CN111611933B - Information extraction method and system for document image - Google Patents
Information extraction method and system for document image Download PDFInfo
- Publication number
- CN111611933B CN111611933B CN202010441086.7A CN202010441086A CN111611933B CN 111611933 B CN111611933 B CN 111611933B CN 202010441086 A CN202010441086 A CN 202010441086A CN 111611933 B CN111611933 B CN 111611933B
- Authority
- CN
- China
- Prior art keywords
- character
- identified
- characters
- image
- text
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000605 extraction Methods 0.000 title claims abstract description 67
- 230000008447 perception Effects 0.000 claims abstract description 66
- 230000004044 response Effects 0.000 claims abstract description 59
- 238000013528 artificial neural network Methods 0.000 claims abstract description 40
- 238000000034 method Methods 0.000 claims abstract description 10
- 230000004927 fusion Effects 0.000 claims description 17
- 230000011218 segmentation Effects 0.000 claims description 16
- 238000010586 diagram Methods 0.000 claims description 6
- 238000009792 diffusion process Methods 0.000 claims description 6
- 238000013507 mapping Methods 0.000 claims description 3
- 238000001514 detection method Methods 0.000 description 7
- 239000011159 matrix material Substances 0.000 description 4
- 238000013527 convolutional neural network Methods 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 238000012549 training Methods 0.000 description 2
- 230000002238 attenuated effect Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/148—Segmentation of character regions
- G06V30/153—Segmentation of character regions using recognition of characters or words
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- General Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Computing Systems (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Evolutionary Biology (AREA)
- Character Discrimination (AREA)
- Image Analysis (AREA)
Abstract
The invention relates to an information extraction method and system of a document image, wherein the extraction method comprises the following steps: based on the full convolution neural network, obtaining a character perception response graph according to the document image to be identified; dividing the character perception response graph by adopting a watershed algorithm to obtain a plurality of divided images; character extraction is carried out on each segmented image through a connected domain extraction method, so that characters in each segmented image are obtained; based on a character recognition model of the deep neural network, recognizing each character, and determining the position information of each character; and merging the characters according to the position information to obtain the identification information of the image to be identified. The method comprises the steps of determining characters in each divided image of a document image to be recognized through a full convolution neural network, a watershed algorithm and a connected domain extraction method, and determining position information of each character based on a character recognition model of a deep neural network; and combining the characters according to the position information, so that the identification information of the image to be identified can be accurately obtained.
Description
Technical Field
The invention relates to the technical fields of image processing and text detection and recognition, in particular to an information extraction method and system of a document image.
Background
The character detection and recognition are an important technology, and have huge application value and wide application prospect, in particular to automatic recognition and input of document images. For example, the automatic identification and input of the document image can be directly applied to bill identification, report identification, identification card identification and input, automatic identification of a bank card number, business card identification and the like.
The existing text detection and recognition method based on deep learning is mostly aimed at detecting and recognizing character strings in scene images. Compared with scene text detection and recognition, the document image takes a text area as a main body part, the text density is high, and the text area has structural information. The direct adoption of the scene character string detection method can cause the problems of wrong division, uneven length, crossing text fields and the like of a character string detection result detection frame, and causes difficulties in document identification result processing and structured output.
Disclosure of Invention
In order to solve the above problems in the prior art, that is, to improve the accuracy of information extraction in document images, the present invention aims to provide a method and a system for extracting information of document images.
In order to solve the technical problems, the invention provides the following scheme:
an information extraction method of a document image, the extraction method comprising:
based on the full convolution neural network, obtaining a character perception response graph according to the document image to be identified;
dividing the character perception response graph by adopting a watershed algorithm to obtain a plurality of divided images;
character extraction is carried out on each segmented image through a connected domain extraction method, so that characters in each segmented image are obtained;
based on a character recognition model of the deep neural network, recognizing each character, and determining the position information of each character;
and merging the characters according to the position information to obtain the identification information of the image to be identified.
Optionally, the character perception response graph is an intensity graph with gradually decreasing intensity from the central position of the rectangular surrounding frame of the character to the edge position of the character.
Optionally, the full convolution neural network comprises a first feature extraction layer, a cross-layer feature fusion layer and an intensity perception prediction layer which are sequentially connected;
the method for obtaining the character perception response graph based on the full convolution neural network comprises the following steps of:
extracting features of the document image to be identified through the first feature extraction layer to obtain image features of different layers;
through the cross-layer feature fusion layer, the features of different layers are sequentially and automatically assigned with weights, combined in a weighting way, combined in a cascading way and fused in a feature way, and a multi-channel fusion feature image is obtained;
and mapping the multi-channel fusion characteristic image into a single-channel intensity image through an intensity perception prediction layer, wherein the single-channel intensity image is a character perception response image.
Optionally, the dividing the character perception response graph by adopting a watershed algorithm to obtain a divided image specifically includes:
performing binarization segmentation on the character perception response graph through a preset first threshold value to determine seed points;
performing binarization segmentation on the character perception response graph through a preset second threshold value, and determining all character areas in the character perception response graph;
and dividing each character area by adopting a seed point diffusion mode according to the seed points to obtain a divided image.
Optionally, the dividing the character perception response graph by adopting a watershed algorithm to obtain a divided image further includes:
dividing the text image to be recognized into a plurality of text fields to be recognized according to each character area, and determining the type attribute of each text field to be recognized.
Optionally, the merging the characters according to the position information to obtain the identification information of the image to be identified specifically includes:
for each text field to be identified,
according to the position information, ordering the characters in the text field to be identified in a top-down mode;
dividing the characters sequenced from top to bottom into different text lines according to the gaps among the characters;
sorting the characters in each text line from left to right according to the position information;
merging characters in each text line from left to right to obtain a recognition result of each text line;
combining the text line recognition results from top to bottom to obtain a character string;
and determining the identification information of the image to be identified according to the character strings of the text fields to be identified.
Optionally, the information extraction method further includes:
and storing the character strings of each text field to be identified under the corresponding type entry in the database according to the type attribute of the text field to be identified.
In order to solve the technical problems, the invention also provides the following scheme:
an information extraction system of a document image, the information extraction system comprising:
the determining unit is used for obtaining a character perception response diagram according to the document image to be identified based on the full convolution neural network;
the segmentation unit is used for segmenting the character perception response graph by adopting a watershed algorithm to obtain a plurality of segmented images;
the extraction unit is used for extracting characters from each divided image by a connected domain extraction method to obtain characters in each divided image;
the recognition unit is used for recognizing each character based on a character recognition model of the deep neural network and determining the position information of each character;
and the merging unit is used for merging the characters according to the position information to obtain the identification information of the image to be identified.
In order to solve the technical problems, the invention also provides the following scheme:
an information extraction system of a document image, comprising:
a processor; and
a memory arranged to store computer executable instructions that, when executed, cause the processor to:
based on the full convolution neural network, obtaining a character perception response graph according to the document image to be identified;
dividing the character perception response graph by adopting a watershed algorithm to obtain a plurality of divided images;
character extraction is carried out on each segmented image through a connected domain extraction method, so that characters in each segmented image are obtained;
based on a character recognition model of the deep neural network, recognizing each character, and determining the position information of each character;
and merging the characters according to the position information to obtain the identification information of the image to be identified.
In order to solve the technical problems, the invention also provides the following scheme:
a computer-readable storage medium storing one or more programs that, when executed by an electronic device comprising a plurality of application programs, cause the electronic device to:
based on the full convolution neural network, obtaining a character perception response graph according to the document image to be identified;
dividing the character perception response graph by adopting a watershed algorithm to obtain a plurality of divided images;
character extraction is carried out on each segmented image through a connected domain extraction method, so that characters in each segmented image are obtained;
based on a character recognition model of the deep neural network, recognizing each character, and determining the position information of each character;
and merging the characters according to the position information to obtain the identification information of the image to be identified.
According to the embodiment of the invention, the following technical effects are disclosed:
the method comprises the steps of determining characters in each divided image of a document image to be recognized through a full convolution neural network, a watershed algorithm and a connected domain extraction method, and determining position information of each character based on a character recognition model of a deep neural network; and combining the characters according to the position information, so that the identification information of the image to be identified can be accurately obtained.
Drawings
FIG. 1 is a flow chart of a method of information extraction of a document image of the present invention;
FIG. 2 is a schematic illustration of determining a character perception response map based on a full convolutional neural network;
FIG. 3 is a schematic diagram of a channel sensitive attention mechanism for cross-layer feature fusion;
fig. 4 is a schematic block diagram of an information extraction system of a document image of the present invention.
Symbol description:
the device comprises a determining unit-1, a dividing unit-2, an extracting unit-3, a recognizing unit-4 and a merging unit-5.
Detailed Description
Preferred embodiments of the present invention are described below with reference to the accompanying drawings. It should be understood by those skilled in the art that these embodiments are merely for explaining the technical principles of the present invention, and are not intended to limit the scope of the present invention.
The invention aims to provide an information extraction method of a document image, which is characterized in that characters in each divided image of the document image to be identified are determined through a full convolution neural network, a watershed algorithm and a connected domain extraction method, and the position information of each character is determined based on a character identification model of a deep neural network; and combining the characters according to the position information, so that the identification information of the image to be identified can be accurately obtained.
In order that the above-recited objects, features and advantages of the present invention will become more readily apparent, a more particular description of the invention will be rendered by reference to the appended drawings and appended detailed description.
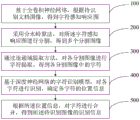
As shown in fig. 1, the information extraction method of the document image of the present invention includes:
step 100: based on the full convolution neural network, obtaining a character perception response graph according to the document image to be identified;
step 200: dividing the character perception response graph by adopting a watershed algorithm to obtain a plurality of divided images;
step 300: character extraction is carried out on each segmented image through a connected domain extraction method, so that characters in each segmented image are obtained;
step 400: based on a character recognition model of the deep neural network, recognizing each character, and determining the position information of each character;
step 500: and merging the characters according to the position information to obtain the identification information of the image to be identified.
The character perception response graph is an intensity graph with gradually reduced intensity from the central position of a rectangular surrounding frame of the character to the edge position of the character.
As shown in fig. 2, the full convolution neural network includes a first feature extraction layer, a cross-layer feature fusion layer and an intensity perception prediction layer connected in sequence.
In step 100, the obtaining a character perception response diagram based on the full convolution neural network according to the document image to be identified specifically includes:
step 110: and extracting the characteristics of the document image to be identified through the first characteristic extraction layer to obtain image characteristics of different layers.
The first feature extraction layer is a multi-layer convolutional neural network and is used for extracting image features of different layers.
Step 120: and through the cross-layer feature fusion layer, automatically distributing weights, weighting, combining in a cascading way and fusing the features of different layers in sequence to obtain a multi-channel fusion feature image.
The purpose of cross-layer feature fusion is to effectively fuse features of different layers, as shown in fig. 3, and the cross-layer feature fusion layer is to adopt a channel sensitive attention mechanism to process features of different layersThe rows are automatically assigned weights and combined by weighting. For two feature layers X to be fused 1 And X 2 ,X 1 The size of (2) is X 2 1/2 of (C). X is to be 2 Up-sampling by 2 times to obtain uninol 2 (X 2 ) Then with X 1 Performing cascade combination; then the number of channels is reduced by 1X 1 convolution to obtain the number of channels as 2 Weight matrix [ A ] of (2) 1 ,A 2 ]First channel A in weight matrix 1 For characteristic layer X 1 Weighting the second channel A in the weight matrix 2 To the feature layer Unpool 2 (X 2 ) Weighting is performed. And carrying out cascade combination on the weighted feature layers, and then carrying out feature fusion through 1X 1 convolution to obtain the fused features.
[A 1 ,A 2 ]=Conv 1×1 ([X 1 ;unpool 2 (X 2 )])
G=conv 1×1 ([A 1 *X 1 ;A 2 *unpool 2 (X 2 )]);
Wherein G is a feature map after feature fusion, operator [ ■; ■ And represents cascading along the feature channel, and the operator represents feature map and weight matrix dot product.
Step 130: and mapping the multi-channel fusion characteristic image into a single-channel intensity image through an intensity perception prediction layer, wherein the single-channel intensity image is a character perception response image.
The intensity perception prediction layer maps the multi-channel characteristic map into a single-channel intensity map. In this embodiment, the character perception response graph predicted by the deep neural network is an intensity graph with intensity gradually attenuated from the center position of the rectangular bounding box of the character to the edge position of the character, and in the training stage, training labels are generated by filling the text character bounding box with two-dimensional gaussian intensity distribution.
Optionally, in step 200, the segmenting the character perception response graph by using a watershed algorithm to obtain segmented images specifically includes:
step 210: performing binarization segmentation on the character perception response graph through a preset first threshold value to determine seed points;
step 220: performing binarization segmentation on the character perception response graph through a preset second threshold value, and determining all character areas in the character perception response graph;
step 230: and dividing each character area by adopting a seed point diffusion mode according to the seed points to obtain a divided image.
Wherein the first threshold is higher than the second threshold.
Preferably, the dividing the character perception response graph by adopting a watershed algorithm to obtain a divided image further includes:
dividing the text image to be recognized into a plurality of text fields to be recognized according to each character area, and determining the type attribute of each text field to be recognized.
In step 400, the character recognition model of the deep neural network includes a second feature extraction layer including a multi-layer convolutional neural network, a full connection layer, and a Softmax classification output layer.
In step 500, the merging the characters according to the position information to obtain the identification information of the image to be identified specifically includes:
step 510: aiming at each text field to be identified, ordering the characters in the text field to be identified in a top-to-bottom mode according to the position information;
step 520: dividing the characters sequenced from top to bottom into different text lines according to the gaps among the characters;
step 530: sorting the characters in each text line from left to right according to the position information;
step 540: merging characters in each text line from left to right to obtain a recognition result of each text line;
step 550: combining the text line recognition results from top to bottom to obtain a character string;
step 560: and determining the identification information of the image to be identified according to the character strings of the text fields to be identified.
Further, the information extraction method of the document image of the present invention further comprises:
and storing the character strings of each text field to be identified under the corresponding type entry in the database according to the type attribute of the text field to be identified.
The invention is suitable for identifying and inputting various document images, and can effectively improve the speed and accuracy of automatic identification of document type images.
In addition, the invention also provides an information extraction system of the document image, which can improve the accuracy of information extraction in the document image.
As shown in fig. 4, the information extraction system of the document image of the present invention includes a determination unit 1, a segmentation unit 2, an extraction unit 3, an identification unit 4, and a merging unit 5.
Specifically, the determining unit 1 is configured to obtain a character perception response diagram according to a document image to be identified based on a full convolution neural network;
the segmentation unit 2 is used for segmenting the character perception response graph by adopting a watershed algorithm to obtain a plurality of segmented images;
the extraction unit 3 is used for extracting characters from each divided image by a connected domain extraction method to obtain characters in each divided image;
the recognition unit 4 is used for recognizing each character based on a character recognition model of the deep neural network and determining the position information of each character;
the merging unit 5 is configured to merge characters according to the position information, so as to obtain identification information of the image to be identified.
In addition, the invention also provides an information extraction system of the document image, which comprises the following steps:
a processor; and
a memory arranged to store computer executable instructions that, when executed, cause the processor to:
based on the full convolution neural network, obtaining a character perception response graph according to the document image to be identified;
dividing the character perception response graph by adopting a watershed algorithm to obtain a plurality of divided images;
character extraction is carried out on each segmented image through a connected domain extraction method, so that characters in each segmented image are obtained;
based on a character recognition model of the deep neural network, recognizing each character, and determining the position information of each character;
and merging the characters according to the position information to obtain the identification information of the image to be identified.
Further, the present invention provides a computer-readable storage medium storing one or more programs that, when executed by an electronic device including a plurality of application programs, cause the electronic device to:
based on the full convolution neural network, obtaining a character perception response graph according to the document image to be identified;
dividing the character perception response graph by adopting a watershed algorithm to obtain a plurality of divided images;
character extraction is carried out on each segmented image through a connected domain extraction method, so that characters in each segmented image are obtained;
based on a character recognition model of the deep neural network, recognizing each character, and determining the position information of each character;
and merging the characters according to the position information to obtain the identification information of the image to be identified.
Compared with the prior art, the information extraction system and the computer readable storage medium of the document image have the same beneficial effects as the information extraction method of the document image, and are not repeated here.
Thus far, the technical solution of the present invention has been described in connection with the preferred embodiments shown in the drawings, but it is easily understood by those skilled in the art that the scope of protection of the present invention is not limited to these specific embodiments. Equivalent modifications and substitutions for related technical features may be made by those skilled in the art without departing from the principles of the present invention, and such modifications and substitutions will fall within the scope of the present invention.
Claims (7)
1. An information extraction method of a document image, characterized in that the extraction method comprises:
based on the full convolution neural network, obtaining a character perception response graph according to the document image to be identified;
dividing the character perception response graph by adopting a watershed algorithm to obtain a plurality of divided images:
performing binarization segmentation on the character perception response graph through a preset first threshold value to determine seed points;
performing binarization segmentation on the character perception response graph through a preset second threshold value, and determining all character areas in the character perception response graph;
dividing each character area by adopting a seed point diffusion mode according to the seed points to obtain a divided image;
further comprises: dividing the document image to be identified into a plurality of text fields to be identified according to each character area, and determining the type attribute of each text field to be identified;
character extraction is carried out on each segmented image through a connected domain extraction method, so that characters in each segmented image are obtained;
based on a character recognition model of the deep neural network, recognizing each character, and determining the position information of each character;
combining the characters according to the position information to obtain the identification information of the document image to be identified:
for each text field to be identified,
according to the position information, ordering the characters in the text field to be identified in a top-down mode;
dividing the characters sequenced from top to bottom into different text lines according to the gaps among the characters;
sorting the characters in each text line from left to right according to the position information;
merging characters in each text line from left to right to obtain a recognition result of each text line;
combining the text line recognition results from top to bottom to obtain a character string;
and determining the identification information of the document image to be identified according to the character strings of the text fields to be identified.
2. The method for extracting information from a document image according to claim 1, wherein the character perception response map is an intensity map in which intensity gradually decays from a center position of a rectangular surrounding frame of a character to an edge position of the character.
3. The method for extracting information from a document image according to claim 1, wherein the full convolution neural network comprises a first feature extraction layer, a cross-layer feature fusion layer and an intensity perception prediction layer which are sequentially connected;
the method for obtaining the character perception response graph based on the full convolution neural network comprises the following steps of:
extracting features of the document image to be identified through the first feature extraction layer to obtain image features of different layers;
through the cross-layer feature fusion layer, the features of different layers are sequentially and automatically assigned with weights, combined in a weighting way, combined in a cascading way and fused in a feature way, and a multi-channel fusion feature image is obtained;
and mapping the multi-channel fusion characteristic image into a single-channel intensity image through an intensity perception prediction layer, wherein the single-channel intensity image is a character perception response image.
4. The information extraction method of a document image according to claim 1, characterized in that the information extraction method further comprises:
and storing the character strings of each text field to be identified under the corresponding type entry in the database according to the type attribute of the text field to be identified.
5. An information extraction system of a document image, characterized by comprising:
the determining unit is used for obtaining a character perception response diagram according to the document image to be identified based on the full convolution neural network;
the segmentation unit is used for segmenting the character perception response graph by adopting a watershed algorithm to obtain a plurality of segmented images:
performing binarization segmentation on the character perception response graph through a preset first threshold value to determine seed points;
performing binarization segmentation on the character perception response graph through a preset second threshold value, and determining all character areas in the character perception response graph;
dividing each character area by adopting a seed point diffusion mode according to the seed points to obtain a divided image;
further comprises: dividing the document image to be identified into a plurality of text fields to be identified according to each character area, and determining the type attribute of each text field to be identified;
the extraction unit is used for extracting characters from each divided image by a connected domain extraction method to obtain characters in each divided image;
the recognition unit is used for recognizing each character based on a character recognition model of the deep neural network and determining the position information of each character;
the merging unit is used for merging the characters according to the position information to obtain the identification information of the document image to be identified:
for each text field to be identified,
according to the position information, ordering the characters in the text field to be identified in a top-down mode;
dividing the characters sequenced from top to bottom into different text lines according to the gaps among the characters;
sorting the characters in each text line from left to right according to the position information;
merging characters in each text line from left to right to obtain a recognition result of each text line;
combining the text line recognition results from top to bottom to obtain a character string;
and determining the identification information of the document image to be identified according to the character strings of the text fields to be identified.
6. An information extraction system of a document image, comprising:
a processor; and
a memory arranged to store computer executable instructions that, when executed, cause the processor to:
based on the full convolution neural network, obtaining a character perception response graph according to the document image to be identified;
dividing the character perception response graph by adopting a watershed algorithm to obtain a plurality of divided images:
performing binarization segmentation on the character perception response graph through a preset first threshold value to determine seed points;
performing binarization segmentation on the character perception response graph through a preset second threshold value, and determining all character areas in the character perception response graph;
dividing each character area by adopting a seed point diffusion mode according to the seed points to obtain a divided image;
further comprises: dividing the document image to be identified into a plurality of text fields to be identified according to each character area, and determining the type attribute of each text field to be identified;
character extraction is carried out on each segmented image through a connected domain extraction method, so that characters in each segmented image are obtained;
based on a character recognition model of the deep neural network, recognizing each character, and determining the position information of each character;
combining the characters according to the position information to obtain the identification information of the document image to be identified:
for each text field to be identified,
according to the position information, ordering the characters in the text field to be identified in a top-down mode;
dividing the characters sequenced from top to bottom into different text lines according to the gaps among the characters;
sorting the characters in each text line from left to right according to the position information;
merging characters in each text line from left to right to obtain a recognition result of each text line;
combining the text line recognition results from top to bottom to obtain a character string;
and determining the identification information of the document image to be identified according to the character strings of the text fields to be identified.
7. A computer-readable storage medium storing one or more programs that, when executed by an electronic device comprising a plurality of application programs, cause the electronic device to:
based on the full convolution neural network, obtaining a character perception response graph according to the document image to be identified;
dividing the character perception response graph by adopting a watershed algorithm to obtain a plurality of divided images:
performing binarization segmentation on the character perception response graph through a preset first threshold value to determine seed points;
performing binarization segmentation on the character perception response graph through a preset second threshold value, and determining all character areas in the character perception response graph;
dividing each character area by adopting a seed point diffusion mode according to the seed points to obtain a divided image;
further comprises: dividing the document image to be identified into a plurality of text fields to be identified according to each character area, and determining the type attribute of each text field to be identified;
character extraction is carried out on each segmented image through a connected domain extraction method, so that characters in each segmented image are obtained;
based on a character recognition model of the deep neural network, recognizing each character, and determining the position information of each character;
combining the characters according to the position information to obtain the identification information of the document image to be identified:
for each text field to be identified,
according to the position information, ordering the characters in the text field to be identified in a top-down mode;
dividing the characters sequenced from top to bottom into different text lines according to the gaps among the characters;
sorting the characters in each text line from left to right according to the position information;
merging characters in each text line from left to right to obtain a recognition result of each text line;
combining the text line recognition results from top to bottom to obtain a character string;
and determining the identification information of the document image to be identified according to the character strings of the text fields to be identified.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010441086.7A CN111611933B (en) | 2020-05-22 | 2020-05-22 | Information extraction method and system for document image |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010441086.7A CN111611933B (en) | 2020-05-22 | 2020-05-22 | Information extraction method and system for document image |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN111611933A CN111611933A (en) | 2020-09-01 |
| CN111611933B true CN111611933B (en) | 2023-07-14 |
Family
ID=72199241
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202010441086.7A Active CN111611933B (en) | 2020-05-22 | 2020-05-22 | Information extraction method and system for document image |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN111611933B (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112132150B (en) * | 2020-09-15 | 2024-05-28 | 上海高德威智能交通系统有限公司 | Text string recognition method and device and electronic equipment |
| CN112580655B (en) * | 2020-12-25 | 2021-10-08 | 特赞(上海)信息科技有限公司 | Text detection method and device based on improved CRAFT |
| CN113554549B (en) * | 2021-07-27 | 2024-03-29 | 深圳思谋信息科技有限公司 | Text image generation method, device, computer equipment and storage medium |
| CN113554027B (en) * | 2021-08-09 | 2024-10-15 | 深圳市迪博企业风险管理技术有限公司 | Method for calibrating and extracting reimbursement bill image text information |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106845475A (en) * | 2016-12-15 | 2017-06-13 | 西安电子科技大学 | Natural scene character detecting method based on connected domain |
| CN109117713A (en) * | 2018-06-27 | 2019-01-01 | 淮阴工学院 | A kind of drawing printed page analysis of full convolutional neural networks and character recognition method |
| WO2020010547A1 (en) * | 2018-07-11 | 2020-01-16 | 深圳前海达闼云端智能科技有限公司 | Character identification method and apparatus, and storage medium and electronic device |
-
2020
- 2020-05-22 CN CN202010441086.7A patent/CN111611933B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106845475A (en) * | 2016-12-15 | 2017-06-13 | 西安电子科技大学 | Natural scene character detecting method based on connected domain |
| CN109117713A (en) * | 2018-06-27 | 2019-01-01 | 淮阴工学院 | A kind of drawing printed page analysis of full convolutional neural networks and character recognition method |
| WO2020010547A1 (en) * | 2018-07-11 | 2020-01-16 | 深圳前海达闼云端智能科技有限公司 | Character identification method and apparatus, and storage medium and electronic device |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111611933A (en) | 2020-09-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111611933B (en) | Information extraction method and system for document image | |
| CN112200161B (en) | Face recognition detection method based on mixed attention mechanism | |
| CN113160192B (en) | Visual sense-based snow pressing vehicle appearance defect detection method and device under complex background | |
| CN108830188B (en) | Vehicle detection method based on deep learning | |
| CN110210475B (en) | License plate character image segmentation method based on non-binarization and edge detection | |
| CN103049763B (en) | Context-constraint-based target identification method | |
| CN111460927B (en) | Method for extracting structured information of house property evidence image | |
| CN114519819B (en) | Remote sensing image target detection method based on global context awareness | |
| CN110516676A (en) | A kind of bank's card number identifying system based on image procossing | |
| CN111242144A (en) | Method and device for detecting abnormality of power grid equipment | |
| CN113435319B (en) | Classification method combining multi-target tracking and pedestrian angle recognition | |
| CN113808123B (en) | Dynamic detection method for liquid medicine bag based on machine vision | |
| Li et al. | Pixel‐Level Recognition of Pavement Distresses Based on U‐Net | |
| CN110991447A (en) | Train number accurate positioning and identification method based on deep learning | |
| CN113609895A (en) | Road traffic information acquisition method based on improved Yolov3 | |
| Satti et al. | R‐ICTS: Recognize the Indian cautionary traffic signs in real‐time using an optimized adaptive boosting cascade classifier and a convolutional neural network | |
| Mei et al. | A conditional wasserstein generative adversarial network for pixel-level crack detection using video extracted images | |
| CN111680691B (en) | Text detection method, text detection device, electronic equipment and computer readable storage medium | |
| CN114078106B (en) | Defect detection method based on improved Faster R-CNN | |
| CN113989624A (en) | Infrared low-slow small target detection method and device, computing equipment and storage medium | |
| CN117437647B (en) | Oracle character detection method based on deep learning and computer vision | |
| CN114998689B (en) | Track data set generation method, track identification method and system | |
| CN104573663B (en) | A kind of English scene character recognition method based on distinctive stroke storehouse | |
| Wu et al. | Research on asphalt pavement disease detection based on improved YOLOv5s | |
| KR102026280B1 (en) | Method and system for scene text detection using deep learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |