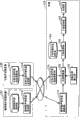具体实施方式
以下,参照附图来说明本发明的具体实施方式。
(实施例1)
图3是本发明的实施例1所涉及的音质转换装置的框图。
实施例1所涉及的音质转换装置是通过根据被输入了输入声音的元音的声道信息的转换比率,来转换目标讲话者的元音的声道信息,从而转换输入声音的音质的装置,其包括:目标元音声道信息保持部101、转换比率输入部102、元音转换部103、子音声道信息保持部104、子音选择部105、子音变形部106、合成部107。
目标元音声道信息保持部101是保持从目标讲话者发音的元音中抽取的声道信息的存储装置,例如,由硬盘或存储器等构成。
转换比率输入部102是输入进行音质转换时的向目标讲话者的转换比率的处理部。
元音转换部103是针对被输入了的附带音素边界信息的声道信息所包含的各个元音区间,根据由转换比率输入部102输入的转换比率,进行向附带音素边界信息的声道信息中的与目标元音声道信息保持部101所保持的该元音区间相对应的元音的声道信息的转换的处理部。另外,附带音素边界信息的声道信息是指,在输入声音的声道信息中附带了音素标记的信息。音素标记是指,包含与输入声音相对应的音素信息和各个音素的时间长度的信息的信息。关于附带音素边界信息的声道信息的生成方法,以后再述。
子音声道信息保持部104是保持,针对从多个讲话者的声音数据中抽取了的非特定讲话者的子音的声道信息的存储装置,例如,由硬盘或存储器等构成。
子音选择部105是根据附带音素边界信息的声道信息所包含的子音的声道信息的前后的元音的声道信息,从子音声道信息保持部104选择子音的声道信息的处理部,该子音的声道信息与通过元音转换部103元音的声道信息被变形后的附带音素边界信息的声道信息所包含的子音的声道信息相对应。
子音变形部106是,将由子音选择部105选择的子音的声道信息配合该子音的前后的元音的声道信息,进行变形的处理部。
合成部107是根据输入声音的声源信息和通过元音转换部103、子音选择部105及子音变形部106被变形的附带音素边界信息的声道信息,合成声音的处理部。即,合成部107依据输入声音的声源信息生成激励声源,并驱动根据附带音素边界信息的声道信息而构成的声道滤波器从而合成声音。关于声源信息的生成方法,以后再述。
例如,音质转换装置由计算机等构成,并通过在计算机上执行程序来实现上述各个处理部。
其次,关于各自的构成部分进行详细地说明。
<目标元音声道信息保持部101>
目标元音声道信息保持部101在是日语的情况下,保持目标讲话 者的至少五个元音(/aiueo/)的、来自目标讲话者的声道形状的声道信息。在是英语等其他语言的情况下,与日语的情况同样,关于各个元音保持声道信息即可。作为声道信息的表现方式,例如存在声道截面面积函数。声道截面面积函数表述如图4(a)所示的,在以可变圆形截面面积的声管来模拟声道的声管模型中的各个声管的截面面积。众所周知,此截面面积与基于LPC(Linear Predictive Coding:线性预测编码)分析的PARCOR(Partial Auto Correlation:偏自相关)系数一一对应,并能够通过公式1来转换。在本实施例中,设通过PARCOR系数ki来表现声道信息。以后,虽然利用PARCOR系数来说明声道信息,但是,声道信息并不只限定于PARCOR系数,也可以利用与PARCOR系数等价的LSP(Line Spectrum Pairs:线谱对)和LPC等。而且,所述声管模型中的声管之间的反射系数和PARCOR系数的关系,仅在于符号是相反的。因此,利用反射系数本身当然也没关系。
(公式1)
在此,An表示如图4(b)所示的第i区间的声管的截面面积,ki表示第i个和第i+1个边界的PARCOR系数(反射系数)。
利用根据LPC分析被分析出的线性预测系数αi,能够算出PARCOR系数。具体而言,通过利用Levinson-Durbin-Itakura算法,能够算出PARCOR系数。另外,PARCOR系数具有以下的特征。
·线性预测系数依赖于分析次数p,而PARCOR系数则不依赖于分析的次数。
·越是低次的系数,由于变动而对频谱的影响就越大,越成为高次则变动的影响就越小。
·高次的系数的变动的影响平稳地涉及全部频带。
其次,关于目标讲话者的元音的声道信息(以下,称为“目标元 音声道信息”)的制作方法,边举例边进行说明。例如,目标元音声道信息能够通过由目标讲话者发出的孤立的元音声音来构筑。
图5是表示通过由目标讲话者发出的孤立的元音声音,生成目标元音声道信息保持部101所存储的目标元音声道信息的处理部的构成的图。
元音稳定区间抽取部203从被输入的孤立的元音声音中抽取孤立的元音的区间。抽取方法并不特别限定。例如,也可以将一定功率以上的区间作为稳定区间,并将该稳定区间作为元音的区间来抽取。
目标声道信息制作部204针对由元音稳定区间抽取部203抽取的元音的区间,算出上述PARCOR系数。
通过对发出被输入的孤立的元音的声音进行元音稳定区间抽取部203的处理以及目标声道信息制作部204的处理,从而构筑目标元音声道信息保持部101。
在此之外,也可以通过如图6所示的处理部,构筑目标元音声道信息保持部101。只要目标讲话者的发音至少包含五个元音,就并不限定于孤立的元音声音。例如,可以是目标讲话者临时自由发音后的声音,也可以是预先被收录的声音。另外,还可以利用歌唱数据等声音。
对这样的目标讲话者声音201,音素识别部202进行音素识别。其次,元音稳定区间抽取部203,根据在音素识别部202的识别结果,抽取稳定的元音区间。作为抽取的方法,例如,能够将在音素识别部202的识别结果的可靠性高的区间(似然高的区间)作为稳定的元音区间使用。
如此通过抽取稳定的元音区间,能够排除由于音素识别部202的识别错误的影响。例如,对关于在如图7所示的声音(/k//a//i/)被输入,并抽取元音区间/i/的稳定区间的情况进行说明。例如,能够将元音区间/i/内的功率大的区间设为稳定区间50。或者,能够使用作为音素识别部202的内部信息的似然,将似然在阈值以上的区间作为稳定 区间来利用。
目标声道信息制作部204在抽出了的元音的稳定区间中,制作目标元音声道信息,并存储在目标元音声道信息保持部101。通过此处理,能够构筑目标元音声道信息保持部101。例如,由目标声道信息制作部204进行的目标元音声道信息的制作,通过计算前述的PARCOR系数来进行。
并且,目标元音声道信息保持部101所保持的目标元音声道信息的制作方法,并不限定于此,只要对稳定的元音区间进行声道信息的抽取,则也可以为其他的方法。
<转换比率输入部102>
转换比率输入部102接受,对接近设为目标的讲话者的声音的程度进行指定的转换比率的输入。转换比率通常被指定为0以上1以下的数值。转换比率越接近1,转换后的声音的音质就越接近目标讲话者,转换比率越接近0,就越接近转换前声音的音质。
而且,通过输入1以上的转换比率,能够更加强调地表现转换前声音的音质和目标讲话者的音质之间的差别。并且,通过输入0以下的转换比率(负转换比率),能够在相反的方向强调地表现转换前声音的音质和目标讲话者的音质之间的差别。另外,也可以省略转换比率的输入,将预先确定的比率作为转换比率来设定。
<元音转换部103>
元音转换部103将被输入了的附带音素边界信息的声道信息所包含的元音区间的声道信息,以转换比率输入部102所指定的转换比率,转换为目标元音声道信息保持部101所保持的目标元音声道信息。以下对详细的转换方法进行说明。
通过从转换前的声音取得依据前述的PARCOR系数的声道信息,并通过将音素标记付与该声道信息,从而生成附带音素边界信息的声道信息。
具体如图8A所示,LPC分析部301针对输入声音进行线性预测 分析,PARCOR计算部302以分析后的线性预测系数为基础,算出PARCOR系数。并且,音素标记被另外付与。
而且,如下所述,求出输入合成部107的声源信息。即,逆滤波器部304从由LPC分析部301分析的滤波系数(线性预测系数)形成具备此频率响应的逆向特性的滤波器,并通过过滤输入声音,从而生成输入声音的声源波形(声源信息)。
也能够利用ARX(autoregressive with exogenous input:外因输入自动回归)分析来代替上述LPC分析。ARX分析是根据声音生成过程的声音分析法,该声音生成过程通过以高精度推定声道及声源参数为目的的ARX模式和声源模式公式来表述,该声音分析法与LPC分析相比,是能够高精度地分离声道信息和声源信息的声音分析法(非专利文献:大冢等「音源パルス列を考慮した頑健なARX音声分析法」(“考虑了声源脉冲串的强健的ARX声音分析法”),日本声学学会会刊58卷7号(2002年)、pp.386-397)。
图8B是表示附带音素边界信息的声道信息的其他的制作方法的图。
如该图所示,ARX分析部303针对输入声音进行ARX分析,PARCOR计算部302以分析后的全极点模型的多项式为基础,算出PARCOR系数。并且,音素标记被另外付与。
而且,输入合成部107的声源信息通过与图8A所示的在逆滤波器部304的处理相同的处理而生成。即,逆滤波器部304从由ARX分析部303分析的滤波系数形成具备此频率响应的逆向特性的滤波器,并通过过滤输入声音,从而生成输入声音的声源波形(声源信息)。
图9是表示附带音素边界信息的声道信息的另一其他的制作方法的图。
如图9所示,文本合成装置401从被输入的文本来合成声音,并输出合成声音。合成声音被输入LPC分析部301及逆滤波器部304。因此,在输入声音是通过文本合成装置401合成的合成声音的情况下, 能够通过文本合成装置401取得音素标记。而且,LPC分析部301及PARCOR计算部302通过利用合成后的声音,能够容易地算出PARCOR系数。
并且,输入合成部107的声源信息通过与图8A所示的在逆滤波器部304的处理相同的处理而生成。即,逆滤波器部304从由ARX分析部303分析的滤波系数形成具备此频率响应的逆向特性的滤波器,并通过过滤输入声音,从而生成输入声音的声源波形(声源信息)。
而且,在与音质转换装置脱机时生成附带音素边界信息的声道信息的情况下,也可以预先通过手动付与音素边界。
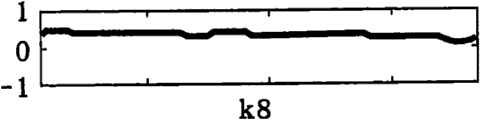
图10A至图10J是表示以十次PARCOR系数表现的元音/a/的声道信息的一个例子的图。
在该图中,纵座标轴表示反射系数,横坐标轴表示时间。从这些图中可以得知PARCOR系数针对时间变化进行比较平滑的变动。
元音转换部103如上所述,对被输入的附带音素边界信息的声道信息所包含的元音的声道信息进行转换。
首先,元音转换部103从目标元音声道信息保持部101取得与转换对象的元音的声道信息相对应的目标元音声道信息。在成为对象的目标元音声道信息为多个的情况下,元音转换部103配合成为转换对象的元音的音韵环境(例如前后的音素种类等)的状况,取得最合适的目标元音声道信息。
元音转换部103根据由转换比率输入部102输入的转换比率,将转换对象的元音的声道信息转换为目标元音声道信息。
在被输入的附带音素边界信息的声道信息中,根据公式2所示的多项式(第一函数),将以成为转换对象的元音区间的PARCOR系数表现的声道信息的各因次的时间序列进行近似。例如,在十次PARCOR系数的情况下,各自的次数的PARCOR系数根据公式2所示的多项式来近似。因此,能够得出十种多项式。多项式的次数没有特别的限定,能够设定适当的次数。
(公式2)
不过,
是被输入的被转换声音的PARCOR系数的近似多项式,a
i是多项式的系数,x表示时刻。
此时作为适用多项式近似的单位,例如,能够将一个音素区间设为近似的单位。而且,也可以不是音素区间,而是设从音素中心到下一个音素中心为止的时间幅度为单位。另外,在以下的说明中,将音素区间作为单位来进行说明。
图11A至图11D是表示根据五次多项式对PARCOR系数进行近似,并以音素区间单位在时间方向上进行平滑化时的从一次至四次PARCOR系数的图。所谓图形的纵座标轴和横坐标轴,与图10A至图10J相同。
在本实施例中,作为多项式的次数虽然以五次为例进行了说明,但是多项式的次数也可以不是五次。并且,在根据多项式近似之外,也可以按每个音素区间根据回归线对PARCOR系数进行近似。
与成为转换对象的元音区间的PARCOR系数相同,根据公式3所示的多项式(第二函数),将以目标元音声道信息保持部101所保持的PARCOR系数来表现的目标元音声道信息进行近似,从而取得多项式的系数bi。
(公式3)
其次,利用被转换参数(ai)、目标元音声道信息(bi)、转换比率(r),根据公式4求出转换后的声道信息(PARCOR系数)的多项式的系数ci。
ci=ai+(bi-ai)×r (公式4)
通常,转换比率r在0≤r≤1的范围内被指定。但是,即使在转换比率r超出此范围的情况下,也能够根据公式4进行转换。在转换比率r超过1的情况下,成为更加强调被转换参数(ai)与目标元音声道信息(bi)之间的差分的转换。另一方面,在r是负值的情况下,成为在反方向上更加强调被转换参数(ai)与目标元音声道信息(bi)之间的差分的转换。
利用算出的转换后的多项式的系数ci,以公式5(第三函数)来求出转换后的声道信息。
(公式5)
通过在PARCOR系数的各个因次中进行以上的转换处理,能够以被指定的转换比率转换为目标PARCOR系数。
图12表示实际上,针对元音/a/进行了上述转换的例子。在该图中,横坐标轴表示被归一化了的时间,纵座标轴表示第一次PARCOR系数。被归一化了的时间是指,通过以元音区间的持续时间长度,对时间进行归一化,从而具有从0到1为止的时刻的时间。这是在被转换声音的元音持续时间和目标元音声道信息的持续时间不相同的情况下,为了使时间轴一致的处理。图中的(a)表示被转换声音的男性讲话者的/a/的发音的系数的推移。同样,(b)表示目标元音的女性讲话者的/a/的发音的系数的推移。(c)表示利用上述转换方法,将男性讲话者的系数以转换比率0.5转换为女性讲话者的系数时的系数的推移。从该图可知,通过上述的变形方法,即能够对讲话者之间的PARCOR系数进行插值。
在音素边界为了防止PARCOR系数的值变得不连续,设置适当的过渡区间以进行插值处理。尽管插值的方法没有特别限定,但是例如能够通过进行线形插值来消除PARCOR系数的不连续。
图13是对关于设置过渡区间,对PARCOR系数的值进行插值的例子进行说明的图。该图表示元音/a/和元音/e/的连接边界的反射系数。在该图中的边界时刻(t),反射系数变得不连续。于是,从边界时刻设置适当的过渡时间(Δt),对从时刻t-Δt到时刻t+Δt之间的反射系数进行线形插值,通过求出插值后的反射系数51来防止在音素边界的反射系数的不连续。作为过渡时间,例如设为20msec即可。或者,也可以按照前后的元音继续时间长度来改变过渡时间。例如,也可以使元音区间越短过渡区间也就越短,元音区间越长过渡区间也就越长。
图14A是表示在对元音/a/和元音/i/的边界的PARCOR系数进行插值的情况下的频谱的图。图14B是表示将元音/a/和元音/i/的边界的声音通过平滑转换进行连接的情况下的频谱的图。在图14A及图14B中,纵座标轴表示频率,横坐标轴表示时间。在图14A中,可以得知,将在元音边界21的边界时刻作为t的情况下,在从时刻t-Δt(22)到时刻t+Δt(23)为止的范围内,频谱上的强度的峰值为连续性变化。另一方面,在图14B中,频谱的峰值将元音边界24作为边界,不连续性地变化。如此通过对PARCOR系数的值进行插值,能够使频谱峰值(对应共振峰)连续性地变化。其结果为,由于共振峰连续性地变化,所以也能够使得到的合成音从/a/到/i/连续性地变化。
而且,图15是从将合成后的PARCOR系数进行了插值的PARCOR系数,再次抽取共振峰,并绘制的图。在该图中,纵座标轴表示频率(Hz),横坐标轴表示时间(sec)。图上的点表示按每个合成音的帧的共振峰频率。附属在点上的竖棒表示共振峰的强度。竖棒越短共振峰强度就越强,竖棒越长共振峰强度就越弱。在以共振峰来看的情况下也可知,以元音边界27为中心的过渡区间(从时刻28到时刻29为止的区间)中,各个共振峰(共振峰强度也)连续性地变化。
如上所述,在元音边界中,通过设置适当的过渡区间,并对PARCOR系数进行插值,能够连续地转换共振峰及频谱,从而实现自然的音韵转变。
这样的频谱及共振峰的连续性的转变,在通过图14B所示的声音的平滑转换的连接中无法实现。
同样,图16是,在图16(a)为/a/和/u/的连接,图16(b)为/a/和/e/的连接,图16(c)为/a/和/o/的连接之时的,表示根据平滑转换连接的频谱、对PARCOR系数进行插值后的频谱以及根据PARCOR系数插值的共振峰的移动的图。由此可知,在所有的元音连接中,能够使频谱强度的峰值连续地变化。
即表示了,通过进行以声道形状(PARCOR系数)的插值,也能够进行共振峰的插值。因此,在合成音中也能够自然地表现元音的音韵转变。
图17A至图17C是表示在转换后的元音区间的时间上的中心的声道截面面积的图。此图是根据公式1,将图12所示的在PARCOR系数的时间上的中心点的PARCOR系数转换为声道截面面积的图。在图17A至图17C的各个图形中,横坐标轴表示在声管中的位置,纵座标轴表示声道截面面积。图17A表示转换前的男性讲话者的声道截面面积,图17B表示目标讲话者的女性的声道截面面积,图17C表示以转换比率50%,将转换前的PARCOR系数对应于转换后的PARCOR系数的声道截面面积。从这些图也可得知,图17C所示的声道截面面积为,转换前和转换后之间的中间的声道截面面积。
<子音声道信息保持部104>
为了将音质转换为目标讲话者,虽然将在元音转换部103被输入的附带音素边界信息的声道信息所包含的元音转换为目标讲话者的元音声道信息,但是,由于转换元音,因而在子音和元音的连接边界上发生声道信息的不连续。
图18是在VCV(V表示元音,C表示子音)音素列中,将元音转换部103进行元音的转换之后的某个PARCOR系数模式化表示的图。
在该图中,横坐标轴表示时间轴,纵座标轴表示PARCOR系数。图18(a)是被输入的声音的声道信息。在此之中的元音部分的PARCOR 系数利用图18(b)所示的目标讲话者的声道信息,通过元音转换部103被变形。其结果为,得到如图18(c)所示的元音部分的声道信息10a及10b。但是,子音部分的声道信息10c未被转换,表示为输入声音的声道形状。因此,元音部分的声道信息和子音部分的声道信息之间的边界发生不连续性。因而关于子音部分的声道信息也需要转换。以下对关于子音部分的声道信息的转换方法进行说明。
声音的个人特性在考虑元音和子音的持续时间和稳定性等的情况下,可以考虑为主要根据元音来表现的。
于是,关于子音,能够不使用目标讲话者的声道信息,而从预先准备好的多个子音的声音信息之中,通过选择适合由元音转换部103转换后的元音声道信息的子音的声道信息,来缓和与转换后的元音在连接边界上的不连续性。在图18(c)中,从子音声道信息保持部104所存储的子音的声道信息中,通过选择与前后的元音的声道信息10a及10b的连接性好的子音的声道信息10d,能够实现缓和在音素边界上的不连续性。
为了实现以上的处理,预先从多个讲话者的多个发音中提出子音区间,与制作目标元音声道信息保持部101所存储的目标元音声道信息时同样,通过算出各个子音区间的PARCOR系数,来制作存储在子音声道信息保持部104的子音声道信息。
<子音选择部105>
子音选择部105从子音声道信息保持部104选择,适合由元音转换部103转换了的元音声道信息的子音的声道信息。至于选择哪个子音声道信息,能够根据子音的种类(音素)和子音的始点及终点的连接点中的声道信息的连续性来判断。即,能够根据PARCOR系数的连接点中的连续性,来判断是否选择。具体而言,子音选择部105进行满足公式6的子音声道信息Ci的检索。
(公式6)
在此,Ui-1表示前面的音素的声道信息,Ui+1表示后续的音素的声道信息。
而且,w是前面的音素与选择对象的子音之间的连续性和选择对象的子音与后续的音素之间的连续性的权重。权重w以重视与后续音素的连接的方式被适当地设定。之所以重视与后续音素的连接,是因为子音与后续的元音的结合比与前面的音素强。
并且,函数Cc是表示两个音素的声道信息的连续性的函数,例如,能够通过两个音素的边界上的PARCOR系数的差的绝对值来表现该连续性。而且,也可以设计成PARCOR系数越是低次的系数,权重就越大。
这样,通过选择适合向目标音质转换后的元音的声道信息的子音的声道信息,从而能够实现平滑的连接,并能够提高合成声音的自然性。
而且,还可以设计成仅设子音选择部105中选择的子音的声道信息为有声子音的声道信息,关于无声子音,使用被输入的声道信息。其理由是因为,无声子音是不伴随声带的振动的发音,声音的生成过程与生成元音或有声子音时不同。
<子音变形部106>
虽然通过子音选择部105,能够取得适合由元音转换部103转换后的元音声道信息的子音声道信息,但是,具有连接点的连续性并不一定充分的情况。因此,子音变形部106进行变形,以使由子音选择部105所选择了的子音的声道信息与后续元音的连接点能够连续地连接。
具体而言,子音变形部106使子音的PARCOR系数移动,以使在与后续元音的连接点中,PARCOR系数和后续元音的PARCOR系数一致。但是,为了保证稳定性,PARCOR系数必须在[-1,1]的范围内。因此,暂且根据tanh-1函数等将PARCOR系数映射在[-∞, ∞]的空间中,并在映射后的空间上进行线性移动之后,通过再次根据tanh返回[-1,1]的范围,从而能够既保证了稳定性,又改善子音区间与后续元音区间的声道形状的连续性。
<合成部107>
合成部107利用音质转换后的声道信息和另外被输入的声源信息来合成声音。虽然没有特别限定合成的方法,但是,在利用PARCOR系数作为声道信息的情况下,利用PARCOR合成即可。或者,也可以在从PARCOR系数转换成LPC系数之后合成声音,还可以从PARCOR系数中抽取共振峰,通过共振峰合成来合成声音。进而,也可以从PARCOR系数算出LSP系数,通过LSP合成来合成声音。
其次,关于在本实施例中被执行的处理,利用图19A及图19B所示的流程图进行说明。
在本发明的实施例中被执行的处理大致由两个处理组成。一个是目标元音声道信息保持部101的构筑处理,另一个是音质的转换处理。
首先,参照图19A对有关目标元音声道信息保持部101的构筑处理进行说明。
从目标讲话者发出了的声音中抽取元音的稳定区间(步骤S001)。作为稳定区间的抽取方法,如上所述,音素识别部202识别音素,元音稳定区间抽取部203将在识别结果中所包含的元音区间之中的似然是阈值以上的元音区间作为元音稳定区间来抽取。
目标声道信息制作部204制作在被抽取的元音区间中的声道信息(步骤S002)。如上所述,声道信息能够通过PARCOR系数来表示。PARCOR系数能够从全极点模型的多项式中算出。因此,作为分析方法,能够使用LPC分析或者ARX分析。
目标声道信息制作部204将在步骤S002中被分析了的元音稳定区间的PARCOR系数作为声道信息,登记在目标元音声道信息保持部101(步骤S003)。
通过以上步骤,能够构筑对针对目标讲话者的音质附加特征的目 标元音声道信息保持部101。
其次,参照图19B对有关通过图3所示的音质转换装置,将被输入的附带音素边界信息的声音转换为目标讲话者的声音的处理进行说明。
转换比率输入部102接受表示向目标讲话者的转换的程度的转换比率的输入(步骤S004)。
元音转换部103针对被输入的声音的元音区间,从目标元音声道信息保持部101取得针对所对应的元音的目标声道信息,根据在步骤S004中被输入的转换比率,转换被输入的声音的元音区间的声道信息(步骤S005)。
子音选择部105选择适合被转换了的元音区间的声道信息的子音声道信息(步骤S006)。此时,设子音选择部105将子音的种类(音素)以及子音与其前后的音素的连接点中的声道信息的连续性作为评价的标准,选择连续性最高的子音的声道信息。
为了提高被选择的子音的声道信息与在前后的音素区间的声道信息的连续性,子音变形部106将子音的声道信息进行变形(步骤S007)。根据被选择的子音的声道信息与前后的音素区间的各自的连接点中的声道信息(PARCOR系数)的差分值,通过使子音的PARCOR系数移动来实现变形。并且,在使之移动之时,为了保证PARCOR系数的稳定性,根据tanh-1函数等,暂且将PARCOR系数映射在[-∞,∞]的空间,并在映射后的空间中线性移动PARCOR系数,移动后再次根据tanh函数等返回[-1,1]的空间。因此,能够进行稳定后的子音声道信息的转换。并且,从[-1,1]向[-∞,∞]的映射不仅限于tanh-1函数,也可以利用f(x)=sgn(x)×1/(1-|x|)等的函数。在此,sgn(x)是在x为正的时候成为+1,在x为负的时候成为-1的函数。
这样,通过对子音区间的声道信息进行变形,能够制作适合转换后的元音区间且连续性高的子音区间的声道信息。因此,能够实现稳定连续的,且为高音质的音质转换。
合成部107根据通过元音转换部103、子音选择部105以及子音变形部106所转换了的声道信息,生成合成音(步骤S008)。此时,作为声源信息,能够使用转换前声音的声源信息。通常,在LPC系统的分析合成中,因为作为激励声源使用脉冲串的情况较多,所以也可以根据预先设定了的基频等信息,在对声源信息(F0(基频)、功率等)进行变形之后,生成合成音。因此,不仅能够进行依据声道信息的声调的转换,也能够进行依据基频等表示的韵律、或者声源信息的转换。
而且,例如在合成部107中,也能够使用Rosenberg-Klatt模型等的声门声源模型,在使用了这样的构成的情况下,还能够使用利用从被转换声音的Rosenberg-Klatt模型的参数(OQ、TL、AV、F0等)向目标声音移动后的值等方法。
根据所涉及的构成,将附带音素边界信息的声道信息作为输入,元音转换部103根据由转换比率输入部102输入的转换比率,进行从被输入了的附带音素边界信息的声道信息所包含的各个元音区间的声道信息,向与目标元音声道信息保持部101所保持的该元音区间相对应的元音的声道信息的转换。子音选择部105根据子音的前后的元音的声道信息,从子音声道信息保持部104选择适合由元音转换部103转换了的元音声道信息的子音的声道信息。子音变形部106将由子音选择部105选择的子音的声道信息配合前后的元音的声道信息,来进行变形。合成部107根据通过元音转换部103、子音选择部105以及子音变形部106变形了的附带音素边界信息的声道信息,合成声音。因此,作为目标讲话者的声道信息,只准备元音稳定区间的声道信息即可。而且,在制作目标讲话者的声道信息之时,由于只需识别元音稳定区间即可,所以不受如专利文献2的技术那样的声音识别错误的影响。
即,由于能够大大减少针对目标讲话者的负担,所以能够容易地进行音质转换。而且,在专利文献2的技术中,根据在声音合成部14的声音合成中所使用的声音单元与目标讲话者的发音之间的差分,来 编写变换函数。因此,被转换声音的音质必须与声音合成用数据存储部13所保持的声音单元的音质相同或者类似。对此,本发明的音质转换装置将目标讲话者的元音声道信息作为绝对的目标。为此,可以完全不限制转换前的声音的音质,从而可以输入任何音质的声音。即,因为对被输入的被转换声音的限制非常少,所以能够针对广泛的声音进行该声音的音质的转换。
同时,通过子音选择部105从子音声道信息保持部104选择预先被保持的子音的声道信息,从而能够使用适合转换后的元音的声道信息的最佳的子音声道信息。
而且,在本实施例中,通过子音选择部105及子音变形部106,不仅在元音区间,并且在子音区间中也进行了转换声源信息的处理,但是,也可以省略这些处理。在此情况下,作为子音的声道信息,就照原样使用被输入音质转换装置的附带音素边界信息的声道信息所包含的子音的声道信息。因此,无论在处理终端的处理性能低的情况下,或在存储容量少的情况下,都能够实现向目标讲话者的音质转换。
另外,也可以只省略子音变形部106,而构成音质转换装置。在此情况下,就照原样使用子音选择部105所选择的子音的声道信息。
或者,也可以只省略子音选择部105,而构成音质转换装置。在此情况下,子音变形部106对被输入音质转换装置的附带音素边界信息的声道信息所包含的子音的声道信息进行变形。
(实施例2)
以下,对本发明的实施例2进行说明。
实施例2与实施例1的音质转换装置不同,考虑的是被转换声音和目标音质信息被个别地管理的情况。并考虑被转换声音是声音内容。例如,是唱歌声音等。作为目标音质信息,设为保持着各种各样的音质。例如,设为保持着各种各样的歌手的音质信息。在这种情况下,可以考虑分别下载声音内容和目标音质信息,从而在终端进行音质转换的使用方法。
图20是表示本发明的实施例2所涉及的音质转换系统的构成的图。关于图20中的与图3相同的构成部分使用同样的符号,并省略对其的说明。
音质转换系统包括:被转换声音服务器121、目标声音服务器122、终端123。
被转换声音服务器121是管理并提供被转换声音信息的服务器,包括:被转换声音保持部111、被转换声音信息发送部112。
被转换声音保持部111是保持被转换声音的信息的存储装置,例如,由硬盘或存储器等构成。
被转换声音信息发送部112是将被转换声音保持部111所保持的被转换声音信息,通过网络发送到终端123的处理部。
目标声音服务器122是管理并提供成为目标的音质信息的服务器,包括:目标元音声道信息保持部101、目标元音声道信息发送部113。
目标元音声道信息发送部113是将目标元音声道信息保持部101所保持的目标讲话者的元音声道信息,通过网络发送到终端123的处理部。
终端123是根据从目标声音服务器122发送的目标元音声道信息,对从被转换声音服务器121发送的被转换声音信息的音质进行转换的终端装置,包括:被转换声音信息接收部114、目标元音声道信息接收部115、转换比率输入部102、元音转换部103、子音声道信息保持部104、子音选择部105、子音变形部106、合成部107。
被转换声音信息接收部114是通过网络,接收由被转换声音信息发送部112发送了的被转换声音信息的处理部。
目标元音声道信息接收部115是通过网络,接收由目标元音声道信息发送部113发送了的目标元音声道信息的处理部。
被转换声音服务器121、目标声音服务器122以及终端123,例如,由具备CPU、存储器、通信接口等的计算机等构成,上述各个处 理部通过在计算机的CPU上执行程序来实现。
本实施例与实施例1的不同之处在于,作为目标讲话者的元音的声道信息的目标元音声道信息和作为与被转换声音对应的信息的被转换声音信息,通过网络进行收发。
其次,关于实施例2所涉及的音质转换系统的工作进行说明。图21是表示本发明的实施例2所涉及的音质转换系统的处理的流程的流程图。
终端123通过网络,对目标声音服务器122请求目标讲话者的元音声道信息。目标声音服务器122的目标元音声道信息发送部113从目标元音声道信息保持部101取得被请求了的目标讲话者的元音声道信息,并发送到终端123。终端123的目标元音声道信息接收部115接收目标讲话者的元音声道信息(步骤S101)。
并不特别限定目标讲话者的指定方法,例如也可以利用讲话者标识符进行指定。
终端123通过网络,对被转换声音服务器121请求被转换声音信息。被转换声音服务器121的被转换声音信息发送部112从被转换声音保持部111取得被请求了的被转换声音信息,并发送到终端123。终端123的被转换声音信息接收部114接收被转换声音信息(步骤S102)。
并不特别限定被转换声音信息的指定方法,例如也可以通过标识符来管理声音内容,并利用此标识符进行指定。
转换比率输入部102接受表示向目标讲话者的转换的程度的转换比率的输入(步骤S004)。另外,也可以省略转换比率的输入,而设定预先确定的转换比率。
元音转换部103针对被输入的声音的元音区间,从目标元音声道信息接收部115取得对应的元音的目标元音声道信息,根据在步骤S004中被输入的转换比率,转换被输入的声音的元音区间的声道信息(步骤S005)。
子音选择部105选择适合被转换了的元音区间的声道信息的子音声道信息(步骤S006)。此时,设子音选择部105将子音与其前后的音素的连接点中的声道信息的连续性作为评价标准,并选择连续性最高的子音的声道信息。
为了提高被选择的子音的声道信息与在前后的音素区间的声道信息的连续性,子音变形部106将子音的声道信息进行变形(步骤S007)。根据被选择的子音的声道信息与前后的音素区间的各自的连接点中的声道信息(PARCOR系数)的差分值,通过使子音的PARCOR系数移动来实现变形。并且,在使之移动之时,为了保证PARCOR系数的稳定性,根据tanh-1函数等,暂且将PARCOR系数映射在[-∞,∞]的空间,并在映射后的空间中线性移动PARCOR系数,移动后再次根据tanh函数等返回[-1,1]的空间。因此,能够进行稳定后的子音声道信息的转换。并且,从[-1,1]向[-∞,∞]的映射不仅限于tanh-1函数,也可以利用f(x)=sgn(x)×1/(1-|x|)等的函数。在此,sgn(x)是在x为正的时候成为+1,在x为负的时候成为-1的函数。
这样,通过对子音区间的声道信息进行变形,能够制作适合转换后的元音区间且连续性高的子音区间的声道信息。因此,能够实现稳定连续的,且为高音质的音质转换。
合成部107根据通过元音转换部103、子音选择部105以及子音变形部106所转换了的声道信息,生成合成音(步骤S008)。此时,作为声源信息,能够使用转换前声音的声源信息。并且,也可以在根据预先设定了的基频等信息将声源信息进行变形之后,生成合成音。因此,不仅能够进行依据声道信息的声调的转换,也能够进行依据基频等表示的韵律、或者声源信息的转换。
另外,也可以不是步骤S101、步骤S102、步骤S004的顺序,可以按任意的顺序来执行。
根据所涉及的构成,目标声音服务器122管理并发送目标声音信息。因此,不需要在终端123制作目标声音信息,且能够进行向登记 在目标声音服务器122上的各种各样的音质的音质转换。
并且,通过被转换声音服务器121管理并发送被转换声音,从而不需要在终端123制作被转换声音信息,就能够利用登记在被转换声音服务器121上的各种各样的被转换声音信息。
通过被转换声音服务器121管理声音内容,目标声音服务器122管理目标讲话者的音质信息,从而能够分别管理声音信息和讲话者的音质信息。因此,终端123的使用者能够以适合自己的爱好的音质来收听适合自己的爱好的声音内容。
例如,通过以被转换声音服务器121管理唱歌声音,并以目标声音服务器122管理各种各样的歌手的目标声音信息,能够在终端123中将各种各样的音乐转换成各种各样的歌手的音质来收听,从而能够提供适合使用者的爱好的音乐。
并且,也可以通过同一个服务器来实现被转换声音服务器121和目标声音服务器122。
(实施例3)
在实施例2表示了使用服务器来管理被转换声音和目标元音声道信息,且终端分别将其下载,以生成转换了音质的声音的利用方法。对此,在本实施例中,用户利用终端来登记自己的声音的音质,例如,对将本发明适用于,将用于对用户通知来电呼叫的来电歌声等转换为自己的音质来享受的服务的情况进行说明。
图22是表示本发明的实施例3所涉及的音质转换系统的构成的图。关于图22中的与图3相同的构成部分使用同样的符号,并省略对其的说明。
音质转换系统包括:被转换声音服务器121、音质转换服务器222、终端223。
被转换声音服务器121具有与实施例2所示的被转换声音服务器121相同的构成,包括:被转换声音保持部111、被转换声音信息发送部112。但是,依据被转换声音信息发送部112的被转换声音信息 的发送目的地不同,本实施例所涉及的被转换声音信息发送部112通过网络,将被转换声音信息发送到音质转换服务器222。
终端223是为了用户享受歌声转换服务的终端装置。即,终端223是制作成为目标的音质信息,并将其提供给音质转换服务器222,且接收并再生由音质转换服务器222转换了的歌声声音的装置,包括:声音输入部109、目标元音声道信息制作部224、目标元音声道信息发送部113、被转换声音指定部1301、转换比率输入部102、音质转换声音接收部1304、再生部305。
声音输入部109是为了取得用户的声音的装置,例如,包括扩音器等。
目标元音声道信息制作部224是制作,作为从目标讲话者、即声音输入部109输入了声音的用户的元音的声道信息的目标元音声道信息的处理部。并不限定目标元音声道信息的制作方法,例如,目标元音声道信息制作部224根据图5所示的方法制作目标元音声道信息,并包括元音稳定区间抽取部203、目标声道信息制作部204。
目标元音声道信息发送部113是通过网络,将由目标元音声道信息制作部224制作了的目标元音声道信息发送到音质转换服务器222的处理部。
被转换声音指定部1301是,从被转换声音服务器121所保持的被转换声音信息中,指定作为转换对象的被转换声音信息,并将指定的结果通过网络发送到音质转换服务器222的处理部。
虽然转换比率输入部102具有与实施例1及2所示的转换比率输入部102同样的构成,但是,本实施例所涉及的转换比率输入部102还通过网络,将被输入了的转换比率发送到音质转换服务器222。另外,也可以省略转换比率的输入,而使用预先确定的转换比率。
音质转换声音接收部1304是接收作为通过音质转换服务器222,音质被转换了的被转换声音的合成音的处理部。
再生部306是再生音质转换声音接收部1304所接收了的合成音 的装置,例如,包括扬声器等。
音质转换服务器222是根据从终端223的目标元音声道信息发送部113发送的目标元音声道信息,对从被转换声音服务器121发送的被转换声音信息的音质进行转换的终端装置,包括:被转换声音信息接收部114、目标元音声道信息接收部115、转换比率接收部1302、元音转换部103、子音声道信息保持部104、子音选择部105、子音变形部106、合成部107、合成声音发送部1303。
转换比率接收部1302是接收从转换比率输入部102发送了的转换比率的处理部。
合成声音发送部1303是通过网络,将由合成部107输出的合成音发送到终端223的音质转换声音接收部1304的处理部。
被转换声音服务器121、音质转换服务器222以及终端223,例如,由具备CPU、存储器、通信接口等的计算机等构成,上述各个处理部通过在计算机的CPU上执行程序来实现。
本实施例与实施例2的不同之处在于,通过终端223在抽取了成为目标的音质特征之后,将其发送到音质转换服务器222,并通过音质转换服务器222将音质转换后的合成音送回到终端223,从而能够在终端223上得到具有抽取了的音质特征的合成音。
其次,关于实施例3所涉及的音质转换系统的工作进行说明。图23是表示本发明的实施例3所涉及的音质转换系统的处理的流程的流程图。
终端223利用声音输入部109,取得用户的元音声音。例如,能够通过用户对着扩音器进行“あ、い、う、え、お”的发音,来取得元音声音。元音声音的取得方法并不仅限于此,还可以如图6所示,从被发音了的文章中抽取元音声音(步骤S301)。
终端223根据利用目标元音声道信息制作部224取得了的元音声音,制作声道信息。声道信息的制作方法可以与实施例1相同(步骤S302)。
终端223利用被转换声音指定部1301,指定被转换声音信息。指定的方法并不特别限定。被转换声音服务器121的被转换声音信息发送部112从被转换声音保持部111所保持的被转换声音信息之中,选择由被转换声音指定部1301指定了的被转换声音信息,并将所选择的被转换声音信息发送到音质转换服务器222(步骤S303)。
终端223利用转换比率输入部102来取得转换比率(步骤S304)。
音质转换服务器222的转换比率接收部1302接收由终端223发送的转换比率,目标元音声道信息接收部115接收由终端223发送的目标元音声道信息。而且,被转换声音信息接收部114接收由被转换声音服务器121发送的被转换声音信息。并且,元音转换部103针对接收了的被转换声音信息的元音区间的声道信息,从目标元音声道信息接收部115取得对应的元音的目标元音声道信息,根据由转换比率接收部1302接收了的转换比率,转换元音区间的声道信息(步骤S305)。
音质转换服务器222的子音选择部105选择适合被转换了的元音区间的声道信息的子音声道信息(步骤S306)。此时,设子音选择部105将子音与其前后的音素的连接点中的声道信息的连续性作为评价的标准,并选择连续性最高的子音的声道信息。
音质转换服务器222的子音变形部106为了提高被选择的子音的声道信息与在前后的音素区间的连续性,对子音的声道信息进行变形(步骤S307)。
作为变形的方法,可以与实施例2的变形方法相同。这样,通过对子音区间的声道信息进行变形,能够制作适合转换后的元音区间且连续性高的子音区间的声道信息。因此,能够实现稳定连续的,且为高音质的音质转换。
音质转换服务器222的合成部107根据通过元音转换部103、子音选择部105以及子音变形部106转换了的声道信息,生成合成音,合成声音发送部1303将生成的合成音发送到终端223(步骤S308)。 此时,作为合成音生成时的声源信息,能够使用转换前声音的声源信息。并且,也可以在根据预先设定了的基频等信息将声源信息进行变形之后,生成合成音。因此,不仅能够进行依据声道信息的声调的转换,也能够进行依据基频等表示的韵律、或者声源信息的转换。
终端223的音质转换声音接收部1304接收由合成声音发送部1303发送的合成音,再生部305再生接收了的合成音(S309)。
根据所涉及的构成,终端223制作并发送目标声音信息,且接收并再生通过音质转换服务器222转换了音质的声音。因此,只需在终端223输入成为目标的声音,并制作成为目标的元音的声道信息即可,从而能够大为减小终端223的处理负荷。
而且,通过利用被转换声音服务器121来管理被转换声音信息,并通过将被转换声音信息从被转换声音服务器121发送到音质转换服务器222,从而不需要在终端223制作被转换声音信息。
因为被转换声音服务器121管理声音内容,且终端223只制作成为目标的音质,所以终端223的使用者能够以适合自己的爱好的音质来收听适合自己的爱好的声音内容。
例如,通过以被转换声音服务器121管理唱歌声音,并通过利用音质转换服务器222将唱歌声音转换成由终端223取得了的目标音质,从而能够提供适合使用者的爱好的音乐。
并且,也可以通过同一个服务器来实现被转换声音服务器121和音质转换服务器222。
作为本实施例的应用例,例如在终端223是移动电话的情况下,例如通过将取得了的合成音作为铃声来登记,从而用户能够制作自己独有的铃声。
并且,在本实施例的构成中,由于以音质转换服务器222来进行音质转换,所以能够以服务器来进行音质转换的管理。因此,能够管理用户的音质转换的履历,具有不容易发生侵犯版权及肖像权的问题之效果。
另外,在本实施例中,虽然目标元音声道信息制作部224被设置在终端223,但是,也可以设置在音质转换服务器222。在此情况下,通过网络,将声音输入部109所输入的目标元音声音发送到音质转换服务器222。而且,在音质转换服务器222中,还可以利用目标元音声道信息制作部224从接收了的声音制作目标元音声道信息,并在通过元音转换器103的音质转换之时使用。根据此构成,由于终端223只需输入成为目标的音质的元音即可,因此具有大为减小处理负荷的效果。
再者,本实施例不仅能够适用于移动电话的来电歌声的音质转换,例如,通过以用户的音质来再生歌手所演唱的歌曲,从而能够收听既具备专业歌手的演唱能力又是以用户的音质来演唱的歌曲。由于通过模仿歌曲的演唱从而能够学习专业歌手的演唱能力,因此能够适用于卡拉OK的练习等用途上。
在此公开的实施例的所有部分都是例示,应当认为并不是加以限制的内容。本发明的范围不在于上述的说明,是根据权利要求而表示的,并意味着包括与权利要求同等的意思以及在范围内的所有变更。
本发明所涉及的音质转换装置具有从目标讲话者的元音区间的声道信息,高品质地转换音质的功能,作为需要各种各样的音质的用户界面或娱乐等非常有用。并且,能够应用于通过移动电话等的声音通信中的语音变换器等用途上。