CN111709313B - Pedestrian re-identification method based on local and channel combination characteristics - Google Patents
Pedestrian re-identification method based on local and channel combination characteristics Download PDFInfo
- Publication number
- CN111709313B CN111709313B CN202010460902.9A CN202010460902A CN111709313B CN 111709313 B CN111709313 B CN 111709313B CN 202010460902 A CN202010460902 A CN 202010460902A CN 111709313 B CN111709313 B CN 111709313B
- Authority
- CN
- China
- Prior art keywords
- pedestrian
- picture
- pictures
- network
- multiplied
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/103—Static body considered as a whole, e.g. static pedestrian or occupant recognition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2415—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on parametric or probabilistic models, e.g. based on likelihood ratio or false acceptance rate versus a false rejection rate
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/047—Probabilistic or stochastic networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/44—Local feature extraction by analysis of parts of the pattern, e.g. by detecting edges, contours, loops, corners, strokes or intersections; Connectivity analysis, e.g. of connected components
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Mathematical Physics (AREA)
- Computing Systems (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Probability & Statistics with Applications (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Multimedia (AREA)
- Human Computer Interaction (AREA)
- Image Analysis (AREA)
Abstract
The invention provides a pedestrian re-identification method based on local and channel combination characteristics. According to the invention, various shielding situations are simulated in a data enhancement mode, and the robustness of the shielding problem is improved. The picture is simultaneously scaled, rotated and translated using the STN to align the pedestrian picture. And horizontally dividing the picture to obtain the characteristics of different parts. For the global features of the whole pedestrian picture, the pedestrian identity is correctly classified through classification loss, the features of the same pedestrian are distributed more closely through similarity loss, and the features of different pedestrians are distributed more distantly. For local and channel combination features, different patterns on these different body parts are compared by similarity loss. Finally, the two features are fused to be used as the pedestrian descriptors, and the discrimination of the pedestrian descriptors is further improved. Through improving the anti-sheltering and discrimination ability of the pedestrian descriptor, the pedestrian re-identification can be more accurate.
Description
Technical Field
The invention belongs to the field of computer vision and image retrieval, and relates to a pedestrian re-identification method based on local and channel combination characteristics. The method solves some common problems in the field of pedestrian re-identification.
Background
With the development and popularization of monitoring systems, more and more pedestrian image data are urgently pending. The pedestrian re-identification technology is to find out the image of the pedestrian from the images of the pedestrians shot by a certain camera and the images of the pedestrians shot by other cameras. The intelligent pedestrian detection system has wide application scenes in real life, such as intelligent security, criminal investigation, man-machine interaction and the like, and is also closely related to other fields such as pedestrian detection, pedestrian tracking and the like.
The pedestrian re-identification method commonly used at present is based on a Convolutional Neural Network (CNN). Some approaches therefore aim to design or refine network models to extract more discriminative pedestrian image features, such as the residual network ResNet-50 pre-trained on ImageNet data sets and fine-tuned on the pedestrian re-identification data sets. While some methods work on improving or designing the loss functions, the loss functions are mainly classified into two categories: 1) classifying the loss, treating each pedestrian as a particular class, such as cross-entropy loss (cross-entropy loss); 2) and similarity loss, namely, the relationship which restricts the similarity between pedestrian images, such as contrast loss (contrast loss), triple loss (triple loss) and quadruple loss (quadruple loss).
Disclosure of Invention
Aiming at the problems in the existing pedestrian re-identification field, the invention provides a pedestrian re-identification method based on local and channel combination characteristics. The method has the following advantages: 1) the network model improves the capability of resisting the shielding problem in a data enhancement mode; 2) solving the problem of misalignment of images of pedestrians through a Spatial Transformer Network (STN); 3) the local and channel combination characteristics with more discrimination are obtained by cutting the characteristic diagram and grouping the characteristic diagram channels; 4) by applying different loss functions to different features, the discrimination of the features is further improved. The method provided by the invention comprehensively solves the main problems of shielding, misalignment, large pedestrian appearance change and the like in pedestrian re-identification, so that the method has more accurate identification capability.
A pedestrian re-identification method based on local and channel combination features comprises the following procedures:
firstly, a training process: the neural network is trained to obtain the best network parameters. The samples in the training dataset consist of a pedestrian picture x and its corresponding pedestrian identity id (x), id (x) e { 1. C represents the total number of the identities of the pedestrians, and the pedestrian with one identity has a plurality of pictures. The method comprises the following specific steps:
a small batch of data contains P x K pictures, namely P pedestrians with different identities, and K pictures of each pedestrian. If the number of pictures of one pedestrian is more than K in the training set, randomly sampling K pictures; if the number of the pictures is less than K, all the pictures are sampled, and the sampling is not enough and repeated.
2-1, generating a picture Pool (Pool) capable of storing pictures with different resolutions;
2-2, before each picture is input into the network, it will be in p 1 And copying one small picture into Pool in a probability mode. Assuming that the resolution of a picture is H × W, the resolution of a small picture, i.e., a picture block, randomly falls within the interval [0.1H,0.2H ]]×[0.1W,0.2W]In between, the locations are also randomly selected.
2-3, then with p 2 And randomly selecting a picture block from Pool according to the probability to cover the picture, and randomly selecting the covered position.
using the ResNet-50 network pre-trained on the ImageNet dataset, the structure before the Global Average Pooling (GAP) Layer of the network is preserved and the step size of the last Convolutional Layer (Convolutional Layer) is set to 1, which is denoted as the "Convolutional basis network". After a picture with the resolution of 256 × 128 is input into the convolution base network, a tensor eigenmap T with the size of 16 × 8 × 2048 is output.
And 4, grouping the channels to obtain the characteristics of each group of channels:
dividing the tensor eigen map T with the size of 16 multiplied by 8 multiplied by 2048 obtained in the step 3 into 4 groups along the channel (namely the last dimension) on average, wherein the size of the tensor eigen map of each group is 16 multiplied by 8 multiplied by 512 and is respectively recorded as T 1 ,T 2 ,T 3 ,T 4 。
And 5, cutting the tensor characteristic diagram to obtain local characteristics:
each obtained in step 4Eigenmap of group tensor T 1 ,T 2 ,T 3 ,T 4 The image is equally divided into 4 local tensor eigenmaps along the horizontal direction, the size of each local tensor eigenmap is 4 multiplied by 8 multiplied by 512, and the local tensor eigenmaps are respectively marked as T 11 ~T 14 ,T 21 ~T 24 ,T 31 ~T 34 ,T 41 ~T 44 . T obtaining 16 local tensor eigenmaps T through steps 4 and 5 11 ~T 14 ,T 21 ~T 24 ,T 31 ~T 34 ,T 41 ~T 44 . Each local tensor eigenmap represents the combined features of different locations and different channels.
And 6, compressing the characteristic diagram:
and (3) convolving the tensor eigen map T, wherein the size of a convolution kernel is 16 multiplied by 8 multiplied by 512, the number of the convolution kernels is 512, and parameters are initialized randomly to obtain the global features g with the size of 1 multiplied by 512. Same pair T 11 ~T 14 ,T 21 ~T 24 ,T 31 ~T 34 ,T 41 ~T 44 Performing convolution respectively, wherein the convolution kernel size corresponding to each local tensor eigenmap is 4 multiplied by 8 multiplied by 512, the number is 512, parameters are initialized randomly, and 16 local channel combined features pc with the size of 1 multiplied by 512 are obtained 1 ~pc 16 。
Step 7, applying different loss functions to different characteristics:
Combining features pc for local channels 1 ~pc 16 Batch Hard sample triple Loss (Batch Hard Triplet Loss) was applied separately:

in the formula (1), X represents the small batch of data obtained by sampling in the step 1, and theta represents the parameter of the network. Representing that the ith pedestrian corresponds to the a picture in the K pictures,
Representing that the ith pedestrian corresponds to the a picture in the K pictures, representing that the ith pedestrian corresponds to the p picture in the K pictures, and calling the p picture as a positive sample pair because the two pictures belong to the same pedestrian;
representing that the ith pedestrian corresponds to the p picture in the K pictures, and calling the p picture as a positive sample pair because the two pictures belong to the same pedestrian; represents that the jth pedestrian corresponds to the nth picture in the K pictures because
represents that the jth pedestrian corresponds to the nth picture in the K pictures because And
And belonging to different pedestrians and called as a negative sample pair. f. of θ (x) D (x, y) represents the Euclidean Distance (Euclidean Distance) between the feature x and the feature y. m is a constant that constrains the relationship between the two feature pairs distance, [ x ]] + Max (0, x). A picture of a pedestrian
belonging to different pedestrians and called as a negative sample pair. f. of θ (x) D (x, y) represents the Euclidean Distance (Euclidean Distance) between the feature x and the feature y. m is a constant that constrains the relationship between the two feature pairs distance, [ x ]] + Max (0, x). A picture of a pedestrian In other words, traversing the pedestrian corresponds to each of the K pictures
In other words, traversing the pedestrian corresponds to each of the K pictures Find a particular
Find a particular So that
So that And
And the Euclidean distance between the two characteristics obtained after the input network operation is maximum respectively,
the Euclidean distance between the two characteristics obtained after the input network operation is maximum respectively, namely a positive and difficult sample pair; meanwhile, each picture (P-1) multiplied by K pictures in total) of the rest pedestrians is traversed
namely a positive and difficult sample pair; meanwhile, each picture (P-1) multiplied by K pictures in total) of the rest pedestrians is traversed Find a particular
Find a particular So that
So that And
And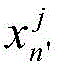 the Euclidean distance between the two characteristics obtained after the input network operation is respectively minimum,
the Euclidean distance between the two characteristics obtained after the input network operation is respectively minimum,  Namely a negative difficulty sample pair. The loss function finds out the corresponding positive difficulty and negative difficulty sample pairs of each picture of each pedestrian, and constrains the relationship between the positive difficulty sample pairs characteristic distance and the negative difficulty sample pairs characteristic distance.
Namely a negative difficulty sample pair. The loss function finds out the corresponding positive difficulty and negative difficulty sample pairs of each picture of each pedestrian, and constrains the relationship between the positive difficulty sample pairs characteristic distance and the negative difficulty sample pairs characteristic distance.
For the feature pc 1 And the Batch Hard triple Loss is as follows:

in the formula (2) Representing a feature pc extracted from the a picture of the ith pedestrian 1 ,
Representing a feature pc extracted from the a picture of the ith pedestrian 1 , Representing features pc extracted from the p picture of the ith pedestrian 1 ,
Representing features pc extracted from the p picture of the ith pedestrian 1 , Representing features pc extracted from the nth picture of the jth pedestrian 1 。
Representing features pc extracted from the nth picture of the jth pedestrian 1 。
For the global signature g, the Batch Hard Triplet Loss and the Softmax Loss are applied, respectively. The Batch Hard triple Loss is as follows:

in the formula (3)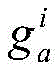 Representing the feature g extracted from the a picture of the ith pedestrian,
Representing the feature g extracted from the a picture of the ith pedestrian, representing the feature g extracted from the p picture of the ith pedestrian,
representing the feature g extracted from the p picture of the ith pedestrian, representing the feature g extracted from the nth picture of the jth pedestrian. Before applying Softmax Loss, g needs to be imported into a Fully Connected Layer (FC Layer). The number of output neurons of the full connection layer is the total number C of the pedestrian identities of the training set, and parameters of the full connection layer are initialized randomly. The Softmax Loss of the global feature g is:
representing the feature g extracted from the nth picture of the jth pedestrian. Before applying Softmax Loss, g needs to be imported into a Fully Connected Layer (FC Layer). The number of output neurons of the full connection layer is the total number C of the pedestrian identities of the training set, and parameters of the full connection layer are initialized randomly. The Softmax Loss of the global feature g is:

in the formula (4) Representing a feature g extracted from the jth picture of the ith pedestrian,
Representing a feature g extracted from the jth picture of the ith pedestrian,  Representing the identity of the pedestrian corresponding to the picture.
Representing the identity of the pedestrian corresponding to the picture. Represents FClayer number
Represents FClayer number Weight corresponding to each output neuron, W k Represents the weight corresponding to the k output neuron of the FClayer.
Weight corresponding to each output neuron, W k Represents the weight corresponding to the k output neuron of the FClayer.
The overall loss function of the network is:

in formula (5) < lambda > 1 ,λ 2 ,λ 3 For three lost weights, satisfy λ 1 +λ 2 +λ 3 =1。
And 8, recording the network constructed in the step 3-6 as N. Using a gradient descent algorithm, the Loss function Loss in step 7 is derived and the learnable parameters in N are optimized by back propagation.
Step 9, aligning the feature graph by using a space transformation network:
9-1, outputting a characteristic diagram F from a 4 th Block (Res 4 Block) of the convolution base network in N 4 (three-dimensional tensor) obtaining a vector theta (theta) with the length of 6 through a residual connecting Block (Res Block, parameter random initialization) and a GAP layer 11 ,θ 12 ,θ 13 ,θ 21 ,θ 22 ,θ 23 ). Wherein theta is 11 ,θ 12 ,θ 21 ,θ 22 For scaling and rotating the characteristic map, theta 13 ,θ 23 For translating the feature map.
9-2, using theta 11 ,θ 12 ,θ 13 ,θ 21 ,θ 22 ,θ 23 Outputting a profile F for Block 2 (Res2Block) of a convolutional base network in N 2 (tensor with size of H multiplied by W multiplied by C) is affine transformed to obtain a blank feature map F " 2 . To F 2 For the eigen map (tensor of H × W size) of the channel c, the coordinate of the pixel point on the eigen map is (x) s ,y s ) After affine transformation becomes (x) t ,y t ) The relationship between the two is:

9-3, blank feature map F according to formula (6) " 2 From F 2 Filling the upper sampling pixel to obtain an aligned feature map F' 2 . . In the affine process, aOccurrence of F " 2 F corresponding to middle coordinate 2 Coordinate exceeds F 2 In the original range, the pixel value is set to 0 for these coordinates. Occurrence of F " 2 F corresponding to middle coordinate 2 When the coordinates are not pixel points, filling pixel values to the coordinates through bilinear interpolation:

in the formula (7) Is F' 2 The pixel value of the (m, n) position on the c-channel of (c),
Is F' 2 The pixel value of the (m, n) position on the c-channel of (c), is F 2 The (m, n) position on the c-channel of (c).
is F 2 The (m, n) position on the c-channel of (c).
Step 10, processing the aligned characteristic graph:
for aligned feature map F' 2 Inputting the data into a new convolution network, wherein the new convolution network is formed by stacking Res 3 Block, Res 4 Block and Res 5 Block in ResNet-50 network pre-trained on ImageNet data set, and outputting a feature map T with the same size as the feature map T in step 3 align . For T align The same operation as in step 3-6 is performed, and 1 global feature g is obtained align And 16 local and channel combination features Note that the network constructed in steps 9-10 is N align ,N align The convolutional code is composed of
Note that the network constructed in steps 9-10 is N align ,N align The convolutional code is composed of Res 1 Block, Res 2 Block, Res 3 Block, Res 4 Block and STN of a convolutional base network in N, Res 3 Block, Res 4 Block and Res 5 Block in a new convolutional network, and convolutional layers for compressing global features and local and channel combination features. For global feature g align And local and channel combining features Optimizing N using the same loss function in step 7 align Of the learning parameters.
Optimizing N using the same loss function in step 7 align Of the learning parameters.
II, a test flow:
the test data set is divided into a query set and a warehouse set, wherein the query set comprises the pedestrian pictures with known identities, and the warehouse set comprises the pictures with the same identities as the pedestrians in the query set and the pictures with different identities from the pedestrians in the query set. The data set is constructed by shooting pictures of pedestrians by monitoring cameras with non-overlapping view angles, automatically marking a rectangular frame of the pedestrians by a pedestrian Detector (DPM), and finally keeping the pictures of the pedestrians in the rectangular frame and adding identity tags of the pedestrians, wherein the pictures of the same pedestrian in the query set and the warehouse set have different shooting view angles. The method comprises the following specific steps:


And 2, similarly obtaining the pedestrian descriptors of all the pictures in the warehouse through the step 1.
And 3, respectively calculating and storing cosine distances between the pedestrian descriptors to be inquired and each pedestrian descriptor in the warehouse set.
And 4, sequencing the stored distances from small to large, and selecting the pedestrian pictures of the warehouse corresponding to the front k distances as the re-identification result of the pedestrian to be inquired.
And 5, judging whether the real identity of the warehouse pedestrian picture obtained by the proportion recognition is consistent with the identity of the pedestrian to be inquired to measure the recognition performance of the model.
The invention has the following beneficial effects:
according to the invention, various shielding situations are simulated in a data enhancement mode, and the network improves the robustness of the shielding problem by processing the pictures which are artificially shielded. The picture is simultaneously scaled, rotated and translated using the STN to align the pedestrian picture. On the basis that the pictures are aligned, the pictures are simply horizontally divided, so that different body parts of the pedestrian can be well positioned, and the features of the different parts can be obtained (the operations of cutting, channel grouping and affine transformation on the feature map are equivalent to the same operation on the original picture). Different channels in the feature map will respond to different patterns (color, clothing type, gender, age, etc.), so the local and channel combination features can better locate different patterns on different body parts of a pedestrian. For the global features of the whole pedestrian picture, the pedestrian identity is correctly classified through classification loss, the features of the same pedestrian are distributed more closely through similarity loss, and the features of different pedestrians are distributed more distantly. For local and channel combined features, classification loss is not applicable because the information content is small, and the pedestrian identity cannot be correctly classified through the feature. But comparing the different patterns on these different body parts through similarity loss can make the model better distinguish these patterns, making the local and channel combination features more discriminative. Finally, the two features are fused to be used as the pedestrian descriptors, and the discrimination of the pedestrian descriptors is further improved. Through improving the anti-sheltering and discrimination ability of the pedestrian descriptor, the pedestrian re-identification can be more accurate.
Drawings
FIG. 1 is a flow chart of the present invention;
FIG. 2 is an exemplary diagram of data enhancement;
FIG. 3 is a network constructed by training steps 3-6;
FIG. 4 is a network constructed by training steps 9-10;
FIG. 5 is a flow chart of the test of the present invention.
Detailed Description
The invention is further described below with reference to the accompanying drawings.
The training flow of the pedestrian re-identification method based on the local and channel combined features is shown in fig. 1. And firstly carrying out data enhancement on batch training samples, inputting the samples subjected to data enhancement into a convolution base network, and outputting a characteristic diagram. Performing two different operations on the feature map, wherein the first operation is to compress the feature map to obtain a global feature; the second method is to divide the channel into groups and cut horizontally to generate sub-feature map, and then compress the sub-feature map to obtain the local and channel combination features. Different loss functions are applied to the global characteristics and the local and channel combination characteristics, the derivation is carried out on the total loss function, and the network is optimized by utilizing a back propagation algorithm. And aligning the feature maps output by Res2Block in the optimized network through STN, and inputting the aligned feature maps into a new convolution network to obtain an output feature map. The aligned global features and local and channel combination features are obtained for the feature map in the same manner as above, and the same loss function is applied to optimize the new network again.
The method comprises the following specific steps:
a small batch of data contains P multiplied by K pictures, P pedestrians with different identities, and K pictures of each pedestrian. If the number of pictures of one pedestrian is more than K in the training set, randomly sampling K pictures; if the number of the pictures is less than K, all the pictures are sampled, and the sampling is not enough and repeated.
2-1, generating a picture Pool (Pool) capable of storing pictures with different resolutions;
2-2, before each picture is input into the network, it will be in p 1 And copying one small picture into Pool in a probability mode. Assuming that the resolution of a picture is H × W, the resolution of a small picture, i.e., a picture block, randomly falls within the interval [0.1H,0.2H ]]×[0.1W,0.2W]In between, the locations are also randomly selected.
2-3, then with p 2 And randomly selecting a picture block from Pool according to the probability to cover the picture, and randomly selecting the covered position.
using the ResNet-50 network pre-trained on the ImageNet dataset, the structure before the Global Average Pooling (GAP) Layer of the network is preserved and the step size of the last Convolutional Layer (Convolutional Layer) is set to 1, which is denoted as the Convolutional basis network. A picture with a resolution of 256 × 128 is input into the convolution base network to output a tensor eigenmap T with a size of 16 × 8 × 2048.
And 4, grouping the channels to obtain the characteristics of each group of channels:
dividing the tensor eigen map T with the size of 16 multiplied by 8 multiplied by 2048 obtained in the step 3 into 4 groups along the channel, wherein the size of the tensor eigen map of each group is 16 multiplied by 8 multiplied by 512 and is respectively marked as T 1 ,T 2 ,T 3 ,T 4 。
And 5, cutting the tensor characteristic diagram to obtain local characteristics:
each group of tensor characteristic map T obtained in the step 4 1 ,T 2 ,T 3 ,T 4 The image is equally divided into 4 local tensor eigenmaps along the horizontal direction, the size of each local tensor eigenmap is 4 multiplied by 8 multiplied by 512, and the local tensor eigenmaps are respectively marked as T 11 ~T 14 ,T 21 ~T 24 ,T 31 ~T 34 ,T 41 ~T 44 . T obtaining 16 local tensor eigenmaps T through steps 4 and 5 11 ~T 14 ,T 21 ~T 24 ,T 31 ~T 34 ,T 41 ~T 44 . Each local tensor eigenmap represents the combined features of different locations and different channels.
And 6, compressing the characteristic diagram:
and (3) convolving the tensor eigen map T, wherein the size of a convolution kernel is 16 multiplied by 8 multiplied by 512, the number of the convolution kernels is 512, and parameters are initialized randomly to obtain the global features g with the size of 1 multiplied by 512. Same pair T 11 ~T 14 ,T 21 ~T 24 ,T 31 ~T 34 ,T 41 ~T 44 Performing convolution respectively, wherein the convolution kernel size corresponding to each local tensor characteristic diagram is 4 multiplied by 8 multiplied by 512, the parameters are initialized randomly, the number is 512, and 16 local tensors with the size of 1 multiplied by 512 are obtainedChannel combination characteristic pc 1 ~pc 16 . The network N constructed in steps 3-6 is shown in fig. 3.
Step 7, applying different loss functions to different characteristics:
Combining features pc for local channels 1 ~pc 16 A Batch Hard sample Triplet Loss (Batch Hard Triplet Loss) was applied separately.
For example, for the characteristic pc 1 And the Batch Hard triple Loss is as follows:

for the global signature g, the Batch Hard Triplet Loss and the Softmax Loss are applied, respectively. The Batch Hard triple Loss is as follows:

the Softmax Loss is:

the overall loss function of the network is:

and 8, using a gradient descent algorithm to derive and reversely propagate the Loss function Loss in the step 7 to optimize learnable parameters in the N.
Step 9, aligning the feature graph by using a space transformation network:
9-1, outputting a characteristic diagram F from a 4 th Block (Res 4 Block) of the convolution base network in N 4 (three-dimensional tensor) obtaining a vector theta (theta) with the length of 6 through a residual connecting Block (Res Block, parameter random initialization) and a GAP layer 11 ,θ 12 ,θ 13 ,θ 21 ,θ 22 ,θ 23 ). Wherein theta is 11 ,θ 12 ,θ 21 ,θ 22 For scaling and rotating the characteristic map, theta 13 ,θ 23 For translating the feature map.
9-2, using theta 11 ,θ 12 ,θ 13 ,θ 21 ,θ 22 ,θ 23 Outputting a profile F for Block 2 (Res 2 Block) of a convolutional base network in N 2 (tensor with size of H multiplied by W multiplied by C) is affine transformed to obtain a blank feature map F " 2 . To F 2 For the eigen map (tensor of H × W size) of the channel c, the coordinate of the pixel point on the eigen map is (x) s ,y s ) After affine transformation becomes (x) t ,y t ) The relationship between the two is:

9-3, blank feature map F according to formula (12) " 2 From F 2 Filling the upper sampling pixel to obtain an aligned feature map F' 2 . In an affine process, F' will appear " 2 F corresponding to middle coordinate 2 Coordinate exceeds F 2 In the original range, the pixel value is set to 0 for these coordinates. Occurrence of F " 2 F corresponding to middle coordinate 2 When the coordinates are not pixel points, filling pixel values to the coordinates through bilinear interpolation:

step 10, processing the aligned characteristic graph:
for the aligned feature map F " 2 Inputting the data into a new convolutional network, wherein the new network is formed by stacking Res 3 Block, Res 4 Block and Res 5 Block in ResNet-50 network pre-trained on ImageNet data set, and outputting a feature map T with the same size as the feature map T in the step 3 align . For T align The same operations as in steps 3-6 were carried out to obtain 1 piece of the sameGlobal feature g align And 16 local and channel combination features Note that the network constructed in steps 9-10 is N align ,N align The convolutional code is composed of
Note that the network constructed in steps 9-10 is N align ,N align The convolutional code is composed of Res 1 Block, Res 2 Block, Res 3 Block, Res 4 Block and STN of a convolutional base network in N, Res 3 Block, Res 4 Block and Res 5 Block in a new convolutional network, and convolutional layers for compressing global features and local and channel combination features, and the specific structure is shown in FIG. 4. For global feature g align And local and channel combining features Optimizing N using the same loss function in step 7 align Of the parameter(s) to be learned.
Optimizing N using the same loss function in step 7 align Of the parameter(s) to be learned.
The testing flow of the pedestrian re-identification method based on the local and channel combination characteristics is shown in fig. 5. And inputting the pedestrian picture to be inquired and all the pedestrian pictures in the warehouse into a trained network, and respectively outputting pedestrian descriptors of the pedestrian pictures. And calculating cosine distances among the pedestrian descriptors, and selecting the front k warehouse pedestrian pictures corresponding to the minimum distance as re-identification results of the pedestrian pictures to be inquired. Whether the identity of the heavily recognized pedestrian is consistent with the identity of the pedestrian to be inquired or not is compared to judge the quality of the model.
The method comprises the following specific steps:


And 2, similarly obtaining the pedestrian descriptors of all the pictures in the warehouse through the step 1.
And 3, respectively calculating and storing the cosine distance between the pedestrian descriptor to be inquired and each pedestrian descriptor in the warehouse set.
And 4, sequencing the stored distances from small to large, and selecting the pedestrian pictures of the warehouse corresponding to the first k distances as the re-identification result of the pedestrian to be inquired.
Claims (2)
1. A pedestrian re-identification method based on local and channel combination features is characterized by comprising the following procedures:
firstly, a training process: training a neural network to obtain optimal network parameters; a sample in the training data set consists of a pedestrian picture x and a corresponding pedestrian identity ID (x), wherein the ID (x) belongs to { 1., C }; c represents the total number of the identities of the pedestrians, and the pedestrian with one identity has a plurality of pictures;
II, a test flow:
the test data set is divided into an inquiry set and a warehouse set, wherein the inquiry set comprises the pedestrian pictures with known identities, and the warehouse set comprises the pictures with the same identities as the pedestrians in the inquiry set and the pictures with different identities from the pedestrians in the inquiry set; the data set is constructed by firstly shooting pictures of pedestrians by monitoring cameras with non-overlapping view angles, then automatically marking a rectangular frame of the pedestrians by a pedestrian Detector (DPM), and finally keeping the pictures of the pedestrians in the rectangular frame and adding identity tags of the pedestrians, wherein the pictures of the same pedestrian in the query set and the warehouse set have different shooting view angles;
the training process comprises the following specific steps:
step 1, sampling samples in a training set to generate small-batch data:
the small batch of data comprises P multiplied by K pictures, namely P pedestrians with different identities, wherein each pedestrian has K pictures; if the number of pictures of one pedestrian is more than K in the training set, randomly sampling K pictures; if the number of the pictures is less than K, sampling all the pictures, and repeatedly sampling when the number of the pictures is insufficient;
Step 2, improving the anti-shielding capability of the model in a data enhancement mode:
2-1, generating a picture Pool capable of storing pictures with different resolutions;
2-2, before each picture is input into the network, it will be in p 1 Copying one small picture in probability and storing the small picture in Pool; assuming that the resolution of a picture is H × W, the resolution of a small picture, i.e., a picture block, randomly falls within the interval [0.1H,0.2H ]]×[0.1W,0.2W]Position is also randomly selected;
2-3, then with p 2 Randomly selecting a picture block from Pool according to the probability to cover the picture, and randomly selecting the covered position;
step 3, loading a pre-training network:
using the ResNet-50 network pre-trained on the ImageNet dataset, preserving the structure of the network before Global Average Pooling Global Average potential, GAP Layer, and setting the step size of the last Convolutional Layer conditional Layer to 1, which is denoted as "Convolutional basis network"; inputting a picture with the resolution of 256 multiplied by 128 into a convolution base network, and outputting a tensor eigen map T with the size of 16 multiplied by 8 multiplied by 2048;
and 4, grouping the channels to obtain the characteristics of each group of channels:
dividing the tensor eigen map T with the size of 16 multiplied by 8 multiplied by 2048 obtained in the step 3 into 4 groups along a channel, namely the last dimension, wherein the size of the tensor eigen map of each group is 16 multiplied by 8 multiplied by 512 and is respectively recorded as T 1 ,T 2 ,T 3 ,T 4 ;
Step 5, cutting the tensor characteristic diagram to obtain local characteristics:
each group of tensor characteristic map T obtained in the step 4 1 ,T 2 ,T 3 ,T 4 The image is equally divided into 4 local tensor eigenmaps along the horizontal direction, the size of each local tensor eigenmap is 4 multiplied by 8 multiplied by 512, and the local tensor eigenmaps are respectively marked as T 11 ~T 14 ,T 21 ~T 24 ,T 31 ~T 34 ,T 41 ~T 44 (ii) a T obtaining 16 local tensor eigenmaps T through steps 4 and 5 11 ~T 14 ,T 21 ~T 24 ,T 31 ~T 34 ,T 41 ~T 44 (ii) a Each local tensor feature map represents combined features of different positions and different channels;
and 6, compressing the characteristic diagram:
convolving the tensor eigen map T, wherein the size of convolution kernels is 16 multiplied by 8 multiplied by 512, the number of convolution kernels is 512, and parameters are initialized randomly to obtain global features g with the size of 1 multiplied by 512; same pair T 11 ~T 14 ,T 21 ~T 24 ,T 31 ~T 34 ,T 41 ~T 44 Performing convolution respectively, wherein the convolution kernel size corresponding to each local tensor eigenmap is 4 multiplied by 8 multiplied by 512, the number is 512, parameters are initialized randomly, and 16 local channel combined features pc with the size of 1 multiplied by 512 are obtained 1 ~pc 16 ;
Step 7, applying different loss functions to different characteristics:
combining features pc for local channels 1 ~pc 16 Applying Batch Hard sample triple Loss Batch Hard Triplet Loss:

in the formula (1), X represents the small batch of data obtained by sampling in the step 1, and theta represents the parameter of the network; representing that the ith pedestrian corresponds to the a picture in the K pictures,
representing that the ith pedestrian corresponds to the a picture in the K pictures,  Representing that the ith pedestrian corresponds to the p picture in the K pictures, and calling the p picture as a positive sample pair because the two pictures belong to the same pedestrian;
Representing that the ith pedestrian corresponds to the p picture in the K pictures, and calling the p picture as a positive sample pair because the two pictures belong to the same pedestrian; represents that the jth pedestrian corresponds to the nth picture in the K pictures because
represents that the jth pedestrian corresponds to the nth picture in the K pictures because And
And belonging to different pedestrians and called as a negative sample pair; f. of θ (x) Representing the characteristics output after the picture x is input into the network operation, and D (x, y) represents the Euclidean distance between the characteristics x and y; m is a constant that constrains the relationship between the two feature pairs distance, [ x ]] + Max (0, x); a picture of a pedestrian
belonging to different pedestrians and called as a negative sample pair; f. of θ (x) Representing the characteristics output after the picture x is input into the network operation, and D (x, y) represents the Euclidean distance between the characteristics x and y; m is a constant that constrains the relationship between the two feature pairs distance, [ x ]] + Max (0, x); a picture of a pedestrian In other words, traversing the pedestrian corresponds to each of the K pictures
In other words, traversing the pedestrian corresponds to each of the K pictures Find a particular
Find a particular So that
So that And
And the Euclidean distance between the two characteristics obtained after the input network operation is maximum respectively,
the Euclidean distance between the two characteristics obtained after the input network operation is maximum respectively, namely a positive and difficult sample pair; meanwhile, each picture of the other pedestrians is traversed, and (P-1) multiplied by K pictures are recorded
namely a positive and difficult sample pair; meanwhile, each picture of the other pedestrians is traversed, and (P-1) multiplied by K pictures are recorded Find a particular
Find a particular So that
So that And
And the Euclidean distance between two features obtained after the two features are respectively input into the network for operation is minimum,
the Euclidean distance between two features obtained after the two features are respectively input into the network for operation is minimum, the negative difficulty sample pair is obtained; the loss function finds out a positive difficulty sample pair and a negative difficulty sample pair corresponding to each picture of each pedestrian, and constrains the relationship between the characteristic distance of the positive difficulty sample pair and the characteristic distance of the negative difficulty sample pair;
the negative difficulty sample pair is obtained; the loss function finds out a positive difficulty sample pair and a negative difficulty sample pair corresponding to each picture of each pedestrian, and constrains the relationship between the characteristic distance of the positive difficulty sample pair and the characteristic distance of the negative difficulty sample pair;
For the feature pc 1 And the Batch Hard triple Loss is as follows:

in the formula (2) Representing features pc extracted from the a picture of the ith pedestrian 1 ,
Representing features pc extracted from the a picture of the ith pedestrian 1 , Representing features pc extracted from the p picture of the ith pedestrian 1 ,
Representing features pc extracted from the p picture of the ith pedestrian 1 , Representing features pc extracted from the nth picture of the jth pedestrian 1 ;
Representing features pc extracted from the nth picture of the jth pedestrian 1 ;
For the global feature g, respectively applying a Batch Hard triple Loss and a Softmax Loss; the Batch Hard triple Loss is as follows:

in formula (3) Represents from the ithThe feature g extracted from the a picture of the pedestrian,
Represents from the ithThe feature g extracted from the a picture of the pedestrian, representing the feature g extracted from the p picture of the ith pedestrian,
representing the feature g extracted from the p picture of the ith pedestrian, representing a feature g extracted from the nth picture of the jth pedestrian; before applying Softmax Loss, g needs to be input into a full Connected Layer, FC Layer; the number of output neurons of the full connection layer is the total number C of the pedestrian identities of the training set, and parameters of the full connection layer are initialized randomly; the Softmax Loss of the global feature g is:
representing a feature g extracted from the nth picture of the jth pedestrian; before applying Softmax Loss, g needs to be input into a full Connected Layer, FC Layer; the number of output neurons of the full connection layer is the total number C of the pedestrian identities of the training set, and parameters of the full connection layer are initialized randomly; the Softmax Loss of the global feature g is:

in formula (4) Representing a feature g extracted from the jth picture of the ith pedestrian,
Representing a feature g extracted from the jth picture of the ith pedestrian, representing the identity of the pedestrian corresponding to the picture;
representing the identity of the pedestrian corresponding to the picture; represents FC layer No
represents FC layer No Weight corresponding to each output neuron, W k Representing the weight corresponding to the k output neuron of the FC layer;
Weight corresponding to each output neuron, W k Representing the weight corresponding to the k output neuron of the FC layer;
the overall loss function of the network is:

In the formula (5)λ 1 ,λ 2 ,λ 3 For three lost weights, satisfy λ 1 +λ 2 +λ 3 =1;
Step 8, recording the network constructed in the step 3-6 as N; using a gradient descent algorithm, deriving the Loss function Loss in the step 7 and optimizing learnable parameters in the N through back propagation;
step 9, aligning the feature graph by using a space transformation network:
9-1, outputting a characteristic diagram F from a Res 4 Block of a 4 th Block of a convolutional base network in N 4 Obtaining a vector theta (theta) with the length of 6 through a residual error connecting block and a GAP layer 11 ,θ 12 ,θ 13 ,θ 21 ,θ 22 ,θ 23 ) (ii) a Wherein theta is 11 ,θ 12 ,θ 21 ,θ 22 For scaling and rotating the characteristic map, theta 13 ,θ 23 For translating the feature map;
9-2, using theta 11 ,θ 12 ,θ 13 ,θ 21 ,θ 22 ,θ 23 Outputting a characteristic diagram F to a Res 2Block 2 of a convolution base network in N 2 Affine transformation is carried out to obtain a blank feature map F' 2 (ii) a To F 2 For the feature map of channel c, the coordinate of the pixel point is (x) s ,y s ) After affine transformation becomes (x) t ,y t ) The relationship between the two is:

9-3, blank feature map F according to formula (6) " 2 From F 2 Filling up the up-sampling pixels to obtain an aligned characteristic diagram F 2 '; in an affine process, F' will appear " 2 F corresponding to middle coordinate 2 Coordinate exceeds F 2 In the original range, the pixel values of the coordinates are set to 0; occurrence of F " 2 F corresponding to middle coordinate 2 When the coordinates are not pixel points, filling pixel values to the coordinates through bilinear interpolation:

In the formula (7) Is F' 2 The pixel value of the (m, n) position on the c-channel of (c),
Is F' 2 The pixel value of the (m, n) position on the c-channel of (c), is F 2 C channel of (x) s ,y s ) A pixel value of the location;
is F 2 C channel of (x) s ,y s ) A pixel value of the location;
step 10, processing the aligned characteristic graph:
for aligned feature map F' 2 Inputting the data into a new convolution network, wherein the new convolution network is formed by stacking Res 3 Block, Res 4 Block and Res 5 Block in ResNet-50 network pre-trained on ImageNet data set, and outputting a feature map T with the same size as the feature map T in step 3 align (ii) a For T align The same operation as in step 3-6 is performed, and 1 global feature g is obtained align And 16 local and channel combination features Note that the network constructed in steps 9-10 is N align ,N align The system is composed of Res 1 Block, Res 2 Block, Res 3 Block, Res 4 Block and STN of a convolution base network in N, Res 3 Block, Res 4 Block and Res 5 Block in a new convolution network, and a convolution layer for compressing global characteristics and local and channel combination characteristics; for global feature g align And local and channel combination features
Note that the network constructed in steps 9-10 is N align ,N align The system is composed of Res 1 Block, Res 2 Block, Res 3 Block, Res 4 Block and STN of a convolution base network in N, Res 3 Block, Res 4 Block and Res 5 Block in a new convolution network, and a convolution layer for compressing global characteristics and local and channel combination characteristics; for global feature g align And local and channel combination features Optimizing N using the same loss function in step 7 align Of the parameter(s) to be learned.
Optimizing N using the same loss function in step 7 align Of the parameter(s) to be learned.
2. The pedestrian re-identification method based on the local and channel combined features as claimed in claim 1, wherein the testing process comprises the following steps:
Step 1, inputting a pedestrian picture to be inquired into N align G to be output align And connected to obtain the descriptor of the pedestrian
connected to obtain the descriptor of the pedestrian Is a 8704-dimensional feature vector;
Is a 8704-dimensional feature vector;
step 2, obtaining pedestrian descriptors of all the pictures in the warehouse set through the step 1;
step 3, respectively calculating and storing cosine distances between the pedestrian descriptors to be inquired and each pedestrian descriptor in the warehouse set;
4, sequencing the stored distances in the order from small to large, and selecting the pedestrian pictures of the warehouse corresponding to the front k distances as the re-identification result of the pedestrian to be inquired;
and 5, judging whether the real identity of the pedestrian picture of the warehouse obtained by the proportion recognition is consistent with the identity of the pedestrian to be inquired to measure the recognition performance of the model.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010460902.9A CN111709313B (en) | 2020-05-27 | 2020-05-27 | Pedestrian re-identification method based on local and channel combination characteristics |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010460902.9A CN111709313B (en) | 2020-05-27 | 2020-05-27 | Pedestrian re-identification method based on local and channel combination characteristics |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111709313A CN111709313A (en) | 2020-09-25 |
| CN111709313B true CN111709313B (en) | 2022-07-29 |
Family
ID=72537979
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010460902.9A Active CN111709313B (en) | 2020-05-27 | 2020-05-27 | Pedestrian re-identification method based on local and channel combination characteristics |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111709313B (en) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112232194A (en) * | 2020-10-15 | 2021-01-15 | 广州云从凯风科技有限公司 | Single-target human body key point detection method, system, equipment and medium |
| CN112686176B (en) * | 2020-12-30 | 2024-05-07 | 深圳云天励飞技术股份有限公司 | Target re-identification method, model training method, device, equipment and storage medium |
| CN113343909B (en) * | 2021-06-29 | 2023-09-26 | 南京星云数字技术有限公司 | Training method of multi-task classification network and pedestrian re-recognition method |
| CN113255615B (en) * | 2021-07-06 | 2021-09-28 | 南京视察者智能科技有限公司 | Pedestrian retrieval method and device for self-supervision learning |
| CN114170516B (en) * | 2021-12-09 | 2022-09-13 | 清华大学 | Vehicle weight recognition method and device based on roadside perception and electronic equipment |
| CN114299535B (en) * | 2021-12-09 | 2024-05-31 | 河北大学 | Transformer-based feature aggregation human body posture estimation method |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108009528A (en) * | 2017-12-26 | 2018-05-08 | 广州广电运通金融电子股份有限公司 | Face authentication method, device, computer equipment and storage medium based on Triplet Loss |
| CN108399362A (en) * | 2018-01-24 | 2018-08-14 | 中山大学 | A kind of rapid pedestrian detection method and device |
| CN109583379A (en) * | 2018-11-30 | 2019-04-05 | 常州大学 | A kind of pedestrian's recognition methods again being aligned network based on selective erasing pedestrian |
| CN110543817A (en) * | 2019-07-25 | 2019-12-06 | 北京大学 | Pedestrian re-identification method based on posture guidance feature learning |
| CN110659573A (en) * | 2019-08-22 | 2020-01-07 | 北京捷通华声科技股份有限公司 | Face recognition method and device, electronic equipment and storage medium |
-
2020
- 2020-05-27 CN CN202010460902.9A patent/CN111709313B/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108009528A (en) * | 2017-12-26 | 2018-05-08 | 广州广电运通金融电子股份有限公司 | Face authentication method, device, computer equipment and storage medium based on Triplet Loss |
| CN108399362A (en) * | 2018-01-24 | 2018-08-14 | 中山大学 | A kind of rapid pedestrian detection method and device |
| WO2019144575A1 (en) * | 2018-01-24 | 2019-08-01 | 中山大学 | Fast pedestrian detection method and device |
| CN109583379A (en) * | 2018-11-30 | 2019-04-05 | 常州大学 | A kind of pedestrian's recognition methods again being aligned network based on selective erasing pedestrian |
| CN110543817A (en) * | 2019-07-25 | 2019-12-06 | 北京大学 | Pedestrian re-identification method based on posture guidance feature learning |
| CN110659573A (en) * | 2019-08-22 | 2020-01-07 | 北京捷通华声科技股份有限公司 | Face recognition method and device, electronic equipment and storage medium |
Non-Patent Citations (1)
| Title |
|---|
| Combining multilevel feature extraction and multi-loss learning for person re-identification;Weilin Zhong 等;《Neurocomputing》;20191231;全文 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111709313A (en) | 2020-09-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111709313B (en) | Pedestrian re-identification method based on local and channel combination characteristics | |
| CN110443143B (en) | Multi-branch convolutional neural network fused remote sensing image scene classification method | |
| CN110348319B (en) | Face anti-counterfeiting method based on face depth information and edge image fusion | |
| Xie et al. | Multilevel cloud detection in remote sensing images based on deep learning | |
| CN112766158B (en) | Multi-task cascading type face shielding expression recognition method | |
| CN105138973B (en) | The method and apparatus of face authentication | |
| CN110209859B (en) | Method and device for recognizing places and training models of places and electronic equipment | |
| CN109145745B (en) | Face recognition method under shielding condition | |
| CN109359541A (en) | A kind of sketch face identification method based on depth migration study | |
| Yang et al. | A deep multiscale pyramid network enhanced with spatial–spectral residual attention for hyperspectral image change detection | |
| CN108154133B (en) | Face portrait-photo recognition method based on asymmetric joint learning | |
| CN113361495A (en) | Face image similarity calculation method, device, equipment and storage medium | |
| CN112580480B (en) | Hyperspectral remote sensing image classification method and device | |
| Mshir et al. | Signature recognition using machine learning | |
| CN106096517A (en) | A kind of face identification method based on low-rank matrix Yu eigenface | |
| CN108960142B (en) | Pedestrian re-identification method based on global feature loss function | |
| CN104715266B (en) | The image characteristic extracting method being combined based on SRC DP with LDA | |
| CN112329662B (en) | Multi-view saliency estimation method based on unsupervised learning | |
| CN115311502A (en) | Remote sensing image small sample scene classification method based on multi-scale double-flow architecture | |
| CN110852292B (en) | Sketch face recognition method based on cross-modal multi-task depth measurement learning | |
| CN107784284B (en) | Face recognition method and system | |
| CN111105436B (en) | Target tracking method, computer device and storage medium | |
| CN114882537A (en) | Finger new visual angle image generation method based on nerve radiation field | |
| CN114627424A (en) | Gait recognition method and system based on visual angle transformation | |
| CN114743257A (en) | Method for detecting and identifying image target behaviors |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |