CN110163057B - Object detection method, device, equipment and computer readable medium - Google Patents
Object detection method, device, equipment and computer readable medium Download PDFInfo
- Publication number
- CN110163057B CN110163057B CN201811273526.1A CN201811273526A CN110163057B CN 110163057 B CN110163057 B CN 110163057B CN 201811273526 A CN201811273526 A CN 201811273526A CN 110163057 B CN110163057 B CN 110163057B
- Authority
- CN
- China
- Prior art keywords
- convolution
- neural network
- semantic extraction
- feature image
- image
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/161—Detection; Localisation; Normalisation
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Evolutionary Computation (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Human Computer Interaction (AREA)
- Life Sciences & Earth Sciences (AREA)
- Image Analysis (AREA)
Abstract
A target detection method, apparatus, device and computer readable medium are disclosed. The method comprises the following steps: extracting an input feature image from an input image using a first convolutional neural network, wherein the input feature image has a size that is smaller than the size of the input image; performing convolution processing on the input feature image by using a second convolution neural network; and predicting the input characteristic image which is output by the second convolutional neural network and is subjected to convolutional processing by using a third convolutional neural network, and determining the position of the area where the target is positioned according to the prediction result output by the third convolutional neural network.
Description
Technical Field
The present disclosure relates to the field of image processing, and in particular, to a target detection method, apparatus, device, and computer readable medium for performing using convolutional neural networks.
Background
Deep learning-based methods are currently common target detection methods, such as two-stage methods like RCNN, fast-RCNN, or one-stage method SSD, YOLO, DSSD, SSH, etc. By the above-described general object detection method, objects of a plurality of categories, such as faces, can be detected. The position of the target is regressed and classified to obtain the category of the target, for example, by setting an "anchor" serving as a candidate region.
In use scenarios where only a single class of object detection is required, the detection of a particular object may be performed using a detector designed for the particular object (e.g., face detector MRCNN, S3FD, etc.).
However, the existing target detection models have the defects of low speed and large model. For example, the fast-CNN of the two-stage method runs at a speed of about 10 s/frame on a normal CPU. The one-stage method such as YOLO algorithm runs at a speed of about 2 s/frame on a normal CPU. In order to meet the real-time requirements of target detection, it is necessary to provide a faster target detection model.
Disclosure of Invention
To this end, the present disclosure provides a target detection method, apparatus, device, and computer readable medium that are performed using convolutional neural networks.
According to one aspect of the present disclosure, there is provided a target detection method including: extracting an input feature image from an input image using a first convolutional neural network, wherein the input feature image has a size that is smaller than the size of the input image; performing convolution processing on the input feature image by using a second convolution neural network; and predicting the input characteristic image which is output by the second convolutional neural network and is subjected to convolutional processing by using a third convolutional neural network, and determining the position of the area where the target is positioned according to the prediction result output by the third convolutional neural network.
In some embodiments, extracting the input feature image from the input image using the first convolutional neural network comprises: transforming an input image into a feature image using a first convolution layer, wherein the number of channels of the feature image is greater than the number of channels of the input image; pooling the characteristic images by using a first pooling layer to obtain pooled characteristic images; convolving the feature image with a second convolution layer to obtain a convolved feature image; splicing the pooled characteristic image and the convolved characteristic image by using a splicing layer; transforming the characteristic image output by the splicing layer into a characteristic image with a preset channel number by using a third convolution layer; and pooling the characteristic images with the preset channel number by utilizing a second pooling layer so as to obtain the input characteristic images.
In some embodiments, performing convolution processing on the input feature image using a second convolution neural network includes: convolving the input feature image with a cascade of a plurality of first semantic extraction neural networks, the convolving comprising, for each of the cascade of the plurality of first semantic extraction neural networks: performing multi-path convolution on the input features of the first semantic extraction neural network, wherein the sizes of receptive fields of the paths of convolution are different from each other; fusing the results of convolution output of each path by using addition operation; and outputting the fused convolution results of all paths as the output of the first semantic extraction neural network.
In some embodiments, at least one of the multiple convolutions comprises a depth separable convolution.
In some embodiments, performing convolution processing on the input feature image using a second convolution neural network further comprises: pooling the output of at least one of the cascaded plurality of first semantic extraction neural networks with a third pooling layer to obtain a smaller size feature image.
In some embodiments, the second convolutional neural network further comprises a second semantic extraction neural network, performing convolutional processing on the input feature image using the second convolutional neural network further comprises performing the following operations using the second semantic extraction neural network: performing multi-path convolution on the outputs of the cascaded first semantic extraction neural networks, wherein the sizes of receptive fields of the paths of convolution are different from each other, fusing the results of the outputs of the paths of convolution by using an addition operation, and outputting the fused results of the paths of convolution as the output of the second semantic extraction neural network, wherein at least one path of convolution in the second semantic extraction neural network comprises an expansion convolution.
In some embodiments, the target detection method further comprises: determining an output of at least one first semantic extraction neural network of the cascaded plurality of first semantic extraction neural networks and/or an output of the second semantic extraction neural network as a predicted feature image, wherein performing prediction on the feature image output by the second convolutional neural network using a third convolutional neural network comprises: and respectively executing prediction operation on the prediction feature images by using convolution layers with preset sizes so as to obtain the position offset of the region where the target is located relative to the candidate region and the confidence coefficient of the prediction operation as the prediction result.
In some embodiments, the candidate region is set by: for each prediction feature image, determining a region size of a candidate region for the prediction feature image; and determining, for each position point of the predicted feature image, a plurality of candidate regions having the region size overlapping each other in a graphics range with the position point as a center point.
According to another aspect of the present disclosure, there is also provided an object detection apparatus including: a first convolutional neural network configured to extract an input feature image from an input image, wherein a size of the input feature image is smaller than a size of the input image; a second convolutional neural network configured to perform convolutional processing on the input feature image; and a third convolutional neural network configured to perform prediction on the convolved input feature image output by the second convolutional neural network, and determine a position of an area where the target is located according to a prediction result output by the third convolutional neural network.
In some embodiments, the first convolutional neural network comprises: a first convolution layer configured to transform an input image into a feature image, wherein a number of channels of the feature image is greater than a number of channels of the input image; the first pooling layer is configured to pool the characteristic images to obtain pooled characteristic images; a second convolution layer configured to convolve the feature image to obtain a convolved feature image; a stitching layer configured to stitch the pooled feature image and the convolved feature image; the third convolution layer is configured to transform the characteristic image output by the splicing layer into a characteristic image with a preset channel number; and a second pooling layer configured to pool the feature images having a preset number of channels to obtain the input feature images.
In some embodiments, the second convolutional neural network comprises a cascade of a plurality of first semantic extraction neural networks, each of the cascade of the plurality of first semantic extraction neural networks configured to: performing multi-path convolution on the input features of the first semantic extraction neural network, wherein the sizes of receptive fields of the paths of convolution are different from each other; fusing the results of convolution output of each path by using addition operation; and outputting the fused convolution results of all paths as the output of the first semantic extraction neural network.
In some embodiments, at least one of the multiple convolutions comprises a depth separable convolution.
In some embodiments, the second convolutional neural network further comprises: and a third pooling layer configured to perform pooling on an output of at least one first semantic extraction neural network of the cascaded plurality of first semantic extraction neural networks to obtain a smaller-sized feature image.
In some embodiments, the second convolutional neural network further comprises a second semantic extraction neural network configured to: performing multi-path convolution on the outputs of the cascaded first semantic extraction neural networks, wherein the sizes of receptive fields of the paths of convolution are different from each other, fusing the results of the outputs of the paths of convolution by using an addition operation, and outputting the fused results of the paths of convolution as the output of the second semantic extraction neural network, wherein at least one path of convolution in the second semantic extraction neural network comprises an expansion convolution.
In some embodiments, the third convolutional neural network is further configured to: determining the output of at least one first semantic extraction neural network and/or the output of the second semantic extraction neural network in the cascade of the plurality of first semantic extraction neural networks as a prediction feature image, and respectively executing prediction operation on the prediction feature image by utilizing a convolution layer with a preset size to obtain the position offset of the region where the target is located relative to the candidate region and the confidence of the prediction operation as the prediction result.
In some embodiments, the candidate region is set by: for each prediction feature image, determining a region size of a candidate region for the prediction feature image; and determining, for each position point of the predicted feature image, a plurality of candidate regions having the region size overlapping each other in a graphics range with the position point as a center point.
According to another aspect of the present disclosure, there is also provided an object detection device comprising a processor and a memory, the memory having stored therein program instructions which, when executed by the processor, are configured to perform the object detection method as described above.
According to another aspect of the present disclosure, there is also provided a computer-readable storage medium having stored thereon instructions that, when executed by a processor, cause the processor to perform the object detection method as described above.
According to the target detection method, device, equipment and computer readable medium executed by using the convolutional neural network, the resolution of each characteristic layer in the network can be reduced by using a new network structure design mode so as to improve the operation speed of target detection. And the effect of target detection is improved on the premise of ensuring the operation speed by utilizing an effective network structure.
Drawings
In order to more clearly illustrate the technical solutions of the embodiments of the present disclosure, the drawings required for the description of the embodiments will be briefly introduced below, and it is obvious that the drawings in the following description are only some embodiments of the present disclosure, and other drawings may be obtained according to these drawings without making creative efforts to one of ordinary skill in the art. The following drawings are not intended to be drawn to scale on actual dimensions, emphasis instead being placed upon illustrating the principles of the disclosure.
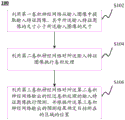
FIG. 1A shows a schematic flow chart of a target detection method according to an embodiment of the disclosure;
FIG. 1B illustrates a configuration of a candidate region according to an embodiment of the present disclosure;
FIG. 2 shows a schematic block diagram of an object detection device according to an embodiment of the present disclosure;
FIG. 3 shows a schematic flow chart of a method for extracting an input feature image according to an embodiment of the disclosure;
FIG. 4 shows a schematic block diagram of a first convolutional neural network, in accordance with an embodiment of the present disclosure;
FIG. 5 shows a schematic flow chart of an image processing procedure performed with a first semantic extraction neural network according to an embodiment of the present disclosure;
FIG. 6 illustrates a schematic block diagram of a first semantic extraction neural network according to an embodiment of the present disclosure;
FIG. 7 illustrates a schematic block diagram of a depth separable convolution according to an embodiment of the present disclosure;
FIG. 8 illustrates an exemplary flowchart of an image processing procedure performed using a second semantic extraction neural network according to an embodiment of the present disclosure;
FIG. 9 shows a schematic block diagram of a second semantic extraction neural network according to an embodiment of the present disclosure;
FIG. 10 illustrates an exemplary neural network structure for target detection, in accordance with the present disclosure; and
Fig. 11 illustrates an architecture of an exemplary computing device according to the present disclosure.
Detailed Description
To make the objects, technical solutions and advantages of the present disclosure more apparent, the present disclosure is further described in detail by the following examples. It will be apparent that the described embodiments are merely some, but not all embodiments of the present disclosure. Based on the embodiments in this disclosure, all other embodiments that a person of ordinary skill in the art would obtain without making any inventive effort are within the scope of protection of this disclosure.
As described above, the target detection method based on deep learning can be classified into a two-stage method and a one-stage method. In the two-stage method, the first stage is responsible for extracting from the image to be detected a plurality of "regions of interest", which are considered as regions that may contain targets, and are sent to the second stage. The second stage is responsible for accurately judging whether the regions of interest comprise targets and further obtaining detection results. The object is for example a human face. Hereinafter, an example targeting a face is described.
It can be seen that, since the two-stage method needs to extract the region of interest from the image to be detected first, especially when the number of faces in the image to be detected is large, the time consumption of two-stage calculation is greatly increased.
In the one-stage method, the final target detection result can be directly obtained through one-stage operation. Therefore, the calculation speed of the target detection method of the one-stage method has some advantages over the two-stage method.
However, as mentioned above, the calculation speed of currently used target detection algorithms such as fast-RCNN, YOLO, etc. still cannot meet the requirements of fast target detection, especially real-time target detection. For example, in a monitoring scene with a large amount of people, in order to ensure that the number of targets (such as the number of faces) to be detected is large because the image to be detected (such as the monitoring video image) changes rapidly, a new target detection algorithm needs to be designed, so that a faster target detection speed is realized on the basis of ensuring the target detection effect.
Fig. 1A shows a schematic flow chart of a target detection method according to an embodiment of the disclosure. As shown in fig. 1A, the target detection method 100 may include step S102. In step S102, an input image may be received and an input feature image may be extracted from the input image using a first convolutional neural network, wherein a size of the input feature image is smaller than a size of the input image. For example, the parameters of the first convolutional neural network may be set such that the size of the input feature image output by the first convolutional neural network is 1/4, 1/8, or less of the size of the input image. By rapidly reducing the size of the input feature image, the calculation amount of the system can be reduced in the subsequent processing.
In step S104, convolution processing may be performed on the input feature image using a second convolution neural network. The second convolutional neural network may include a plurality of convolutional layers and/or pooled layers connected in a specific structure, and may output a feature image representing semantic information of an input image by performing a convolutional process on the input feature image output from the first convolutional neural network. In some embodiments, the second convolutional neural network may include a cascade of a plurality of first semantic extraction neural networks and/or second semantic extraction neural networks.
In step S106, a third convolutional neural network may be used to perform prediction on the convolved input feature image output by the second convolutional neural network, and determine, according to the prediction result output by the third convolutional neural network, the position of the region where the target is located. In some embodiments, an output of at least one first semantic extraction neural network of the cascaded plurality of first semantic extraction neural networks and/or an output of the second semantic extraction neural network may be determined as a predictive feature image. The third convolutional neural network may be implemented as a convolutional layer of a preset size, e.g., 3×3, and performs prediction on the prediction feature images, respectively. By setting the convolutional layer parameters in the third convolutional neural network, the position offset of the region where the target is located in the third convolutional neural network relative to the candidate region can be used as the prediction result. In addition, the third convolutional neural network may also output a classification result of the target as a prediction result. For example, for a single type of object detection, such as face detection, the third convolutional neural network may output the confidence of the prediction operation as a classification result, i.e., the third convolutional neural network may output a result that the object obtained by the prediction operation belongs to a face or does not belong to a face. For target detection methods for detecting multiple types of targets, the confidence level of the third convolutional neural network output may indicate that the detected target belongs to a certain class or does not belong to any class detectable by the current target detection method.
In some embodiments, the candidate region may be determined by: for each prediction feature image, determining a region size of a candidate region for the prediction feature image; and determining, for each position point of the predicted feature image, a plurality of candidate regions having the region size overlapping each other in a graphics range with the position point as a center point. That is, taking a prediction feature image of a size of 12×16 as an example, a region size for a candidate region is set for each of 12×16 position points in the prediction feature image. For example, the region size of the candidate region may be set to 16, 32, 64, or 128. By predicting the prediction feature image by using a convolution layer with a preset size, the position offset of the region where the predicted target is located relative to the candidate region and the confidence of prediction can be output. When the object detection method provided in the present disclosure is used for face detection, the candidate region may be set to a square. When the object detection method provided in the present disclosure is used to detect other types of objects, the candidate regions may be set to rectangles of any other scale.
In some embodiments, one candidate region may be determined for each location point in the predicted feature image. In other embodiments, for each location point in the predicted feature image, multiple candidate regions that overlap each other may be determined. For example, as shown in fig. 1B, for the position point a, a candidate region 1 such as a square may be determined centering on a. Then, the candidate region 1 is divided into four small squares using the broken line shown in fig. 1B, and a square candidate region 2 is determined with the center B of the divided small squares as the midpoint. By using a similar method, four mutually overlapping candidate regions can be determined, respectively, with the center of the small square divided in the candidate region 1 as the midpoint. Only candidate region 2 is shown in fig. 1B. Although not shown, other candidate regions may be determined by one of ordinary skill in the art by the same method.
The candidate region determination method shown in fig. 1B may be used for a candidate region of size 16 or 32. In this case, since the candidate areas of sizes 16 and 32 are candidate areas for detecting a small-sized target, the number and density of candidate areas serving as references in the target detection method can be increased by the above-described method, and thus, it is advantageous to improve the detection effect of a small-sized target.
By utilizing the target detection method provided by the disclosure, the speed of target detection can be improved on the premise of ensuring the target detection effect by utilizing the convolutional neural network structure trained by the corresponding data set and through the effective neural network structure, and the rapid target detection effect is realized.
Fig. 2 shows a schematic block diagram of an object detection device according to an embodiment of the present disclosure. The object detection method shown in fig. 1A can be implemented using the object detection apparatus shown in fig. 2. As shown in fig. 2, the object detection device 200 may include a first convolutional neural network 210, which may be configured to receive an input image and extract an input feature image from the input image, wherein a size of the input feature image is smaller than a size of the input image. For example, the parameters of the first convolutional neural network may be set such that the size of the input feature image output by the first convolutional neural network is 1/4, 1/8, or less of the size of the input image.
The object detection device 200 may further include a second convolutional neural network 220, which may be configured to perform a convolutional process on the input feature image output by the first convolutional neural network. The second convolutional neural network may include a plurality of convolutional layers and/or pooled layers connected in a specific structure, and may output a feature image representing semantic information of an input image by performing a convolutional process on the input feature image output from the first convolutional neural network. In some embodiments, the second convolutional neural network may include a cascade of a plurality of first semantic extraction neural networks and/or second semantic extraction neural networks.
The object detection device 200 may further include a third convolutional neural network 230, which may be configured to perform prediction on the convolutionally processed input feature image output from the second convolutional neural network, and determine a position of an area where the object is located according to a prediction result output from the third convolutional neural network. In some embodiments, an output of at least one first semantic extraction neural network of the cascaded plurality of first semantic extraction neural networks and/or an output of the second semantic extraction neural network may be determined as a predictive feature image. The third convolutional neural network may be implemented as a convolutional layer of a preset size, e.g., 3×3, and performs prediction on the prediction feature images, respectively. By setting the convolutional layer parameters in the third convolutional neural network, the third convolutional neural network can output the position offset of the region where the target is located relative to the candidate region and the confidence of prediction as the prediction result.
The target detection apparatus 200 may be used for target detection for a specific purpose by training the target detection apparatus 200 with a corresponding data set and determining parameters of the first convolutional neural network 210, the second convolutional neural network 220, and the third convolutional neural network 230, respectively. For example, training the object detection apparatus 200 with a data set including a human face may enable the object detection apparatus 200 to have a function of human face detection.
In some embodiments, a loss function may be utilized The
The target detection apparatus 200 is trained. Where N is the number of candidate regions that match at a time. L (L) conf Representing the classification loss, L loc Indicating a loss of position.
The following is the position loss L loc Is defined by:

wherein I is ijk E {0,1}, when the degree of overlap IOU (Intersection-over-Union) of the kth candidate region at location (I, j) and the real data (ground trunk) is greater than a preset threshold (e.g., 0.7), I ijk Take the value of 1, otherwise I ijk The value is 0.W, H the size of the current feature image in length and width, and K represents the number of candidate regions for each position point of the current feature image.
(δx ijk ,δy ijk ,δw ijk ,δh ijk ) And representing the position offset of the region where the target output by the third neural network is located relative to the candidate region. Indicating the amount of positional shift of the real data (ground trunk) with respect to the candidate region.
Indicating the amount of positional shift of the real data (ground trunk) with respect to the candidate region.
Classification loss L conf The cross entropy loss (cross entropy loss) is defined as follows:

wherein I is ijk E {0,1}, when the degree of overlap IOU (Intersection-over-Union) of the kth candidate region at location (I, j) with the real data of all categories is greater than a preset threshold (e.g., 0.7), I ijk Take the value of 1, otherwise I ijk The value is 0.C represents a certain class of target detection.  When the overlapping degree IOU (Intersection-over-Union) of the kth candidate region at the position (i, j) and the real data of the category C is greater than a preset threshold (such as 0.7), y c G Take a value of 1, otherwise y c G The value is 0.P is p c The probability that the target belongs to class C in the prediction result is represented. W, H the size of the current feature image in length and width, and K represents the number of candidate regions for each position point of the current feature image.
When the overlapping degree IOU (Intersection-over-Union) of the kth candidate region at the position (i, j) and the real data of the category C is greater than a preset threshold (such as 0.7), y c G Take a value of 1, otherwise y c G The value is 0.P is p c The probability that the target belongs to class C in the prediction result is represented. W, H the size of the current feature image in length and width, and K represents the number of candidate regions for each position point of the current feature image.
The use of the loss function described above may be used to train the object detection device 200 with the data set and to determine parameters for the various convolutional layers in the object detection device 200.
The structure of the first convolutional neural network 210, the second convolutional neural network 220, and the third convolutional neural network 230, and their functions, will be further detailed below.
Fig. 3 shows a schematic flow chart of a method for extracting an input feature image according to an embodiment of the disclosure. As shown in fig. 3, the method 300 may include step S302, in which an input image may be transformed into a feature image using a first convolution layer, wherein the number of channels of the feature image is greater than the number of channels of the input image. For example, the input image may have three channels of RGB. The feature image obtained by the processing of the first convolution layer may have 32 channels. The input image may be transformed into a feature image through step S302.
Next, in step S304, the feature image obtained in step S302 may be pooled by using a first pooling layer to obtain a pooled feature image. In addition, in step S306, the feature image of step S302 may be convolved with a second convolution layer to obtain a convolved feature image. By appropriately setting the parameters of the first pooling layer and the second convolution layer, steps S304 and S306 can be caused to output feature images having the same size. In step S308, the feature images obtained in steps S304 and S306 may be stitched using a stitching layer. In step S310, the feature image output in step S308 may be transformed into a preset number of channels using a third convolution layer. In step S312, the feature image output in step S310 may be pooled by the second pooling layer, and an input feature image having a preset size may be obtained.
Fig. 4 shows a schematic block diagram of a first convolutional neural network, in accordance with an embodiment of the present disclosure. The feature image extraction method shown in fig. 3 may be performed using the first convolutional neural network shown in fig. 4. As shown in fig. 4, the first convolutional neural network 210 may include a first convolutional layer 211. In some embodiments, the first convolution layer 211 may be implemented as a convolution layer having a size of 3×3. For example, the first convolution layer 211 may be set as a convolution layer having a size of 3×3, a step size of 2, and a channel number of 32. The above steps and channel numbers are merely one possible example for implementing the principles of the present disclosure. In accordance with the principles of the present disclosure, one skilled in the art may also set the step size of the convolutional layers in the first convolutional layer as desired. For example, if it is desired to obtain a feature image of a smaller size, the step size of the convolution layers in the first convolution layer may be set to a value of 3 or more. For another example, if it is desired that the feature image output by the first convolution layer is the same size as the input image, the step size of the convolution layers in the first convolution layer 211 may be set to 1. In addition, the number of channels of the convolution layers in the first convolution layer may be set by those skilled in the art according to actual needs. For example, the number of channels may be set to 16, 64, or any other value.
With continued reference to fig. 4, the first convolutional neural network 210 may also include a second convolutional layer 212 and a first pooling layer 213. As shown in fig. 4, the second convolution layer 212 may include a concatenation of convolution layers 2121 and 2122, where the convolution layer 2121 may be 1×1 in size, the step size may be set to 1, and the number of channels may be set to 16. The size of the convolution layer 2122 may be 3×3, the step size may be set to 2, and the number of channels may be set to 32. As mentioned above, the parameters of each convolution layer in the second convolution layer 212 can be set by those skilled in the art according to actual needs, which will not be described herein. The pooling kernel size of the first pooling layer 213 may be 2×2 and the step size may be set to 2. In some embodiments, the first pooling layer 213 may be configured to perform maximum pooling, average pooling, or random pooling.
As shown in fig. 4, the first convolutional neural network 210 may also include a splice layer 214. In some embodiments, the splice layer may be implemented as a splice function concat. The results output by the second convolutional layer 212 and the first pooling layer 213 may be spliced using a splice function concat. In some examples, parameters of the second convolutional layer 212 and the first pooling layer 213 may be set such that the feature images output by the second convolutional layer 212 and the first pooling layer 213 have the same size in the dimensions of length H and width W, so that the two outputs may be spliced in the dimension of the channel number using a concat splice function. As shown in fig. 4, in the second convolution layer 212, the step size of the convolution layer 2121 is set to 1, and thus the size of the feature image input to the second convolution layer is not changed. The step size of the convolution layer 2122 is set to 2, and thus the size of the feature image can be reduced to 1/2 of the original dimension in the length H and width W, respectively. Thus, with the second convolution layer 212 as shown in fig. 4, the size of the feature image output thereof is half the size of the feature image input thereof in the dimensions of the length H and the width W, respectively. In the first pooling layer 213, the step size of the pooling kernel is set to 2, and thus the size of the output feature image of the first pooling layer is also half the size of the feature image input thereto in the dimensions of the length H and the width W, respectively. As can be seen, with the structure shown in fig. 4, the feature images output by the second convolution layer 212 and the first pooling layer 213 have the same size in the dimensions of the length H and the width W.
Further, as shown in fig. 4, the first convolutional neural network 210 may further include a third convolutional layer 215. In some embodiments, the third convolution layer 215 may be implemented as a convolution layer having a size of 1×1. For example, the third convolution layer 215 may be set to a convolution layer having a size of 1×1, a step size of 1, and a channel number of 32. With the third convolution layer 215, the number of channels of the feature image output by the stitching layer 214 can be changed to the number of channels of the convolution layers in the third convolution layer 215. Accordingly, one skilled in the art can determine the number of channels of the feature image output by the first convolutional neural network 210 by setting the number of channels of the convolutional layers in the third convolutional layer 215.
In some embodiments, the first convolutional neural network 210 may optionally further include a second pooling layer 216. The third pooling layer 216 may be configured to pool the feature images having the preset number of channels output from the third convolution layer 215 and obtain input feature images having a preset size. For example, the third pooling layer 216 may be implemented as a pooling kernel having a size of 2×2, and a step size is set to 2, thereby outputting a feature image having a further reduced size. In some embodiments, the third pooling layer 216 may be configured to perform maximum pooling, average pooling, or random pooling of the feature images output by the third convolution layer 215.
It will be appreciated that although one example of the first convolutional neural network 210 is shown in fig. 4, the scope of the present disclosure is not limited in this regard. The first convolutional neural network shown in fig. 4 may be modified by those skilled in the art according to the actual circumstances. For example, the size of each convolution layer in the first convolution neural network illustrated in fig. 4 may be adjusted, and for example, a convolution layer having a size of 3×3 may be adjusted to any size of 5×5, 7×7, or the like.
By using the first convolutional neural network provided by the present disclosure, features of an input image can be effectively extracted with a structure formed by a simple convolutional layer. The first convolutional neural network is simple in structure, so that the operation time consumption is low. In addition, the characteristic image with smaller size can be output by using the first convolution neural network, so that the required calculation amount in the subsequent convolution neural network structure is further reduced.
In some embodiments, step S104 in the object detection method 100 may include image processing the input feature image using a cascaded plurality of first semantic extraction neural networks. In other embodiments, step S104 may further include image processing the output of the cascaded plurality of first semantic extraction neural networks using the second semantic extraction neural network. Fig. 5 shows a schematic flow chart of an image processing procedure performed with a first semantic extraction neural network according to an embodiment of the present disclosure. As shown in fig. 5, for each of the plurality of first semantic extraction neural networks of the cascade, the image processing method 500 may include step S502, in which a multi-convolution may be performed on an input feature of the first semantic extraction neural network, wherein a receptive field size of each convolution is different from each other. Then, in step S504, the results of the convolution outputs of the respective paths may be fused by an addition operation. Further, in step S506, the result of the fused convolutions of each path may be output as an output of the first semantic extraction neural network.
Fig. 6 shows a schematic block diagram of a first semantic extraction neural network according to an embodiment of the present disclosure. The image processing procedure shown in fig. 5 can be implemented using the first semantic extraction neural network shown in fig. 6. As shown in fig. 6, a multi-path convolution structure is set in the first semantic extraction neural network, so as to implement different convolution processes on the input feature image of the first semantic extraction neural network. For example, in the first convolution 610, a convolution layer having a size of 1×1 is included. In the second convolution 620, a convolution layer of size 1 x 1 and a convolution layer of size 3 x 3 are included in cascade. In the third convolution 630, one convolution layer of size 1 x 1 and two convolution layers of size 3 x 3 are included in cascade. Because of the different convolution layer sizes and numbers of convolution layers in the multi-path convolution structure shown in fig. 6, the size of the receptive field for each path of convolution is different. Through convolution processing of different degrees, the first semantic extraction neural network can extract relatively low-level texture information and relatively high-level semantic information in the input characteristic image. For example, since the third convolution 630 includes more and larger-sized convolution layers, the feature image output by the third convolution 630 has more semantic information. In contrast, the number of convolution layers in the first convolution 610 is smaller and the size is smaller, so that the feature image output by the first convolution 610 has more texture information.
Furthermore, as shown in fig. 6, the first semantic extraction neural network further includes a 1×1 convolution layer. After the results of the convolution outputs are processed by the convolution layer of 1×1, an addition operation is performed with the input image of the first semantic extraction neural network. The addition operation can be used for merging the results of convolution output of each path in the first semantic extraction neural network. In this way, the first semantic extraction neural network can output the result of the convolution of each path fused, that is, the feature image fused with the texture information and the semantic information included in the feature image input thereto as the output of the first semantic extraction neural network.
In some embodiments, the convolution layer of size 3×3 shown in fig. 6 may take the form of a depth separable convolution. Fig. 7 shows a schematic block diagram of a depth separable convolution according to an embodiment of the present disclosure. As shown in fig. 7, the convolution of size 3 x 3 shown in fig. 6 may be implemented by one channel dimension convolution of size 3 x 3 (depthwise convolution) and one normal convolution of size 1 x 1. The convolution layer in which the channel dimensions are convolved has the same number of channels as the input features shown in fig. 7. In the process of channel dimension convolution, a convolution layer on each channel of the channel dimension convolution is used for respectively carrying out convolution processing on the characteristic images of the corresponding channel in the input characteristics. Then, fusion of the channel features is achieved using a common convolution of size 1 x 1. In this way, when the number of channels of the input feature is m and the number of channels of the output feature is n, the parameters required for processing by the normal convolution of 3×3 are 3×3×m×n, and the parameters required for processing by the depth separable convolution include only (3×3×m) + (mxn×1×1). Therefore, the calculation amount of the neural network structure can be greatly reduced by using the depth separable convolution instead of the normal convolution.
It will be appreciated that not only the depth-separable convolution illustrated in fig. 7 may be utilized to replace the 3 x 3 size convolution layer illustrated in fig. 6, but also any convolution layer provided in the present disclosure may be implemented in the form of a depth-separable convolution as desired by those skilled in the art to achieve the goal of substantially reducing the computational effort of the neural network structure.
Optionally, although not shown in fig. 6, the first semantic extraction neural network may further include a pooling layer that may be configured to perform pooling processing on the results of the fused path convolutions, thereby further reducing the size of the processed feature images.
It will be appreciated that although one example of a first semantic extraction neural network is shown in fig. 6, the scope of the present disclosure is not limited in this regard. The first semantic extraction neural network shown in fig. 6 may be modified by those skilled in the art according to the actual circumstances. For example, the size of each convolution layer in the first semantic extraction neural network illustrated in fig. 6 may be adjusted, and for example, a convolution layer having a size of 3×3 may be adjusted to any size of 5×5, 7×7, or the like.
Fig. 8 illustrates an exemplary flowchart of an image processing procedure performed using a second semantic extraction neural network according to an embodiment of the present disclosure.
In step S802, a multi-way convolution may be performed on the outputs of the cascaded plurality of first semantic extraction neural networks, wherein the receptive field sizes of the respective ways of convolution are different from each other.
In step S804, the results of the convolution outputs of the respective paths may be fused by an addition operation.
In step S806, the fused results of the convolutions of the paths may be output as an output of the second semantic extraction neural network.
Fig. 9 shows a schematic block diagram of a second semantic extraction neural network according to an embodiment of the present disclosure. The image processing procedure shown in fig. 8 can be implemented using the second semantic extraction neural network shown in fig. 9. As shown in fig. 9, a multi-path convolution structure is included in the second semantic extraction neural network. For example, as shown in fig. 9, in the leftmost convolution structure in fig. 9, the input features of the second semantic extraction neural network are processed by a convolution layer having a size of 3×3, a step size of 2, and a dilation rate of 1, and a convolution layer having a size of 1×1, a step size of 1, and a dilation rate of 1, respectively.
In the convolution structure of the second column from the left side in fig. 9, the input features of the second semantic extraction neural network are processed by one convolution layer of 3×3 in size, 2 in step size, 1 in expansion ratio, 1 in step size, 1 in expansion ratio, 3×3 in size, 1 in step size, 5 in expansion ratio, and 3×3 in size, 2 in step size, 1 in expansion ratio, respectively.
In the convolution structure of the third column from the left side in fig. 9, the input features of the second semantic extraction neural network are processed by one convolution layer of 3×3 in size, 2 in step size, 1 in expansion ratio, 1 in step size, 1 in expansion ratio, 3×3 in size, 1 in step size, 3 in expansion ratio, and 2 in step size, 1 in expansion ratio, respectively.
In the convolution structure of the second column from the right in fig. 9, the input features of the second semantic extraction neural network are processed by one convolution layer of size 3×3, step size 2, expansion ratio 1, one convolution layer of size 1×1, step size 1, expansion ratio 1, one convolution layer of size 1×3, step size 1, expansion ratio 1, one convolution layer of size 3×3, step size 1, expansion ratio 3, and one convolution layer of size 3×3, step size 2, expansion ratio 1, respectively.
In the convolution structure on the far right side in fig. 9, the input features of the second semantic extraction neural network are processed by a convolution layer having a size of 3×3, a step size of 2, and an expansion ratio of 1, a convolution layer having a size of 1×1, a step size of 1, and an expansion ratio of 1, a convolution layer having a size of 3×3, a step size of 1, and an expansion ratio of 1, and a convolution layer having a size of 3×3, a step size of 2, and an expansion ratio of 1, respectively.
Then, according to the second semantic extraction neural network shown in fig. 9, an addition operation may be performed using the addition unit 901 to fuse the results of the convolution outputs of the respective paths, and the fused results of the convolution of the respective paths may be taken as the output of the second semantic extraction neural network.
Similar to the first semantic extraction neural network, the second semantic extraction neural network shown in fig. 9 fuses the texture information included in the feature image input thereto and the feature image of the semantic information, thereby achieving a better detection effect.
In addition, the second semantic extraction neural network shown in fig. 9 employs an expansion convolution with a larger expansion rate (expansion rate). Those skilled in the art will appreciate that when the expansion ratio is greater than 1, the convolution layer has a larger receptive field than a normal convolution of the same size. Thus, the second semantic extraction neural network shown in fig. 9 can extract richer semantic information from the feature image. It should be noted that, in the scheme provided in the present disclosure, if no special description is given, the expansion ratio of the convolution layer is considered to be 1, that is, normal convolution.
It will be appreciated that although one example of a second semantic extraction neural network is shown in fig. 9, the scope of the present disclosure is not limited in this regard. The second semantic extraction neural network shown in fig. 9 can be modified by those skilled in the art according to the actual situation. For example, the size of each convolution layer in the second semantic extraction neural network illustrated in fig. 9 may be adjusted, and for example, a convolution layer having a size of 3×3 may be adjusted to any size of 5×5, 7×7, or the like.
Fig. 10 illustrates an exemplary neural network structure for target detection according to the present disclosure. As shown in fig. 10, an input image may be received using a first convolutional neural network as previously described and an input feature image may be extracted from the input image. The characteristic image output by the first convolutional neural network can then be convolved with the second convolutional neural network. As shown in fig. 10, the second convolutional neural network may include two first semantic extraction neural networks in cascade. Then, a pooling layer can be utilized to pool the feature images output by the two cascaded first semantic extraction neural networks, so that the size of the processed feature images is further reduced. The feature image may then be convolved with one first semantic extraction neural network and two second semantic extraction neural networks in cascade. Further, the results output by the two second semantic extraction neural networks and the last first semantic extraction neural network can be determined to be prediction feature images, prediction is respectively performed on each prediction feature image by using a third convolution neural network, and the position offset of the region where the target is located relative to the candidate region and the confidence of the prediction are respectively output as prediction results.
With the neural network architecture shown in fig. 10, the speed of target detection can be increased by a convolution method that quickly reduces the size of each feature layer of the network and saves parameters. An operation speed of 200fps on the GPU and 20fps on the CPU can be realized.
It is to be understood that what is shown in fig. 10 is merely one exemplary network structure in accordance with an embodiment of the present disclosure. Those skilled in the art can adjust the network structure in fig. 10 according to the actual situation. For example, the pooling layer in fig. 10 may be omitted, or added after either the first semantic extraction neural network or the second semantic extraction neural network in fig. 10. For another example, any one of the first semantic extraction neural networks in fig. 10 may be replaced with a second semantic extraction neural network, or any one of the second semantic extraction neural networks may be replaced with a first semantic extraction neural network. For another example, the number of prediction feature images may be increased or decreased. In fact, the output of any one unit selected from the three first semantic extraction neural networks and the two second semantic extraction neural networks shown in fig. 10 may be used as the prediction feature image.
By utilizing the target detection method and the target detection device provided by the disclosure, the input image can be processed through a simple and effective neural network structure, and the calculation amount of the target detection process can be saved under the condition that the effect of target detection is ensured by utilizing the method for reducing the size of the processed characteristic image and saving convolution parameters, so that real-time target detection becomes possible.
According to the principle of the present disclosure, the rapid target detection method provided by the present disclosure may be implemented by a GPU or a CPU, so as to perform rapid target detection on images and videos. For example, when the target detection method provided by the disclosure is applied to a portable electronic device (such as a mobile phone, a camera and the like), real-time face detection can be realized.
Furthermore, methods or apparatus according to embodiments of the present disclosure may also be implemented by way of the architecture of the computing device shown in fig. 11. Fig. 11 illustrates an architecture of the computing device. As shown in fig. 11, computing device 1100 may include a bus 1110, one or more CPUs 1120, a Read Only Memory (ROM) 1130, a Random Access Memory (RAM) 1140, a communication port 1150 connected to a network, an input/output component 1160, a hard disk 1170, and the like. A storage device in computing device 1100, such as ROM 1130 or hard disk 1170, may store various data or files for processing and/or communication use of the image processing method provided by the present disclosure, as well as program instructions executed by the CPU. Computing device 1100 can also include a user interface 1180. Of course, the architecture shown in FIG. 11 is merely exemplary, and one or more components of the computing device shown in FIG. 11 may be omitted as may be practical in implementing different devices.
Embodiments of the present disclosure may also be implemented as a computer-readable storage medium. Computer readable storage media according to embodiments of the present disclosure have computer readable instructions stored thereon. When executed by a processor, may perform a method according to embodiments of the present disclosure described with reference to the above figures. The computer-readable storage medium includes, but is not limited to, for example, volatile memory and/or nonvolatile memory. The volatile memory may include, for example, random Access Memory (RAM) and/or cache memory (cache), and the like. The non-volatile memory may include, for example, read Only Memory (ROM), hard disk, flash memory, and the like.
Those skilled in the art will appreciate that various modifications and improvements can be made to the disclosure. For example, the various devices or components described above may be implemented in hardware, or may be implemented in software, firmware, or a combination of some or all of the three.
Furthermore, as shown in the present disclosure and claims, unless the context clearly indicates otherwise, the words "a," "an," "the," and/or "the" are not specific to the singular, but may include the plural. In general, the terms "comprises" and "comprising" merely indicate that the steps and elements are explicitly identified, and they do not constitute an exclusive list, as other steps or elements may be included in a method or apparatus.
Further, while the present disclosure makes various references to certain elements in a system according to embodiments of the present disclosure, any number of different elements may be used and run on a client and/or server. The units are merely illustrative and different aspects of the systems and methods may use different units.
Further, a flowchart is used in this disclosure to describe the operations performed by the system according to embodiments of the present disclosure. It should be understood that the preceding or following operations are not necessarily performed in order precisely. Rather, the various steps may be processed in reverse order or simultaneously. Also, other operations may be added to or removed from these processes.
Unless otherwise defined, all terms (including technical and scientific terms) used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. It will be further understood that terms, such as those defined in commonly used dictionaries, should be interpreted as having a meaning that is consistent with their meaning in the context of the relevant art and will not be interpreted in an idealized or overly formal sense unless expressly so defined herein.
The foregoing is illustrative of the present invention and is not to be construed as limiting thereof. Although a few exemplary embodiments of this invention have been described, those skilled in the art will readily appreciate that many modifications are possible in the exemplary embodiments without materially departing from the novel teachings and advantages of this invention. Accordingly, all such modifications are intended to be included within the scope of this invention as defined in the following claims. It is to be understood that the foregoing is illustrative of the present invention and is not to be construed as limited to the specific embodiments disclosed, and that modifications to the disclosed embodiments, as well as other embodiments, are intended to be included within the scope of the appended claims. The invention is defined by the claims and their equivalents.
Claims (15)
1. A target detection method comprising:
extracting an input feature image from an input image using a first convolutional neural network, wherein the input feature image has a size that is smaller than the size of the input image;
performing convolution processing on the input feature image by using a second convolution neural network, wherein the second convolution neural network comprises a plurality of cascaded first semantic extraction neural networks and further comprises a second semantic extraction neural network, wherein a multi-path convolution structure with different receptive field sizes is arranged in each first semantic extraction neural network, so as to perform different convolution processing on the input feature image of the first semantic extraction neural network, fusion is performed on the results of the different convolution processing, the fused results are used as output of the first semantic extraction neural network, and the second semantic extraction neural network performs multi-path convolution with different receptive field sizes on the output of the plurality of cascaded first semantic extraction neural networks; and
And predicting the input characteristic image which is output by the second convolutional neural network and is subjected to convolutional processing by using a third convolutional neural network, and determining the position of the area where the target is positioned according to the prediction result output by the third convolutional neural network.
2. The object detection method according to claim 1, wherein extracting the input feature image from the input image using the first convolutional neural network comprises:
transforming an input image into a feature image using a first convolution layer, wherein the number of channels of the feature image is greater than the number of channels of the input image;
pooling the characteristic images by using a first pooling layer to obtain pooled characteristic images;
convolving the feature image with a second convolution layer to obtain a convolved feature image;
splicing the pooled characteristic image and the convolved characteristic image by using a splicing layer;
transforming the characteristic image output by the splicing layer into a characteristic image with a preset channel number by using a third convolution layer; and
and pooling the characteristic images with the preset channel number by using a second pooling layer so as to obtain the input characteristic images.
3. The object detection method according to claim 1, wherein performing convolution processing on the input feature image using a second convolution neural network comprises: convolving the input feature image with a cascade of first semantic extraction neural networks,
For each of the concatenated plurality of first semantic extraction neural networks, the convolution process includes:
performing multi-path convolution on the input features of the first semantic extraction neural network, wherein the sizes of receptive fields of the paths of convolution are different from each other;
fusing the results of convolution output of each path by using addition operation; and
and outputting the fused convolution results of all paths as the output of the first semantic extraction neural network.
4. The target detection method of claim 3, wherein at least one of the multiple convolutions comprises a depth separable convolution.
5. The object detection method according to claim 4, wherein performing convolution processing on the input feature image using a second convolution neural network further comprises: pooling the output of at least one of the cascaded plurality of first semantic extraction neural networks with a third pooling layer to obtain a smaller size feature image.
6. The method for detecting a target according to any one of claims 3 to 5, wherein,
performing convolution processing on the input feature image using a second convolution neural network further includes performing the following operations using a second semantic extraction neural network:
Performing a multi-convolution on the outputs of the cascade of first semantic extraction neural networks, wherein the receptive field sizes of the convolutions of each pass are different from each other,
fusion of the results of convolutionally output paths by addition operations
Outputting the fused convolution results of the paths as the output of the second semantic extraction neural network,
wherein at least one convolution in the second semantic extraction neural network comprises an expanded convolution.
7. The target detection method according to claim 6, further comprising:
determining an output of at least one first semantic extraction neural network of the cascaded plurality of first semantic extraction neural networks and/or an output of the second semantic extraction neural network as a predictive feature image,
wherein performing prediction on the feature image output by the second convolutional neural network using a third convolutional neural network comprises: and respectively executing prediction operation on the prediction feature images by using convolution layers with preset sizes so as to obtain the position offset of the region where the target is located relative to the candidate region and the confidence coefficient of the prediction operation as the prediction result.
8. The object detection method according to claim 7, wherein the candidate region is set by:
For each prediction feature image, determining a region size of a candidate region for the prediction feature image; and
for each position point of the predicted feature image, a plurality of candidate regions having the region size overlapping each other in a graphics range with the position point as a center point are determined.
9. An object detection apparatus comprising:
a first convolutional neural network configured to extract an input feature image from an input image, wherein a size of the input feature image is smaller than a size of the input image;
a second convolution neural network configured to perform convolution processing on the input feature image, wherein the second convolution neural network includes a plurality of first semantic extraction neural networks in cascade, and further includes a second semantic extraction neural network, wherein a multi-path convolution structure having different receptive field sizes is provided in each of the first semantic extraction neural networks for performing different convolution processing on the input feature image of the first semantic extraction neural network, fusing results of the different convolution processing, and taking the fused results as outputs of the first semantic extraction neural network, and the second semantic extraction neural network performs multi-path convolution having different receptive field sizes on the outputs of the plurality of first semantic extraction neural networks in cascade; and
And the third convolution neural network is configured to execute prediction on the input characteristic image which is output by the second convolution neural network and is subjected to convolution processing, and the position of the area where the target is located is determined according to the prediction result output by the third convolution neural network.
10. The object detection device of claim 9, wherein the first convolutional neural network comprises:
a first convolution layer configured to transform an input image into a feature image, wherein a number of channels of the feature image is greater than a number of channels of the input image;
the first pooling layer is configured to pool the characteristic images to obtain pooled characteristic images;
a second convolution layer configured to convolve the feature image to obtain a convolved feature image;
a stitching layer configured to stitch the pooled feature image and the convolved feature image;
the third convolution layer is configured to transform the characteristic image output by the splicing layer into a characteristic image with a preset channel number; and
and the second pooling layer is configured to pool the characteristic images with the preset channel number so as to obtain the input characteristic images.
11. The object detection apparatus according to claim 9, wherein each of the cascaded plurality of first semantic extraction neural networks is configured to:
Performing multi-path convolution on the input features of the first semantic extraction neural network, wherein the sizes of receptive fields of the paths of convolution are different from each other;
fusing the results of convolution output of each path by using addition operation; and
and outputting the fused convolution results of all paths as the output of the first semantic extraction neural network.
12. The object detection device of claim 11, wherein at least one of the multiple convolutions comprises a depth separable convolution.
13. The object detection device of claim 12, wherein the second convolutional neural network further comprises: and a third pooling layer configured to perform pooling on an output of at least one first semantic extraction neural network of the cascaded plurality of first semantic extraction neural networks to obtain a smaller-sized feature image.
14. The object detection apparatus according to any one of claims 11-13, wherein the second semantic extraction neural network is configured to:
performing a multi-convolution on the outputs of the cascade of first semantic extraction neural networks, wherein the receptive field sizes of the convolutions of each pass are different from each other,
fusion of the results of convolutionally output paths by addition operations
Outputting the fused convolution results of the paths as the output of the second semantic extraction neural network,
Wherein at least one convolution in the second semantic extraction neural network comprises an expanded convolution.
15. A computer readable storage medium having stored thereon instructions which, when executed by a processor, cause the processor to perform the object detection method according to any of claims 1-8.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811273526.1A CN110163057B (en) | 2018-10-29 | 2018-10-29 | Object detection method, device, equipment and computer readable medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201811273526.1A CN110163057B (en) | 2018-10-29 | 2018-10-29 | Object detection method, device, equipment and computer readable medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN110163057A CN110163057A (en) | 2019-08-23 |
| CN110163057B true CN110163057B (en) | 2023-06-09 |
Family
ID=67645274
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201811273526.1A Active CN110163057B (en) | 2018-10-29 | 2018-10-29 | Object detection method, device, equipment and computer readable medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN110163057B (en) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110717451B (en) * | 2019-10-10 | 2022-07-08 | 电子科技大学 | Medicinal plant leaf disease image identification method based on deep learning |
| CN110838125B (en) * | 2019-11-08 | 2024-03-19 | 腾讯医疗健康(深圳)有限公司 | Target detection method, device, equipment and storage medium for medical image |
| CN111950342A (en) * | 2020-06-22 | 2020-11-17 | 广州杰赛科技股份有限公司 | Face detection method, device and storage medium |
| CN111768397B (en) * | 2020-07-01 | 2023-01-20 | 创新奇智(重庆)科技有限公司 | Freeze-storage tube distribution condition detection method and device, electronic equipment and storage medium |
| CN112184641A (en) * | 2020-09-15 | 2021-01-05 | 佛山中纺联检验技术服务有限公司 | Small target object detection method |
| CN113065575A (en) * | 2021-02-27 | 2021-07-02 | 华为技术有限公司 | Image processing method and related device |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107644209A (en) * | 2017-09-21 | 2018-01-30 | 百度在线网络技术(北京)有限公司 | Method for detecting human face and device |
| CN107862261A (en) * | 2017-10-25 | 2018-03-30 | 天津大学 | Image people counting method based on multiple dimensioned convolutional neural networks |
| CN108021923A (en) * | 2017-12-07 | 2018-05-11 | 维森软件技术(上海)有限公司 | A kind of image characteristic extracting method for deep neural network |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10657424B2 (en) * | 2016-12-07 | 2020-05-19 | Samsung Electronics Co., Ltd. | Target detection method and apparatus |
| CN106845529B (en) * | 2016-12-30 | 2020-10-27 | 北京柏惠维康科技有限公司 | Image feature identification method based on multi-view convolution neural network |
| CN110298266B (en) * | 2019-06-10 | 2023-06-06 | 天津大学 | Deep neural network target detection method based on multiscale receptive field feature fusion |
-
2018
- 2018-10-29 CN CN201811273526.1A patent/CN110163057B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107644209A (en) * | 2017-09-21 | 2018-01-30 | 百度在线网络技术(北京)有限公司 | Method for detecting human face and device |
| CN107862261A (en) * | 2017-10-25 | 2018-03-30 | 天津大学 | Image people counting method based on multiple dimensioned convolutional neural networks |
| CN108021923A (en) * | 2017-12-07 | 2018-05-11 | 维森软件技术(上海)有限公司 | A kind of image characteristic extracting method for deep neural network |
Also Published As
| Publication number | Publication date |
|---|---|
| CN110163057A (en) | 2019-08-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110163057B (en) | Object detection method, device, equipment and computer readable medium | |
| US11062123B2 (en) | Method, terminal, and storage medium for tracking facial critical area | |
| US10872262B2 (en) | Information processing apparatus and information processing method for detecting position of object | |
| US11475681B2 (en) | Image processing method, apparatus, electronic device and computer readable storage medium | |
| CN113850829B (en) | Video shot segmentation method and device based on efficient depth network and related components | |
| CN112232300B (en) | Global occlusion self-adaptive pedestrian training/identifying method, system, equipment and medium | |
| CN111242125B (en) | Natural scene image text detection method, storage medium and terminal equipment | |
| CN109977832B (en) | Image processing method, device and storage medium | |
| CN112668522B (en) | Human body key point and human body mask joint detection network and method | |
| CN114708437B (en) | Training method of target detection model, target detection method, device and medium | |
| CN110991310A (en) | Portrait detection method, portrait detection device, electronic equipment and computer readable medium | |
| Luo et al. | A lightweight face detector by integrating the convolutional neural network with the image pyramid | |
| CN110991412A (en) | Face recognition method and device, storage medium and electronic equipment | |
| CN114022748B (en) | Target identification method, device, equipment and storage medium | |
| CN113762220B (en) | Object recognition method, electronic device, and computer-readable storage medium | |
| CN113221842B (en) | Model training method, image recognition method, device, equipment and medium | |
| CN110969640A (en) | Video image segmentation method, terminal device and computer-readable storage medium | |
| CN116258873A (en) | Position information determining method, training method and device of object recognition model | |
| CN115937121A (en) | Non-reference image quality evaluation method and system based on multi-dimensional feature fusion | |
| CN113821689A (en) | Pedestrian retrieval method and device based on video sequence and electronic equipment | |
| CN113723375A (en) | Double-frame face tracking method and system based on feature extraction | |
| CN113743219A (en) | Moving object detection method and device, electronic equipment and storage medium | |
| TWI699993B (en) | Region of interest recognition | |
| CN113971671A (en) | Instance partitioning method, instance partitioning device, electronic equipment and storage medium | |
| CN116091971A (en) | Target object matching method, device, computer equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |