CN109033978B - Error correction strategy-based CNN-SVM hybrid model gesture recognition method - Google Patents
Error correction strategy-based CNN-SVM hybrid model gesture recognition method Download PDFInfo
- Publication number
- CN109033978B CN109033978B CN201810684333.9A CN201810684333A CN109033978B CN 109033978 B CN109033978 B CN 109033978B CN 201810684333 A CN201810684333 A CN 201810684333A CN 109033978 B CN109033978 B CN 109033978B
- Authority
- CN
- China
- Prior art keywords
- cnn
- error correction
- svm
- classification
- training
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 55
- 238000012937 correction Methods 0.000 title claims abstract description 36
- 238000007781 pre-processing Methods 0.000 claims abstract description 13
- 230000003068 static effect Effects 0.000 claims abstract description 11
- 238000012549 training Methods 0.000 claims description 44
- 238000012360 testing method Methods 0.000 claims description 33
- 238000002474 experimental method Methods 0.000 claims description 12
- 230000008569 process Effects 0.000 claims description 12
- 230000011218 segmentation Effects 0.000 claims description 11
- 238000000605 extraction Methods 0.000 claims description 10
- 239000013598 vector Substances 0.000 claims description 9
- 239000011159 matrix material Substances 0.000 claims description 8
- 238000012545 processing Methods 0.000 claims description 5
- 238000012216 screening Methods 0.000 claims description 2
- 230000003993 interaction Effects 0.000 abstract description 8
- 238000013527 convolutional neural network Methods 0.000 description 31
- 241000282414 Homo sapiens Species 0.000 description 15
- 238000012706 support-vector machine Methods 0.000 description 10
- 238000004422 calculation algorithm Methods 0.000 description 7
- 238000013528 artificial neural network Methods 0.000 description 5
- 230000008901 benefit Effects 0.000 description 4
- 239000000284 extract Substances 0.000 description 4
- 238000010586 diagram Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 238000011176 pooling Methods 0.000 description 3
- 238000013459 approach Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000005286 illumination Methods 0.000 description 2
- 230000010365 information processing Effects 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- 235000008375 Decussocarpus nagi Nutrition 0.000 description 1
- 244000309456 Decussocarpus nagi Species 0.000 description 1
- 230000006978 adaptation Effects 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000002790 cross-validation Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 210000002569 neuron Anatomy 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 238000003909 pattern recognition Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000003238 somatosensory effect Effects 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/107—Static hand or arm
- G06V40/113—Recognition of static hand signs
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/217—Validation; Performance evaluation; Active pattern learning techniques
- G06F18/2193—Validation; Performance evaluation; Active pattern learning techniques based on specific statistical tests
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2411—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on the proximity to a decision surface, e.g. support vector machines
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/107—Static hand or arm
- G06V40/117—Biometrics derived from hands
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Bioinformatics & Computational Biology (AREA)
- General Engineering & Computer Science (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Probability & Statistics with Applications (AREA)
- Human Computer Interaction (AREA)
- Multimedia (AREA)
- Image Analysis (AREA)
Abstract
The invention provides a CNN-SVM mixed model gesture recognition method based on an error correction strategy, and belongs to the field of human-computer interaction. The CNN-SVM mixed model gesture recognition method based on the error correction strategy comprises the steps of firstly preprocessing acquired gesture data, then automatically extracting features, conducting prediction classification to obtain a classification result, and finally correcting the classification result by using the error correction strategy. By using the method, the error recognition rate among the confusable gestures is reduced, and the recognition rate of the static gestures is improved.
Description
Technical Field
The invention belongs to the field of human-computer interaction, and particularly relates to a CNN-SVM hybrid model gesture recognition method based on an error correction strategy.
Background
As computers become more and more popular in today's society, a convenient and natural human-computer interaction (HCI) approach is particularly important to users. Among numerous human-computer interaction modes, gestures are receiving more and more attention as a natural, simple and visual human-computer interaction mode, and can play an important role in various real scenes, such as somatosensory games, sign language recognition, intelligent wearable equipment, intelligent teaching and the like. The purpose of gesture recognition is to design an algorithm to enable a computer to recognize the gestures of pictures or human bodies and understand the meanings of the gestures, so that the interaction between the human bodies and the computer is realized. In the gesture recognition process, gestures are usually in a complex environment, and in order to accurately perform human-computer interaction, a designed gesture recognition algorithm should have good recognition capability under various light rays, angles, backgrounds and other complex environments.
Traditional gesture recognition algorithms are mainly based on Hidden Markov Models (HMMs) and template matching. The hidden Markov model-based gesture recognition method can be used for expressing a Markov process with hidden unknown parameters, and the gesture recognition process can be regarded as a Markov chain with a time sequence, so that the hidden Markov model can be applied to gesture recognition. The gesture recognition method based on the last shift matching establishes a gesture template by taking information such as the outline, the edge, the spatial distribution and the like of the gesture as characteristics, and realizes gesture recognition by applying a template matching algorithm. The two methods need to manually extract features, the manually extracted gesture features need a large amount of experience bases, and the manually extracted features have certain subjectivity and limitation, so that some significant features are easily ignored, and therefore the traditional method is limited in recognition capability and low in efficiency.
The Convolutional Neural Network (CNN) is one of the most widely applied models in the field of machine vision and image processing at present, and can obtain local and global features of an input image through training and learning, thereby solving the problem of insufficient feature extraction caused by artificial feature extraction. In recent years, convolutional neural networks have been successfully applied to image retrieval, face recognition, expression recognition, and target detection. Scholars apply CNN to the field of gesture recognition, jawad Nagi et al combine a maximum pooling layer with a convolutional neural network (MPCNN) for gesture recognition to obtain good effect, and Takayoushi et al propose an end-to-end deep convolutional network to realize gesture recognition and improve the accuracy of gesture recognition. In the application of gesture recognition, a relatively shallow network is generally adopted, and in the traditional static gesture recognition method, the gesture recognition method based on manual feature extraction is long in time consumption and low in recognition rate.
Disclosure of Invention
The invention aims to solve the problems in the prior art and provides a CNN-SVM mixed model gesture recognition method based on an error correction strategy, which adopts a deeper network, can learn deeper features, reduces the error recognition rate of the model on confusable gestures, and finally realizes the recognition of static gestures.
The invention is realized by the following technical scheme:
a CNN-SVM mixed model gesture recognition method based on an error correction strategy comprises the steps of preprocessing collected gesture data, automatically extracting features, conducting prediction classification to obtain a classification result, and finally correcting the classification result by using the error correction strategy.
The method comprises the following steps:
the first step is as follows: preprocessing the acquired data to obtain a training sample and a test sample;
the second step is that: obtaining a CNN-SVM mixed model;
the third step: inputting the test sample into the CNN-SVM mixed model obtained in the second step to obtain a classification result, probability estimation of the classification result and a confusion matrix;
the fourth step: and obtaining an error correction strategy based on the probability estimation obtained in the third step and the confusion matrix, and then correcting the classification result by using the error correction strategy.
The operation of the first step includes:
(11) Acquiring static gestures, and respectively acquiring a depth image and a color image of a hand;
(12) Processing the depth image to obtain a mask image;
(13) Performing AND operation on the color image and the mask image to obtain a rough gesture area image;
(14) And carrying out skin color segmentation on the rough gesture area image by utilizing a Bayesian skin color model to obtain a segmented image, and dividing the segmented image into two parts, wherein one part is used as a training sample, and the other part is used as a test sample.
And (11) acquiring a static gesture by using Kinect.
The second step is realized by: replacement of the last output layer of a CNN classifier with an SVM classifier
The second step of operation includes:
(21) Inputting the training sample into an input layer of a CNN classifier, and obtaining a trained CNN model after training of the CNN classifier until the training process converges or reaches the maximum iteration times;
(22): inputting the training sample into the trained CNN model for automatic feature extraction to obtain a feature vector of the training sample;
(23): and inputting the feature vectors of the training samples into an SVM classifier for secondary training, and obtaining a CNN-SVM mixed model after training is completed.
The error correction strategy is as follows: and (4) defining a threshold, screening out wrong classification results according to the threshold, and correcting final classification results according to statistical data obtained by experiments.
The operation of the fourth step includes:
in the N classification problem, let M i For one threshold for error correction of all test samples with classification result i, for M i The description of (A) is as follows:

wherein M is i,j Represents the mean value, M, calculated for the sample with prediction i but true value j i Is a j-dimensional vector; s i,j Denotes the number of all samples with prediction i, but true value j, S i Representing the number of all test samples predicted as class i, P n (i) Representing the maximum value of the probability estimate of the nth test sample among all test samples predicted as class i, P n (j) Represents the next largest value; i represents the class to which the maximum value in the classification estimation belongs, and j represents the class to which the second maximum value in the classification estimation belongs;
when the probability estimation meets the following conditions, modifying the class corresponding to the maximum value of the probability estimation into the class corresponding to the second maximum value:

wherein w n (i) The distance between the maximum value of the probability estimate representing the prediction result as class i and the second largest value of the probability estimate, i.e. equal in value to P n (i)-P n (j),p ij Representing the probability of a classification result of i but the true value of j in the confusion matrix.
Compared with the prior art, the invention has the beneficial effects that: by using the method, the error recognition rate among the confusable gestures is reduced, and the recognition rate of the static gestures is improved.
Drawings
Fig. 1-1, photo of nine different gestures
1-2 correspond to the depth images of the nine different gestures of FIGS. 1-1
FIG. 2 is a block diagram of insufficient image preprocessing in the method of the present invention
FIG. 3 Picture in Pre-processing
Fig. 4 is a diagram of a CNN network structure used in the method of the present invention
FIG. 5 is a graph of test accuracy on different data sets
FIG. 6 is a block diagram of the steps of the method of the present invention.
Detailed Description
The invention is described in further detail below with reference to the accompanying drawings:
the invention combines the advantages of a convolutional neural network and a support vector machine, provides a hybrid model to automatically extract features and improve the generalization capability of the model, and reduces the error recognition rate of confusable gestures by using an error correction strategy based on probability estimation.
As shown in fig. 6, the method of the present invention includes: firstly, the gesture data collected by the Kinect is subjected to segmentation preprocessing so as to reduce the interference of a complex background and other parts of a human body. Then, the hybrid model automatically extracts features and performs predictive classification. And finally, adjusting the classification decision by using an error correction strategy. Experiments are carried out on the established database, the recognition rate of 95.81% without using the error correction strategy is finally obtained, and the average accuracy rate of 97.32% is obtained after the error correction strategy is used.
The data acquisition in the method of the invention is as follows:
the system adopts Kinect2.0 to collect static gestures, respectively obtains depth images and color images of the hand, and then establishes a corresponding gesture database. The created gesture library contains 17 types of gestures and consists of 300 static images acquired by college students under different illumination backgrounds. In the invention, 9 gestures commonly used by human beings are selected, and each gesture comprises 3300 pictures. Fig. 1-2, 1-2 are photographs and depth images, respectively, of 9 gestures performed by an operator.
Data preprocessing is as follows:
it is easy to see from the collected gesture images, although the human gesture images in the color image are clearly recognizable, it is difficult to achieve accurate recognition because the collected gesture is affected by the view angle, appearance, shape, other parts of the human body and complex background. In the collected depth image, on one hand, the depth information is not influenced by the color, texture characteristics and illumination of the human hand, and the method has good robustness and high precision; on the other hand, the depth information in the depth image reflects the distance between the human hand and the acquisition device, so the depth difference in the gesture area is not very large. Because the depth image is segmented in the acquisition process, the gesture area interested by the color image can be segmented by utilizing the characteristic, so that the interference of other parts of a human body and a complex background in the color image is reduced. The steps of the segmentation pre-processing are shown in fig. 2.
In the preprocessing process, the acquired depth image is binarized, and the depth image is converted into a gray level depth image in the acquisition process, namely, the value range of the depth value is adjusted to be between gray values of 0 to 255. Because the depth map is segmented in the gesture area in the acquisition process, a binary image of the gesture area can be obtained by utilizing the size of the gray value. The mask image (a threshold value is set for the gray image, the value of a pixel point which is 128 in the invention is assigned to 1, and the value of a pixel point which is smaller than 128 is assigned to 0) and the color image are directly subjected to logical AND operation, so that only a rough gesture area image can be obtained. The obtained rough gesture area is subjected to skin color segmentation, and an accurate gesture area image is obtained by utilizing a Bayesian skin color model (please refer to documents 'M.J. Jones, et al. Statistical color models with application to skin detection [ J ]. International Journal of Computer Vision (IJCV), 2002,46 (1): 81-96').
In the present invention, an image is randomly selected to check the effectiveness of the segmentation pre-processing, wherein the color image, the depth image, the mask image, the coarse gesture area, and the segmented image are shown in fig. 3-1 to 3-5, respectively.
The segmentation preprocessing in the method can be obviously seen to effectively remove the influence of complex backgrounds and other parts of human bodies, and finally, the effective information of the gesture area can be accurately reserved by utilizing the Bayesian skin color model, so that good data guarantee is provided for later training work.
The hybrid CNN-SVM model is as follows:
SVM classifier: the support vector machine converts a low-dimensional input space linear indivisible sample into a high-dimensional feature space by selecting different kernel functions, so that the linear indivisible sample can be linearly divided, an optimal hyperplane is constructed in the feature space on the basis of the principle of minimizing the risk of a mechanism as a theoretical basis, and the structural description of data distribution is obtained, so that the requirements on data scale and data distribution are reduced, the error of an independent test set is effectively reduced, and the support vector machine is considered as one of the most common classifiers with the best effect.
LIBSVM was used in the experiment (see the literature "Chih-Chung Chang, chih-Jen Lin. LIBSVM: A library for support vector machines [ J ]]ACM Transactions on Intelligent Systems and Technology (TIST), 2011,2 (3): 1-27 ") to construct SVMs, LIBSVM is a fast and efficient software package for classification and regression, using a one-to-one strategy to solve the multi-classification problem. LIBSVM is not only able to predict the classification result but also to provide probability information of classification for each test sample. For a k-class problem, the goal is to estimate the samples Probability of belonging to each class:
Probability of belonging to each class:

for one-to-one strategies, p i Obtained by solving the following optimization problem:


wherein r is ij The probability of being a pair is defined as:

in the experiments of the present invention, SVMs are trained to predict probabilistic classification results whose probability values are to be applied to error correction for confusing gestures to determine whether the classification results are to be applied directly or reclassified through a strategy employed by the present invention.
A CNN classifier: the convolutional neural network is a deep feedforward neural network, directly takes an image as the input of the network, does not need manual definition and feature selection, avoids the links of feature selection and feature extraction in the traditional recognition algorithm, and simultaneously has good fault-tolerant capability, parallel processing capability and self-learning capability.
Instead of using a more complex CNN as mentioned in the document "Chih-Chung Chang, chih-Jen Lin. LIBSVM: A library for support vector machines [ J ]. ACM Transactions on Intelligent Systems and Technology (TIST), 2011,2 (3): 1-27") the present invention employs a more complex CNN as mentioned in the documents "A.Krizhevsky, S.Ilya, and G.E.Hinton.Imagementation with subsequent conditional Neural networks [ C ]// Advances in Neural Information Processing Systems 2 (NIPS), 2012-1114", wherein the network structure is as shown in FIG. 4. This network has a total of 8 layers, including 5 convolutional layers and 3 fully-connected layers, the last fully-connected layer outputting a 9-dimensional softmax to express the prediction for 9 classes. The first layer convolution layer convolves the input image of 224 × 224 × 3 with 96 convolution kernels of 11 × 11 × 3, with a step size of 4. The second layer convolution layer performs convolution operation on the output of the first layer after response normalization and pooling and 256 convolution kernels of 5 multiplied by 48. The third layer of convolution layer uses 384 convolution kernels with a 3 × 3 × 256 number and the second layer output after being pooled by the normalization kernels to perform convolution operation. The number of convolution kernels of the fourth convolution layer is 384 with a size of 3 × 3 × 192, and the fifth convolution layer has 256 convolution kernels with a size of 3 × 3 × 192. There are 4096 neurons per fully connected layer. Due to the complex network structure, the present invention deals with overfitting in a way that amplifies the data set. This is achieved by randomly extracting 224 x 224 blocks from a 256 x 256 picture and horizontal mirroring and training the neural network on these received blocks. Without this approach, the network would appear severely over-fit, forcing the use of smaller networks, resulting in the inability to use deep features in SVM training.
CNN-SVM hybrid model: firstly, the processed image is transmitted into an input layer, and the original CNN is trained for a plurality of times until the training process converges or the maximum iteration number is reached. And then inputting the training samples into the trained CNN model to obtain the feature vectors of the training samples, inputting the feature vectors into an SVM classifier for secondary training to obtain a CNN-SVM model after training is finished, and inputting the test samples into the model to obtain a classification result.
Error Correction Strategy (HECS) based on probability estimation: the LIBSVM gives a probability estimate of each sample classified into categories in the final prediction result, the final selected classification result is the one with the highest probability value, table 1 lists the final probability distribution of some test samples with wrong prediction classification results, the first column in the table represents the real category number of the test sample, the second column in the table represents the prediction classification number of the test sample, and the remaining other columns respectively represent the probabilities of the sample belonging to a certain column, from which it can be observed that in the probability estimates of the test samples with wrong prediction, the maximum value of the estimation probability is the predicted value and the second largest value is the real value.

TABLE 1
According to the final decision characteristics of LIBSVM and the final experimental results, it can be known that the probability estimation difference between the prediction classification and the real classification is very small in the sample with the wrong prediction classification result, and the probability estimation difference between the prediction classification and each other classification result is relatively large in the sample with the correct prediction result. According to the characteristic, the invention provides an error correction strategy based on probability estimation so as to reduce the classification errors generated under the condition. In the N classification problem, the present invention employs M i As a threshold for error correction for all test samples with prediction result i, for M i The description of (A) is as follows:

wherein S i Denotes the number of all test samples predicted as class i, P n (i) Represents the maximum value of the probability estimate of the nth test sample in all pictures predicted as class i, P n (j) Representing the next largest value. i denotes the class to which the largest value in the probability estimate belongs, and j denotes the class to which the next largest value in the probability estimate belongs.
And when the probability estimation meets the following conditions, modifying the class corresponding to the maximum value into the class corresponding to the second maximum value.

Wherein w n (i) The distance between the maximum value of the probability estimate representing the prediction result as class i and the next largest value, i.e. numerically equal to P n (i)-P n (j),p ij The probability that the predicted result is i but the true value j is represented in the confusion matrix.
The model of the invention has the following advantages:
the invention constructs the CNN-SVM model so as to make up the limitation of the CNN classifier and the SVM classifier and combine the advantages of the CNN classifier and the SVM classifier. The theoretical learning method of convolutional neural networks is the same as that of the Multilayer perceptron (MLP) (see the references "E.A. Zantaty. Support Machines (SVMs) cover Multi layer experience (MLP) in data classification [ J ]. Egyptian information Journal,2012,13 (3): 177-183"), and is therefore essentially an extension of MLP. The MLP theory is based on empirical risk minimization, which minimizes training errors during training. When the back propagation calculation is performed, a minimum value, whether it is a global minimum or not, is found so that the training result converges at this point, and the solution of the algorithm is not further improved. The SVM is characterized in that under the condition that the distribution of a training sample set is fixed, an optimal hyperplane is searched by utilizing a structure risk minimization principle, and the generalization error on data is minimized, so that the generalization capability of the SVM is superior to that of the MLP.
The CNN has an advantage in that it can automatically extract deep features of an input image, and the features are not changed when the input image is moved and distorted to some extent. However, manual feature extraction requires elaborate Design, and the traditional manual feature extraction methods (such as the methods provided in the documents "Jiang Y. An HMM based adaptation for video interaction recognition purposes [ C ]// IEEE International Conference on Intelligent Control and Information processing, 2010. Artificially designed feature extraction tends to ignore and lose some features. Therefore, the extraction of features by using CNN can collect more representative and relevant information than the conventional method.
The error correction strategy actually specifies a threshold, screens out the prediction classification results which are likely to make errors, and corrects the final classification decision with a certain probability according to the statistical data obtained by experiments. The CNN-SVM model can already obtain a good effect of classifying the samples, but the error correction strategy provided by the invention can correct the classification result of the samples which are easy to be confused in the final decision to a certain extent so as to improve the accuracy of the final whole body under the condition that two samples are difficult to be separated due to shielding or the problem of image quality acquisition.
The method of the invention is tested and analyzed as follows:
the experimental environment is as follows: in this experiment, the gesture recognition model was run on a Windows operating system, and the hardware configuration was: intel (R) Core (TM) i5-6500 processor, NVIDIA GeForceGT730, memory 8G, video memory 2G. The CNN network is built by Caffe, and the SVM classifier is realized by using an LIBSVM (support vector machine) software package by adopting a radial kernel (Gaussian RBF). All algorithms were run on Matlab2014a platform in the experiment.
The experimental results and analyses were as follows:
in the experiment of the invention, firstly, the color image and the depth image are subjected to segmentation pretreatment, and the obtained segmented gesture images are totalized to 29700 Zhang Zuowei data set of the invention, wherein 27000 pictures are used for training a model, and 2700 pictures are used for testing. 30000 times are adopted as the maximum iteration times in the CNN training process, and as can be seen from FIG. 5, the system has reached convergence when the iteration is about 10000 times, and finally, the model of the iteration is used for 30000 times to carry out the test, and the accuracy on the test set is 88.35%. And then, establishing a CNN-SVM model, replacing the final full-connected layer with an SVM classifier, and putting 4096-dimensional feature vectors into the SVM for training and testing. In the experiment of the invention, the SVM adopts an RBF kernel function, and a 5-fold cross validation method is adopted on a training set to obtain an optimal result in order to find an optimal multiplication coefficient C and an optimal kernel parameter g. The ranges for these two parameter seeks are: g = [2 ] 3 ,2 1 ,...,2 -15 ]And C = [2 ] 15 ,2 13 ,...,2 -5 ]. A total of 11 × 10=110 different combinations were tried, and finally it was determined that C =64,g =0.00024414. The two obtained parameters are used for training a mixed model, the final accuracy rate to the training is 99.94%, and the accuracy rate on 2700 test pictures reaches 95.81%. Table 2 lists training and testing accuracy using CNN and using CNN-SVM on the data set prepared by the present invention.
As can be seen from fig. 5, when the maximum number of iterations is 30000, the accuracy of the color image is the lowest, and can only reach 37.92% at most, the depth image is obviously improved by 79.07% compared with the color image, and the accuracy of the preprocessed image can reach 88.35% at most. The invention is characterized in that when the unprocessed color image is used for training directly, a large amount of noise information (complex background information and information of other parts of a human body) exists in a training sample, although the interference of the background and the other parts of the human body is avoided by using the segmented depth image, the acquired depth image projects the depth information into the gray scale information of [0,255] for storage, so that the depth image has a part of information missing, and the gesture after the segmentation is preprocessed by the invention can not only effectively remove the large interference of the complex background and the other parts of the human body, but also can retain complete color information of a gesture area, so that more abundant characteristics can be extracted for classification when the CNN network training is carried out. By putting the test samples into the mixed model for classification prediction, a confusion matrix can be counted as shown in table 2:


TABLE 2
In 100 experiments, the error correction rate is mainly concentrated between [3% and 5% ], the accuracy is most concentrated between [97% and 98% ], the average error correction rate is 4.12%, and the average accuracy is 97.32%.
Table 3 shows the accuracy of gesture recognition under the provided data set by the method of the present invention and other methods. Unlike the method of the present invention, the document "Yamashita T, watasue T. Hand position registration based on bottom-up structured subsequent reliable neural network with current neural network [ C ]// Image Processing (ICIP), 2014 IEEE International Conference on IEEE,2014 853-857" uses a simpler convolutional neural network, the maximum pooling layer and the convolutional neural network form an MPCNN, and the recognition accuracy of 68.89% is obtained on the test set. The documents "Shao-Zi Li, bin Yu, wei Wu, song-Zhi Su, rong-Rong Ji. Feature learning based on SAE-PCA network for human gesture recognition in RGBD images [ J ]. Neuro-prediction, 2015,151 (2): 565-573" use an end-to-end convolutional neural network, which yields a gesture recognition accuracy of 85.43%. In the documents "Xiao-Xiao Niu, ching Y.Suen.A novel hybrid CNN-SVM classifier for recognizing hand and text directions [ J ]. Pattern Recognition,2012,45 (4): 1318-1325", gesture segmentation is performed by using depth information and skin color information, then the features are extracted by using an SAE-PCA model based on feature learning, and finally classification is performed by using an SVM classifier, the final accuracy of gesture Recognition is 93.32%, and the accuracy of different gesture Recognition methods on the data set of the invention is shown in Table 3:


TABLE 3
As can be seen, the method provided by the invention has obvious improvement in the aspect of accurate identification compared with other methods.
The method firstly carries out segmentation pretreatment on the depth data and the color data of the gesture, and eliminates the influence of color data on a human body and a complex background; then, the features of the gestures are extracted by utilizing the convolutional neural network, so that the complex process of artificially designing the features according to the outline and the geometric characteristics of the gestures is avoided; then, carrying out probability estimation of the gesture through a support vector machine; and finally, an error correction strategy is provided to correct the classification result of the model based on the obtained probability estimation and a confusion matrix obtained by an experiment. A large number of experimental results show that the method can effectively recognize the static gesture, can optimize the capability of classifying the confusable gesture by the CNN-SVM model to a certain extent, and can improve the accuracy of final recognition on the whole.
The above-described embodiment is only one embodiment of the present invention, and it will be apparent to those skilled in the art that various modifications and variations can be easily made based on the application and principle of the present invention disclosed in the present application, and the present invention is not limited to the method described in the above-described embodiment of the present invention, so that the above-described embodiment is only preferred, and not restrictive.
Claims (5)
1. A CNN-SVM mixed model gesture recognition method based on an error correction strategy is characterized by comprising the following steps: the method comprises the steps of firstly preprocessing collected gesture data, then automatically extracting features, conducting prediction classification to obtain a classification result, and finally correcting the classification result by using an error correction strategy;
the method comprises the following steps:
the first step is as follows: preprocessing the acquired data to obtain a training sample and a test sample;
the second step is that: obtaining a CNN-SVM mixed model;
the third step: inputting the test sample into the CNN-SVM mixed model obtained in the second step for training to obtain a classification result, probability estimation of the classification result and a confusion matrix;
the fourth step: obtaining an error correction strategy based on the probability estimation and the confusion matrix obtained in the third step, and then correcting the classification result by using the error correction strategy;
the operation of the first step includes:
(11) Acquiring static gestures, and respectively acquiring a depth image and a color image of a hand;
(12) Processing the depth image to obtain a mask image;
(13) Performing AND operation on the color image and the mask image to obtain a rough gesture area image;
(14) Carrying out skin color segmentation on the rough gesture area image by utilizing a Bayesian skin color model to obtain a segmented image, and dividing the segmented image into two parts, wherein one part is used as a training sample, and the other part is used as a test sample;
the operation of the fourth step includes:
in that In the classification problem, set->
In the classification problem, set-> Is classified as having a result of->
Is classified as having a result of->
 For all test samples, for ∑ or ∑ a threshold value for error correction>
For all test samples, for ∑ or ∑ a threshold value for error correction> The description of (A) is as follows:
The description of (A) is as follows:

wherein,M i,j the mean value calculated for the sample with prediction i, but true value j,M i is a j-dimensional vector;S i,j the number of all samples representing a prediction result of i, but the true value of j, indicates a prediction as +>
indicates a prediction as +> Number of all test samples in a class>
Number of all test samples in a class> Representing all predictions being +>
Representing all predictions being +>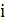 Class i on all test samples>
Class i on all test samples> The maximum value of the probability estimates for individual test samples,
The maximum value of the probability estimates for individual test samples, represents the next largest value;
represents the next largest value; Indicates the class to which the maximum value in the classification estimate belongs>
Indicates the class to which the maximum value in the classification estimate belongs> Representing the class to which the next largest value in the classification estimate belongs;
Representing the class to which the next largest value in the classification estimate belongs;
when the probability estimation meets the following conditions, modifying the class corresponding to the maximum value of the probability estimation into the class corresponding to the second maximum value:

wherein Indicates that the prediction result is->
Indicates that the prediction result is-> The distance of the maximum value of the probability estimate of a class from the next largest value of the probability estimate, i.e. numerically equal to ≦ ≦ value>
The distance of the maximum value of the probability estimate of a class from the next largest value of the probability estimate, i.e. numerically equal to ≦ ≦ value> ,
, Is represented in a confusion matrixClass result is>
Is represented in a confusion matrixClass result is> But the true value is->
But the true value is-> The probability of (c).
The probability of (c).
2. The error correction strategy-based CNN-SVM hybrid model gesture recognition method of claim 1, wherein: and (11) acquiring a static gesture by using Kinect.
3. The error correction strategy-based CNN-SVM hybrid model gesture recognition method of claim 1, wherein: the second step is realized by: the last output layer of the CNN classifier is replaced with an SVM classifier.
4. The error correction strategy-based CNN-SVM hybrid model gesture recognition method of claim 1, wherein: the operation of the second step comprises:
(21) Inputting the training sample into an input layer of a CNN classifier, and obtaining a trained CNN model after training of the CNN classifier until the training process converges or reaches the maximum iteration times;
(22): inputting the training sample into the trained CNN model for automatic feature extraction to obtain a feature vector of the training sample;
(23): and inputting the feature vectors of the training samples into an SVM classifier for secondary training, and obtaining a CNN-SVM mixed model after the training is finished.
5. The method for recognizing the gesture of the CNN-SVM hybrid model based on the error correction strategy as claimed in claim 2, wherein: the error correction strategy is as follows: and defining a threshold, screening out wrong classification results according to the threshold, and correcting final classification results according to statistical data obtained by experiments.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810684333.9A CN109033978B (en) | 2018-06-28 | 2018-06-28 | Error correction strategy-based CNN-SVM hybrid model gesture recognition method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810684333.9A CN109033978B (en) | 2018-06-28 | 2018-06-28 | Error correction strategy-based CNN-SVM hybrid model gesture recognition method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN109033978A CN109033978A (en) | 2018-12-18 |
| CN109033978B true CN109033978B (en) | 2023-04-18 |
Family
ID=65521908
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810684333.9A Active CN109033978B (en) | 2018-06-28 | 2018-06-28 | Error correction strategy-based CNN-SVM hybrid model gesture recognition method |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN109033978B (en) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109890573B (en) * | 2019-01-04 | 2022-05-03 | 上海阿科伯特机器人有限公司 | Control method and device for mobile robot, mobile robot and storage medium |
| CN109902593A (en) * | 2019-01-30 | 2019-06-18 | 济南大学 | A kind of gesture occlusion detection method and system based on Kinect |
| CN111191002B (en) * | 2019-12-26 | 2023-05-23 | 武汉大学 | Neural code searching method and device based on hierarchical embedding |
| CN111310812B (en) * | 2020-02-06 | 2023-04-28 | 佛山科学技术学院 | Hierarchical human body activity recognition method and system based on data driving |
| CN112308042A (en) * | 2020-05-22 | 2021-02-02 | 哈尔滨工程大学 | Stranger action identification method based on channel state information |
| CN111722717B (en) * | 2020-06-18 | 2024-03-15 | 歌尔科技有限公司 | Gesture recognition method, gesture recognition device and computer-readable storage medium |
| CN115223239B (en) * | 2022-06-23 | 2024-05-07 | 山东科技大学 | Gesture recognition method, gesture recognition system, computer equipment and readable storage medium |
| CN118236226A (en) * | 2024-03-26 | 2024-06-25 | 中山市康骏医疗科技有限公司 | Intelligent wheelchair system based on gesture verification control |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1999042920A1 (en) * | 1998-02-19 | 1999-08-26 | Mindmaker, Inc. | A method and system for gesture category recognition and training |
| CN106227341A (en) * | 2016-07-20 | 2016-12-14 | 南京邮电大学 | Unmanned plane gesture interaction method based on degree of depth study and system |
| CN106529470A (en) * | 2016-11-09 | 2017-03-22 | 济南大学 | Gesture recognition method based on multistage depth convolution neural network |
| CN107704072A (en) * | 2017-06-10 | 2018-02-16 | 济南大学 | The automatic error correction method of user gesture during a kind of gesture interaction |
| CN107766842A (en) * | 2017-11-10 | 2018-03-06 | 济南大学 | A kind of gesture identification method and its application |
| CN108027873A (en) * | 2015-09-03 | 2018-05-11 | 微软技术许可有限责任公司 | Based on the stroke information captured come with assistant's component interaction |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8873813B2 (en) * | 2012-09-17 | 2014-10-28 | Z Advanced Computing, Inc. | Application of Z-webs and Z-factors to analytics, search engine, learning, recognition, natural language, and other utilities |
-
2018
- 2018-06-28 CN CN201810684333.9A patent/CN109033978B/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1999042920A1 (en) * | 1998-02-19 | 1999-08-26 | Mindmaker, Inc. | A method and system for gesture category recognition and training |
| CN108027873A (en) * | 2015-09-03 | 2018-05-11 | 微软技术许可有限责任公司 | Based on the stroke information captured come with assistant's component interaction |
| CN106227341A (en) * | 2016-07-20 | 2016-12-14 | 南京邮电大学 | Unmanned plane gesture interaction method based on degree of depth study and system |
| CN106529470A (en) * | 2016-11-09 | 2017-03-22 | 济南大学 | Gesture recognition method based on multistage depth convolution neural network |
| CN107704072A (en) * | 2017-06-10 | 2018-02-16 | 济南大学 | The automatic error correction method of user gesture during a kind of gesture interaction |
| CN107766842A (en) * | 2017-11-10 | 2018-03-06 | 济南大学 | A kind of gesture identification method and its application |
Also Published As
| Publication number | Publication date |
|---|---|
| CN109033978A (en) | 2018-12-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109033978B (en) | Error correction strategy-based CNN-SVM hybrid model gesture recognition method | |
| CN108154118B (en) | A kind of target detection system and method based on adaptive combined filter and multistage detection | |
| CN110443143B (en) | Multi-branch convolutional neural network fused remote sensing image scene classification method | |
| US10846566B2 (en) | Method and system for multi-scale cell image segmentation using multiple parallel convolutional neural networks | |
| CN109919108B (en) | Remote sensing image rapid target detection method based on deep hash auxiliary network | |
| CN112288011B (en) | Image matching method based on self-attention deep neural network | |
| CN105701502B (en) | Automatic image annotation method based on Monte Carlo data equalization | |
| CN111753828B (en) | Natural scene horizontal character detection method based on deep convolutional neural network | |
| CN103605972B (en) | Non-restricted environment face verification method based on block depth neural network | |
| CN111738143B (en) | Pedestrian re-identification method based on expectation maximization | |
| US20190228268A1 (en) | Method and system for cell image segmentation using multi-stage convolutional neural networks | |
| CN111652317B (en) | Super-parameter image segmentation method based on Bayes deep learning | |
| CN111612008A (en) | Image segmentation method based on convolution network | |
| WO2014205231A1 (en) | Deep learning framework for generic object detection | |
| CN111833322B (en) | Garbage multi-target detection method based on improved YOLOv3 | |
| CN108898138A (en) | Scene text recognition methods based on deep learning | |
| CN107992874A (en) | Image well-marked target method for extracting region and system based on iteration rarefaction representation | |
| CN115049952A (en) | Juvenile fish limb identification method based on multi-scale cascade perception deep learning network | |
| CN112329784A (en) | Correlation filtering tracking method based on space-time perception and multimodal response | |
| Castellano et al. | Deep convolutional embedding for digitized painting clustering | |
| CN113011243A (en) | Facial expression analysis method based on capsule network | |
| CN115410088A (en) | Hyperspectral image field self-adaption method based on virtual classifier | |
| CN112364747B (en) | Target detection method under limited sample | |
| CN115393631A (en) | Hyperspectral image classification method based on Bayesian layer graph convolution neural network | |
| CN107423771B (en) | Two-time-phase remote sensing image change detection method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |