市深网视界科技有限公司 | A kind of pedestrian based on deep learning recognition methods and device again |
| CN107563328A (en) * | 2017-09-01 | 2018-01-09 | 广州智慧城市发展研究院 | A kind of face identification method and system based under complex environment |
| CN109101865A (en) * | 2018-05-31 | 2018-12-28 | 湖北工业大学 | A kind of recognition methods again of the pedestrian based on deep learning |
| CN109190470A (en) * | 2018-07-27 | 2019-01-11 | 北京市商汤科技开发有限公司 | Pedestrian recognition methods and device again |
| CN109214442A (en) * | 2018-08-24 | 2019-01-15 | 昆明理工大学 | A kind of pedestrian's weight recognizer constrained based on list and identity coherence |
| CN110046870A (en) * | 2019-04-16 | 2019-07-23 | 中山大学 | A kind of method and system of registering based on geographical location and face characteristic |
| CN110349240A (en) * | 2019-06-26 | 2019-10-18 | 华中科技大学 | It is a kind of it is unsupervised under based on posture conversion pedestrian's picture synthetic method and system |
| CN110826417A (en) * | 2019-10-12 | 2020-02-21 | 昆明理工大学 | Cross-view pedestrian re-identification method based on discriminant dictionary learning |
| CN111177447A (en) * | 2019-12-26 | 2020-05-19 | 南京大学 | Pedestrian image identification method based on depth network model |
Non-Patent Citations (4)
| Title |
|---|
| Yang E.Shared predictive cross-modal deep quantization.《IEEE transactions on neural networks and learning systems》.2018,第5292-5303页. * |
| 张耿宁等.基于特征融合与核局部Fisher判别分析的行人重识别.《计算机应用》.2016,(第09期), * |
| 詹敏等.基于自适应度量学习的行人再识别.《电脑知识与技术》.2017,(第10期), * |
| 郑伟诗等.非对称行人重识别:跨摄像机持续行人追踪.《中国科学:信息科学》.2018,(第05期), * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111783526A (en) | 2020-10-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111126360B (en) | Cross-domain pedestrian re-identification method based on unsupervised combined multi-loss model | |
| CN105975931B (en) | A kind of convolutional neural networks face identification method based on multiple dimensioned pond | |
| CN111160533B (en) | Neural network acceleration method based on cross-resolution knowledge distillation | |
| CN111783526B (en) | Cross-domain pedestrian re-identification method using posture invariance and graph structure alignment | |
| CN109993100B (en) | Method for realizing facial expression recognition based on deep feature clustering | |
| CN109614853B (en) | Bilinear pedestrian re-identification network construction method based on body structure division | |
| CN109299707A (en) | A kind of unsupervised pedestrian recognition methods again based on fuzzy depth cluster | |
| CN105160310A (en) | 3D (three-dimensional) convolutional neural network based human body behavior recognition method | |
| CN108256486B (en) | Image identification method and device based on nonnegative low-rank and semi-supervised learning | |
| Hasan | An application of pre-trained CNN for image classification | |
| CN105760821A (en) | Classification and aggregation sparse representation face identification method based on nuclear space | |
| Pratama et al. | Face recognition for presence system by using residual networks-50 architecture | |
| CN111783521A (en) | Pedestrian re-identification method based on low-rank prior guidance and based on domain invariant information separation | |
| CN105760879A (en) | Fourier-Mellin transform-based image geometric matching method | |
| CN106960185B (en) | The Pose-varied face recognition method of linear discriminant deepness belief network | |
| CN103268484A (en) | Design method of classifier for high-precision face recognitio | |
| CN107330412A (en) | A kind of face age estimation method based on depth rarefaction representation | |
| CN108596044B (en) | Pedestrian detection method based on deep convolutional neural network | |
| CN111695455B (en) | Low-resolution face recognition method based on coupling discrimination manifold alignment | |
| CN104573728B (en) | A kind of texture classifying method based on ExtremeLearningMachine | |
| Zha et al. | Intensifying the consistency of pseudo label refinement for unsupervised domain adaptation person re-identification | |
| Wang et al. | Action recognition using linear dynamic systems | |
| CN114972904A (en) | Zero sample knowledge distillation method and system based on triple loss resistance | |
| CN114613016A (en) | Gesture image feature extraction method based on Xscene network improvement | |
| Peng | Research on Emotion Recognition Based on Deep Learning for Mental Health |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |