CN101443357A - Mcp1融合物 - Google Patents
Mcp1融合物 Download PDFInfo
- Publication number
- CN101443357A CN101443357A CNA2006800374431A CN200680037443A CN101443357A CN 101443357 A CN101443357 A CN 101443357A CN A2006800374431 A CNA2006800374431 A CN A2006800374431A CN 200680037443 A CN200680037443 A CN 200680037443A CN 101443357 A CN101443357 A CN 101443357A
- Authority
- CN
- China
- Prior art keywords
- mcp1
- polypeptide
- seq
- chemokine
- acid
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 102100021943 C-C motif chemokine 2 Human genes 0.000 title claims abstract description 206
- 101710091439 Major capsid protein 1 Proteins 0.000 title claims abstract description 173
- 230000004927 fusion Effects 0.000 title claims description 109
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 125
- 229920001184 polypeptide Polymers 0.000 claims abstract description 105
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 105
- 238000000034 method Methods 0.000 claims abstract description 73
- 108060003951 Immunoglobulin Proteins 0.000 claims abstract description 38
- 102000018358 immunoglobulin Human genes 0.000 claims abstract description 38
- 102000019034 Chemokines Human genes 0.000 claims description 67
- 108010012236 Chemokines Proteins 0.000 claims description 67
- 241000282414 Homo sapiens Species 0.000 claims description 47
- -1 polyoxyethylene Polymers 0.000 claims description 47
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 45
- 239000000203 mixture Substances 0.000 claims description 44
- 239000003795 chemical substances by application Substances 0.000 claims description 40
- 230000014509 gene expression Effects 0.000 claims description 37
- 239000002773 nucleotide Substances 0.000 claims description 36
- 125000003729 nucleotide group Chemical group 0.000 claims description 36
- 239000000178 monomer Substances 0.000 claims description 35
- JYGXADMDTFJGBT-VWUMJDOOSA-N hydrocortisone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 JYGXADMDTFJGBT-VWUMJDOOSA-N 0.000 claims description 32
- 230000001225 therapeutic effect Effects 0.000 claims description 32
- 239000013612 plasmid Substances 0.000 claims description 31
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 claims description 30
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 30
- 108091033319 polynucleotide Proteins 0.000 claims description 29
- 239000002157 polynucleotide Substances 0.000 claims description 29
- 102000040430 polynucleotide Human genes 0.000 claims description 29
- 201000010099 disease Diseases 0.000 claims description 27
- 230000009466 transformation Effects 0.000 claims description 26
- 238000002360 preparation method Methods 0.000 claims description 25
- 238000011282 treatment Methods 0.000 claims description 25
- 235000001014 amino acid Nutrition 0.000 claims description 21
- 150000001413 amino acids Chemical class 0.000 claims description 20
- 229960001347 fluocinolone acetonide Drugs 0.000 claims description 18
- FEBLZLNTKCEFIT-VSXGLTOVSA-N fluocinolone acetonide Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]2(C)C[C@@H]1O FEBLZLNTKCEFIT-VSXGLTOVSA-N 0.000 claims description 18
- 241000894006 Bacteria Species 0.000 claims description 17
- 239000003446 ligand Substances 0.000 claims description 17
- SNHRLVCMMWUAJD-SUYDQAKGSA-N betamethasone valerate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CO)(OC(=O)CCCC)[C@@]1(C)C[C@@H]2O SNHRLVCMMWUAJD-SUYDQAKGSA-N 0.000 claims description 16
- 229960004311 betamethasone valerate Drugs 0.000 claims description 16
- 229960000890 hydrocortisone Drugs 0.000 claims description 16
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 claims description 15
- UETNIIAIRMUTSM-UHFFFAOYSA-N Jacareubin Natural products CC1(C)OC2=CC3Oc4c(O)c(O)ccc4C(=O)C3C(=C2C=C1)O UETNIIAIRMUTSM-UHFFFAOYSA-N 0.000 claims description 15
- 208000027866 inflammatory disease Diseases 0.000 claims description 15
- 229960001940 sulfasalazine Drugs 0.000 claims description 15
- NCEXYHBECQHGNR-QZQOTICOSA-N sulfasalazine Chemical compound C1=C(O)C(C(=O)O)=CC(\N=N\C=2C=CC(=CC=2)S(=O)(=O)NC=2N=CC=CC=2)=C1 NCEXYHBECQHGNR-QZQOTICOSA-N 0.000 claims description 15
- NCEXYHBECQHGNR-UHFFFAOYSA-N sulfasalazine Natural products C1=C(O)C(C(=O)O)=CC(N=NC=2C=CC(=CC=2)S(=O)(=O)NC=2N=CC=CC=2)=C1 NCEXYHBECQHGNR-UHFFFAOYSA-N 0.000 claims description 15
- 102000009410 Chemokine receptor Human genes 0.000 claims description 14
- 108050000299 Chemokine receptor Proteins 0.000 claims description 14
- 239000012634 fragment Substances 0.000 claims description 14
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 claims description 13
- 229960004703 clobetasol propionate Drugs 0.000 claims description 12
- CBGUOGMQLZIXBE-XGQKBEPLSA-N clobetasol propionate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)CCl)(OC(=O)CC)[C@@]1(C)C[C@@H]2O CBGUOGMQLZIXBE-XGQKBEPLSA-N 0.000 claims description 12
- NQPDZGIKBAWPEJ-UHFFFAOYSA-N valeric acid Chemical compound CCCCC(O)=O NQPDZGIKBAWPEJ-UHFFFAOYSA-N 0.000 claims description 12
- QWOJMRHUQHTCJG-UHFFFAOYSA-N CC([CH2-])=O Chemical compound CC([CH2-])=O QWOJMRHUQHTCJG-UHFFFAOYSA-N 0.000 claims description 11
- 206010039361 Sacroiliitis Diseases 0.000 claims description 11
- CIWBQSYVNNPZIQ-XYWKZLDCSA-N betamethasone dipropionate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H](C)[C@@](C(=O)COC(=O)CC)(OC(=O)CC)[C@@]1(C)C[C@@H]2O CIWBQSYVNNPZIQ-XYWKZLDCSA-N 0.000 claims description 11
- 229960002593 desoximetasone Drugs 0.000 claims description 11
- VWVSBHGCDBMOOT-IIEHVVJPSA-N desoximetasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@@H](C)[C@H](C(=O)CO)[C@@]1(C)C[C@@H]2O VWVSBHGCDBMOOT-IIEHVVJPSA-N 0.000 claims description 11
- 238000002347 injection Methods 0.000 claims description 11
- 239000007924 injection Substances 0.000 claims description 11
- 235000002639 sodium chloride Nutrition 0.000 claims description 11
- POPFMWWJOGLOIF-XWCQMRHXSA-N Flurandrenolide Chemical compound C1([C@@H](F)C2)=CC(=O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]2(C)C[C@@H]1O POPFMWWJOGLOIF-XWCQMRHXSA-N 0.000 claims description 10
- CSNNHWWHGAXBCP-UHFFFAOYSA-L Magnesium sulfate Chemical class [Mg+2].[O-][S+2]([O-])([O-])[O-] CSNNHWWHGAXBCP-UHFFFAOYSA-L 0.000 claims description 10
- 229960003099 amcinonide Drugs 0.000 claims description 10
- ILKJAFIWWBXGDU-MOGDOJJUSA-N amcinonide Chemical compound O([C@@]1([C@H](O2)C[C@@H]3[C@@]1(C[C@H](O)[C@]1(F)[C@@]4(C)C=CC(=O)C=C4CC[C@H]13)C)C(=O)COC(=O)C)C12CCCC1 ILKJAFIWWBXGDU-MOGDOJJUSA-N 0.000 claims description 10
- 229960002170 azathioprine Drugs 0.000 claims description 10
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 claims description 10
- MYSWGUAQZAJSOK-UHFFFAOYSA-N ciprofloxacin Chemical compound C12=CC(N3CCNCC3)=C(F)C=C2C(=O)C(C(=O)O)=CN1C1CC1 MYSWGUAQZAJSOK-UHFFFAOYSA-N 0.000 claims description 10
- 229940069235 cordran Drugs 0.000 claims description 10
- 229960004154 diflorasone Drugs 0.000 claims description 10
- WXURHACBFYSXBI-XHIJKXOTSA-N diflorasone Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@H](C)[C@@](C(=O)CO)(O)[C@@]2(C)C[C@@H]1O WXURHACBFYSXBI-XHIJKXOTSA-N 0.000 claims description 10
- XBDQKXXYIPTUBI-UHFFFAOYSA-N dimethylselenoniopropionate Natural products CCC(O)=O XBDQKXXYIPTUBI-UHFFFAOYSA-N 0.000 claims description 10
- 239000013604 expression vector Substances 0.000 claims description 10
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 claims description 10
- 239000010931 gold Substances 0.000 claims description 10
- 229910052737 gold Inorganic materials 0.000 claims description 10
- CGIGDMFJXJATDK-UHFFFAOYSA-N indomethacin Chemical compound CC1=C(CC(O)=O)C2=CC(OC)=CC=C2N1C(=O)C1=CC=C(Cl)C=C1 CGIGDMFJXJATDK-UHFFFAOYSA-N 0.000 claims description 10
- 230000005012 migration Effects 0.000 claims description 10
- 238000013508 migration Methods 0.000 claims description 10
- 235000006408 oxalic acid Nutrition 0.000 claims description 10
- 239000002253 acid Substances 0.000 claims description 9
- 239000011780 sodium chloride Substances 0.000 claims description 9
- 229920003171 Poly (ethylene oxide) Polymers 0.000 claims description 8
- 239000003937 drug carrier Substances 0.000 claims description 8
- 229960002117 triamcinolone acetonide Drugs 0.000 claims description 8
- YNDXUCZADRHECN-JNQJZLCISA-N triamcinolone acetonide Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H]3OC(C)(C)O[C@@]3(C(=O)CO)[C@@]1(C)C[C@@H]2O YNDXUCZADRHECN-JNQJZLCISA-N 0.000 claims description 8
- 101000617130 Homo sapiens Stromal cell-derived factor 1 Proteins 0.000 claims description 7
- 102100021669 Stromal cell-derived factor 1 Human genes 0.000 claims description 7
- 206010009887 colitis Diseases 0.000 claims description 7
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 claims description 7
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 claims description 6
- 208000011231 Crohn disease Diseases 0.000 claims description 6
- 101000815628 Homo sapiens Regulatory-associated protein of mTOR Proteins 0.000 claims description 6
- 101000652747 Homo sapiens Target of rapamycin complex 2 subunit MAPKAP1 Proteins 0.000 claims description 6
- 101000648491 Homo sapiens Transportin-1 Proteins 0.000 claims description 6
- 101100495074 Mus musculus Ccl2 gene Proteins 0.000 claims description 6
- 206010040047 Sepsis Diseases 0.000 claims description 6
- 102100028748 Transportin-1 Human genes 0.000 claims description 6
- 206010047115 Vasculitis Diseases 0.000 claims description 6
- SOQJPQZCPBDOMF-YCUXZELOSA-N betamethasone benzoate Chemical compound O([C@]1([C@@]2(C)C[C@H](O)[C@]3(F)[C@@]4(C)C=CC(=O)C=C4CC[C@H]3[C@@H]2C[C@@H]1C)C(=O)CO)C(=O)C1=CC=CC=C1 SOQJPQZCPBDOMF-YCUXZELOSA-N 0.000 claims description 6
- 235000001465 calcium Nutrition 0.000 claims description 6
- 229960005069 calcium Drugs 0.000 claims description 6
- 229910052791 calcium Inorganic materials 0.000 claims description 6
- 239000011575 calcium Substances 0.000 claims description 6
- 229960000289 fluticasone propionate Drugs 0.000 claims description 6
- WMWTYOKRWGGJOA-CENSZEJFSA-N fluticasone propionate Chemical compound C1([C@@H](F)C2)=CC(=O)C=C[C@]1(C)[C@]1(F)[C@@H]2[C@@H]2C[C@@H](C)[C@@](C(=O)SCF)(OC(=O)CC)[C@@]2(C)C[C@@H]1O WMWTYOKRWGGJOA-CENSZEJFSA-N 0.000 claims description 6
- 208000024908 graft versus host disease Diseases 0.000 claims description 6
- 210000000056 organ Anatomy 0.000 claims description 6
- 201000009890 sinusitis Diseases 0.000 claims description 6
- 229940005605 valeric acid Drugs 0.000 claims description 6
- RDJGLLICXDHJDY-NSHDSACASA-N (2s)-2-(3-phenoxyphenyl)propanoic acid Chemical compound OC(=O)[C@@H](C)C1=CC=CC(OC=2C=CC=CC=2)=C1 RDJGLLICXDHJDY-NSHDSACASA-N 0.000 claims description 5
- GUHPRPJDBZHYCJ-SECBINFHSA-N (2s)-2-(5-benzoylthiophen-2-yl)propanoic acid Chemical compound S1C([C@H](C(O)=O)C)=CC=C1C(=O)C1=CC=CC=C1 GUHPRPJDBZHYCJ-SECBINFHSA-N 0.000 claims description 5
- WHTVZRBIWZFKQO-AWEZNQCLSA-N (S)-chloroquine Chemical compound ClC1=CC=C2C(N[C@@H](C)CCCN(CC)CC)=CC=NC2=C1 WHTVZRBIWZFKQO-AWEZNQCLSA-N 0.000 claims description 5
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 claims description 5
- WNWVKZTYMQWFHE-UHFFFAOYSA-N 4-ethylmorpholine Chemical compound [CH2]CN1CCOCC1 WNWVKZTYMQWFHE-UHFFFAOYSA-N 0.000 claims description 5
- PJJGZPJJTHBVMX-UHFFFAOYSA-N 5,7-Dihydroxyisoflavone Chemical compound C=1C(O)=CC(O)=C(C2=O)C=1OC=C2C1=CC=CC=C1 PJJGZPJJTHBVMX-UHFFFAOYSA-N 0.000 claims description 5
- BSYNRYMUTXBXSQ-FOQJRBATSA-N 59096-14-9 Chemical group CC(=O)OC1=CC=CC=C1[14C](O)=O BSYNRYMUTXBXSQ-FOQJRBATSA-N 0.000 claims description 5
- 241001116389 Aloe Species 0.000 claims description 5
- 201000001320 Atherosclerosis Diseases 0.000 claims description 5
- XHVAWZZCDCWGBK-WYRLRVFGSA-M Aurothioglucose Chemical compound OC[C@H]1O[C@H](S[Au])[C@H](O)[C@@H](O)[C@@H]1O XHVAWZZCDCWGBK-WYRLRVFGSA-M 0.000 claims description 5
- VOVIALXJUBGFJZ-KWVAZRHASA-N Budesonide Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1C[C@H]3OC(CCC)O[C@@]3(C(=O)CO)[C@@]1(C)C[C@@H]2O VOVIALXJUBGFJZ-KWVAZRHASA-N 0.000 claims description 5
- 206010009900 Colitis ulcerative Diseases 0.000 claims description 5
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 claims description 5
- VVNCNSJFMMFHPL-VKHMYHEASA-N D-penicillamine Chemical compound CC(C)(S)[C@@H](N)C(O)=O VVNCNSJFMMFHPL-VKHMYHEASA-N 0.000 claims description 5
- 108010008165 Etanercept Proteins 0.000 claims description 5
- APQPGQGAWABJLN-UHFFFAOYSA-N Floctafenine Chemical compound OCC(O)COC(=O)C1=CC=CC=C1NC1=CC=NC2=C(C(F)(F)F)C=CC=C12 APQPGQGAWABJLN-UHFFFAOYSA-N 0.000 claims description 5
- MUQNGPZZQDCDFT-JNQJZLCISA-N Halcinonide Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@H]3OC(C)(C)O[C@@]3(C(=O)CCl)[C@@]1(C)C[C@@H]2O MUQNGPZZQDCDFT-JNQJZLCISA-N 0.000 claims description 5
- HEFNNWSXXWATRW-UHFFFAOYSA-N Ibuprofen Chemical compound CC(C)CC1=CC=C(C(C)C(O)=O)C=C1 HEFNNWSXXWATRW-UHFFFAOYSA-N 0.000 claims description 5
- SHGAZHPCJJPHSC-NUEINMDLSA-N Isotretinoin Chemical compound OC(=O)C=C(C)/C=C/C=C(C)C=CC1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-NUEINMDLSA-N 0.000 claims description 5
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 claims description 5
- SBDNJUWAMKYJOX-UHFFFAOYSA-N Meclofenamic Acid Chemical compound CC1=CC=C(Cl)C(NC=2C(=CC=CC=2)C(O)=O)=C1Cl SBDNJUWAMKYJOX-UHFFFAOYSA-N 0.000 claims description 5
- ZRVUJXDFFKFLMG-UHFFFAOYSA-N Meloxicam Chemical compound OC=1C2=CC=CC=C2S(=O)(=O)N(C)C=1C(=O)NC1=NC=C(C)S1 ZRVUJXDFFKFLMG-UHFFFAOYSA-N 0.000 claims description 5
- BLXXJMDCKKHMKV-UHFFFAOYSA-N Nabumetone Chemical compound C1=C(CCC(C)=O)C=CC2=CC(OC)=CC=C21 BLXXJMDCKKHMKV-UHFFFAOYSA-N 0.000 claims description 5
- CMWTZPSULFXXJA-UHFFFAOYSA-N Naproxen Natural products C1=C(C(C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-UHFFFAOYSA-N 0.000 claims description 5
- ZGUGWUXLJSTTMA-UHFFFAOYSA-N Promazinum Chemical compound C1=CC=C2N(CCCN(C)C)C3=CC=CC=C3SC2=C1 ZGUGWUXLJSTTMA-UHFFFAOYSA-N 0.000 claims description 5
- 206010063837 Reperfusion injury Diseases 0.000 claims description 5
- 201000006704 Ulcerative Colitis Diseases 0.000 claims description 5
- 229930003779 Vitamin B12 Natural products 0.000 claims description 5
- OGQICQVSFDPSEI-UHFFFAOYSA-N Zorac Chemical compound N1=CC(C(=O)OCC)=CC=C1C#CC1=CC=C(SCCC2(C)C)C2=C1 OGQICQVSFDPSEI-UHFFFAOYSA-N 0.000 claims description 5
- 229960002964 adalimumab Drugs 0.000 claims description 5
- DJHCCTTVDRAMEH-DUUJBDRPSA-N alclometasone dipropionate Chemical compound C([C@H]1Cl)C2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1C[C@@H](C)[C@@](C(=O)COC(=O)CC)(OC(=O)CC)[C@@]1(C)C[C@@H]2O DJHCCTTVDRAMEH-DUUJBDRPSA-N 0.000 claims description 5
- 229960002459 alefacept Drugs 0.000 claims description 5
- 235000011399 aloe vera Nutrition 0.000 claims description 5
- NUZWLKWWNNJHPT-UHFFFAOYSA-N anthralin Chemical compound C1C2=CC=CC(O)=C2C(=O)C2=C1C=CC=C2O NUZWLKWWNNJHPT-UHFFFAOYSA-N 0.000 claims description 5
- AUJRCFUBUPVWSZ-XTZHGVARSA-M auranofin Chemical compound CCP(CC)(CC)=[Au]S[C@@H]1O[C@H](COC(C)=O)[C@@H](OC(C)=O)[C@H](OC(C)=O)[C@H]1OC(C)=O AUJRCFUBUPVWSZ-XTZHGVARSA-M 0.000 claims description 5
- 229960005207 auranofin Drugs 0.000 claims description 5
- 229960001799 aurothioglucose Drugs 0.000 claims description 5
- CUBCNYWQJHBXIY-UHFFFAOYSA-N benzoic acid;2-hydroxybenzoic acid Chemical compound OC(=O)C1=CC=CC=C1.OC(=O)C1=CC=CC=C1O CUBCNYWQJHBXIY-UHFFFAOYSA-N 0.000 claims description 5
- 229960004436 budesonide Drugs 0.000 claims description 5
- 229960002882 calcipotriol Drugs 0.000 claims description 5
- LWQQLNNNIPYSNX-UROSTWAQSA-N calcipotriol Chemical compound C1([C@H](O)/C=C/[C@@H](C)[C@@H]2[C@]3(CCCC(/[C@@H]3CC2)=C\C=C\2C([C@@H](O)C[C@H](O)C/2)=C)C)CC1 LWQQLNNNIPYSNX-UROSTWAQSA-N 0.000 claims description 5
- 201000011510 cancer Diseases 0.000 claims description 5
- 229960003677 chloroquine Drugs 0.000 claims description 5
- WHTVZRBIWZFKQO-UHFFFAOYSA-N chloroquine Natural products ClC1=CC=C2C(NC(C)CCCN(CC)CC)=CC=NC2=C1 WHTVZRBIWZFKQO-UHFFFAOYSA-N 0.000 claims description 5
- 229960003405 ciprofloxacin Drugs 0.000 claims description 5
- 239000011280 coal tar Substances 0.000 claims description 5
- 229960003957 dexamethasone Drugs 0.000 claims description 5
- UREBDLICKHMUKA-CXSFZGCWSA-N dexamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-CXSFZGCWSA-N 0.000 claims description 5
- 229960001259 diclofenac Drugs 0.000 claims description 5
- DCOPUUMXTXDBNB-UHFFFAOYSA-N diclofenac Chemical compound OC(=O)CC1=CC=CC=C1NC1=C(Cl)C=CC=C1Cl DCOPUUMXTXDBNB-UHFFFAOYSA-N 0.000 claims description 5
- 235000015872 dietary supplement Nutrition 0.000 claims description 5
- 229960000616 diflunisal Drugs 0.000 claims description 5
- HUPFGZXOMWLGNK-UHFFFAOYSA-N diflunisal Chemical compound C1=C(O)C(C(=O)O)=CC(C=2C(=CC(F)=CC=2)F)=C1 HUPFGZXOMWLGNK-UHFFFAOYSA-N 0.000 claims description 5
- 229960000403 etanercept Drugs 0.000 claims description 5
- 229960005293 etodolac Drugs 0.000 claims description 5
- 239000004744 fabric Substances 0.000 claims description 5
- 229960001419 fenoprofen Drugs 0.000 claims description 5
- 229960003240 floctafenine Drugs 0.000 claims description 5
- 229960002390 flurbiprofen Drugs 0.000 claims description 5
- SYTBZMRGLBWNTM-UHFFFAOYSA-N flurbiprofen Chemical compound FC1=CC(C(C(O)=O)C)=CC=C1C1=CC=CC=C1 SYTBZMRGLBWNTM-UHFFFAOYSA-N 0.000 claims description 5
- 229940014144 folate Drugs 0.000 claims description 5
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 claims description 5
- 235000019152 folic acid Nutrition 0.000 claims description 5
- 239000011724 folic acid Substances 0.000 claims description 5
- 229960002383 halcinonide Drugs 0.000 claims description 5
- 229910052736 halogen Inorganic materials 0.000 claims description 5
- 229960001680 ibuprofen Drugs 0.000 claims description 5
- 229960000905 indomethacin Drugs 0.000 claims description 5
- 230000002757 inflammatory effect Effects 0.000 claims description 5
- 229960000598 infliximab Drugs 0.000 claims description 5
- 229960005280 isotretinoin Drugs 0.000 claims description 5
- DKYWVDODHFEZIM-UHFFFAOYSA-N ketoprofen Chemical compound OC(=O)C(C)C1=CC=CC(C(=O)C=2C=CC=CC=2)=C1 DKYWVDODHFEZIM-UHFFFAOYSA-N 0.000 claims description 5
- 229960000991 ketoprofen Drugs 0.000 claims description 5
- 229960004752 ketorolac Drugs 0.000 claims description 5
- OZWKMVRBQXNZKK-UHFFFAOYSA-N ketorolac Chemical compound OC(=O)C1CCN2C1=CC=C2C(=O)C1=CC=CC=C1 OZWKMVRBQXNZKK-UHFFFAOYSA-N 0.000 claims description 5
- 235000019341 magnesium sulphate Nutrition 0.000 claims description 5
- 229960003803 meclofenamic acid Drugs 0.000 claims description 5
- 229960003464 mefenamic acid Drugs 0.000 claims description 5
- 229960001929 meloxicam Drugs 0.000 claims description 5
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 claims description 5
- 229960000485 methotrexate Drugs 0.000 claims description 5
- 229960004584 methylprednisolone Drugs 0.000 claims description 5
- VAOCPAMSLUNLGC-UHFFFAOYSA-N metronidazole Chemical compound CC1=NC=C([N+]([O-])=O)N1CCO VAOCPAMSLUNLGC-UHFFFAOYSA-N 0.000 claims description 5
- 229960000282 metronidazole Drugs 0.000 claims description 5
- 229950007856 mofetil Drugs 0.000 claims description 5
- 201000006417 multiple sclerosis Diseases 0.000 claims description 5
- 229960004270 nabumetone Drugs 0.000 claims description 5
- 229960002009 naproxen Drugs 0.000 claims description 5
- CMWTZPSULFXXJA-VIFPVBQESA-N naproxen Chemical compound C1=C([C@H](C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-VIFPVBQESA-N 0.000 claims description 5
- 229960002895 phenylbutazone Drugs 0.000 claims description 5
- VYMDGNCVAMGZFE-UHFFFAOYSA-N phenylbutazonum Chemical compound O=C1C(CCCC)C(=O)N(C=2C=CC=CC=2)N1C1=CC=CC=C1 VYMDGNCVAMGZFE-UHFFFAOYSA-N 0.000 claims description 5
- 229960002702 piroxicam Drugs 0.000 claims description 5
- QYSPLQLAKJAUJT-UHFFFAOYSA-N piroxicam Chemical compound OC=1C2=CC=CC=C2S(=O)(=O)N(C)C=1C(=O)NC1=CC=CC=N1 QYSPLQLAKJAUJT-UHFFFAOYSA-N 0.000 claims description 5
- 229940072689 plaquenil Drugs 0.000 claims description 5
- 229960002794 prednicarbate Drugs 0.000 claims description 5
- FNPXMHRZILFCKX-KAJVQRHHSA-N prednicarbate Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@@](C(=O)COC(=O)CC)(OC(=O)OCC)[C@@]1(C)C[C@@H]2O FNPXMHRZILFCKX-KAJVQRHHSA-N 0.000 claims description 5
- 229960005205 prednisolone Drugs 0.000 claims description 5
- OIGNJSKKLXVSLS-VWUMJDOOSA-N prednisolone Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 OIGNJSKKLXVSLS-VWUMJDOOSA-N 0.000 claims description 5
- 230000008569 process Effects 0.000 claims description 5
- 229960003598 promazine Drugs 0.000 claims description 5
- 229940095574 propionic acid Drugs 0.000 claims description 5
- 235000019260 propionic acid Nutrition 0.000 claims description 5
- 206010039073 rheumatoid arthritis Diseases 0.000 claims description 5
- 229960000371 rofecoxib Drugs 0.000 claims description 5
- RZJQGNCSTQAWON-UHFFFAOYSA-N rofecoxib Chemical compound C1=CC(S(=O)(=O)C)=CC=C1C1=C(C=2C=CC=CC=2)C(=O)OC1 RZJQGNCSTQAWON-UHFFFAOYSA-N 0.000 claims description 5
- WVYADZUPLLSGPU-UHFFFAOYSA-N salsalate Chemical compound OC(=O)C1=CC=CC=C1OC(=O)C1=CC=CC=C1O WVYADZUPLLSGPU-UHFFFAOYSA-N 0.000 claims description 5
- 238000000926 separation method Methods 0.000 claims description 5
- 150000003431 steroids Chemical class 0.000 claims description 5
- 229960000894 sulindac Drugs 0.000 claims description 5
- MLKXDPUZXIRXEP-MFOYZWKCSA-N sulindac Chemical compound CC1=C(CC(O)=O)C2=CC(F)=CC=C2\C1=C/C1=CC=C(S(C)=O)C=C1 MLKXDPUZXIRXEP-MFOYZWKCSA-N 0.000 claims description 5
- 229960000565 tazarotene Drugs 0.000 claims description 5
- 229960002871 tenoxicam Drugs 0.000 claims description 5
- 229960001312 tiaprofenic acid Drugs 0.000 claims description 5
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 claims description 5
- 229960001017 tolmetin Drugs 0.000 claims description 5
- UPSPUYADGBWSHF-UHFFFAOYSA-N tolmetin Chemical compound C1=CC(C)=CC=C1C(=O)C1=CC=C(CC(O)=O)N1C UPSPUYADGBWSHF-UHFFFAOYSA-N 0.000 claims description 5
- 229960002004 valdecoxib Drugs 0.000 claims description 5
- LNPDTQAFDNKSHK-UHFFFAOYSA-N valdecoxib Chemical compound CC=1ON=C(C=2C=CC=CC=2)C=1C1=CC=C(S(N)(=O)=O)C=C1 LNPDTQAFDNKSHK-UHFFFAOYSA-N 0.000 claims description 5
- 229940099259 vaseline Drugs 0.000 claims description 5
- 235000019163 vitamin B12 Nutrition 0.000 claims description 5
- 239000011715 vitamin B12 Substances 0.000 claims description 5
- 206010018691 Granuloma Diseases 0.000 claims description 4
- 102000051628 Interleukin-1 receptor antagonist Human genes 0.000 claims description 4
- 108700021006 Interleukin-1 receptor antagonist Proteins 0.000 claims description 4
- 201000009906 Meningitis Diseases 0.000 claims description 4
- 206010028980 Neoplasm Diseases 0.000 claims description 4
- 206010035664 Pneumonia Diseases 0.000 claims description 4
- 206010040070 Septic Shock Diseases 0.000 claims description 4
- 206010046851 Uveitis Diseases 0.000 claims description 4
- 230000001154 acute effect Effects 0.000 claims description 4
- 208000003455 anaphylaxis Diseases 0.000 claims description 4
- 229960000590 celecoxib Drugs 0.000 claims description 4
- RZEKVGVHFLEQIL-UHFFFAOYSA-N celecoxib Chemical compound C1=CC(C)=CC=C1C1=CC(C(F)(F)F)=NN1C1=CC=C(S(N)(=O)=O)C=C1 RZEKVGVHFLEQIL-UHFFFAOYSA-N 0.000 claims description 4
- 206010014599 encephalitis Diseases 0.000 claims description 4
- 206010014665 endocarditis Diseases 0.000 claims description 4
- 208000001606 epiglottitis Diseases 0.000 claims description 4
- 208000006454 hepatitis Diseases 0.000 claims description 4
- 231100000283 hepatitis Toxicity 0.000 claims description 4
- 230000000302 ischemic effect Effects 0.000 claims description 4
- 229940054136 kineret Drugs 0.000 claims description 4
- KBOPZPXVLCULAV-UHFFFAOYSA-N mesalamine Chemical compound NC1=CC=C(O)C(C(O)=O)=C1 KBOPZPXVLCULAV-UHFFFAOYSA-N 0.000 claims description 4
- 229960004963 mesalazine Drugs 0.000 claims description 4
- 208000031225 myocardial ischemia Diseases 0.000 claims description 4
- 206010034674 peritonitis Diseases 0.000 claims description 4
- 208000037803 restenosis Diseases 0.000 claims description 4
- 206010000228 Abortion infected Diseases 0.000 claims description 3
- 206010001052 Acute respiratory distress syndrome Diseases 0.000 claims description 3
- 206010001889 Alveolitis Diseases 0.000 claims description 3
- 244000036975 Ambrosia artemisiifolia Species 0.000 claims description 3
- 235000003129 Ambrosia artemisiifolia var elatior Nutrition 0.000 claims description 3
- 206010002199 Anaphylactic shock Diseases 0.000 claims description 3
- 208000027496 Behcet disease Diseases 0.000 claims description 3
- 208000009137 Behcet syndrome Diseases 0.000 claims description 3
- 206010006448 Bronchiolitis Diseases 0.000 claims description 3
- 206010006895 Cachexia Diseases 0.000 claims description 3
- 208000015943 Coeliac disease Diseases 0.000 claims description 3
- 206010009895 Colitis ischaemic Diseases 0.000 claims description 3
- 201000003883 Cystic fibrosis Diseases 0.000 claims description 3
- 201000004624 Dermatitis Diseases 0.000 claims description 3
- 206010012438 Dermatitis atopic Diseases 0.000 claims description 3
- 206010014561 Emphysema Diseases 0.000 claims description 3
- 208000004232 Enteritis Diseases 0.000 claims description 3
- 208000000289 Esophageal Achalasia Diseases 0.000 claims description 3
- 206010016228 Fasciitis Diseases 0.000 claims description 3
- 208000024869 Goodpasture syndrome Diseases 0.000 claims description 3
- 201000005569 Gout Diseases 0.000 claims description 3
- 208000009329 Graft vs Host Disease Diseases 0.000 claims description 3
- 208000024781 Immune Complex disease Diseases 0.000 claims description 3
- 208000009525 Myocarditis Diseases 0.000 claims description 3
- 206010029240 Neuritis Diseases 0.000 claims description 3
- 206010030136 Oesophageal achalasia Diseases 0.000 claims description 3
- 208000010191 Osteitis Deformans Diseases 0.000 claims description 3
- 206010031252 Osteomyelitis Diseases 0.000 claims description 3
- 208000027868 Paget disease Diseases 0.000 claims description 3
- 206010033645 Pancreatitis Diseases 0.000 claims description 3
- 208000030852 Parasitic disease Diseases 0.000 claims description 3
- 201000007100 Pharyngitis Diseases 0.000 claims description 3
- 208000003100 Pseudomembranous Enterocolitis Diseases 0.000 claims description 3
- 206010037660 Pyrexia Diseases 0.000 claims description 3
- 208000013616 Respiratory Distress Syndrome Diseases 0.000 claims description 3
- 208000002359 Septic Abortion Diseases 0.000 claims description 3
- 208000007107 Stomach Ulcer Diseases 0.000 claims description 3
- 206010042496 Sunburn Diseases 0.000 claims description 3
- 208000025865 Ulcer Diseases 0.000 claims description 3
- 208000024780 Urticaria Diseases 0.000 claims description 3
- 206010046914 Vaginal infection Diseases 0.000 claims description 3
- 201000008100 Vaginitis Diseases 0.000 claims description 3
- 208000000260 Warts Diseases 0.000 claims description 3
- 208000027207 Whipple disease Diseases 0.000 claims description 3
- 201000000621 achalasia Diseases 0.000 claims description 3
- 208000011341 adult acute respiratory distress syndrome Diseases 0.000 claims description 3
- 201000000028 adult respiratory distress syndrome Diseases 0.000 claims description 3
- 235000003484 annual ragweed Nutrition 0.000 claims description 3
- 208000010123 anthracosis Diseases 0.000 claims description 3
- 206010003230 arteritis Diseases 0.000 claims description 3
- 208000006673 asthma Diseases 0.000 claims description 3
- 201000008937 atopic dermatitis Diseases 0.000 claims description 3
- 206010006451 bronchitis Diseases 0.000 claims description 3
- 235000006263 bur ragweed Nutrition 0.000 claims description 3
- 208000003167 cholangitis Diseases 0.000 claims description 3
- 201000001352 cholecystitis Diseases 0.000 claims description 3
- 235000003488 common ragweed Nutrition 0.000 claims description 3
- 201000001981 dermatomyositis Diseases 0.000 claims description 3
- 208000007784 diverticulitis Diseases 0.000 claims description 3
- 208000000718 duodenal ulcer Diseases 0.000 claims description 3
- 208000026500 emaciation Diseases 0.000 claims description 3
- 201000010063 epididymitis Diseases 0.000 claims description 3
- 201000005917 gastric ulcer Diseases 0.000 claims description 3
- 208000024326 hypersensitivity reaction type III disease Diseases 0.000 claims description 3
- 201000008222 ischemic colitis Diseases 0.000 claims description 3
- 206010025135 lupus erythematosus Diseases 0.000 claims description 3
- 208000027202 mammary Paget disease Diseases 0.000 claims description 3
- 206010028417 myasthenia gravis Diseases 0.000 claims description 3
- 230000017074 necrotic cell death Effects 0.000 claims description 3
- 208000004296 neuralgia Diseases 0.000 claims description 3
- 208000008494 pericarditis Diseases 0.000 claims description 3
- 238000001126 phototherapy Methods 0.000 claims description 3
- 208000008423 pleurisy Diseases 0.000 claims description 3
- 201000006292 polyarteritis nodosa Diseases 0.000 claims description 3
- 201000007094 prostatitis Diseases 0.000 claims description 3
- 235000009736 ragweed Nutrition 0.000 claims description 3
- 230000008521 reorganization Effects 0.000 claims description 3
- 201000003068 rheumatic fever Diseases 0.000 claims description 3
- 206010039083 rhinitis Diseases 0.000 claims description 3
- 201000005404 rubella Diseases 0.000 claims description 3
- 201000000306 sarcoidosis Diseases 0.000 claims description 3
- 208000013223 septicemia Diseases 0.000 claims description 3
- 201000010153 skin papilloma Diseases 0.000 claims description 3
- 201000004595 synovitis Diseases 0.000 claims description 3
- 230000009885 systemic effect Effects 0.000 claims description 3
- 201000005060 thrombophlebitis Diseases 0.000 claims description 3
- 206010043778 thyroiditis Diseases 0.000 claims description 3
- 208000025883 type III hypersensitivity disease Diseases 0.000 claims description 3
- 230000036269 ulceration Effects 0.000 claims description 3
- 208000000143 urethritis Diseases 0.000 claims description 3
- 230000009385 viral infection Effects 0.000 claims description 3
- 208000024172 Cardiovascular disease Diseases 0.000 claims description 2
- 206010016654 Fibrosis Diseases 0.000 claims description 2
- 230000002526 effect on cardiovascular system Effects 0.000 claims description 2
- 230000004761 fibrosis Effects 0.000 claims description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 claims 4
- VHRSUDSXCMQTMA-PJHHCJLFSA-N 6alpha-methylprednisolone Chemical compound C([C@@]12C)=CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2[C@@H](O)C[C@]2(C)[C@@](O)(C(=O)CO)CC[C@H]21 VHRSUDSXCMQTMA-PJHHCJLFSA-N 0.000 claims 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims 2
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims 2
- 102000004877 Insulin Human genes 0.000 claims 2
- 108090001061 Insulin Proteins 0.000 claims 2
- 208000008589 Obesity Diseases 0.000 claims 2
- XJHSMFDIQHVMCY-UHFFFAOYSA-K aurothiomalate(2-) Chemical compound [O-]C(=O)CC(S[Au])C([O-])=O XJHSMFDIQHVMCY-UHFFFAOYSA-K 0.000 claims 2
- FDJOLVPMNUYSCM-WZHZPDAFSA-L cobalt(3+);[(2r,3s,4r,5s)-5-(5,6-dimethylbenzimidazol-1-yl)-4-hydroxy-2-(hydroxymethyl)oxolan-3-yl] [(2r)-1-[3-[(1r,2r,3r,4z,7s,9z,12s,13s,14z,17s,18s,19r)-2,13,18-tris(2-amino-2-oxoethyl)-7,12,17-tris(3-amino-3-oxopropyl)-3,5,8,8,13,15,18,19-octamethyl-2 Chemical compound [Co+3].N#[C-].N([C@@H]([C@]1(C)[N-]\C([C@H]([C@@]1(CC(N)=O)C)CCC(N)=O)=C(\C)/C1=N/C([C@H]([C@@]1(CC(N)=O)C)CCC(N)=O)=C\C1=N\C([C@H](C1(C)C)CCC(N)=O)=C/1C)[C@@H]2CC(N)=O)=C\1[C@]2(C)CCC(=O)NC[C@@H](C)OP([O-])(=O)O[C@H]1[C@@H](O)[C@@H](N2C3=CC(C)=C(C)C=C3N=C2)O[C@@H]1CO FDJOLVPMNUYSCM-WZHZPDAFSA-L 0.000 claims 2
- XXSMGPRMXLTPCZ-UHFFFAOYSA-N hydroxychloroquine Chemical compound ClC1=CC=C2C(NC(C)CCCN(CCO)CC)=CC=NC2=C1 XXSMGPRMXLTPCZ-UHFFFAOYSA-N 0.000 claims 2
- 229940125396 insulin Drugs 0.000 claims 2
- 235000020824 obesity Nutrition 0.000 claims 2
- WZWYJBNHTWCXIM-UHFFFAOYSA-N tenoxicam Chemical compound O=C1C=2SC=CC=2S(=O)(=O)N(C)C1=C(O)NC1=CC=CC=N1 WZWYJBNHTWCXIM-UHFFFAOYSA-N 0.000 claims 2
- 210000004027 cell Anatomy 0.000 description 112
- 229920000642 polymer Polymers 0.000 description 73
- 108090000623 proteins and genes Proteins 0.000 description 51
- 241000699666 Mus <mouse, genus> Species 0.000 description 47
- 108020004414 DNA Proteins 0.000 description 34
- 102000004169 proteins and genes Human genes 0.000 description 28
- 235000018102 proteins Nutrition 0.000 description 27
- 101000897480 Homo sapiens C-C motif chemokine 2 Proteins 0.000 description 20
- 229940024606 amino acid Drugs 0.000 description 20
- 108091028043 Nucleic acid sequence Proteins 0.000 description 18
- 102000039446 nucleic acids Human genes 0.000 description 18
- 108020004707 nucleic acids Proteins 0.000 description 18
- 150000007523 nucleic acids Chemical class 0.000 description 18
- 101710149815 C-C chemokine receptor type 2 Proteins 0.000 description 17
- 102100031151 C-C chemokine receptor type 2 Human genes 0.000 description 17
- 101710155857 C-C motif chemokine 2 Proteins 0.000 description 16
- 239000002299 complementary DNA Substances 0.000 description 16
- 239000000047 product Substances 0.000 description 16
- 241001465754 Metazoa Species 0.000 description 13
- 230000008859 change Effects 0.000 description 13
- 102000004190 Enzymes Human genes 0.000 description 11
- 108090000790 Enzymes Proteins 0.000 description 11
- 108020005038 Terminator Codon Proteins 0.000 description 11
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 11
- 239000003814 drug Substances 0.000 description 11
- 229940088598 enzyme Drugs 0.000 description 11
- 230000001185 psoriatic effect Effects 0.000 description 11
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 10
- 230000000694 effects Effects 0.000 description 10
- 238000009396 hybridization Methods 0.000 description 10
- 239000000243 solution Substances 0.000 description 10
- 210000001519 tissue Anatomy 0.000 description 10
- 241000238631 Hexapoda Species 0.000 description 9
- 108010009817 Immunoglobulin Constant Regions Proteins 0.000 description 9
- 102000009786 Immunoglobulin Constant Regions Human genes 0.000 description 9
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 9
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 9
- 239000002585 base Substances 0.000 description 9
- 238000006243 chemical reaction Methods 0.000 description 9
- 239000000463 material Substances 0.000 description 9
- 210000002966 serum Anatomy 0.000 description 9
- 239000003981 vehicle Substances 0.000 description 9
- 108020004705 Codon Proteins 0.000 description 8
- 102000008186 Collagen Human genes 0.000 description 8
- 108010035532 Collagen Proteins 0.000 description 8
- 241000588724 Escherichia coli Species 0.000 description 8
- 230000037396 body weight Effects 0.000 description 8
- 239000000872 buffer Substances 0.000 description 8
- 230000012292 cell migration Effects 0.000 description 8
- 229920001436 collagen Polymers 0.000 description 8
- 239000000539 dimer Substances 0.000 description 8
- 230000000968 intestinal effect Effects 0.000 description 8
- 238000010369 molecular cloning Methods 0.000 description 8
- 230000002265 prevention Effects 0.000 description 8
- 239000002904 solvent Substances 0.000 description 8
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 8
- 239000003153 chemical reaction reagent Substances 0.000 description 7
- 230000008961 swelling Effects 0.000 description 7
- 238000001890 transfection Methods 0.000 description 7
- 239000013598 vector Substances 0.000 description 7
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 6
- 206010061218 Inflammation Diseases 0.000 description 6
- 238000010240 RT-PCR analysis Methods 0.000 description 6
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- AUZONCFQVSMFAP-UHFFFAOYSA-N disulfiram Chemical compound CCN(CC)C(=S)SSC(=S)N(CC)CC AUZONCFQVSMFAP-UHFFFAOYSA-N 0.000 description 6
- 239000002552 dosage form Substances 0.000 description 6
- 239000000839 emulsion Substances 0.000 description 6
- 201000002491 encephalomyelitis Diseases 0.000 description 6
- 235000001727 glucose Nutrition 0.000 description 6
- 239000008103 glucose Substances 0.000 description 6
- 230000004054 inflammatory process Effects 0.000 description 6
- 230000004048 modification Effects 0.000 description 6
- 238000012986 modification Methods 0.000 description 6
- 238000012544 monitoring process Methods 0.000 description 6
- ZCCUUQDIBDJBTK-UHFFFAOYSA-N psoralen Chemical compound C1=C2OC(=O)C=CC2=CC2=C1OC=C2 ZCCUUQDIBDJBTK-UHFFFAOYSA-N 0.000 description 6
- 238000010254 subcutaneous injection Methods 0.000 description 6
- 239000007929 subcutaneous injection Substances 0.000 description 6
- 208000024891 symptom Diseases 0.000 description 6
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 5
- 108010016626 Dipeptides Proteins 0.000 description 5
- VGGSQFUCUMXWEO-UHFFFAOYSA-N Ethene Chemical compound C=C VGGSQFUCUMXWEO-UHFFFAOYSA-N 0.000 description 5
- BCCRXDTUTZHDEU-VKHMYHEASA-N Gly-Ser Chemical compound NCC(=O)N[C@@H](CO)C(O)=O BCCRXDTUTZHDEU-VKHMYHEASA-N 0.000 description 5
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 5
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 5
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 5
- 108091034117 Oligonucleotide Proteins 0.000 description 5
- 229930006000 Sucrose Natural products 0.000 description 5
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 210000004899 c-terminal region Anatomy 0.000 description 5
- 150000001875 compounds Chemical class 0.000 description 5
- 230000000875 corresponding effect Effects 0.000 description 5
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 5
- 239000000975 dye Substances 0.000 description 5
- 230000003203 everyday effect Effects 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 239000008101 lactose Substances 0.000 description 5
- 239000007788 liquid Substances 0.000 description 5
- 239000005720 sucrose Substances 0.000 description 5
- 241000699802 Cricetulus griseus Species 0.000 description 4
- 239000005977 Ethylene Substances 0.000 description 4
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 4
- 241000187479 Mycobacterium tuberculosis Species 0.000 description 4
- 229920002472 Starch Polymers 0.000 description 4
- 239000002671 adjuvant Substances 0.000 description 4
- 230000002917 arthritic effect Effects 0.000 description 4
- 230000001580 bacterial effect Effects 0.000 description 4
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 4
- 239000002775 capsule Substances 0.000 description 4
- 229920001577 copolymer Polymers 0.000 description 4
- 239000008121 dextrose Substances 0.000 description 4
- 239000003995 emulsifying agent Substances 0.000 description 4
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 4
- 230000013595 glycosylation Effects 0.000 description 4
- 238000002649 immunization Methods 0.000 description 4
- 230000003053 immunization Effects 0.000 description 4
- 210000004962 mammalian cell Anatomy 0.000 description 4
- VNWKTOKETHGBQD-UHFFFAOYSA-N methane Natural products C VNWKTOKETHGBQD-UHFFFAOYSA-N 0.000 description 4
- 210000001616 monocyte Anatomy 0.000 description 4
- 210000001672 ovary Anatomy 0.000 description 4
- 239000011049 pearl Substances 0.000 description 4
- YBYRMVIVWMBXKQ-UHFFFAOYSA-N phenylmethanesulfonyl fluoride Chemical compound FS(=O)(=O)CC1=CC=CC=C1 YBYRMVIVWMBXKQ-UHFFFAOYSA-N 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 239000002516 radical scavenger Substances 0.000 description 4
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 4
- 239000001488 sodium phosphate Substances 0.000 description 4
- 235000011008 sodium phosphates Nutrition 0.000 description 4
- 239000007787 solid Substances 0.000 description 4
- 241000894007 species Species 0.000 description 4
- 235000019698 starch Nutrition 0.000 description 4
- 239000008107 starch Substances 0.000 description 4
- 229940032147 starch Drugs 0.000 description 4
- 208000011580 syndromic disease Diseases 0.000 description 4
- 239000003826 tablet Substances 0.000 description 4
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 4
- 238000005406 washing Methods 0.000 description 4
- 230000003442 weekly effect Effects 0.000 description 4
- JCBIVZZPXRZKTI-UHFFFAOYSA-N 2-[4-[(7-chloroquinolin-4-yl)amino]pentyl-ethylamino]ethanol;sulfuric acid Chemical compound OS(O)(=O)=O.ClC1=CC=C2C(NC(C)CCCN(CCO)CC)=CC=NC2=C1 JCBIVZZPXRZKTI-UHFFFAOYSA-N 0.000 description 3
- 108010017312 CCR2 Receptors Proteins 0.000 description 3
- 102000004497 CCR2 Receptors Human genes 0.000 description 3
- 241000701022 Cytomegalovirus Species 0.000 description 3
- 239000004278 EU approved seasoning Substances 0.000 description 3
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 3
- FQISKWAFAHGMGT-SGJOWKDISA-M Methylprednisolone sodium succinate Chemical compound [Na+].C([C@@]12C)=CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2[C@@H](O)C[C@]2(C)[C@@](O)(C(=O)COC(=O)CCC([O-])=O)CC[C@H]21 FQISKWAFAHGMGT-SGJOWKDISA-M 0.000 description 3
- 206010035226 Plasma cell myeloma Diseases 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 201000001263 Psoriatic Arthritis Diseases 0.000 description 3
- 208000036824 Psoriatic arthropathy Diseases 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- 241000700605 Viruses Species 0.000 description 3
- DPDMMXDBJGCCQC-UHFFFAOYSA-N [Na].[Cl] Chemical compound [Na].[Cl] DPDMMXDBJGCCQC-UHFFFAOYSA-N 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- 239000002260 anti-inflammatory agent Substances 0.000 description 3
- 229940121363 anti-inflammatory agent Drugs 0.000 description 3
- 239000003963 antioxidant agent Substances 0.000 description 3
- 230000003078 antioxidant effect Effects 0.000 description 3
- 210000000709 aorta Anatomy 0.000 description 3
- 206010003246 arthritis Diseases 0.000 description 3
- 238000003556 assay Methods 0.000 description 3
- 230000003115 biocidal effect Effects 0.000 description 3
- 239000003139 biocide Substances 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 238000004820 blood count Methods 0.000 description 3
- 244000309466 calf Species 0.000 description 3
- 210000003169 central nervous system Anatomy 0.000 description 3
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 239000013599 cloning vector Substances 0.000 description 3
- AGVAZMGAQJOSFJ-WZHZPDAFSA-M cobalt(2+);[(2r,3s,4r,5s)-5-(5,6-dimethylbenzimidazol-1-yl)-4-hydroxy-2-(hydroxymethyl)oxolan-3-yl] [(2r)-1-[3-[(1r,2r,3r,4z,7s,9z,12s,13s,14z,17s,18s,19r)-2,13,18-tris(2-amino-2-oxoethyl)-7,12,17-tris(3-amino-3-oxopropyl)-3,5,8,8,13,15,18,19-octamethyl-2 Chemical compound [Co+2].N#[C-].[N-]([C@@H]1[C@H](CC(N)=O)[C@@]2(C)CCC(=O)NC[C@@H](C)OP(O)(=O)O[C@H]3[C@H]([C@H](O[C@@H]3CO)N3C4=CC(C)=C(C)C=C4N=C3)O)\C2=C(C)/C([C@H](C\2(C)C)CCC(N)=O)=N/C/2=C\C([C@H]([C@@]/2(CC(N)=O)C)CCC(N)=O)=N\C\2=C(C)/C2=N[C@]1(C)[C@@](C)(CC(N)=O)[C@@H]2CCC(N)=O AGVAZMGAQJOSFJ-WZHZPDAFSA-M 0.000 description 3
- 238000013016 damping Methods 0.000 description 3
- 238000000586 desensitisation Methods 0.000 description 3
- VXIHRIQNJCRFQX-UHFFFAOYSA-K disodium aurothiomalate Chemical compound [Na+].[Na+].[O-]C(=O)CC(S[Au])C([O-])=O VXIHRIQNJCRFQX-UHFFFAOYSA-K 0.000 description 3
- 229940079593 drug Drugs 0.000 description 3
- 238000002474 experimental method Methods 0.000 description 3
- 239000012530 fluid Substances 0.000 description 3
- 235000011194 food seasoning agent Nutrition 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- BRZYSWJRSDMWLG-CAXSIQPQSA-N geneticin Natural products O1C[C@@](O)(C)[C@H](NC)[C@@H](O)[C@H]1O[C@@H]1[C@@H](O)[C@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](C(C)O)O2)N)[C@@H](N)C[C@H]1N BRZYSWJRSDMWLG-CAXSIQPQSA-N 0.000 description 3
- 238000006206 glycosylation reaction Methods 0.000 description 3
- 238000004128 high performance liquid chromatography Methods 0.000 description 3
- 102000046768 human CCL2 Human genes 0.000 description 3
- 230000036039 immunity Effects 0.000 description 3
- 238000007912 intraperitoneal administration Methods 0.000 description 3
- MOYKHGMNXAOIAT-JGWLITMVSA-N isosorbide dinitrate Chemical compound [O-][N+](=O)O[C@H]1CO[C@@H]2[C@H](O[N+](=O)[O-])CO[C@@H]21 MOYKHGMNXAOIAT-JGWLITMVSA-N 0.000 description 3
- 229960000201 isosorbide dinitrate Drugs 0.000 description 3
- JVTAAEKCZFNVCJ-UHFFFAOYSA-N lactic acid Chemical class CC(O)C(O)=O JVTAAEKCZFNVCJ-UHFFFAOYSA-N 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 239000000314 lubricant Substances 0.000 description 3
- 229930182817 methionine Natural products 0.000 description 3
- 201000000050 myeloid neoplasm Diseases 0.000 description 3
- 239000000041 non-steroidal anti-inflammatory agent Substances 0.000 description 3
- 229940021182 non-steroidal anti-inflammatory drug Drugs 0.000 description 3
- 238000007899 nucleic acid hybridization Methods 0.000 description 3
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 3
- 230000036961 partial effect Effects 0.000 description 3
- 239000002953 phosphate buffered saline Substances 0.000 description 3
- 210000002381 plasma Anatomy 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- 238000003752 polymerase chain reaction Methods 0.000 description 3
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 3
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 239000003352 sequestering agent Substances 0.000 description 3
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 3
- 210000000278 spinal cord Anatomy 0.000 description 3
- 238000003153 stable transfection Methods 0.000 description 3
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- LZNWYQJJBLGYLT-UHFFFAOYSA-N tenoxicam Chemical compound OC=1C=2SC=CC=2S(=O)(=O)N(C)C=1C(=O)NC1=CC=CC=N1 LZNWYQJJBLGYLT-UHFFFAOYSA-N 0.000 description 3
- 238000012360 testing method Methods 0.000 description 3
- 235000013619 trace mineral Nutrition 0.000 description 3
- 239000011573 trace mineral Substances 0.000 description 3
- 238000013518 transcription Methods 0.000 description 3
- 230000035897 transcription Effects 0.000 description 3
- 241000701447 unidentified baculovirus Species 0.000 description 3
- 239000000080 wetting agent Substances 0.000 description 3
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 description 2
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 description 2
- ODHCTXKNWHHXJC-VKHMYHEASA-N 5-oxo-L-proline Chemical compound OC(=O)[C@@H]1CCC(=O)N1 ODHCTXKNWHHXJC-VKHMYHEASA-N 0.000 description 2
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 description 2
- 101100230376 Acetivibrio thermocellus (strain ATCC 27405 / DSM 1237 / JCM 9322 / NBRC 103400 / NCIMB 10682 / NRRL B-4536 / VPI 7372) celI gene Proteins 0.000 description 2
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 208000032116 Autoimmune Experimental Encephalomyelitis Diseases 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 102100036850 C-C motif chemokine 23 Human genes 0.000 description 2
- 102100021936 C-C motif chemokine 27 Human genes 0.000 description 2
- 101710112538 C-C motif chemokine 27 Proteins 0.000 description 2
- 206010057248 Cell death Diseases 0.000 description 2
- 229920000623 Cellulose acetate phthalate Polymers 0.000 description 2
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- 206010009944 Colon cancer Diseases 0.000 description 2
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 2
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 2
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 2
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 2
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 2
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 2
- 241000196324 Embryophyta Species 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 241000233866 Fungi Species 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 206010019280 Heart failures Diseases 0.000 description 2
- 101001046686 Homo sapiens Integrin alpha-M Proteins 0.000 description 2
- 101000947178 Homo sapiens Platelet basic protein Proteins 0.000 description 2
- 241000598436 Human T-cell lymphotropic virus Species 0.000 description 2
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 2
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 2
- 102100022338 Integrin alpha-M Human genes 0.000 description 2
- 108010002386 Interleukin-3 Proteins 0.000 description 2
- 108020004684 Internal Ribosome Entry Sites Proteins 0.000 description 2
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 2
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- 229930195725 Mannitol Natural products 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 101000777597 Mus musculus C-C chemokine receptor type 2 Proteins 0.000 description 2
- XUYPXLNMDZIRQH-LURJTMIESA-N N-acetyl-L-methionine Chemical compound CSCC[C@@H](C(O)=O)NC(C)=O XUYPXLNMDZIRQH-LURJTMIESA-N 0.000 description 2
- 206010028851 Necrosis Diseases 0.000 description 2
- 239000005642 Oleic acid Substances 0.000 description 2
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 229930182555 Penicillin Natural products 0.000 description 2
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 2
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 2
- 102100036154 Platelet basic protein Human genes 0.000 description 2
- 239000004698 Polyethylene Substances 0.000 description 2
- 108010076504 Protein Sorting Signals Proteins 0.000 description 2
- 206010037575 Pustular psoriasis Diseases 0.000 description 2
- 239000012980 RPMI-1640 medium Substances 0.000 description 2
- 208000012322 Raynaud phenomenon Diseases 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 229920002684 Sepharose Polymers 0.000 description 2
- 229920001800 Shellac Polymers 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- 208000006011 Stroke Diseases 0.000 description 2
- 210000001744 T-lymphocyte Anatomy 0.000 description 2
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 2
- 101710120037 Toxin CcdB Proteins 0.000 description 2
- 108700009124 Transcription Initiation Site Proteins 0.000 description 2
- 241000255993 Trichoplusia ni Species 0.000 description 2
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 2
- 230000003213 activating effect Effects 0.000 description 2
- 239000000654 additive Substances 0.000 description 2
- 230000000996 additive effect Effects 0.000 description 2
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 210000004102 animal cell Anatomy 0.000 description 2
- 239000008135 aqueous vehicle Substances 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 235000003704 aspartic acid Nutrition 0.000 description 2
- 210000003719 b-lymphocyte Anatomy 0.000 description 2
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000007853 buffer solution Substances 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 229940081734 cellulose acetate phthalate Drugs 0.000 description 2
- 238000002052 colonoscopy Methods 0.000 description 2
- 201000010989 colorectal carcinoma Diseases 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 239000003636 conditioned culture medium Substances 0.000 description 2
- 230000001276 controlling effect Effects 0.000 description 2
- 230000009089 cytolysis Effects 0.000 description 2
- 230000006378 damage Effects 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 238000006471 dimerization reaction Methods 0.000 description 2
- 239000004205 dimethyl polysiloxane Substances 0.000 description 2
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 2
- 208000035475 disorder Diseases 0.000 description 2
- 239000006185 dispersion Substances 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 238000001035 drying Methods 0.000 description 2
- 229920001971 elastomer Polymers 0.000 description 2
- 239000002895 emetic Substances 0.000 description 2
- 238000007459 endoscopic retrograde cholangiopancreatography Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 210000003527 eukaryotic cell Anatomy 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 208000012997 experimental autoimmune encephalomyelitis Diseases 0.000 description 2
- 239000007888 film coating Substances 0.000 description 2
- 238000009501 film coating Methods 0.000 description 2
- 210000002683 foot Anatomy 0.000 description 2
- 210000002080 free macrophage Anatomy 0.000 description 2
- 239000000499 gel Substances 0.000 description 2
- 229960002989 glutamic acid Drugs 0.000 description 2
- 235000011187 glycerol Nutrition 0.000 description 2
- 239000001963 growth medium Substances 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 238000010376 human cloning Methods 0.000 description 2
- 208000015181 infectious disease Diseases 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 238000010253 intravenous injection Methods 0.000 description 2
- 238000011835 investigation Methods 0.000 description 2
- 150000002500 ions Chemical class 0.000 description 2
- 230000001788 irregular Effects 0.000 description 2
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 description 2
- 239000007951 isotonicity adjuster Substances 0.000 description 2
- 210000003734 kidney Anatomy 0.000 description 2
- 229940070765 laurate Drugs 0.000 description 2
- 125000005647 linker group Chemical group 0.000 description 2
- 229960005015 local anesthetics Drugs 0.000 description 2
- 108010019677 lymphotactin Proteins 0.000 description 2
- 229920001427 mPEG Polymers 0.000 description 2
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 2
- 239000000594 mannitol Substances 0.000 description 2
- 235000010355 mannitol Nutrition 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 210000003071 memory t lymphocyte Anatomy 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 238000010232 migration assay Methods 0.000 description 2
- 108010064578 myelin proteolipid protein (139-151) Proteins 0.000 description 2
- 208000010125 myocardial infarction Diseases 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 229940049954 penicillin Drugs 0.000 description 2
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 230000000144 pharmacologic effect Effects 0.000 description 2
- 239000010452 phosphate Substances 0.000 description 2
- 239000006187 pill Substances 0.000 description 2
- 229920000435 poly(dimethylsiloxane) Polymers 0.000 description 2
- 230000008488 polyadenylation Effects 0.000 description 2
- 229920000573 polyethylene Polymers 0.000 description 2
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 2
- 229920000053 polysorbate 80 Polymers 0.000 description 2
- 229920000915 polyvinyl chloride Polymers 0.000 description 2
- 239000004800 polyvinyl chloride Substances 0.000 description 2
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 2
- 230000004481 post-translational protein modification Effects 0.000 description 2
- 238000001556 precipitation Methods 0.000 description 2
- QQONPFPTGQHPMA-UHFFFAOYSA-N propylene Natural products CC=C QQONPFPTGQHPMA-UHFFFAOYSA-N 0.000 description 2
- QELSKZZBTMNZEB-UHFFFAOYSA-N propylparaben Chemical compound CCCOC(=O)C1=CC=C(O)C=C1 QELSKZZBTMNZEB-UHFFFAOYSA-N 0.000 description 2
- 238000001742 protein purification Methods 0.000 description 2
- 229940079889 pyrrolidonecarboxylic acid Drugs 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 210000000664 rectum Anatomy 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 125000002652 ribonucleotide group Chemical group 0.000 description 2
- 150000003839 salts Chemical class 0.000 description 2
- 210000000582 semen Anatomy 0.000 description 2
- 239000004208 shellac Substances 0.000 description 2
- 229940113147 shellac Drugs 0.000 description 2
- 235000013874 shellac Nutrition 0.000 description 2
- ZLGIYFNHBLSMPS-ATJNOEHPSA-N shellac Chemical compound OCCCCCC(O)C(O)CCCCCCCC(O)=O.C1C23[C@H](C(O)=O)CCC2[C@](C)(CO)[C@@H]1C(C(O)=O)=C[C@@H]3O ZLGIYFNHBLSMPS-ATJNOEHPSA-N 0.000 description 2
- 229920002379 silicone rubber Polymers 0.000 description 2
- 239000004945 silicone rubber Substances 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- 229910052708 sodium Inorganic materials 0.000 description 2
- 229960005322 streptomycin Drugs 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 239000000375 suspending agent Substances 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- LWIHDJKSTIGBAC-UHFFFAOYSA-K tripotassium phosphate Chemical compound [K+].[K+].[K+].[O-]P([O-])([O-])=O LWIHDJKSTIGBAC-UHFFFAOYSA-K 0.000 description 2
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- JHPBZFOKBAGZBL-UHFFFAOYSA-N (3-hydroxy-2,2,4-trimethylpentyl) 2-methylprop-2-enoate Chemical compound CC(C)C(O)C(C)(C)COC(=O)C(C)=C JHPBZFOKBAGZBL-UHFFFAOYSA-N 0.000 description 1
- JGMYDQCXGIMHLL-AATRIKPKSA-N (e)-11-hexadecenoic acid Chemical compound CCCC\C=C\CCCCCCCCCC(O)=O JGMYDQCXGIMHLL-AATRIKPKSA-N 0.000 description 1
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- DDMOUSALMHHKOS-UHFFFAOYSA-N 1,2-dichloro-1,1,2,2-tetrafluoroethane Chemical compound FC(F)(Cl)C(F)(F)Cl DDMOUSALMHHKOS-UHFFFAOYSA-N 0.000 description 1
- UHDGCWIWMRVCDJ-UHFFFAOYSA-N 1-beta-D-Xylofuranosyl-NH-Cytosine Natural products O=C1N=C(N)C=CN1C1C(O)C(O)C(CO)O1 UHDGCWIWMRVCDJ-UHFFFAOYSA-N 0.000 description 1
- OEPOKWHJYJXUGD-UHFFFAOYSA-N 2-(3-phenylmethoxyphenyl)-1,3-thiazole-4-carbaldehyde Chemical compound O=CC1=CSC(C=2C=C(OCC=3C=CC=CC=3)C=CC=2)=N1 OEPOKWHJYJXUGD-UHFFFAOYSA-N 0.000 description 1
- FKOKUHFZNIUSLW-UHFFFAOYSA-N 2-Hydroxypropyl stearate Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(C)O FKOKUHFZNIUSLW-UHFFFAOYSA-N 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- YKBGVTZYEHREMT-UHFFFAOYSA-N 2-amino-9-[4-hydroxy-5-(hydroxymethyl)oxolan-2-yl]-3h-purin-6-one Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1C1CC(O)C(CO)O1 YKBGVTZYEHREMT-UHFFFAOYSA-N 0.000 description 1
- 102100029632 28S ribosomal protein S11, mitochondrial Human genes 0.000 description 1
- WRDABNWSWOHGMS-UHFFFAOYSA-N AEBSF hydrochloride Chemical compound Cl.NCCC1=CC=C(S(F)(=O)=O)C=C1 WRDABNWSWOHGMS-UHFFFAOYSA-N 0.000 description 1
- NIXOWILDQLNWCW-UHFFFAOYSA-N Acrylic acid Chemical compound OC(=O)C=C NIXOWILDQLNWCW-UHFFFAOYSA-N 0.000 description 1
- 101000689231 Aeromonas salmonicida S-layer protein Proteins 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 1
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 101710189683 Alkaline protease 1 Proteins 0.000 description 1
- 101710154562 Alkaline proteinase Proteins 0.000 description 1
- 239000005995 Aluminium silicate Substances 0.000 description 1
- QGZKDVFQNNGYKY-UHFFFAOYSA-O Ammonium Chemical compound [NH4+] QGZKDVFQNNGYKY-UHFFFAOYSA-O 0.000 description 1
- 206010002198 Anaphylactic reaction Diseases 0.000 description 1
- 206010002383 Angina Pectoris Diseases 0.000 description 1
- 206010002388 Angina unstable Diseases 0.000 description 1
- 206010002556 Ankylosing Spondylitis Diseases 0.000 description 1
- 208000008822 Ankylosis Diseases 0.000 description 1
- 101710170876 Antileukoproteinase Proteins 0.000 description 1
- 206010002921 Aortitis Diseases 0.000 description 1
- 101000716807 Arabidopsis thaliana Protein SCO1 homolog 1, mitochondrial Proteins 0.000 description 1
- 101000716806 Arabidopsis thaliana Protein SCO1 homolog 2, mitochondrial Proteins 0.000 description 1
- 200000000007 Arterial disease Diseases 0.000 description 1
- 206010003210 Arteriosclerosis Diseases 0.000 description 1
- 206010003226 Arteriovenous fistula Diseases 0.000 description 1
- 208000006820 Arthralgia Diseases 0.000 description 1
- 206010053555 Arthritis bacterial Diseases 0.000 description 1
- 208000006740 Aseptic Meningitis Diseases 0.000 description 1
- 208000037260 Atherosclerotic Plaque Diseases 0.000 description 1
- 206010003658 Atrial Fibrillation Diseases 0.000 description 1
- 208000002102 Atrial Premature Complexes Diseases 0.000 description 1
- 206010003671 Atrioventricular Block Diseases 0.000 description 1
- 241001112741 Bacillaceae Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- WVDDGKGOMKODPV-UHFFFAOYSA-N Benzyl alcohol Chemical compound OCC1=CC=CC=C1 WVDDGKGOMKODPV-UHFFFAOYSA-N 0.000 description 1
- 206010005003 Bladder cancer Diseases 0.000 description 1
- 241001416152 Bos frontalis Species 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 208000033386 Buerger disease Diseases 0.000 description 1
- 206010006578 Bundle-Branch Block Diseases 0.000 description 1
- SOGAXMICEFXMKE-UHFFFAOYSA-N Butylmethacrylate Chemical compound CCCCOC(=O)C(C)=C SOGAXMICEFXMKE-UHFFFAOYSA-N 0.000 description 1
- 102100023702 C-C motif chemokine 13 Human genes 0.000 description 1
- 102100023700 C-C motif chemokine 16 Human genes 0.000 description 1
- 102100023698 C-C motif chemokine 17 Human genes 0.000 description 1
- 102100036842 C-C motif chemokine 19 Human genes 0.000 description 1
- 101710112622 C-C motif chemokine 19 Proteins 0.000 description 1
- 102100036848 C-C motif chemokine 20 Human genes 0.000 description 1
- 102100036846 C-C motif chemokine 21 Human genes 0.000 description 1
- 102100036849 C-C motif chemokine 24 Human genes 0.000 description 1
- 102100021933 C-C motif chemokine 25 Human genes 0.000 description 1
- 102100021935 C-C motif chemokine 26 Human genes 0.000 description 1
- 102100021942 C-C motif chemokine 28 Human genes 0.000 description 1
- 102100032367 C-C motif chemokine 5 Human genes 0.000 description 1
- 102100032366 C-C motif chemokine 7 Human genes 0.000 description 1
- 102100034871 C-C motif chemokine 8 Human genes 0.000 description 1
- 108010074051 C-Reactive Protein Proteins 0.000 description 1
- 102100025279 C-X-C motif chemokine 11 Human genes 0.000 description 1
- 101710098272 C-X-C motif chemokine 11 Proteins 0.000 description 1
- 102100025277 C-X-C motif chemokine 13 Human genes 0.000 description 1
- 102100025250 C-X-C motif chemokine 14 Human genes 0.000 description 1
- 102100039398 C-X-C motif chemokine 2 Human genes 0.000 description 1
- 102100036150 C-X-C motif chemokine 5 Human genes 0.000 description 1
- 102100036153 C-X-C motif chemokine 6 Human genes 0.000 description 1
- 102100036170 C-X-C motif chemokine 9 Human genes 0.000 description 1
- 101710085500 C-X-C motif chemokine 9 Proteins 0.000 description 1
- 102100032752 C-reactive protein Human genes 0.000 description 1
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 1
- 101150093802 CXCL1 gene Proteins 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 206010007559 Cardiac failure congestive Diseases 0.000 description 1
- 208000031229 Cardiomyopathies Diseases 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 206010008190 Cerebrovascular accident Diseases 0.000 description 1
- 108010082548 Chemokine CCL11 Proteins 0.000 description 1
- 108010083647 Chemokine CCL24 Proteins 0.000 description 1
- 108010083698 Chemokine CCL26 Proteins 0.000 description 1
- 108010055166 Chemokine CCL5 Proteins 0.000 description 1
- 108010078239 Chemokine CX3CL1 Proteins 0.000 description 1
- 102000016950 Chemokine CXCL1 Human genes 0.000 description 1
- 108010014419 Chemokine CXCL1 Proteins 0.000 description 1
- 239000004709 Chlorinated polyethylene Substances 0.000 description 1
- 108090000317 Chymotrypsin Proteins 0.000 description 1
- 108060005980 Collagenase Proteins 0.000 description 1
- 102000029816 Collagenase Human genes 0.000 description 1
- 206010056370 Congestive cardiomyopathy Diseases 0.000 description 1
- 102400000498 Connective tissue-activating peptide III Human genes 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 201000006306 Cor pulmonale Diseases 0.000 description 1
- 208000023374 Crohn jejunoileitis Diseases 0.000 description 1
- 229920002785 Croscarmellose sodium Polymers 0.000 description 1
- 206010011703 Cyanosis Diseases 0.000 description 1
- 229920000858 Cyclodextrin Polymers 0.000 description 1
- UHDGCWIWMRVCDJ-PSQAKQOGSA-N Cytidine Natural products O=C1N=C(N)C=CN1[C@@H]1[C@@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-PSQAKQOGSA-N 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 230000004544 DNA amplification Effects 0.000 description 1
- 206010012310 Dengue fever Diseases 0.000 description 1
- 102100031107 Disintegrin and metalloproteinase domain-containing protein 11 Human genes 0.000 description 1
- 101710121366 Disintegrin and metalloproteinase domain-containing protein 11 Proteins 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 102000016942 Elastin Human genes 0.000 description 1
- 108010014258 Elastin Proteins 0.000 description 1
- 206010014759 Endometrial neoplasm Diseases 0.000 description 1
- 102100023688 Eotaxin Human genes 0.000 description 1
- IMROMDMJAWUWLK-UHFFFAOYSA-N Ethenol Chemical compound OC=C IMROMDMJAWUWLK-UHFFFAOYSA-N 0.000 description 1
- 208000004248 Familial Primary Pulmonary Hypertension Diseases 0.000 description 1
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 1
- 102000013818 Fractalkine Human genes 0.000 description 1
- 229930091371 Fructose Natural products 0.000 description 1
- 239000005715 Fructose Substances 0.000 description 1
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 1
- 108010001515 Galectin 4 Proteins 0.000 description 1
- 102100039556 Galectin-4 Human genes 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 201000000628 Gas Gangrene Diseases 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 102100034221 Growth-regulated alpha protein Human genes 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 208000032759 Hemolytic-Uremic Syndrome Diseases 0.000 description 1
- 208000032843 Hemorrhage Diseases 0.000 description 1
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 1
- 208000009889 Herpes Simplex Diseases 0.000 description 1
- 244000043261 Hevea brasiliensis Species 0.000 description 1
- 101000777599 Homo sapiens C-C chemokine receptor type 2 Proteins 0.000 description 1
- 101000978362 Homo sapiens C-C motif chemokine 17 Proteins 0.000 description 1
- 101000713099 Homo sapiens C-C motif chemokine 20 Proteins 0.000 description 1
- 101000713085 Homo sapiens C-C motif chemokine 21 Proteins 0.000 description 1
- 101000713081 Homo sapiens C-C motif chemokine 23 Proteins 0.000 description 1
- 101000897486 Homo sapiens C-C motif chemokine 25 Proteins 0.000 description 1
- 101000897477 Homo sapiens C-C motif chemokine 28 Proteins 0.000 description 1
- 101000797758 Homo sapiens C-C motif chemokine 7 Proteins 0.000 description 1
- 101000858064 Homo sapiens C-X-C motif chemokine 13 Proteins 0.000 description 1
- 101000858068 Homo sapiens C-X-C motif chemokine 14 Proteins 0.000 description 1
- 101000889128 Homo sapiens C-X-C motif chemokine 2 Proteins 0.000 description 1
- 101100382872 Homo sapiens CCL13 gene Proteins 0.000 description 1
- 101100382876 Homo sapiens CCL16 gene Proteins 0.000 description 1
- 101100005560 Homo sapiens CCL23 gene Proteins 0.000 description 1
- 101100441523 Homo sapiens CXCL5 gene Proteins 0.000 description 1
- 101000883515 Homo sapiens Chitinase-3-like protein 1 Proteins 0.000 description 1
- 101001058904 Homo sapiens Gamma-tubulin complex component 2 Proteins 0.000 description 1
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 description 1
- 101001014636 Homo sapiens Golgin subfamily A member 4 Proteins 0.000 description 1
- 101000973997 Homo sapiens Nucleosome assembly protein 1-like 4 Proteins 0.000 description 1
- 101000582950 Homo sapiens Platelet factor 4 Proteins 0.000 description 1
- 101001076715 Homo sapiens RNA-binding protein 39 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 241000700588 Human alphaherpesvirus 1 Species 0.000 description 1
- 241000701074 Human alphaherpesvirus 2 Species 0.000 description 1
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 1
- 206010020772 Hypertension Diseases 0.000 description 1
- 208000004575 Infectious Arthritis Diseases 0.000 description 1
- 241000500891 Insecta Species 0.000 description 1
- 108090001007 Interleukin-8 Proteins 0.000 description 1
- 102000004890 Interleukin-8 Human genes 0.000 description 1
- VHOQXEIFYTTXJU-UHFFFAOYSA-N Isobutylene-isoprene copolymer Chemical group CC(C)=C.CC(=C)C=C VHOQXEIFYTTXJU-UHFFFAOYSA-N 0.000 description 1
- 206010023198 Joint ankylosis Diseases 0.000 description 1
- 208000003456 Juvenile Arthritis Diseases 0.000 description 1
- 206010059176 Juvenile idiopathic arthritis Diseases 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 108010054278 Lac Repressors Proteins 0.000 description 1
- 244000147568 Laurus nobilis Species 0.000 description 1
- 235000017858 Laurus nobilis Nutrition 0.000 description 1
- 208000004554 Leishmaniasis Diseases 0.000 description 1
- 206010024229 Leprosy Diseases 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- GDBQQVLCIARPGH-UHFFFAOYSA-N Leupeptin Natural products CC(C)CC(NC(C)=O)C(=O)NC(CC(C)C)C(=O)NC(C=O)CCCN=C(N)N GDBQQVLCIARPGH-UHFFFAOYSA-N 0.000 description 1
- 206010024558 Lip oedema Diseases 0.000 description 1
- 208000007021 Lipedema Diseases 0.000 description 1
- 239000012097 Lipofectamine 2000 Substances 0.000 description 1
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 1
- 208000016604 Lyme disease Diseases 0.000 description 1
- 206010025282 Lymphoedema Diseases 0.000 description 1
- 101150084313 MCP1 gene Proteins 0.000 description 1
- 101710091437 Major capsid protein 2 Proteins 0.000 description 1
- 206010027201 Meningitis aseptic Diseases 0.000 description 1
- 244000246386 Mentha pulegium Species 0.000 description 1
- 235000016257 Mentha pulegium Nutrition 0.000 description 1
- 235000004357 Mentha x piperita Nutrition 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- 241000699660 Mus musculus Species 0.000 description 1
- 101000946797 Mus musculus C-C motif chemokine 9 Proteins 0.000 description 1
- 101100382870 Mus musculus Ccl12 gene Proteins 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 241000545499 Mycobacterium avium-intracellulare Species 0.000 description 1
- 201000002481 Myositis Diseases 0.000 description 1
- WHNWPMSKXPGLAX-UHFFFAOYSA-N N-Vinyl-2-pyrrolidone Chemical compound C=CN1CCCC1=O WHNWPMSKXPGLAX-UHFFFAOYSA-N 0.000 description 1
- 241000256259 Noctuidae Species 0.000 description 1
- 102100022932 Nuclear receptor coactivator 5 Human genes 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- 206010033128 Ovarian cancer Diseases 0.000 description 1
- 206010061535 Ovarian neoplasm Diseases 0.000 description 1
- 241000282577 Pan troglodytes Species 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- 208000025584 Pericardial disease Diseases 0.000 description 1
- 208000018262 Peripheral vascular disease Diseases 0.000 description 1
- 201000005702 Pertussis Diseases 0.000 description 1
- 102100030304 Platelet factor 4 Human genes 0.000 description 1
- 208000005384 Pneumocystis Pneumonia Diseases 0.000 description 1
- 206010073755 Pneumocystis jirovecii pneumonia Diseases 0.000 description 1
- 229920002367 Polyisobutene Polymers 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 241000125945 Protoparvovirus Species 0.000 description 1
- 201000004681 Psoriasis Diseases 0.000 description 1
- 208000004186 Pulmonary Heart Disease Diseases 0.000 description 1
- 206010064911 Pulmonary arterial hypertension Diseases 0.000 description 1
- 108020005067 RNA Splice Sites Proteins 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 241000700157 Rattus norvegicus Species 0.000 description 1
- 208000003782 Raynaud disease Diseases 0.000 description 1
- 201000003099 Renovascular Hypertension Diseases 0.000 description 1
- 108020005091 Replication Origin Proteins 0.000 description 1
- 108091027981 Response element Proteins 0.000 description 1
- 206010038748 Restrictive cardiomyopathy Diseases 0.000 description 1
- 241000190932 Rhodopseudomonas Species 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 241000714474 Rous sarcoma virus Species 0.000 description 1
- 102100023361 SAP domain-containing ribonucleoprotein Human genes 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 206010061934 Salivary gland cancer Diseases 0.000 description 1
- 101100129590 Schizosaccharomyces pombe (strain 972 / ATCC 24843) mcp5 gene Proteins 0.000 description 1
- 208000009714 Severe Dengue Diseases 0.000 description 1
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 1
- UIIMBOGNXHQVGW-DEQYMQKBSA-M Sodium bicarbonate-14C Chemical compound [Na+].O[14C]([O-])=O UIIMBOGNXHQVGW-DEQYMQKBSA-M 0.000 description 1
- 241000256248 Spodoptera Species 0.000 description 1
- 235000021355 Stearic acid Nutrition 0.000 description 1
- 208000005718 Stomach Neoplasms Diseases 0.000 description 1
- 101710137500 T7 RNA polymerase Proteins 0.000 description 1
- 208000001871 Tachycardia Diseases 0.000 description 1
- 235000005212 Terminalia tomentosa Nutrition 0.000 description 1
- 101000748795 Thermus thermophilus (strain ATCC 27634 / DSM 579 / HB8) Cytochrome c oxidase polypeptide I+III Proteins 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 206010043540 Thromboangiitis obliterans Diseases 0.000 description 1
- 201000007023 Thrombotic Thrombocytopenic Purpura Diseases 0.000 description 1
- 241000218636 Thuja Species 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 108020004440 Thymidine kinase Proteins 0.000 description 1
- 208000033781 Thyroid carcinoma Diseases 0.000 description 1
- 208000024770 Thyroid neoplasm Diseases 0.000 description 1
- 206010044248 Toxic shock syndrome Diseases 0.000 description 1
- 231100000650 Toxic shock syndrome Toxicity 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 239000006035 Tryptophane Substances 0.000 description 1
- 208000007814 Unstable Angina Diseases 0.000 description 1
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- 206010046996 Varicose vein Diseases 0.000 description 1
- 206010047249 Venous thrombosis Diseases 0.000 description 1
- XTXRWKRVRITETP-UHFFFAOYSA-N Vinyl acetate Chemical compound CC(=O)OC=C XTXRWKRVRITETP-UHFFFAOYSA-N 0.000 description 1
- 108010046516 Wheat Germ Agglutinins Proteins 0.000 description 1
- TVXBFESIOXBWNM-UHFFFAOYSA-N Xylitol Natural products OCCC(O)C(O)C(O)CCO TVXBFESIOXBWNM-UHFFFAOYSA-N 0.000 description 1
- 240000008042 Zea mays Species 0.000 description 1
- 235000016383 Zea mays subsp huehuetenangensis Nutrition 0.000 description 1
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- ZNAWDCNSIVPELL-MCDZGGTQSA-N [C@@H]1([C@H](O)[C@H](O)[C@@H](CO)O1)N1C=NC=2C(N)=NC=NC12.[O] Chemical compound [C@@H]1([C@H](O)[C@H](O)[C@@H](CO)O1)N1C=NC=2C(N)=NC=NC12.[O] ZNAWDCNSIVPELL-MCDZGGTQSA-N 0.000 description 1
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 229960005305 adenosine Drugs 0.000 description 1
- 239000000853 adhesive Substances 0.000 description 1
- 230000001070 adhesive effect Effects 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 239000003513 alkali Substances 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 229910021502 aluminium hydroxide Inorganic materials 0.000 description 1
- 235000012211 aluminium silicate Nutrition 0.000 description 1
- 125000000539 amino acid group Chemical group 0.000 description 1
- 239000003708 ampul Substances 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 230000036783 anaphylactic response Effects 0.000 description 1
- 208000007502 anemia Diseases 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 230000008485 antagonism Effects 0.000 description 1
- 239000000730 antalgic agent Substances 0.000 description 1
- 238000011861 anti-inflammatory therapy Methods 0.000 description 1
- 229940019748 antifibrinolytic proteinase inhibitors Drugs 0.000 description 1
- 239000003125 aqueous solvent Substances 0.000 description 1
- 206010003119 arrhythmia Diseases 0.000 description 1
- 230000006793 arrhythmia Effects 0.000 description 1
- 208000037849 arterial hypertension Diseases 0.000 description 1
- 208000011775 arteriosclerosis disease Diseases 0.000 description 1
- 208000028922 artery disease Diseases 0.000 description 1
- 206010003668 atrial tachycardia Diseases 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- SVPXDRXYRYOSEX-UHFFFAOYSA-N bentoquatam Chemical compound O.O=[Si]=O.O=[Al]O[Al]=O SVPXDRXYRYOSEX-UHFFFAOYSA-N 0.000 description 1
- 229960000686 benzalkonium chloride Drugs 0.000 description 1
- 229960001950 benzethonium chloride Drugs 0.000 description 1
- UREZNYTWGJKWBI-UHFFFAOYSA-M benzethonium chloride Chemical compound [Cl-].C1=CC(C(C)(C)CC(C)(C)C)=CC=C1OCCOCC[N+](C)(C)CC1=CC=CC=C1 UREZNYTWGJKWBI-UHFFFAOYSA-M 0.000 description 1
- 235000019445 benzyl alcohol Nutrition 0.000 description 1
- 229960004217 benzyl alcohol Drugs 0.000 description 1
- CADWTSSKOVRVJC-UHFFFAOYSA-N benzyl(dimethyl)azanium;chloride Chemical compound [Cl-].C[NH+](C)CC1=CC=CC=C1 CADWTSSKOVRVJC-UHFFFAOYSA-N 0.000 description 1
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 238000001574 biopsy Methods 0.000 description 1
- 208000002352 blister Diseases 0.000 description 1
- 210000000601 blood cell Anatomy 0.000 description 1
- 230000037058 blood plasma level Effects 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 229940098773 bovine serum albumin Drugs 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- LRHPLDYGYMQRHN-UHFFFAOYSA-N butyl alcohol Substances CCCCO LRHPLDYGYMQRHN-UHFFFAOYSA-N 0.000 description 1
- CJZGTCYPCWQAJB-UHFFFAOYSA-L calcium stearate Chemical compound [Ca+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O CJZGTCYPCWQAJB-UHFFFAOYSA-L 0.000 description 1
- 235000013539 calcium stearate Nutrition 0.000 description 1
- 239000008116 calcium stearate Substances 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 229910002091 carbon monoxide Inorganic materials 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-N carbonic acid Chemical compound OC(O)=O BVKZGUZCCUSVTD-UHFFFAOYSA-N 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 230000002612 cardiopulmonary effect Effects 0.000 description 1
- 210000000748 cardiovascular system Anatomy 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000034196 cell chemotaxis Effects 0.000 description 1
- 230000003915 cell function Effects 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 230000003833 cell viability Effects 0.000 description 1
- 238000012200 cell viability kit Methods 0.000 description 1
- 210000002421 cell wall Anatomy 0.000 description 1
- 238000012054 celltiter-glo Methods 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 230000003399 chemotactic effect Effects 0.000 description 1
- XENVCRGQTABGKY-ZHACJKMWSA-N chlorohydrin Chemical compound CC#CC#CC#CC#C\C=C\C(Cl)CO XENVCRGQTABGKY-ZHACJKMWSA-N 0.000 description 1
- 238000011097 chromatography purification Methods 0.000 description 1
- 208000019069 chronic childhood arthritis Diseases 0.000 description 1
- 229960002376 chymotrypsin Drugs 0.000 description 1
- 229960002424 collagenase Drugs 0.000 description 1
- 239000000084 colloidal system Substances 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 238000000205 computational method Methods 0.000 description 1
- 238000002591 computed tomography Methods 0.000 description 1
- 108010035886 connective tissue-activating peptide Proteins 0.000 description 1
- 208000029078 coronary artery disease Diseases 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 229940111134 coxibs Drugs 0.000 description 1
- 150000001896 cresols Chemical class 0.000 description 1
- 229960001681 croscarmellose sodium Drugs 0.000 description 1
- 229960000913 crospovidone Drugs 0.000 description 1
- 229920003020 cross-linked polyethylene Polymers 0.000 description 1
- 239000004703 cross-linked polyethylene Substances 0.000 description 1
- 235000010947 crosslinked sodium carboxy methyl cellulose Nutrition 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 239000003255 cyclooxygenase 2 inhibitor Substances 0.000 description 1
- UHDGCWIWMRVCDJ-ZAKLUEHWSA-N cytidine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O1 UHDGCWIWMRVCDJ-ZAKLUEHWSA-N 0.000 description 1
- 230000002354 daily effect Effects 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 201000002950 dengue hemorrhagic fever Diseases 0.000 description 1
- 230000008021 deposition Effects 0.000 description 1
- 239000007933 dermal patch Substances 0.000 description 1
- 239000008355 dextrose injection Substances 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- UMNKXPULIDJLSU-UHFFFAOYSA-N dichlorofluoromethane Chemical compound FC(Cl)Cl UMNKXPULIDJLSU-UHFFFAOYSA-N 0.000 description 1
- 229940099364 dichlorofluoromethane Drugs 0.000 description 1
- 229940087091 dichlorotetrafluoroethane Drugs 0.000 description 1
- 201000011304 dilated cardiomyopathy 1A Diseases 0.000 description 1
- 238000002224 dissection Methods 0.000 description 1
- POULHZVOKOAJMA-UHFFFAOYSA-M dodecanoate Chemical compound CCCCCCCCCCCC([O-])=O POULHZVOKOAJMA-UHFFFAOYSA-M 0.000 description 1
- 238000004043 dyeing Methods 0.000 description 1
- 235000013399 edible fruits Nutrition 0.000 description 1
- 229920002549 elastin Polymers 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 230000001804 emulsifying effect Effects 0.000 description 1
- 201000003914 endometrial carcinoma Diseases 0.000 description 1
- 208000010227 enterocolitis Diseases 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 201000011384 erythromelalgia Diseases 0.000 description 1
- CGPRUXZTHGTMKW-UHFFFAOYSA-N ethene;ethyl prop-2-enoate Chemical compound C=C.CCOC(=O)C=C CGPRUXZTHGTMKW-UHFFFAOYSA-N 0.000 description 1
- OZGODEHZQADZQC-UHFFFAOYSA-N ethenyl acetate terephthalic acid Chemical compound C(C1=CC=C(C(=O)O)C=C1)(=O)O.C(C)(=O)OC=C OZGODEHZQADZQC-UHFFFAOYSA-N 0.000 description 1
- XEKOWRVHYACXOJ-UHFFFAOYSA-N ethyl acetate Substances CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 1
- 208000021045 exocrine pancreatic carcinoma Diseases 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 230000004438 eyesight Effects 0.000 description 1
- 239000003925 fat Substances 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 208000027792 gastroduodenal Crohn disease Diseases 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 229930182470 glycoside Natural products 0.000 description 1
- 150000002338 glycosides Chemical class 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 229920000591 gum Polymers 0.000 description 1
- 238000003306 harvesting Methods 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 230000036074 healthy skin Effects 0.000 description 1
- 201000010235 heart cancer Diseases 0.000 description 1
- 208000024348 heart neoplasm Diseases 0.000 description 1
- 208000018578 heart valve disease Diseases 0.000 description 1
- 229960002897 heparin Drugs 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- 239000012145 high-salt buffer Substances 0.000 description 1
- 235000001050 hortel pimenta Nutrition 0.000 description 1
- 102000043994 human CCR2 Human genes 0.000 description 1
- 102000054350 human CHI3L1 Human genes 0.000 description 1
- 239000000017 hydrogel Substances 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 229920001477 hydrophilic polymer Polymers 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 208000009326 ileitis Diseases 0.000 description 1
- 201000008254 ileocolitis Diseases 0.000 description 1
- 210000001822 immobilized cell Anatomy 0.000 description 1
- 239000003547 immunosorbent Substances 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 230000008676 import Effects 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 206010022000 influenza Diseases 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 239000007972 injectable composition Substances 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 201000004332 intermediate coronary syndrome Diseases 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 230000004410 intraocular pressure Effects 0.000 description 1
- 229920000831 ionic polymer Polymers 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 1
- 201000002215 juvenile rheumatoid arthritis Diseases 0.000 description 1
- NLYAJNPCOHFWQQ-UHFFFAOYSA-N kaolin Chemical compound O.O.O=[Al]O[Si](=O)O[Si](=O)O[Al]=O NLYAJNPCOHFWQQ-UHFFFAOYSA-N 0.000 description 1
- 239000004310 lactic acid Substances 0.000 description 1
- 235000014655 lactic acid Nutrition 0.000 description 1
- 150000002597 lactoses Chemical class 0.000 description 1
- 238000013532 laser treatment Methods 0.000 description 1
- 208000027906 leg weakness Diseases 0.000 description 1
- GDBQQVLCIARPGH-ULQDDVLXSA-N leupeptin Chemical compound CC(C)C[C@H](NC(C)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C=O)CCCN=C(N)N GDBQQVLCIARPGH-ULQDDVLXSA-N 0.000 description 1
- 108010052968 leupeptin Proteins 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 210000003141 lower extremity Anatomy 0.000 description 1
- 239000007937 lozenge Substances 0.000 description 1
- 229960000994 lumiracoxib Drugs 0.000 description 1
- KHPKQFYUPIUARC-UHFFFAOYSA-N lumiracoxib Chemical compound OC(=O)CC1=CC(C)=CC=C1NC1=C(F)C=CC=C1Cl KHPKQFYUPIUARC-UHFFFAOYSA-N 0.000 description 1
- 201000005202 lung cancer Diseases 0.000 description 1
- 208000020816 lung neoplasm Diseases 0.000 description 1
- 208000002502 lymphedema Diseases 0.000 description 1
- 239000012516 mab select resin Substances 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 235000019359 magnesium stearate Nutrition 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 235000009973 maize Nutrition 0.000 description 1
- 201000004792 malaria Diseases 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000000873 masking effect Effects 0.000 description 1
- 230000035800 maturation Effects 0.000 description 1
- AEUKDPKXTPNBNY-XEYRWQBLSA-N mcp 2 Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CS)NC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)C(C)C)C1=CC=CC=C1 AEUKDPKXTPNBNY-XEYRWQBLSA-N 0.000 description 1
- 101150018062 mcp4 gene Proteins 0.000 description 1
- 238000002483 medication Methods 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 210000004379 membrane Anatomy 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 239000001525 mentha piperita l. herb oil Substances 0.000 description 1
- HEBKCHPVOIAQTA-UHFFFAOYSA-N meso ribitol Natural products OCC(O)C(O)C(O)CO HEBKCHPVOIAQTA-UHFFFAOYSA-N 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 229920000609 methyl cellulose Polymers 0.000 description 1
- OSWPMRLSEDHDFF-UHFFFAOYSA-N methyl salicylate Chemical compound COC(=O)C1=CC=CC=C1O OSWPMRLSEDHDFF-UHFFFAOYSA-N 0.000 description 1
- 239000001923 methylcellulose Substances 0.000 description 1
- LXCFILQKKLGQFO-UHFFFAOYSA-N methylparaben Chemical compound COC(=O)C1=CC=C(O)C=C1 LXCFILQKKLGQFO-UHFFFAOYSA-N 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 235000013379 molasses Nutrition 0.000 description 1
- 208000017972 multifocal atrial tachycardia Diseases 0.000 description 1
- TZBAVQKIEKDGFH-UHFFFAOYSA-N n-[2-(diethylamino)ethyl]-1-benzothiophene-2-carboxamide;hydrochloride Chemical compound [Cl-].C1=CC=C2SC(C(=O)NCC[NH+](CC)CC)=CC2=C1 TZBAVQKIEKDGFH-UHFFFAOYSA-N 0.000 description 1
- 229920003052 natural elastomer Polymers 0.000 description 1
- 229920001194 natural rubber Polymers 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 231100000956 nontoxicity Toxicity 0.000 description 1
- 239000000346 nonvolatile oil Substances 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 1
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 238000002577 ophthalmoscopy Methods 0.000 description 1
- 239000006174 pH buffer Substances 0.000 description 1
- 244000045947 parasite Species 0.000 description 1
- 101150029755 park gene Proteins 0.000 description 1
- 230000001314 paroxysmal effect Effects 0.000 description 1
- 238000004810 partition chromatography Methods 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- 230000006320 pegylation Effects 0.000 description 1
- 210000004197 pelvis Anatomy 0.000 description 1
- 229950000964 pepstatin Drugs 0.000 description 1
- 108010091212 pepstatin Proteins 0.000 description 1
- FAXGPCHRFPCXOO-LXTPJMTPSA-N pepstatin A Chemical compound OC(=O)C[C@H](O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)C[C@H](O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)NC(=O)CC(C)C FAXGPCHRFPCXOO-LXTPJMTPSA-N 0.000 description 1
- 230000010412 perfusion Effects 0.000 description 1
- 208000030613 peripheral artery disease Diseases 0.000 description 1
- 210000005259 peripheral blood Anatomy 0.000 description 1
- 239000011886 peripheral blood Substances 0.000 description 1
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 1
- 210000004303 peritoneum Anatomy 0.000 description 1
- 102000013415 peroxidase activity proteins Human genes 0.000 description 1
- 108040007629 peroxidase activity proteins Proteins 0.000 description 1
- 230000002688 persistence Effects 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 235000021317 phosphate Nutrition 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- 150000003016 phosphoric acids Chemical class 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 201000000317 pneumocystosis Diseases 0.000 description 1
- 229920001084 poly(chloroprene) Polymers 0.000 description 1
- 229920003229 poly(methyl methacrylate) Polymers 0.000 description 1
- 229920000139 polyethylene terephthalate Polymers 0.000 description 1
- 239000005020 polyethylene terephthalate Substances 0.000 description 1
- 229920001195 polyisoprene Polymers 0.000 description 1
- 239000004926 polymethyl methacrylate Substances 0.000 description 1
- 239000000244 polyoxyethylene sorbitan monooleate Substances 0.000 description 1
- 229920001296 polysiloxane Polymers 0.000 description 1
- 229940068968 polysorbate 80 Drugs 0.000 description 1
- 229920002689 polyvinyl acetate Polymers 0.000 description 1
- 239000011118 polyvinyl acetate Substances 0.000 description 1
- 229920000523 polyvinylpolypyrrolidone Polymers 0.000 description 1
- 235000013809 polyvinylpolypyrrolidone Nutrition 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 229910000160 potassium phosphate Inorganic materials 0.000 description 1
- 229940093916 potassium phosphate Drugs 0.000 description 1
- 235000011009 potassium phosphates Nutrition 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 238000002203 pretreatment Methods 0.000 description 1
- 201000008312 primary pulmonary hypertension Diseases 0.000 description 1
- 230000009465 prokaryotic expression Effects 0.000 description 1
- 239000004405 propyl p-hydroxybenzoate Substances 0.000 description 1
- 235000010232 propyl p-hydroxybenzoate Nutrition 0.000 description 1
- 229940093625 propylene glycol monostearate Drugs 0.000 description 1
- 125000004805 propylene group Chemical group [H]C([H])([H])C([H])([*:1])C([H])([H])[*:2] 0.000 description 1
- 229960003415 propylparaben Drugs 0.000 description 1
- 239000002212 purine nucleoside Substances 0.000 description 1
- 150000004053 quinones Chemical class 0.000 description 1
- 238000002601 radiography Methods 0.000 description 1
- 239000011541 reaction mixture Substances 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 239000004627 regenerated cellulose Substances 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 201000003804 salivary gland carcinoma Diseases 0.000 description 1
- 239000012266 salt solution Substances 0.000 description 1
- 210000004761 scalp Anatomy 0.000 description 1
- HFHDHCJBZVLPGP-UHFFFAOYSA-N schardinger α-dextrin Chemical compound O1C(C(C2O)O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC(C(O)C2O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC2C(O)C(O)C1OC2CO HFHDHCJBZVLPGP-UHFFFAOYSA-N 0.000 description 1
- 238000007789 sealing Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000004062 sedimentation Methods 0.000 description 1
- 230000035807 sensation Effects 0.000 description 1
- 201000001223 septic arthritis Diseases 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 230000035939 shock Effects 0.000 description 1
- 238000002579 sigmoidoscopy Methods 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 238000007390 skin biopsy Methods 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 239000001632 sodium acetate Substances 0.000 description 1
- 235000017281 sodium acetate Nutrition 0.000 description 1
- 239000008354 sodium chloride injection Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 229910000162 sodium phosphate Inorganic materials 0.000 description 1
- JXAZAUKOWVKTLO-UHFFFAOYSA-L sodium pyrosulfate Chemical compound [Na+].[Na+].[O-]S(=O)(=O)OS([O-])(=O)=O JXAZAUKOWVKTLO-UHFFFAOYSA-L 0.000 description 1
- 229920003109 sodium starch glycolate Polymers 0.000 description 1
- 229940079832 sodium starch glycolate Drugs 0.000 description 1
- 239000008109 sodium starch glycolate Substances 0.000 description 1
- 239000002689 soil Substances 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 235000013599 spices Nutrition 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 238000005507 spraying Methods 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 239000008117 stearic acid Substances 0.000 description 1
- 238000011146 sterile filtration Methods 0.000 description 1
- 239000008174 sterile solution Substances 0.000 description 1
- 238000003756 stirring Methods 0.000 description 1
- 201000000498 stomach carcinoma Diseases 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 229960004793 sucrose Drugs 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 210000001179 synovial fluid Anatomy 0.000 description 1
- 208000006379 syphilis Diseases 0.000 description 1
- 230000006794 tachycardia Effects 0.000 description 1
- 239000000454 talc Substances 0.000 description 1
- 235000012222 talc Nutrition 0.000 description 1
- 229910052623 talc Inorganic materials 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- 230000008719 thickening Effects 0.000 description 1
- RTKIYNMVFMVABJ-UHFFFAOYSA-L thimerosal Chemical compound [Na+].CC[Hg]SC1=CC=CC=C1C([O-])=O RTKIYNMVFMVABJ-UHFFFAOYSA-L 0.000 description 1
- 150000007970 thio esters Chemical class 0.000 description 1
- 201000002510 thyroid cancer Diseases 0.000 description 1
- 208000013077 thyroid gland carcinoma Diseases 0.000 description 1
- 210000003371 toe Anatomy 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- CYRMSUTZVYGINF-UHFFFAOYSA-N trichlorofluoromethane Chemical compound FC(Cl)(Cl)Cl CYRMSUTZVYGINF-UHFFFAOYSA-N 0.000 description 1
- 229940029284 trichlorofluoromethane Drugs 0.000 description 1
- 229940117013 triethanolamine oleate Drugs 0.000 description 1
- 239000013638 trimer Substances 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 229960004799 tryptophan Drugs 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 1
- 229940045145 uridine Drugs 0.000 description 1
- 201000005112 urinary bladder cancer Diseases 0.000 description 1
- 230000001982 uveitic effect Effects 0.000 description 1
- 208000027185 varicose disease Diseases 0.000 description 1
- 235000013311 vegetables Nutrition 0.000 description 1
- 208000037997 venous disease Diseases 0.000 description 1
- 229920002554 vinyl polymer Polymers 0.000 description 1
- 239000008215 water for injection Substances 0.000 description 1
- 239000001993 wax Substances 0.000 description 1
- 239000009637 wintergreen oil Substances 0.000 description 1
- 239000000811 xylitol Substances 0.000 description 1
- 235000010447 xylitol Nutrition 0.000 description 1
- HEBKCHPVOIAQTA-SCDXWVJYSA-N xylitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)CO HEBKCHPVOIAQTA-SCDXWVJYSA-N 0.000 description 1
- 229960002675 xylitol Drugs 0.000 description 1
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/521—Chemokines
- C07K14/523—Beta-chemokines, e.g. RANTES, I-309/TCA-3, MIP-1alpha, MIP-1beta/ACT-2/LD78/SCIF, MCP-1/MCAF, MCP-2, MCP-3, LDCF-1, LDCF-2
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/19—Cytokines; Lymphokines; Interferons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/02—Stomatological preparations, e.g. drugs for caries, aphtae, periodontitis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/04—Drugs for disorders of the alimentary tract or the digestive system for ulcers, gastritis or reflux esophagitis, e.g. antacids, inhibitors of acid secretion, mucosal protectants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/16—Drugs for disorders of the alimentary tract or the digestive system for liver or gallbladder disorders, e.g. hepatoprotective agents, cholagogues, litholytics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/18—Drugs for disorders of the alimentary tract or the digestive system for pancreatic disorders, e.g. pancreatic enzymes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P11/00—Drugs for disorders of the respiratory system
- A61P11/06—Antiasthmatics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P11/00—Drugs for disorders of the respiratory system
- A61P11/08—Bronchodilators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/08—Drugs for disorders of the urinary system of the prostate
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
- A61P15/08—Drugs for genital or sexual disorders; Contraceptives for gonadal disorders or for enhancing fertility, e.g. inducers of ovulation or of spermatogenesis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
- A61P17/02—Drugs for dermatological disorders for treating wounds, ulcers, burns, scars, keloids, or the like
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
- A61P17/06—Antipsoriatics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
- A61P17/12—Keratolytics, e.g. wart or anti-corn preparations
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/02—Drugs for skeletal disorders for joint disorders, e.g. arthritis, arthrosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/06—Antigout agents, e.g. antihyperuricemic or uricosuric agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P21/00—Drugs for disorders of the muscular or neuromuscular system
- A61P21/04—Drugs for disorders of the muscular or neuromuscular system for myasthenia gravis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/02—Drugs for disorders of the nervous system for peripheral neuropathies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P27/00—Drugs for disorders of the senses
- A61P27/16—Otologicals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/04—Anorexiants; Antiobesity agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/04—Antibacterial agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/10—Antimycotics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P33/00—Antiparasitic agents
- A61P33/10—Anthelmintics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/06—Immunosuppressants, e.g. drugs for graft rejection
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/08—Antiallergic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P5/00—Drugs for disorders of the endocrine system
- A61P5/48—Drugs for disorders of the endocrine system of the pancreatic hormones
- A61P5/50—Drugs for disorders of the endocrine system of the pancreatic hormones for increasing or potentiating the activity of insulin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/10—Drugs for disorders of the cardiovascular system for treating ischaemic or atherosclerotic diseases, e.g. antianginal drugs, coronary vasodilators, drugs for myocardial infarction, retinopathy, cerebrovascula insufficiency, renal arteriosclerosis
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
- C07K2319/74—Fusion polypeptide containing domain for protein-protein interaction containing a fusion for binding to a cell surface receptor
- C07K2319/75—Fusion polypeptide containing domain for protein-protein interaction containing a fusion for binding to a cell surface receptor containing a fusion for activation of a cell surface receptor, e.g. thrombopoeitin, NPY and other peptide hormones
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Engineering & Computer Science (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Genetics & Genomics (AREA)
- Immunology (AREA)
- Zoology (AREA)
- Diabetes (AREA)
- Molecular Biology (AREA)
- Gastroenterology & Hepatology (AREA)
- Biomedical Technology (AREA)
- Biochemistry (AREA)
- Pulmonology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Endocrinology (AREA)
- Biophysics (AREA)
- Dermatology (AREA)
- Physical Education & Sports Medicine (AREA)
- Communicable Diseases (AREA)
- Oncology (AREA)
- Neurology (AREA)
- Toxicology (AREA)
- Rheumatology (AREA)
- Reproductive Health (AREA)
- Orthopedic Medicine & Surgery (AREA)
- Hematology (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
Abstract
本发明提供包含任选通过接头与免疫球蛋白融合的MCP1的多肽。还包括用所述多肽治疗疾病的方法。
Description
本申请要求2005年8月12日提交的美国临时专利申请号60/707,731的权益,其通过引用全部结合到本文中。
发明领域
本发明涉及特别有助于治疗或预防炎性疾病的融合蛋白;以及用所述融合蛋白治疗此类疾病的方法。
发明背景
单核细胞趋化蛋白-1(MCP1,也称为HCl1,MCAF,CCL2,SCYA2,GDCF-2,SMC-CF,HSMCR30,MGC9434,GDCF-2和HC11)是趋化因子受体CCR2的高选择性、高亲和力趋化因子配体。它由炎症组织局部分泌,吸引携带CCR2的细胞如单核细胞和记忆T细胞。与CCR2结合后,MCP1诱导钙流出,细胞沿MCP1的梯度迁移。
有确凿的生物学和遗传证据表明MCP1和CCR2在包括关节炎、动脉粥样硬化、多发性硬化和纤维化在内的炎性疾病中起关键作用。MCP1或CCR2缺陷的小鼠可免于出现实验性自身免疫性脑脊髓炎(EAE)(Huang等,2001,J.Exp.Med.193:713;Izikson等,2000,J.Exp.Med.192:1075;Mahad和Ransohoff,2003,Semi.Immunol.15:23)。CCR2缺陷的小鼠还可免于出现胶原诱导性关节炎(Quinones等,2004,J.Clin.Invest.113:856)。而且,CCR2敲除的小鼠不出现动脉粥样硬化斑块(Charo和Taubman,2004,Circ.Res.95:858)。
本领域存在针对CCR2介导性炎症的抗炎剂的需要。
发明概述
本文公开的发明起源于一个惊人的发现:通过全身性给予趋化因子配体使受体脱敏来靶向作用于趋化因子受体,可防止携带受体的细胞运输至炎症部位,并防止暴露于活化信号如干扰素-γ。在本文讨论的例示性实施例中,将CCR2用作趋化因子受体,MCP1用作趋化因子配体。为了延长MCP1趋化因子的血清半衰期,通过用免疫球蛋白恒定区(从铰链至CH3区)标记MCP1设计免疫球蛋白-融合蛋白。
本发明可解决对抗炎疗法的需求及其它需求,在本发明的实施方案中,提供趋化因子配体如MCP1、SDF1或MIP1β或其片段(如其成熟多肽),与延长蛋白体内半衰期的因子如免疫球蛋白或其片段或PEG融合。
本发明提供分离的多肽,包括(1)与一种或多种半衰期延长部分融合的一种或多种趋化因子多肽;或(2)两种或多种融合的趋化因子多肽。在本发明的实施方案中,MCP1选自人MCP1和小鼠MCP1。在本发明的实施方案中,所述部分是聚乙二醇(PEG)或免疫球蛋白。在本发明的实施方案中,所述多肽包括与一种或多种免疫球蛋白(如任何SEQ ID NO:8-12)融合的一种或多种成熟MCP1多肽(如人或小鼠)。在本发明的实施方案中,所述MCP1选自人MCP1和小鼠MCP1。在本发明的实施方案中,所述免疫球蛋白选自铰链区至CH3区的γ1和γ4。在本发明的实施方案中,所述多肽选自与小鼠IgG1融合的成熟人MCP1;与人IgG4融合的成熟人MCP1;与人IgG4单体变异体融合的成熟人MCP1;与人IgG1融合的成熟人MCP1;和与人IgG1单体变异体融合的成熟人MCP1。在本发明的实施方案中,所述MCP1包含选自SEQ ID NO:2的氨基酸序列。在本发明的实施方案中,所述免疫球蛋白包含SEQ ID NO:3-7列出的氨基酸序列。在本发明的实施方案中,所述MCP1通过肽接头(如GS)与免疫球蛋白融合。本发明的范围包括包含任何多肽和药学上可接受的载体的药用组合物。本发明的范围还包括与一种或多种其它治疗剂缔合的任何多肽或其药用组合物;例如,其中所述其它治疗剂选自阿司匹林、双氯芬酸、二氟尼柳、依托度酸、非诺洛芬、夫洛非宁、氟比洛芬、布洛芬、吲哚美辛、酮洛芬、酮咯酸、甲氯芬那酸、甲芬那酸、美洛昔康、萘丁美酮、萘普生、噁丙嗪、保泰松、吡罗昔康、双水杨酸酯、舒林酸、替诺昔康、噻洛芬酸、托美丁、苯甲酸倍他米松、戊酸倍他米松、丙酸氯倍他索、去羟米松、氟轻松、氟羟可舒松、表面类固醇、二丙酸阿氯米松、芦荟、安西奈德、安西奈德、蒽林、二丙酸倍他米松、戊酸倍他米松、卡泊三烯、丙酸氯倍他索、煤焦油、死海盐、地奈德、地奈德;戊酸倍他米松、去羟米松、二乙酸二氟拉松、泻盐、氟轻松、氟轻松、氟羟可舒松、丙酸氟替卡松、哈西奈德、丙酸卤贝他索、戊酸氢化可的松、氢化可的松、糠酸莫米松、油状麦片、凡士林、泼尼卡酯、水杨酸、他扎罗汀、曲安奈德、氢化可的松、地塞米松、甲基泼尼松龙和泼尼松龙的混合物、alefacept、依那西普、环孢菌素、甲氨蝶呤、阿曲汀、异维甲酸、羟基脲、霉酚酸酯、柳氮磺吡啶、6-硫鸟嘌呤、阿那白滞素、可注射金、青霉胺、硫唑嘌呤、氯喹、羟基氯喹、柳氮磺吡啶、口服金、金诺芬、硫代苹果酸金钠、金硫葡糖、美沙拉嗪、柳氮磺吡啶、布地奈德、甲硝唑、环丙沙星、硫唑嘌呤、6-巯基嘌呤或膳食补充剂钙、叶酸盐、维生素B12、塞来考昔、罗非考昔、伐地考昔、罗美昔布、艾托考昔、依法利珠单抗、阿达木单抗、英夫利昔单抗和ABX-IL8。
本发明提供编码本文任何一种多肽的分离的核苷酸,如编码选自下列的多肽:与小鼠IgG1融合的人未加工的MCP1;与人IgG4融合的人未加工的MCP1;与人IgG4单体变异体融合的人未加工的MCP1;与人IgG1融合的人未加工的MCP1;和与人IgG1单体变异体融合的人未加工的MCP1。在本发明的实施方案中,所述MCP1由SEQ IDNO:13列出的核苷酸序列编码。在本发明的实施方案中,所述免疫球蛋白由选自SEQ ID NO:14-18的核苷酸序列编码。在本发明的实施方案中,所述核苷酸序列选自SEQ ID NO:19-23。本发明还包括含多核苷酸(如pcDNA3.1(+)hMCP1mIgG)的分离载体(如图1显示和/或包含SEQ ID NO:24的核苷酸序列)以及包含该载体的宿主细胞。
本发明还提供制备MCP1-Ig多肽的方法,包括在适合所述表达的条件下用含编码所述多肽的多核苷酸的表达载体转化宿主细胞(如pcDNA3.1(+)hMCP1 mIgG),任选从宿主细胞分离多肽。在本发明的实施方案中,多核苷酸编码包含选自SEQ ID NO:8-12氨基酸序列的多肽。通过所述方法制备的任何多肽也在本发明范围之内。
本发明提供治疗受试者疾病的方法,通过降低趋化因子配体(如MCP1、SDF1或MIP1β)或趋化因子受体的表达或活性或者通过减少趋化因子受体携带细胞迁移入炎症组织内可治疗所述疾病,所述方法包括使受试者的趋化因子受体携带细胞对趋化因子配体脱敏。在本发明的实施方案中,所述疾病选自炎性疾病、寄生虫感染、细菌感染、病毒感染、癌症、心血管疾病和循环系统疾病。在本发明的实施方案中,通过全身性给予与半衰期延长部分(如免疫球蛋白或其片段)融合的趋化因子配体多肽或趋化因子配体多肽使趋化因子受体携带细胞对趋化因子配体脱敏。在本发明的实施方案中,所述MCP1包含SEQID NO:2列出的氨基酸序列。在本发明的实施方案中,Ig包含选自SEQ ID NO:3-7的氨基酸序列。在本发明的实施方案中,多肽是包含选自SEQ ID NO:8-12的氨基酸序列的MCP1-Ig。
本发明提供治疗或预防受试者炎性疾病的方法,包括给予受试者任选与又一种治疗剂或过程联合的MCP1-Ig或其药用组合物。在本发明的实施方案中,所述疾病选自阑尾炎、消化性溃疡、胃溃疡和十二指肠溃疡、腹膜炎、胰腺炎、炎性肠病、结肠炎、溃疡性结肠炎、伪膜性肠炎、急性结肠炎、缺血性结肠炎、憩室炎、会厌炎、失弛缓症、胆管炎、胆囊炎、腹部疾病、肝炎、克罗恩病、肠炎、惠普尔病、哮喘、过敏、过敏性休克、免疫复合物病、器官缺血、再灌注损伤、器官坏死、花粉热、脓毒症、败血症、内毒素性休克、恶病质、高热、嗜酸细胞性肉芽肿、肉芽肿病、肉状瘤病、脓毒性流产、附睾炎、阴道炎、前列腺炎和尿道炎、支气管炎、肺气肿、鼻炎、囊性纤维化、肺炎、成人呼吸窘迫综合征、黑肺病、肺泡炎、细支气管炎、咽炎、胸膜炎、鼻窦炎、皮炎、特应性皮炎、皮肌炎、晒伤、风疹疣、风疹块、狭窄、再狭窄、血管炎、脉管炎、心内膜炎、动脉炎、动脉粥样硬化、血栓性静脉炎、心包炎、心肌炎、心肌缺血、结节性多动脉炎、风湿热、脑膜炎、脑炎、多发性硬化、神经炎、神经痛、葡萄膜炎、关节炎和关节痛、骨髓炎、筋膜炎、佩吉特病、痛风、牙周病、类风湿性关节炎、滑膜炎、重症肌无力、甲状腺炎、系统性红斑狼疮、肺出血-肾炎综合征、白塞综合征、同种异体移植物排斥和移植物抗宿主病。在本发明的实施方案中,MCP1包含SEQ ID NO:2列出的氨基酸序列。在本发明的实施方案中,Ig包含选自SEQ ID NO:3-7的氨基酸序列。在本发明的实施方案中,MCP1-Ig包含选自SEQ ID NO:8-12的氨基酸序列。在本发明的实施方案中,受试者是人。在本发明的实施方案中,又一种治疗剂或过程选自阿司匹林、双氯芬酸、二氟尼柳、依托度酸、非诺洛芬、夫洛非宁、氟比洛芬、布洛芬、吲哚美辛、酮洛芬、酮咯酸、甲氯芬那酸、甲芬那酸、美洛昔康、萘丁美酮、萘普生、噁丙嗪、保泰松、吡罗昔康、双水杨酸酯、舒林酸、替诺昔康、噻洛芬酸、托美丁、苯甲酸倍他米松、戊酸倍他米松、丙酸氯倍他索、去羟米松、氟轻松、氟羟可舒松、表面类固醇二丙酸阿氯米松、芦荟、安西奈德、安西奈德、蒽林、二丙酸倍他米松、戊酸倍他米松、卡泊三烯、丙酸氯倍他索、煤焦油、死海盐、地奈德、地奈德、戊酸倍他米松、去羟米松、二乙酸二氟拉松、泻盐、氟轻松、氟轻松、氟羟可舒松、丙酸氟替卡松、哈西奈德、丙酸卤贝他索、戊酸氢化可的松、氢化可的松、糠酸莫米松、油状麦片、凡士林、泼尼卡酯、水杨酸、他扎罗汀、曲安奈德、氢化可的松、地塞米松、甲基泼尼松龙和泼尼松龙的混合物、alefacept、依那西普、环孢菌素、甲氨蝶呤、阿曲汀、异维甲酸、羟基脲、霉酚酸酯、柳氮磺吡啶、6-硫鸟嘌呤、阿那白滞素、可注射金、青霉胺、硫唑嘌呤、氯喹、羟基氯喹、柳氮磺吡啶、口服金、金诺芬、硫代苹果酸金钠、金硫葡糖、美沙拉嗪、柳氮磺吡啶、布地奈德、甲硝唑、环丙沙星、硫唑嘌呤、6-巯基嘌呤或膳食补充剂钙、叶酸盐、维生素B12、塞来考昔、罗非考昔、伐地考昔、罗美昔布、艾托考昔、依法利珠单抗、阿达木单抗、英夫利昔单抗、ABX-IL8和光疗。
本发明提供增加MCP1在受试者机体的体内半衰期的方法,包括使MCP1与免疫球蛋白或其片段融合。在本发明的实施方案中,MCP1包含SEQ ID NO:2列出的氨基酸序列。在本发明的实施方案中,免疫球蛋白包含选自SEQ ID NO:3-7的氨基酸序列。
附图简述
图1.质粒pcDNA3.1(+)hMCP1 mIgG的图。
发明详述
本发明提供包含与任何半衰期延长部分融合的MCP1的多肽,所述部分延长或拖延MCP1在受试者机体中(如在血浆中)的体内半衰期。
分子生物学
根据本发明,可应用本领域技能范围内的常规分子生物学、微生物学和重组DNA技术。在文献中有关于此类技术的全面解释。参阅如Sambrook,Fritsch & Maniatis,Molecular Cloning:A Laboratory Manual(分子克隆:实验指南),第2版(1989)Cold Spring HarborLaboratory Press,Cold Spring Harbor,New York(本文称为"Sambrook,等,1989");DNA Cloning:A Practical Approach(DNA克隆:实用方法),I和II卷(D.N.Glover编辑,1985);Oligonucleotide Synthesis(寡核苷酸 合成)(M.J.Gait编辑,1984);Nucleic Acid Hybridization(核酸杂交)(B.D.Hames & S.J.Higgins编辑(1985));Transcription And Translation (转录和翻译)(B.D.Hames & S.J.Higgins编辑(1984));Animal Cell Culture(动物细胞培养)(R.I.Freshney编辑(1986));Immobilized Cells And Enzymes(固定细胞和酶)(IRL Press,(1986));B.Perbal,A Practical Guide To Molecular Cloning(分子克隆的实用指南)(1984);F.M.Ausubel等(编辑),Current Protocols in Molecular Biology(分子生物学 的最新方案),John Wiley & Sons,Inc.(1994)。
“多核苷酸”、“核酸”或“核酸分子”包括核糖核苷(腺嘌呤核苷、鸟嘌呤核苷、尿嘧啶核苷或胞嘧啶核苷;"RNA分子")或脱氧核糖核苷(脱氧腺嘌呤核苷、脱氧鸟嘌呤核苷、脱氧胸腺嘧啶核苷或脱氧胞嘧啶核苷;"DNA分子")的磷酸酯聚合物形式或其任何磷酸酯类似物,如硫代磷酸酯和硫酯,为单链形式、双链形式等。
“多核苷酸序列”、“核酸序列”或“核苷酸序列”是核酸如DNA或RNA中的一连串核苷酸碱基(也称为“核苷酸”),指任何两个或多个核苷酸链。
“编码序列”或“编码”表达产物如RNA、多肽、蛋白质或酶的序列,是表达时可产生产物的核苷酸序列。
术语“基因”指编码或对应于核糖核苷酸或氨基酸(包括一种或多种RNA分子、蛋白质或酶的全部或部分)特殊序列的DNA序列,可包括或不包括调控DNA序列,例如启动子序列,该序列确定如基因表达的条件。可将基因从DNA转录为RNA,可将其翻译或不翻译为氨基酸序列。
“蛋白质序列”、“肽序列”或“多肽序列”或“氨基酸序列”包括蛋白质、肽或多肽中的连续两个或多个氨基酸。
“分离的多核苷酸”或“分离的多肽”分别包括多核苷酸(如RNA或DNA分子或混合聚合物)或多肽,部分或完全与正常出现在细胞或重组DNA表达系统的其它组分分离。这些组分包括但不限于细胞膜、细胞壁、核糖体、聚合酶、血清组分和外源性基因组序列。
虽然优选分离的多核苷酸或多肽是基本均匀的分子组合物,但可包含一些不均匀性。
DNA的“扩增”用于本文包括用聚合酶链式反应(PCR)增加DNA序列混合物中特殊DNA序列的浓度。关于PCR的描述,参阅Saiki等,Science(1988)239:487。
术语“宿主细胞”包括以任何方式选择、修饰、转染、转化、生长或使用或处理的任何生物体的任何细胞,通过细胞制备物质,例如通过细胞使基因、DNA或RNA序列或蛋白质表达或复制。宿主细胞包括细菌细胞(如大肠杆菌(E.coli))、中国仓鼠卵巢(CHO)细胞、HEK293细胞、骨髓瘤细胞(包括但不限于SP2/0、NS1和NS0)、鼠类巨噬细胞J774细胞或任何其它巨噬细胞系和人肠上皮Caco2细胞。
多核苷酸的核苷酸序列可通过本领域已知的任何方法测定(如化学测序或酶测序)。DNA的“化学测序”包括如Maxam和Gilbert的方法(1977)(Proc.Natl.Acad.Sci.USA 74:560),其中用个别碱基特异性反应使DNA随机断裂。DNA的“酶测序”包括如Sanger的方法(Sanger等,(1977)Proc.Natl.Acad.Sci.USA 74:5463)。
本文的多核苷酸可位于天然调控(表达控制)序列旁侧,或者可与异源性序列缔合,所述异源性序列包括启动子、内部核糖体进入位点(IRES)及其它核糖体结合位点序列、增强子、效应元件、抑制子、信号序列、多腺苷酸化序列、内含子、5′-和3′-非编码区等。
一般而言,“启动子”或“启动子序列”是能够与细胞内RNA聚合酶结合(如直接或通过其它启动子结合蛋白质或物质)并开始转录编码序列的DNA调控区。启动子序列通常在其3′末端被转录起始位点结合,向上游(5′方向)延伸,包括以任何水平开始转录所需要的最小量碱基或元件。在启动子序列内,可发现转录起始位点(例如通过用S1单链核酸酶作图方便地限定)以及负责与RNA聚合酶结合的蛋白质结合域(共有序列)。可使启动子与其它表达控制序列(包括增强子和阻遏子序列)或与本发明的多核苷酸可操作性缔合。可用于控制基因表达的启动子包括但不限于巨细胞病毒(CMV)启动子(美国专利号5,385,839和5,168,062)、SV40早期启动子区(Benoist等,(1981)Nature290:304-310)、包含在Rous肉瘤病毒3′长末端重复中的启动子(Yamamoto等,(1980)Cell 22:787-797)、疱疹胸腺嘧啶核苷激酶启动子(Wagner等,(1981)Proc.Natl.Acad.Sci.USA 78:1441-1445)、金属硫蛋白基因的调控序列(Brinster等,(1982)Nature 296:39-42);原核表达载体如β-内酰胺酶启动子(Villa-Komaroff等,(1978)Proc.Natl.Acad.Sci.USA 75:3727-3731)或者tac启动子(DeBoer等,(1983)Proc.Natl.Acad.Sci.USA 80:21-25);还参阅“Useful proteins from recombinant bacteria(来自细菌重组体的有用的蛋白质)”Scientific American(1980)242:74-94;以及来自酵母或其它真菌的启动子元件如Gal 4启动子、ADC(醇脱氢酶)启动子、PGK(甘油磷酸激酶)启动子或碱性磷酸酶启动子。
编码序列在细胞内转录和翻译控制序列“控制之下”、“与其功能性联合”或“与其可操作性联合”,当该序列指示RNA聚合酶介导编码序列转录入RNA、优选mRNA内时,可将其RNA剪接(如果它包含内含子),任选翻译成由该编码序列编码的蛋白质。
术语“表达(express)”和“表达(expression)”指允许或引起基因、RNA或DNA序列的信息表现出来;例如,通过激活与相应基因转录和翻译有关的细胞功能产生蛋白质。DNA序列表达在细胞中或者由细胞形成“表达产物”如RNA(如mRNA)或蛋白质。表达产物本身也可称为被细胞“表达”。
术语“转化”指将多核苷酸引入细胞。引入的基因或序列可称为“克隆”。接受引入DNA或RNA的宿主细胞已经被“转化”,是“转化体”或“克隆”。引入宿主细胞的DNA或RNA可来自任何来源,包括与宿主细胞相同种类或物种的细胞,或者来自不同种类或物种的细胞。
术语“载体”包括媒介物(如质粒),其中可将DNA或RNA序列引入宿主细胞内,以便转化宿主,任选启动所引入序列的表达和/或复制。
可用于本发明的载体包括质粒、病毒、噬菌体、可整合的DNA片段及可促进多核苷酸引入宿主内的其它媒介物。虽然质粒是最常用的载体形式,但本领域已知或者变成已知的发挥相似功能的所有其它载体形式都适用于本文。参阅如Pouwels等,Cloning Vectors:A Laboratory Manual(克隆载体:实验手册),1985和Supplements,Elsevier,N.Y.,和Rodriguez等(编辑),Vectors:A Survey of Molecular Cloning Vectors and Their Uses(载体:分子克隆载体及其用途的调查),1988,Buttersworth,Boston,MA。
本发明包括制备MCP1(如成熟MCP1多肽)、MCP1多聚体或其融合物(如与体内半衰期延长部分(如Ig)融合)(如表达系统)的方法。在本发明的实施方案中,将MCP1或其多聚体或融合物插入引入合适的宿主细胞的表达载体内。然后让蛋白质在宿主细胞中表达。可将蛋白质从宿主细胞中分离和再纯化。通过此类方法制备的任何多肽也在本发明的范围之内。
术语“表达系统”指在合适条件下,可表达由载体携带和引入宿主细胞的蛋白质或核酸的宿主细胞和相容性载体。常用表达系统包括大肠杆菌(E.coli)宿主细胞或哺乳动物宿主细胞(如CHO细胞、HEK293细胞和骨髓瘤细胞)和质粒载体、昆虫宿主细胞和杆状病毒载体,以及哺乳动物宿主细胞和载体。
编码本发明的MCP1或其多聚体或融合物的核酸的表达可在原核或真核细胞中用常规方法进行。虽然原核系统最常应用大肠杆菌(E.coli)宿主细胞,但也可使用本领域已知的许多其它细菌,如假单胞菌属和杆菌属的各种菌株。适合表达编码多肽的核酸的宿主细胞包括原核生物和高等真核生物。原核生物包括革兰氏阴性和革兰氏阳性生物,如大肠杆菌(E.coli)和枯草芽孢杆菌(B.subtilis)。高等真核生物包括来自动物细胞的已建立的组织培养细胞系(如CHO细胞),所述动物细胞包括非哺乳动物来源(如昆虫细胞和鸟)和哺乳动物来源(如人、灵长类和啮齿类)。
原核宿主-载体系统包括用于许多不同物种的多种载体。扩增DNA的代表性载体是pBR322或其多种衍生物的任何一种(如pUC18或19)。可用于表达MCP1多肽的载体包括但不限于包含lac启动子(pUC-系列)、trp启动子(pBR322-trp)、Ipp启动子(pIN-系列)、lambda-pP或pR启动子(pOTS)或hybrid启动子如ptac(pDR540)的载体。参阅Brosius等,"Expression Vectors Employing Lambda-,trp-,lac-,andIpp-derived Promoters(Lambda-、trp-、lac-和Ipp-衍生的启动子使用的表达载体)",Rodriguez和Denhardt(编辑)Vectors:A Survey of Molecular Cloning Vectors and Their Uses(载体:分子克隆载体及其用 途的调查),1988,Buttersworth,Boston,205-236页。可将多种多肽高水平表达在E.coli/T7表达系统中,如公开于美国专利号4,952,496、5,693,489和5,869,320和Davanloo,P.等,(1984)Proc.Natl.Acad.Sci.USA 81:2035-2039;Studier,F.W.等,(1986)J.Mol.Biol.189:113-130;Rosenberg,A.H.等,(1987)Gene 56:125-135;和Dunn,J.J.等,(1988)Gene 68:259。
T7表达系统包括包含表达盒的pET质粒,其中将感兴趣的基因(如MCP1或其多聚体或融合物)插入来自大肠杆菌(E.coli)噬菌体T7的极强启动子之后(Studier等,J.Mol.Biol.189(1):113-30(1986))。在T7聚合酶缺乏时,该启动子关闭。为了发生表达,将pET质粒转化入菌株内,该菌株通常包含λ溶源菌(最常用的溶源菌称为DE3)染色体上T7聚合酶的单拷贝。T7聚合酶在Lac-UV5 lac启动子的控制之下。当细胞在无乳糖的培养基中生长时,lac阻遏子(lacl)与lac操纵子结合,防碍lac启动子转录。当乳糖是唯一碳源,或者当乳糖类似物异丙基-β-D-硫代半乳糖苷(IPTG)加入培养基时,乳糖(或IPTG)与阻遏子结合,诱导其与操纵子分离,允许启动子转录。将葡萄糖加入培养基内,通过分解物阻遏机制促成T7 RNA聚合酶的阻遏。
高等真核组织培养细胞也可用于本发明的MCP1或其多聚体或融合物的重组制备。可使用高等真核组织培养细胞系,包括昆虫杆状病毒表达系统和哺乳动物细胞。此类细胞的转化或转染和增殖可成为常规操作。有用的细胞系实例包括HeLa细胞、中国仓鼠卵巢(CHO)细胞系、HEK 293细胞、骨髓瘤细胞、J774细胞、Caco2细胞、幼大鼠肾(BRK)细胞系、昆虫细胞系、鸟细胞系和猴(COS)细胞系。通常,此类细胞系的表达载体包括复制起始点、启动子、翻译起始位点、RNA剪接位点(如果用基因组DNA)、多腺苷酸化位点和转录终止位点。这些载体通常也包含选择基因或扩增基因。合适的表达载体可以由质粒、病毒或逆转录病毒携带启动子衍生,如衍生自此类来源如腺病毒、SV40、细小病毒、痘苗病毒或巨细胞病毒。表达载体的实例包括 pCDNA1、pCD(Okayama等,(1985)Mol.Cell Biol.5:1136)、pMClneo Poly-A(Thomas等,(1987)Cell 51:503)、pREP8、pSVSPORT及其衍生物,和杆状病毒载体如pAC373或pAC610。
pCDNA1、pCD(Okayama等,(1985)Mol.Cell Biol.5:1136)、pMClneo Poly-A(Thomas等,(1987)Cell 51:503)、pREP8、pSVSPORT及其衍生物,和杆状病毒载体如pAC373或pAC610。
在本发明的实施方案中,可将MCP1-Ig用蛋白质A或蛋白质G层析纯化。蛋白质A和蛋白质G优选与免疫球蛋白结合。而且,可将多肽用标准方法纯化,所述方法包括但不限于盐或醇沉淀、亲和层析、制备圆盘凝胶电泳、等电聚焦、高压液相层析(HPLC)、反相HPLC、凝胶过滤、阳离子和阴离子交换和分配层析以及逆流分配。此类纯化方法已为本领域熟知,公开于如“Guide to Protein Purification(蛋白质纯化指南)”,Methods in Enzymology,182卷,M.Deutscher编辑,1990,Academic Press,New York,NY。当从细胞或组织来源分离多肽时,在测定系统中优选包含一种或多种蛋白水解酶抑制剂,如苯甲磺酰氟(PMSF)、Pefabloc SC、抑肽素、亮肽素、糜蛋白酶抑素和EDTA。
发生在多肽内的修饰(如翻译后修饰)通常将是其如何产生的功能。对于宿主内克隆基因表达产生的多肽,例如修饰的性质和程度,大部分将取决于宿主细胞的翻译后修饰能力和多肽氨基酸序列中存在的修饰信号。例如,众所周知,糖基化通常不发生在细菌宿主如大肠杆菌(E.coli)中。因此,当需要MCP1或其多聚体或融合物糖基化时,可将多肽表达在糖基化宿主、通常是真核细胞中。昆虫细胞通常发生与哺乳动物细胞相似的翻译后糖基化。由于这种原因,已经开发有效地表达具有天然糖基化模式的哺乳动物蛋白质的昆虫细胞表达系统。可用于本发明的昆虫细胞是来自昆虫纲生物体的任何细胞;例如,所述昆虫是草地贪夜蛾(Spodoptera fruigiperda)(Sf9或Sf21)或者粉纹夜蛾(Trichoplusia ni)(High 5)。可用于本发明(例如制备MCP1或其多聚体或融合物)的昆虫表达系统实例包括Bac-To-Bac(InvitrogenCorporation,Carlsbad,CA)或Gateway(Invitrogen Corporation,Carlsbad,CA)。如果需要,可在制备真核表达系统时用去糖基化酶除去连接的碳水化合物。
可用常规和本领域熟知的方法使多肽如MCP1或其融合物或多聚体聚乙二醇化或加入聚乙二醇(PEG)(参阅如美国专利号5,691,154、美国专利号5,686,071、美国专利号5,639,633、美国专利号5,492,821、美国专利号5,447,722、美国专利号5,091,176)。
本发明涉及对本发明的MCP1或其多聚体或融合物相应的氨基酸或核苷酸序列的任何表面或轻度修饰。具体来讲,本发明涉及编码本发明多肽的多核苷酸的序列保守性变异。多核苷酸序列的“序列保守性变异”是指其中特定密码子内一个或多个核苷酸的改变不引起该位置编码的氨基酸改变。本发明还涉及本发明多肽的功能保守性变异。“功能保守性变异”是指其中蛋白质或酶的一个或多个氨基酸残基已经改变,多肽的总体构象和功能未改变,包括但决不限于一种氨基酸被具有相似特性的氨基酸置换。本领域熟知特性相似的氨基酸。例如,可互换的极性/亲水氨基酸包括天冬酰胺、谷氨酰胺、丝氨酸、半胱氨酸、苏氨酸、赖氨酸、精氨酸、组氨酸、天冬氨酸和谷氨酸;可互换的非极性/疏水氨基酸包括甘氨酸、丙氨酸、缬氨酸、亮氨酸、异亮氨酸、脯氨酸、酪氨酸、苯丙氨酸、色氨酸和蛋氨酸;可互换的酸性氨基酸包括天冬氨酸和谷氨酸,可互换的碱性氨基酸包括组氨酸、赖氨酸和精氨酸。
本发明包括编码MCP1(如成熟MCP1多肽)、MCP1多聚体或其融合物(如与体内半衰期延长部分(如Ig)融合)(如任何SEQ ID NO:1、2、8-12)的多核苷酸以及杂交为多核苷酸的核酸。优选核酸在低严紧性条件、更优选在中严紧性条件且最优选在高严紧性条件下杂交。在适当的温度和溶液离子强度条件下,当核酸分子的单链形式退火为另一种核酸分子时,该核酸分子“可杂交为”另一种核酸分子,如cDNA、基因组DNA或RNA(参阅Sambrook等,同上)。温度和离子强度的条件决定杂交的“严紧性”。典型低严紧性杂交条件是55℃、5×SSC、0.1%SDS、0.25%牛奶和无42℃甲酰胺;或者30%甲酰胺、5×SSC、0.5%SDS和42℃。通常,中严紧性杂交条件类似于低严紧性条件,但杂交在40%甲酰胺中,用5×或6×SSC在42℃进行。高严紧性杂交条件与低严紧性条件相似,但杂交条件在50%甲酰胺、5×或6×SSC中,任选在更高温度(如高于42℃:57℃、59℃、60℃、62℃、63℃、65℃或68℃)下进行。一般而言,SSC是0.15M NaCl和0.015M枸橼酸钠。杂交要求两种核酸包含互补序列,但根据杂交的严紧性,碱基之间可能错配。核酸杂交的合适严紧性取决于核酸长度和互补度,为本领域熟知的变量。两种核苷酸序列之间相似性或同源性程度越大,核酸可杂交的严紧性越高。对于长度大于100个核苷酸的杂交,已经建立计算解链温度的公式(参阅Sambrook等,同上,9.50-9.51)。对于较短核酸即寡核苷酸的杂交,错配的位置变得更重要,寡核苷酸的长度决定其特异性(参阅Sambrook等,同上)。
本发明还包括含核苷酸序列的多核苷酸和含氨基酸序列的多肽,当用BLAST算法进行比较时,与参考MCP1(如成熟MCP1多肽)、MCP1多聚体或其融合物(如与体内半衰期延长部分(如Ig)融合)的任何SEQ ID NO:13和19-23的核苷酸序列和任何SEQ ID NO:1、2和8-12的氨基酸序列至少约70%相同、优选至少约80%相同、更优选至少约90%相同且最优选至少约95%相同(如95%、96%、97%、98%、99%、100%),其中选择该算法的参数使各序列之间的最大配对超过各参考序列的全长。
本发明还包括含氨基酸序列的多肽,当用BLAST算法进行比较时,与参考MCP1(如成熟MCP1多肽)、MCP1多聚体或其融合物(如与体内半衰期延长部分(如Ig)融合)的任何SEQ ID NO:1、2和8-12至少约70%相似、优选至少约80%相似、更优选至少约90%相似且最优选至少约95%相似(如95%、96%、97%、98%、99%、100%),其中选择该算法的参数使各序列之间的最大配对超过各参考序列的全长。
序列一致性指被比较的两种序列核苷酸或氨基酸之间的精确配对。序列相似性指除了不一致的生化相关性氨基酸之间匹配之外,被比较的两种多肽氨基酸之间的精确匹配。具有相似特性且可互换的生化相关性氨基酸在上文讨论。
下列关于BLAST算法的参考文献通过引用结合到本文中:BLAST算法:Altschul,S.F.等,(1990)J.Mol.Biol.215:403-410;Gish,W.等,(1993)Nature Genet.3:266-272;Madden,T.L.等,(1996)Meth.Enzymol.266:131-141;Altschul,S.F.等,(1997)Nucleic Acids Res.25:3389-3402;Zhang,J.等,(1997)Genome Res.7:649-656;Wootton,J.C.等,(1993)Comput.Chem.17:149-163;Hancock,J.M.等,(1994)Comput.Appl.Biosci.10:67-70;校准评分系统:Dayhoff,M.O.等,"A model ofevolutionary change in proteins."在Atlas of Protein Sequence and Structure(蛋白质序列和结构图谱),(1978)第5卷,增刊3.M.O.Dayhoff(编辑),345-352页,Natl.Biomed.Res.Found.,Washington,DC;Schwartz,R.M.等,"Matrices for detecting distant relationships."在Atlas of Protein Sequence and Structure(蛋白质序列和结构图谱),(1978)第5卷,增刊3.M.O.Dayhoff(编辑),353-358页,Natl.Biomed.Res.Found.,Washington,DC;Altschul,S.F.,(1991)J.Mol.Biol.219:555-565;States,D.J.等,(1991)Methods 3:66-70;Henikoff,S.等,(1992)Proc.Natl.Acad.Sci.USA 89:10915-10919;Altschul,S.F.等,(1993)J.Mol.Evol.36:290-300;校准统计学:Karlin,S.等,(1990)Proc.Natl.Acad.Sci.USA 87:2264-2268;Karlin,S.等,(1993)Proc.Natl.Acad.Sci.USA90:5873-5877;Dembo,A.等,(1994)Ann.Prob.22:2022-2039;和Altschul,S.F."Evaluating the statistical significance of multiple distinctlocal alignments(计算多种不同局部对比的统计学显著性)."在Theoretical and Computational Methods in Genome Research(基因组研 究的理论和计算方法)(S.Suhai,编辑),(1997)1-14页,Plenum,NewYork。
趋化因子配体及其融合物
本发明包括包含任选通过连接肽(如GS)与一种或多种“半衰期延长部分”融合的一种或多种任何趋化因子如MCP1多肽的任何融合多肽。本发明还包括包含融合入单纯连续多肽链的两种或多种趋化因子多肽或其片段的任何趋化因子配体多聚体。
在本发明的实施方案中,趋化因子多肽是MCP1、SDF1(包括SDF1α或SDF1β;参阅基因库检索号P48061)或MIP1β(参阅基因库检索号NP_002975.1、AAA36656.1、AAA36752.1、AAA51576.1、AAA57256.1、AAB00790.1、AAX07292.1、CAA34291.1、CAA37722.2、CAA37723.1或CAG46916.1)。在本发明的实施方案中,趋化因子多肽是CCL或CXCL类趋化因子的任何成员,如任何CCL1、2、3、4、5、6、7、8、9/10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27或28;或者任何CXCL1、2、3、4、5、6、7、8、9、10、11、12、13、14、15或16。例如,在本发明的实施方案中,趋化因子选自I309、MIP1α、MIP1β、RANTES、C10、MCP2、MCP3、CCF18、嗜酸细胞活化趋化因子1、MCP4、MCP5、HCC1、HCC2、NCC4、TARC、PARK、ELC、LARC、SLC、MDC、MPIF1、嗜酸细胞活化趋化因子2、TECK、嗜酸细胞活化趋化因子3、ALP、CTACK的任何一种。例如,在本发明的实施方案中,趋化因子选自CCL23、CCL28、GROα、GROβ、GROγ、PF4、ENA78、GCP2、PBP、β-TG、CTAP-III、NAP-2、IL-8、MIG、IP10、I-TAC、SDF1、BLC、BRAK、lungine、淋巴细胞趋化因子或fractalkine的任何一种。本发明包括包含与半衰期延长部分(如MCP1-SDF1-Ig)融合的1种以上趋化因子的融合物。
“半衰期延长部分”是附加于多肽时,延长多肽在受试者机体(如在受试者血浆中)的体内半衰期的任何部分,如多肽、小分子或聚合物。例如,在本发明的实施方案中,半衰期延长部分是聚乙二醇(PEG)、单甲氧基PEG(mPEG)或免疫球蛋白(Ig)。在本发明的实施方案中,PEG是5、10、12、20、30、40或50kDa或更大的部分,或者包含约12000个乙二醇单元(PEG12000)。
术语“Ig”或“免疫球蛋白”包括来自任何物种如人或小鼠的任何免疫球蛋白及其任何片段或变异体或突变体。该术语包括任何重链IgG(如IgG1、IgG2、IgG3或IgG4)、IgA(如IgA1或IgA2)、IgM、IgD和IgE。在本发明的实施方案中,“Ig”或“免疫球蛋白”指来自从铰链区至重链CH3的任何上述多肽。在本发明的实施方案中,“Ig”是免疫球蛋白的“单体变异体”或“单体”。免疫球蛋白的单体变异体不与另一种免疫球蛋白(参阅如SEQ ID NO:5和7)二聚化。通过使涉及免疫球蛋白二聚化的一个或多个残基(如半胱氨酸残基)突变,可构建任何免疫球蛋白的单体变异体。例如,可使半胱氨酸残基突变为丝氨酸。
本发明还提供MCP1多聚体(如(成熟或未加工的MCP1)n其中n=2、3、4、5、6、7、8、9或10以上)。MCP1多聚体包含与一种或多种其它MCP1多肽或其成熟多肽融合的一种或多种MCP1多肽或其成熟多肽。
术语“MCP1”包括来自任何生物体(如来自任何哺乳动物如人、黑猩猩、犬类(参阅如检索号P52203)、红原鸡、印度野牛(参阅如检索号P28291)、褐家鼠(参阅如检索号XP_213425)或小家鼠)的任何MCP1基因或蛋白质或其任何同系物或片段(如成熟MCP1)。用几个同义词描述MCP1,包括CCL2、HC11、MCAF、MCP1、MCP1、SCYA2、GDCF-2、SMC-CF、HSMCR30、MGC9434、GDCF-2和HC11。成熟MCP1多肽缺乏位于未加工或不成熟MCP1多肽的前导序列。本领域普通技术人员很容易鉴定前导序列。在本发明的实施方案中,MCP1前导序列是SEQ ID NO:1的氨基酸1-23。
术语“MCP1-Ig”包括含有与一种或多种免疫球蛋白多肽或其片段(如人IgG4或IgG1或其片段,只包括铰链至CH3区)以任何方式和任何方向融合的一种或多种MCP1多肽(如人或小鼠)或其片段的多肽。
在本发明的实施方案中,未加工的人MCP1多肽序列包含下列氨基酸序列:
MKVSAALLCLLLIAATFIPQGLAQPDAINAPVTCCYNFTNRKISVQRLASYRRITSSKCPKEAVIFKTIVAKEICADPKQKWVQDSMDHLDKQTQTPKT(SEQ ID NO:1)。
在本发明的实施方案中,人MCP1的成熟多肽序列包含下列氨基酸序列:
QPDAINAPVTCCYNFTNRKISVQRLASYRRITSSKCPKEAVIFKTIVAKEICADPKQKWVQDSMDHLDKQTQTPKT(SEQ ID NO:2)。
在本发明的实施方案中,成熟MCP1是SEQ ID NO:1的氨基酸30-99。在本发明的实施方案中,成熟MCP1包含SEQ ID NO:2的氨基酸序列,其中将焦谷氨酸加入N-端,在本发明的另一个实施方案中,成熟MCP1包含SEQ ID NO:2的氨基酸序列,其中N-端谷氨酰胺(Q)被焦谷氨酸代替。
在本发明的实施方案中,小鼠MCP1包含UniProtKB/Swiss-Prot检索号P10148或者检索号NP_035463或IPI00108087.1的氨基酸序列。本发明实施方案还包括这些多肽的成熟、加工版本(如其中除去信号肽氨基酸1-23)。在本发明的实施方案中,小鼠MCP1包含氨基酸序列:
mqvpvmllgl lftvagwsih vlaqpdavna pltccysfts kmipmsrles ykritssrcpkeavvfvtkl krevcadpkk ewvqtyiknl drnqmrsept tlfktasalr ssaplnvkltrkseanastt fstttsstsv gvtsvtvn
(SEQ ID NO:30)
在本发明的实施方案中,小鼠免疫球蛋白重链恒定区(仅为铰链至CH3)的成熟多肽序列,同种型γ1包含氨基酸序列:
VPRDCGCKPCICTVPEVSSVFIFPPKPKDVLTITLTPKVTCVVVDISKDDPEVQFSWFVDDVEVHTAQTKPREEQFNSTFRSVSELPIMHQDWLNGKEFKCRVNSAAFPAPIEKTISKTKGRPKAPQVYTIPPPKEQMAKDKVSLTCMITDFFPEDITVEWQWNGQPAENYKNTQPIMDTDGSYFVYSKLNVQKSNWEAGNTFTCSVLHEGLHNHHTEKSLSHSPGK(SEQ ID NO:3)
在本发明的实施方案中,人免疫球蛋白重链恒定区(仅为铰链至CH3)的成熟多肽序列,同种型γ4包含氨基酸序列:
ESKYGPPCPSCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(SEQ ID NO:4)
在本发明的实施方案中,人免疫球蛋白重链恒定区(仅为铰链至CH3)的成熟多肽序列,同种型γ4单体变异体(下划线为铰链区C突变为S)包含氨基酸序列:
ESKYGPPSPSSPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(SEQ ID NO:5)
在本发明的实施方案中,人免疫球蛋白重链恒定区(仅为铰链至CH3)的成熟多肽序列,同种型γ1包含氨基酸序列:
VEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:6)
在本发明的实施方案中,人免疫球蛋白重链恒定区(仅为铰链至CH3)的成熟多肽序列,同种型γ1单体变异体(下划线为铰链区C突变为S)包含氨基酸序列:
VEPKSSDKTHTSPPSPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:7)
在本发明的实施方案中,与小鼠IgG1(下划线为接头)融合的成熟人MCP1多肽序列包含氨基酸序列:
QPDAINAPVTCCYNFTNRKISVQRLASYRRITSSKCPKEAVIFKTIVAKEICADPKQKWVQDSMDHLDKQTQTPKTGSVPRDCGCKPCICTVPEVSSVFIFPPKPKDVLTITLTPKVTCVVVDISKDDPEVQFSWFVDDVEVHTAQTKPREEQFNSTFRSVSELPIMHQDWLNGKEFKCRVNSAAFPAPIEKTISKTKGRPKAPQVYTIPPPKEQMAKDKVSLTCMITDFFPEDITVEWQWNGQPAENYKNTQPIMDTDGSYFVYSKLNVQKSNWEAGNTFTCSVLHEGLHNHHTEKSLSHSPGK(SEQ ID NO:8)
在本发明的实施方案中,与人IgG4(下划线为接头)融合的成熟人MCP1多肽序列包含氨基酸序列:
QPDAINAPVTCCYNFTNRKISVQRLASYRRITSSKCPKEAVIFKTIVAKEICADPKQKWVQDSMDHLDKQTQTPKTGSESKYGPPCPSCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(SEQ ID NO:9)
在本发明的实施方案中,与人IgG4单体变异体(下划线为接头)融合的成熟人MCP1多肽序列包含氨基酸序列:
QPDAINAPVTCCYNFTNRKISVQRLASYRRITSSKCPKEAVIFKTIVAKEICADPKQKWVQDSMDHLDKQTQTPKTGSESKYGPPSPSSPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK(SEQ ID NO:10)
在本发明的实施方案中,与人IgG1(下划线为接头)融合的成熟人MCP1多肽序列包含氨基酸序列:
QPDAINAPVTCCYNFTNRKISVQRLASYRRITSSKCPKEAVIFKTIVAKEICADPKQKWVQDSMDHLDKQTQTPKTGSVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQID NO:11)
在本发明的实施方案中,与人IgG1单体变异体(下划线为接头)融合的人MCP1多肽序列包含氨基酸序列:
QPDAINAPVTCCYNFTNRKISVQRLASYRRITSSKCPKEAVIFKTIVAKEICADPKQKWVQDSMDHLDKQTQTPKTGSVEPKSSDKTHTSPPSPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ IDNO:12)
在本发明的实施方案中,人MCP1编码区的DNA序列包含核苷酸序列(下划线为起始和终止密码子;粗体字为成熟多肽第一个氨基酸的密码子):
atgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagacttga(SEQ ID NO:13)
在本发明的实施方案中,小鼠重链免疫球蛋白恒定区γ1同种型,从铰链区氨基末端开始至CH3区羧基末端终止(下划线为终止密码子)的DNA序列包含核苷酸序列:
gtgcccagggattgtggttgtaagccttgcatatgtacagtcccagaagtatcatctgtcttcatcttccccccaaagcccaaggatgtgctcaccattactctgactcctaaggtcacgtgtgttgtggtagacatcagcaaggatgatcccgaggtccagttcagctggtttgtagatgatgtggaggtgcacacagctcagacaaaaccccgggaggagcagttcaacagcactttccgttcagtcagtgaacttcccatcatgcaccaggactggctcaatggcaaggagttcaaatgcagggtcaacagtgcagctttccctgcccccatcgagaaaaccatctccaaaaccaaaggcagaccgaaggctccacaggtgtacaccattccacctcccaaggagcagatggccaaggataaagtcagtctgacctgcatgataacagacttcttccctgaagacattactgtggagtggcagtggaatgggcagccagcggagaactacaagaacactcagcccatcatggacacagatggctcttacttcgtctacagcaagctcaatgtgcagaagagcaactgggaggcaggaaatactttcacctgctctgtgttacatgagggcctgcacaaccaccatactgagaagagcctctcccactctcctggtaaatga(SEQ ID NO:14)
在本发明的实施方案中,人重链免疫球蛋白恒定区γ4同种型,从铰链区氨基末端开始至CH3区羧基末端终止(下划线为终止密码子)的DNA序列包含核苷酸序列:
gagtccaaatatggtcccccatgcccatcatgcccagcacctgagttcctggggggaccatcagtcttcctgttccccccaaaacccaaggacactctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccaggaagaccccgaggtccagttcaactggtacgtggatggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagttcaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccgtcctccatcgagaaaaccatctccaaagccaaagggcagccccgagagccacaggtgtacaccctgcccccatcccaggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaggctaaccgtggacaagagcaggtggcaggaggggaatgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacacagaagagcctctccctgtctctgggtaaat ga(SEQ ID NO:15)
在本发明的实施方案中,人重链免疫球蛋白恒定区γ4同种型单体变异体,从铰链区氨基末端开始至CH3区羧基末端终止(下划线是半胱氨酸变为丝氨酸;粗体为终止密码子)的DNA序列包含核苷酸序列:
gagtccaaatatggtcccccatctccatcatctccagcacctgagttcctggggggaccatcagtcttcctgttccccccaaaacccaaggacactctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccaggaagaccccgaggtccagttcaactggtacgtggatggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagttcaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccgtcctccatcgagaaaaccatctccaaagccaaagggcagccccgagagccacaggtgtacaccctgcccccatcccaggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaggctaaccgtggacaagagcaggtggcaggaggggaatgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacacagaagagcctctccctgtctctgggtaaatga(SEQ ID NO:16)
在本文列出的任何免疫球蛋白单体变异体(其中一个或多个半胱氨酸已经突变)中,编码丝氨酸的密码子可以是编码丝氨酸的任何密码子;例如AGT、AGC、TCT、TCC、TCA或TCG。
在本发明的实施方案中,人重链免疫球蛋白恒定区γ1同种型,从铰链区氨基末端开始至CH3区羧基末端终止(下划线是终止密码子)的DNA序列包含核苷酸序列:
gttgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga(SEQ ID NO:17)
在本发明的实施方案中,人重链免疫球蛋白恒定区γ1同种型单体变异体,从铰链区氨基末端开始至CH3区羧基末端终止(下划线是半胱氨酸变为丝氨酸;粗体为终止密码子)的DNA序列包含核苷酸序列:
gttgagcccaaatcttctgacaaaactcacacatctccaccgtctccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga(SEQ ID NO:18)
在本发明的实施方案中,与小鼠IgG1融合的人MCP1(包括前导肽)的cDNA包含核苷酸序列:
atgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagactggatccgtgcccagggattgtggttgtaagccttgcatatgtacagtcccagaagtatcatctgtcttcatcttccccccaaagcccaaggatgtgctcaccattactctgactcctaaggtcacgtgtgttgtggtagacatcagcaaggatgatcccgaggtccagttcagctggtttgtagatgatgtggaggtgcacacagctcagacaaaaccccgggaggagcagttcaacagcactttccgttcagtcagtgaacttcccatcatgcaccaggactggctcaatggcaaggagttcaaatgcagggtcaacagtgcagctttccctgcccccatcgagaaaaccatctccaaaaccaaaggcagaccgaaggctccacaggtgtacaccattccacctcccaaggagcagatggccaaggataaagtcagtctgacctgcatgataacagacttcttccctgaagacattactgtggagtggcagtggaatgggcagccagcggagaactacaagaacactcagcccatcatggacacagatggctcttacttcgtctacagcaagctcaatgtgcagaagagcaactgggaggcaggaaatactttcacctgctctgtgttacatgagggcctgcacaaccaccatactgagaagagcctctcccactctcctggtaaatga(SEQ ID NO:19)
在本发明的实施方案中,与人IgG4融合的人MCP1(包括前导肽)的cDNA包含核苷酸序列:
atgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagactggatccgagtccaaatatggtcccccatgcccatcatgcccagcacctgagttcctggggggaccatcagtcttcctgttccccccaaaacccaaggacactctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccaggaagaccccgaggtccagttcaactggtacgtggatggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagttcaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccgtcctccatcgagaaaaccatctccaaagccaaagggcagccccgagagccacaggtgtacaccctgcccccatcccaggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaggctaaccgtggacaagagcaggtggcaggaggggaatgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacacagaagagcctctccctgtctctgggtaaatga(SEQ ID NO:20)
在本发明的实施方案中,与人IgG4单体变异体融合的人MCP1(包括前导序列)的cDNA包含核苷酸序列:
atgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagactggatccgagtccaaatatggtcccccatctccatcatctccagcacctgagttcctggggggaccatcagtcttcctgttccccccaaaacccaaggacactctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccaggaagaccccgaggtccagttcaactggtacgtggatggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagttcaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccgtcctccatcgagaaaaccatctccaaagccaaagggcagccccgagagccacaggtgtacaccctgcccccatcccaggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaggctaaccgtggacaagagcaggtggcaggaggggaatgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacacagaagagcctctccctgtctctgggtaaatga(SEQ ID NO:21)
在本发明的实施方案中,与人IgG1融合的人MCP1(包括前导序列)的cDNA包含核苷酸序列:
atgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagactggatccgttgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga(SEQ ID NO:22)
在本发明的实施方案中,与人IgG1单体变异体融合的人MCP1(包括前导序列)的cDNA包含核苷酸序列:
atgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagactggatccgttgagcccaaatcttctgacaaaactcacacatctccaccgtctccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatga(SEQ ID NO:23)
在本发明的实施方案中,编码包含成熟人MCP1和小鼠IgG的融合蛋白的表达质粒即质粒pcDNA3.1(+)hMCP1mIgG的序列(下划线为起始和终止密码子,粗体为MCP1与mIg接头的密码子)包含核苷酸序列:
gacggatcgggagatctcccgatcccctatggtgcactctcagtacaatctgctctgatgccgcatagttaagccagtatctgctccctgcttgtgtgttggaggtcgctgagtagtgcgcgagcaaaatttaagctacaacaaggcaaggcttgaccgacaattgcatgaagaatctgcttagggttaggcgttttgcgctgcttcgcgatgtacgggccagatatacgcgttgacattgattattgactagttattaatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctctctggctaactagagaacccactgcttactggcttatcgaaattaatacgactcactatagggagacccaagctggctagcgtttaaacttaagcttacgatcagtcgaattcgccgccaccatgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagactggatccgtgcccagggattgtggttgtaagccttgcatatgtacagtcccagaagtatcatctgtcttcatcttccccccaaagcccaaggatgtgctcaccattactctgactcctaaggtcacgtgtgttgtggtagacatcagcaaggatgatcccgaggtccagttcagctggtttgtagatgatgtggaggtgcacacagctcagacaaaaccccgggaggagcagttcaacagcactttccgttcagtcagtgaacttcccatcatgcaccaggactggctcaatggcaaggagttcaaatgcagggtcaacagtgcagctttccctgcccccatcgagaaaaccatctccaaaaccaaaggcagaccgaaggctccacaggtgtacaccattccacctcccaaggagcagatggccaaggataaagtcagtctgacctgcatgataacagacttcttccctgaagacattactgtggagtggcagtggaatgggcagccagcggagaactacaagaacactcagcccatcatggacacagatggctcttacttcgtctacagcaagctcaatgtgcagaagagcaactgggaggcaggaaatactttcacctgctctgtgttacatgagggcctgcacaaccaccatactgagaagagcctctcccactctcctggtaaatgactagtcatagtttagcggccgctcgagtctagagggcccgtttaaacccgctgatcagcctcgactgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggcttctgaggcggaaagaaccagctggggctctagggggtatccccacgcgccctgtagcggcgcattaagcgcggcgggtgtggtggttacgcgcagcgtgaccgctacacttgccagcgccctagcgcccgctcctttcgctttcttcccttcctttctcgccacgttcgccggctttccccgtcaagctctaaatcgggggctccctttagggttccgatttagtgctttacggcacctcgaccccaaaaaacttgattagggtgatggttcacgtagtgggccatcgccctgatagacggtttttcgccctttgacgttggagtccacgttctttaatagtggactcttgttccaaactggaacaacactcaaccctatctcggtctattcttttgatttataagggattttgccgatttcggcctattggttaaaaaatgagctgatttaacaaaaatttaacgcgaattaattctgtggaatgtgtgtcagttagggtgtggaaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagtcagcaaccaggtgtggaaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagtcagcaaccatagtcccgcccctaactccgcccatcccgcccctaactccgcccagttccgcccattctccgccccatggctgactaattttttttatttatgcagaggccgaggccgcctctgcctctgagctattccagaagtagtgaggaggcttttttggaggcctaggcttttgcaaaaagctcccgggagcttgtatatccattttcggatctgatcaagagacaggatgaggatcgtttcgcatgattgaacaagatggattgcacgcaggttctccggccgcttgggtggagaggctattcggctatgactgggcacaacagacaatcggctgctctgatgccgccgtgttccggctgtcagcgcaggggcgcccggttctttttgtcaagaccgacctgtccggtgccctgaatgaactgcaggacgaggcagcgcggctatcgtggctggccacgacgggcgttccttgcgcagctgtgctcgacgttgtcactgaagcgggaagggactggctgctattgggcgaagtgccggggcaggatctcctgtcatctcaccttgctcctgccgagaaagtatccatcatggctgatgcaatgcggcggctgcatacgcttgatccggctacctgcccattcgaccaccaagcgaaacatcgcatcgagcgagcacgtactcggatggaagccggtcttgtcgatcaggatgatctggacgaagagcatcaggggctcgcgccagccgaactgttcgccaggctcaaggcgcgcatgcccgacggcgaggatctcgtcgtgacccatggcgatgcctgcttgccgaatatcatggtggaaaatggccgcttttctggattcatcgactgtggccggctgggtgtggcggaccgctatcaggacatagcgttggctacccgtgatattgctgaagagcttggcggcgaatgggctgaccgcttcctcgtgctttacggtatcgccgctcccgattcgcagcgcatcgccttctatcgccttcttgacgagttcttctgagcgggactctggggttcgaaatgaccgaccaagcgacgcccaacctgccatcacgagatttcgattccaccgccgccttctatgaaaggttgggcttcggaatcgttttccgggacgccggctggatgatcctccagcgcggggatctcatgctggagttcttcgcccaccccaacttgtttattgcagcttataatggttacaaataaagcaatagcatcacaaatttcacaaataaagcatttttttcactgcattctagttgtggtttgtccaaactcatcaatgtatcttatcatgtctgtataccgtcgacctctagctagagcttggcgtaatcatggtcatagctgtttcctgtgtgaaattgttatccgctcacaattccacacaacatacgagccggaagcataaagtgtaaagcctggggtgcctaatgagtgagctaactcacattaattgcgttgcgctcactgcccgctttccagtcgggaaacctgtcgtgccagctgcattaatgaatcggccaacgcgcggggagaggcggtttgcgtattgggcgctcttccgcttcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacaggattagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactacggctacactagaagaacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgagattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactccccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgataccgcgagacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtactcaaccaagtcattctgagaatagtgtatgcggcgaccgagttgctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgctcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagatccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcaccagcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcgacacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagggttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaataggggttccgcgcacatttccccgaaaagtgccacctgacgtc(SEQ ID NO:24)
本发明的融合物包含以任何顺序重复任何次数的一种或多种MCP1和一种或多种半衰期延长部分(如免疫球蛋白)。如果融合物包含多种MCP1,则所述MCP1可以相同或不同。例如在实施方案中,本发明的融合物包含人MCP1-小鼠MCP1-Ig。本发明的融合物还包括多种免疫球蛋白多肽。例如在实施方案中,融合物包含人MCP1-人MCP1-IgG1-IgG1、人MCP1-人MCP1-IgG1-IgG4或人MCP1-Ig-小鼠MCP1-Ig-Ig-人MCP1。任何这些实施方案都包括在术语“MCP1-Ig”中。本发明还包括如(人MCP1)2-PEG或小鼠MCP1-人MCP1-PEG。
本发明羧基端MCP1融合物的范围包括氨基端含有MCP1的融合物;术语MCP1-Ig指这些类型融合物。例如,本发明包括任何下列MCP1-Ig融合物:人MCP1-Ig、Ig-人MCP1、小鼠MCP1-Ig、Ig-小鼠MCP1、PEG-人MCP1或人MCP1-PEG。
在本发明的实施方案中,本发明的MCP1-Ig融合物包含连接MCP1和Ig的接头(如肽接头)。在本发明的实施方案中,接头包含1、2、3、4、5、6、7、8、9或10个氨基酸。
除了pcDNA3.1(+)hMCP1 mIgG之外,下列质粒形成本发明一部分。质粒pcDNA3.1(+)hMCP1 hIgG4(下划线为起始和终止密码子,粗体为MCP-1与mIg接头的密码子):
gacggatcgggagatctcccgatcccctatggtgcactctcagtacaatctgctctgatgccgcatagttaagccagtatctgctccctgcttgtgtgttggaggtcgctgagtagtgcgcgagcaaaatttaagctacaacaaggcaaggcttgaccgacaattgcatgaagaatctgcttagggttaggcgttttgcgctgcttcgcgatgtacgggccagatatacgcgttgacattgattattgactagttattaatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctctctggctaactagagaacccactgcttactggcttatcgaaattaatacgactcactatagggagacccaagctggctagcgtttaaacttaagcttacgatcagtcgaattcgccgccaccatgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagactggatccgagtccaaatatggtcccccatgcccatcatgcccagcacctgagttcctggggggaccatcagtcttcctgttccccccaaaacccaaggacactctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccaggaagaccccgaggtccagttcaactggtacgtggatggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagttcaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccgtcctccatcgagaaaaccatctccaaagccaaagggcagccccgagagccacaggtgtacaccctgcccccatcccaggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaggctaaccgtggacaagagcaggtggcaggaggggaatgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacacagaagagcctctccctgtctctgggtaaatgactagtcatagtttagcggccgctcgagtctagagggcccgtttaaacccgctgatcagcctcgactgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggcttctgaggcggaaagaaccagctggggctctagggggtatccccacgcgccctgtagcggcgcattaagcgcggcgggtgtggtggttacgcgcagcgtgaccgctacacttgccagcgccctagcgcccgctcctttcgctttcttcccttcctttctcgccacgttcgccggctttccccgtcaagctctaaatcgggggctccctttagggttccgatttagtgctttacggcacctcgaccccaaaaaacttgattagggtgatggttcacgtagtgggccatcgccctgatagacggtttttcgccctttgacgttggagtccacgttctttaatagtggactcttgttccaaactggaacaacactcaaccctatctcggtctattcttttgatttataagggattttgccgatttcggcctattggttaaaaaatgagctgatttaacaaaaatttaacgcgaattaattctgtggaatgtgtgtcagttagggtgtggaaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagtcagcaaccaggtgtggaaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagtcagcaaccatagtcccgcccctaactccgcccatcccgcccctaactccgcccagttccgcccattctccgccccatggctgactaattttttttatttatgcagaggccgaggccgcctctgcctctgagctattccagaagtagtgaggaggcttttttggaggcctaggcttttgcaaaaagctcccgggagcttgtatatccattttcggatctgatcaagagacaggatgaggatcgtttcgcatgattgaacaagatggattgcacgcaggttctccggccgcttgggtggagaggctattcggctatgactgggcacaacagacaatcggctgctctgatgccgccgtgttccggctgtcagcgcaggggcgcccggttctttttgtcaagaccgacctgtccggtgccctgaatgaactgcaggacgaggcagcgcggctatcgtggctggccacgacgggcgttccttgcgcagctgtgctcgacgttgtcactgaagcgggaagggactggctgctattgggcgaagtgccggggcaggatctcctgtcatctcaccttgctcctgccgagaaagtatccatcatggctgatgcaatgcggcggctgcatacgcttgatccggctacctgcccattcgaccaccaagcgaaacatcgcatcgagcgagcacgtactcggatggaagccggtcttgtcgatcaggatgatctggacgaagagcatcaggggctcgcgccagccgaactgttcgccaggctcaaggcgcgcatgcccgacggcgaggatctcgtcgtgacccatggcgatgcctgcttgccgaatatcatggtggaaaatggccgcttttctggattcatcgactgtggccggctgggtgtggcggaccgctatcaggacatagcgttggctacccgtgatattgctgaagagcttggcggcgaatgggctgaccgcttcctcgtgctttacggtatcgccgctcccgattcgcagcgcatcgccttctatcgccttcttgacgagttcttctgagcgggactctggggttcgaaatgaccgaccaagcgacgcccaacctgccatcacgagatttcgattccaccgccgccttctatgaaaggttgggcttcggaatcgttttccgggacgccggctggatgatcctccagcgcggggatctcatgctggagttcttcgcccaccccaacttgtttattgcagcttataatggttacaaataaagcaatagcatcacaaatttcacaaataaagcatttttttcactgcattctagttgtggtttgtccaaactcatcaatgtatcttatcatgtctgtataccgtcgacctctagctagagcttggcgtaatcatggtcatagctgtttcctgtgtgaaattgttatccgctcacaattccacacaacatacgagccggaagcataaagtgtaaagcctggggtgcctaatgagtgagctaactcacattaattgcgttgcgctcactgcccgctttccagtcgggaaacctgtcgtgccagctgcattaatgaatcggccaacgcgcggggagaggcggtttgcgtattgggcgctcttccgcttcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacaggattagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactacggctacactagaagaacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgagattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactccccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgataccgcgagacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtactcaaccaagtcattctgagaatagtgtatgcggcgaccgagttgctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgctcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagatccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcaccagcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcgacacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagggttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaataggggttccgcgcacatttccccgaaaagtgccacctgacgtc(SEQ IDNO:25)
质粒pcDNA3.1(+)hMCP1 hIgG4单体变异体(下划线为起始和终止密码子,粗体为MCP-1与mIg接头密码子):
gacggatcgggagatctcccgatcccctatggtgcactctcagtacaatctgctctgatgccgcatagttaagccagtatctgctccctgcttgtgtgttggaggtcgctgagtagtgcgcgagcaaaatttaagctacaacaaggcaaggcttgaccgacaattgcatgaagaatctgcttagggttaggcgttttgcgctgcttcgcgatgtacgggccagatatacgcgttgacattgattattgactagttattaatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctctctggctaactagagaacccactgcttactggcttatcgaaattaatacgactcactatagggagacccaagctggctagcgtttaaacttaagcttacgatcagtcgaattcgccgccaccatgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagactggatccgagtccaaatatggtcccccatctccatcatctccagcacctgagttcctggggggaccatcagtcttcctgttccccccaaaacccaaggacactctcatgatctcccggacccctgaggtcacgtgcgtggtggtggacgtgagccaggaagaccccgaggtccagttcaactggtacgtggatggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagttcaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaacggcaaggagtacaagtgcaaggtctccaacaaaggcctcccgtcctccatcgagaaaaccatctccaaagccaaagggcagccccgagagccacaggtgtacaccctgcccccatcccaggaggagatgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctaccccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaggctaaccgtggacaagagcaggtggcaggaggggaatgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacacagaagagcctctccctgtctctgggtaaatgactagtcatagtttagcggccgctcgagtctagagggcccgtttaaacccgctgatcagcctcgactgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggcttctgaggcggaaagaaccagctggggctctagggggtatccccacgcgccctgtagcggcgcattaagcgcggcgggtgtggtggttacgcgcagcgtgaccgctacacttgccagcgccctagcgcccgctcctttcgctttcttcccttcctttctcgccacgttcgccggctttccccgtcaagctctaaatcgggggctccctttagggttccgatttagtgctttacggcacctcgaccccaaaaaacttgattagggtgatggttcacgtagtgggccatcgccctgatagacggtttttcgccctttgacgttggagtccacgttctttaatagtggactcttgttccaaactggaacaacactcaaccctatctcggtctattcttttgatttataagggattttgccgatttcggcctattggttaaaaaatgagctgatttaacaaaaatttaacgcgaattaattctgtggaatgtgtgtcagttagggtgtggaaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagtcagcaaccaggtgtggaaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagtcagcaaccatagtcccgcccctaactccgcccatcccgcccctaactccgcccagttccgcccattctccgccccatggctgactaattttttttatttatgcagaggccgaggccgcctctgcctctgagctattccagaagtagtgaggaggcttttttggaggcctaggcttttgcaaaaagctcccgggagcttgtatatccattttcggatctgatcaagagacaggatgaggatcgtttcgcatgattgaacaagatggattgcacgcaggttctccggccgcttgggtggagaggctattcggctatgactgggcacaacagacaatcggctgctctgatgccgccgtgttccggctgtcagcgcaggggcgcccggttctttttgtcaagaccgacctgtccggtgccctgaatgaactgcaggacgaggcagcgcggctatcgtggctggccacgacgggcgttccttgcgcagctgtgctcgacgttgtcactgaagcgggaagggactggctgctattgggcgaagtgccggggcaggatctcctgtcatctcaccttgctcctgccgagaaagtatccatcatggctgatgcaatgcggcggctgcatacgcttgatccggctacctgcccattcgaccaccaagcgaaacatcgcatcgagcgagcacgtactcggatggaagccggtcttgtcgatcaggatgatctggacgaagagcatcaggggctcgcgccagccgaactgttcgccaggctcaaggcgcgcatgcccgacggcgaggatctcgtcgtgacccatggcgatgcctgcttgccgaatatcatggtggaaaatggccgcttttctggattcatcgactgtggccggctgggtgtggcggaccgctatcaggacatagcgttggctacccgtgatattgctgaagagcttggcggcgaatgggctgaccgcttcctcgtgctttacggtatcgccgctcccgattcgcagcgcatcgccttctatcgccttcttgacgagttcttctgagcgggactctggggttcgaaatgaccgaccaagcgacgcccaacctgccatcacgagatttcgattccaccgccgccttctatgaaaggttgggcttcggaatcgttttccgggacgccggctggatgatcctccagcgcggggatctcatgctggagttcttcgcccaccccaacttgtttattgcagcttataatggttacaaataaagcaatagcatcacaaatttcacaaataaagcatttttttcactgcattctagttgtggtttgtccaaactcatcaatgtatcttatcatgtctgtataccgtcgacctctagctagagcttggcgtaatcatggtcatagctgtttcctgtgtgaaattgttatccgctcacaattccacacaacatacgagccggaagcataaagtgtaaagcctggggtgcctaatgagtgagctaactcacattaattgcgttgcgctcactgcccgctttccagtcgggaaacctgtcgtgccagctgcattaatgaatcggccaacgcgcggggagaggcggtttgcgtattgggcgctcttccgcttcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacaggattagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactacggctacactagaagaacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgagattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactccccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgataccgcgagacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtactcaaccaagtcattctgagaatagtgtatgcggcgaccgagttgctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgctcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagatccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcaccagcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcgacacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagggttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaataggggttccgcgcacatttccccgaaaagtgccacctgacgtc(SEQ IDNO:26)
质粒pcDNA3.1(+)hMCP1 hIgG1(下划线为起始和终止密码子,粗体为MCP-1与mIg接头密码子):
gacggatcgggagatctcccgatcccctatggtgcactctcagtacaatctgctctgatgccgcatagttaagccagtatctgctccctgcttgtgtgttggaggtcgctgagtagtgcgcgagcaaaatttaagctacaacaaggcaaggcttgaccgacaattgcatgaagaatctgcttagggttaggcgttttgcgctgcttcgcgatgtacgggccagatatacgcgttgacattgattattgactagttattaatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctctctggctaactagagaacccactgcttactggcttatcgaaattaatacgactcactatagggagacccaagctggctagcgtttaaacttaagcttacgatcagtcgaattcgccgccaccatgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagactggatccgttgagcccaaatcttgtgacaaaactcacacatgcccaccgtgcccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgactagtcatagtttagcggccgctcgagtctagagggcccgtttaaacccgctgatcagcctcgactgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggcttctgaggcggaaagaaccagctggggctctagggggtatccccacgcgccctgtagcggcgcattaagcgcggcgggtgtggtggttacgcgcagcgtgaccgctacacttgccagcgccctagcgcccgctcctttcgctttcttcccttcctttctcgccacgttcgccggctttccccgtcaagctctaaatcgggggctccctttagggttccgatttagtgctttacggcacctcgaccccaaaaaacttgattagggtgatggttcacgtagtgggccatcgccctgatagacggtttttcgccctttgacgttggagtccacgttctttaatagtggactcttgttccaaactggaacaacactcaaccctatctcggtctattcttttgatttataagggattttgccgatttcggcctattggttaaaaaatgagctgatttaacaaaaatttaacgcgaattaattctgtggaatgtgtgtcagttagggtgtggaaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagtcagcaaccaggtgtggaaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagtcagcaaccatagtcccgcccctaactccgcccatcccgcccctaactccgcccagttccgcccattctccgccccatggctgactaattttttttatttatgcagaggccgaggccgcctctgcctctgagctattccagaagtagtgaggaggcttttttggaggcctaggcttttgcaaaaagctcccgggagcttgtatatccattttcggatctgatcaagagacaggatgaggatcgtttcgcatgattgaacaagatggattgcacgcaggttctccggccgcttgggtggagaggctattcggctatgactgggcacaacagacaatcggctgctctgatgccgccgtgttccggctgtcagcgcaggggcgcccggttctttttgtcaagaccgacctgtccggtgccctgaatgaactgcaggacgaggcagcgcggctatcgtggctggccacgacgggcgttccttgcgcagctgtgctcgacgttgtcactgaagcgggaagggactggctgctattgggcgaagtgccggggcaggatctcctgtcatctcaccttgctcctgccgagaaagtatccatcatggctgatgcaatgcggcggctgcatacgcttgatccggctacctgcccattcgaccaccaagcgaaacatcgcatcgagcgagcacgtactcggatggaagccggtcttgtcgatcaggatgatctggacgaagagcatcaggggctcgcgccagccgaactgttcgccaggctcaaggcgcgcatgcccgacggcgaggatctcgtcgtgacccatggcgatgcctgcttgccgaatatcatggtggaaaatggccgcttttctggattcatcgactgtggccggctgggtgtggcggaccgctatcaggacatagcgttggctacccgtgatattgctgaagagcttggcggcgaatgggctgaccgcttcctcgtgctttacggtatcgccgctcccgattcgcagcgcatcgccttctatcgccttcttgacgagttcttctgagcgggactctggggttcgaaatgaccgaccaagcgacgcccaacctgccatcacgagatttcgattccaccgccgccttctatgaaaggttgggcttcggaatcgttttccgggacgccggctggatgatcctccagcgcggggatctcatgctggagttcttcgcccaccccaacttgtttattgcagcttataatggttacaaataaagcaatagcatcacaaatttcacaaataaagcatttttttcactgcattctagttgtggtttgtccaaactcatcaatgtatcttatcatgtctgtataccgtcgacctctagctagagcttggcgtaatcatggtcatagctgtttcctg3tgtgaaattgttatccgctcacaattccacacaacatacgagccggaagcataaagtgtaaagcctggggtgcctaatgagtgagctaactcacattaattgcgttgcgctcactgcccgctttccagtcgggaaacctgtcgtgccagctgcattaatgaatcggccaacgcgcggggagaggcggtttgcgtattgggcgctcttccgcttcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacaggattagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactacggctacactagaagaacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgagattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactccccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgataccgcgagacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtactcaaccaagtcattctgagaatagtgtatgcggcgaccgagttgctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgctcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagatccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcaccagcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcgacacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagggttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaataggggttccgcgcacatttccccgaaaagtgccacctgacgtc(SEQ ID NO:27)
质粒pcDNA3.1(+)hMCP1 hIgG1单体变异体(下划线为起始和终止密码子,粗体为MCP-1与mIg接头密码子):
gacggatcgggagatctcccgatcccctatggtgcactctcagtacaatctgctctgatgccgcatagttaagccagtatctgctccctgcttgtgtgttggaggtcgctgagtagtgcgcgagcaaaatttaagctacaacaaggcaaggcttgaccgacaattgcatgaagaatctgcttagggttaggcgttttgcgctgcttcgcgatgtacgggccagatatacgcgttgacattgattattgactagttattaatagtaatcaattacggggtcattagttcatagcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatcaatgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttgttttggcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcggtaggcgtgtacggtgggaggtctatataagcagagctctctggctaactagagaacccactgcttactggcttatcgaaattaatacgactcactatagggagacccaagctggctagcgtttaaacttaagcttacgatcagtcgaattcgccgccaccatgaaagtctctgccgcccttctgtgcctgctgctcatagcagccaccttcattccccaagggctcgctcagccagatgcaatcaatgccccagtcacctgctgttataacttcaccaataggaagatctcagtgcagaggctcgcgagctatagaagaatcaccagcagcaagtgtcccaaagaagctgtgatcttcaagaccattgtggccaaggagatctgtgctgaccccaagcagaagtgggttcaggattccatggaccacctggacaagcaaacccaaactccgaagactggatccgttgagcccaaatcttctgacaaaactcacacatctccaccgtctccagcacctgaactcctggggggaccgtcagtcttcctcttccccccaaaacccaaggacaccctcatgatctcccggacccctgaggtcacatgcgtggtggtggacgtgagccacgaagaccctgaggtcaagttcaactggtacgtggacggcgtggaggtgcataatgccaagacaaagccgcgggaggagcagtacaacagcacgtaccgtgtggtcagcgtcctcaccgtcctgcaccaggactggctgaatggcaaggagtacaagtgcaaggtctccaacaaagccctcccagcccccatcgagaaaaccatctccaaagccaaagggcagccccgagaaccacaggtgtacaccctgcccccatcccgggatgagctgaccaagaaccaggtcagcctgacctgcctggtcaaaggcttctatcccagcgacatcgccgtggagtgggagagcaatgggcagccggagaacaactacaagaccacgcctcccgtgctggactccgacggctccttcttcctctacagcaagctcaccgtggacaagagcaggtggcagcaggggaacgtcttctcatgctccgtgatgcatgaggctctgcacaaccactacacgcagaagagcctctccctgtctccgggtaaatgactagtcatagtttagcggccgctcgagtctagagggcccgtttaaacccgctgatcagcctcgactgtgccttctagttgccagccatctgttgtttgcccctcccccgtgccttccttgaccctggaaggtgccactcccactgtcctttcctaataaaatgaggaaattgcatcgcattgtctgagtaggtgtcattctattctggggggtggggtggggcaggacagcaagggggaggattgggaagacaatagcaggcatgctggggatgcggtgggctctatggcttctgaggcggaaagaaccagctggggctctagggggtatccccacgcgccctgtagcggcgcattaagcgcggcgggtgtggtggttacgcgcagcgtgaccgctacacttgccagcgccctagcgcccgctcctttcgctttcttcccttcctttctcgccacgttcgccggctttccccgtcaagctctaaatcgggggctccctttagggttccgatttagtgctttacggcacctcgaccccaaaaaacttgattagggtgatggttcacgtagtgggccatcgccctgatagacggtttttcgccctttgacgttggagtccacgttctttaatagtggactcttgttccaaactggaacaacactcaaccctatctcggtctattcttttgatttataagggattttgccgatttcggcctattggttaaaaaatgagctgatttaacaaaaatttaacgcgaattaattctgtggaatgtgtgtcagttagggtgtggaaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagtcagcaaccaggtgtggaaagtccccaggctccccagcaggcagaagtatgcaaagcatgcatctcaattagtcagcaaccatagtcccgcccctaactccgcccatcccgcccctaactccgcccagttccgcccattctccgccccatggctgactaattttttttatttatgcagaggccgaggccgcctctgcctctgagctattccagaagtagtgaggaggcttttttggaggcctaggcttttgcaaaaagctcccgggagcttgtatatccattttcggatctgatcaagagacaggatgaggatcgtttcgcatgattgaacaagatggattgcacgcaggttctccggccgcttgggtggagaggctattcggctatgactgggcacaacagacaatcggctgctctgatgccgccgtgttccggctgtcagcgcaggggcgcccggttctttttgtcaagaccgacctgtccggtgccctgaatgaactgcaggacgaggcagcgcggctatcgtggctggccacgacgggcgttccttgcgcagctgtgctcgacgttgtcactgaagcgggaagggactggctgctattgggcgaagtgccggggcaggatctcctgtcatctcaccttgctcctgccgagaaagtatccatcatggctgatgcaatgcggcggctgcatacgcttgatccggctacctgcccattcgaccaccaagcgaaacatcgcatcgagcgagcacgtactcggatggaagccggtcttgtcgatcaggatgatctggacgaagagcatcaggggctcgcgccagccgaactgttcgccaggctcaaggcgcgcatgcccgacggcgaggatctcgtcgtgacccatggcgatgcctgcttgccgaatatcatggtggaaaatggccgcttttctggattcatcgactgtggccggctgggtgtggcggaccgctatcaggacatagcgttggctacccgtgatattgctgaagagcttggcggcgaatgggctgaccgcttcctcgtgctttacggtatcgccgctcccgattcgcagcgcatcgccttctatcgccttcttgacgagttcttctgagcgggactctggggttcgaaatgaccgaccaagcgacgcccaacctgccatcacgagatttcgattccaccgccgccttctatgaaaggttgggcttcggaatcgttttccgggacgccggctggatgatcctccagcgcggggatctcatgctggagttcttcgcccaccccaacttgtttattgcagcttataatggttacaaataaagcaatagcatcacaaatttcacaaataaagcatttttttcactgcattctagttgtggtttgtccaaactcatcaatgtatcttatcatgtctgtataccgtcgacctctagctagagcttggcgtaatcatggtcatagctgtttcctgtgtgaaattgttatccgctcacaattccacacaacatacgagccggaagcataaagtgtaaagcctggggtgcctaatgagtgagctaactcacattaattgcgttgcgctcactgcccgctttccagtcgggaaacctgtcgtgccagctgcattaatgaatcggccaacgcgcggggagaggcggtttgcgtattgggcgctcttccgcttcctcgctcactgactcgctgcgctcggtcgttcggctgcggcgagcggtatcagctcactcaaaggcggtaatacggttatccacagaatcaggggataacgcaggaaagaacatgtgagcaaaaggccagcaaaaggccaggaaccgtaaaaaggccgcgttgctggcgtttttccataggctccgcccccctgacgagcatcacaaaaatcgacgctcaagtcagaggtggcgaaacccgacaggactataaagataccaggcgtttccccctggaagctccctcgtgcgctctcctgttccgaccctgccgcttaccggatacctgtccgcctttctcccttcgggaagcgtggcgctttctcatagctcacgctgtaggtatctcagttcggtgtaggtcgttcgctccaagctgggctgtgtgcacgaaccccccgttcagcccgaccgctgcgccttatccggtaactatcgtcttgagtccaacccggtaagacacgacttatcgccactggcagcagccactggtaacaggattagcagagcgaggtatgtaggcggtgctacagagttcttgaagtggtggcctaactacggctacactagaagaacagtatttggtatctgcgctctgctgaagccagttaccttcggaaaaagagttggtagctcttgatccggcaaacaaaccaccgctggtagcggtttttttgtttgcaagcagcagattacgcgcagaaaaaaaggatctcaagaagatcctttgatcttttctacggggtctgacgctcagtggaacgaaaactcacgttaagggattttggtcatgagattatcaaaaaggatcttcacctagatccttttaaattaaaaatgaagttttaaatcaatctaaagtatatatgagtaaacttggtctgacagttaccaatgcttaatcagtgaggcacctatctcagcgatctgtctatttcgttcatccatagttgcctgactccccgtcgtgtagataactacgatacgggagggcttaccatctggccccagtgctgcaatgataccgcgagacccacgctcaccggctccagatttatcagcaataaaccagccagccggaagggccgagcgcagaagtggtcctgcaactttatccgcctccatccagtctattaattgttgccgggaagctagagtaagtagttcgccagttaatagtttgcgcaacgttgttgccattgctacaggcatcgtggtgtcacgctcgtcgtttggtatggcttcattcagctccggttcccaacgatcaaggcgagttacatgatcccccatgttgtgcaaaaaagcggttagctccttcggtcctccgatcgttgtcagaagtaagttggccgcagtgttatcactcatggttatggcagcactgcataattctcttactgtcatgccatccgtaagatgcttttctgtgactggtgagtactcaaccaagtcattctgagaatagtgtatgcggcgaccgagttgctcttgcccggcgtcaatacgggataataccgcgccacatagcagaactttaaaagtgctcatcattggaaaacgttcttcggggcgaaaactctcaaggatcttaccgctgttgagatccagttcgatgtaacccactcgtgcacccaactgatcttcagcatcttttactttcaccagcgtttctgggtgagcaaaaacaggaaggcaaaatgccgcaaaaaagggaataagggcgacacggaaatgttgaatactcatactcttcctttttcaatattattgaagcatttatcagggttattgtctcatgagcggatacatatttgaatgtatttagaaaaataaacaaataggggttccgcgcacatttccccgaaaagtgccacctgacgtc(SEQ ID NO:28)
治疗组合物和方法
本发明包括治疗或预防任何病症、紊乱或疾病的方法,通过减少趋化因子受体携带细胞(如CCR2携带细胞;如单核细胞、巨噬细胞和记忆T淋巴细胞)迁移至炎症组织内、降低内源性趋化因子(如MCP1)表达或相关活性(如CCR2受体结合)或者通过降低趋化因子受体(如CCR2)的表达或活性可治疗所述病症、紊乱或疾病。在本发明的实施方案中,通过将配体全身性给予受试者,使受试者的趋化因子受体(如CCR2)携带细胞对同源趋化因子配体(如MCP1)的存在脱敏,治疗炎性疾病。在本发明的实施方案中,可延长给予趋化因子配体的时间,以便达到在细胞中完全脱敏的水平。例如,本发明包括治疗或预防受试者炎性疾病的方法,给予受试者治疗有效量的趋化因子或其多聚体或融合物,如MCP1、MCP1多聚体或其融合物(如与体内半衰期延长部分(如PEG或Ig)融合)或其药用组合物(如包含药学上可接受的载体),任选与其联合的是治疗有效量的其它治疗剂。
本发明的药用组合物可用制药领域熟知的任何方法制备。参阅如Gilman等,(编辑)(1990),The Pharmacological Bases of Therapeutics(治 疗药理学基础),第8版,Pergamon Press;A.Gennaro(编辑),Remington’s Pharmaceutical Sciences,第18版,(1990),Mack PublishingCo.,Easton,Pennsylvania.;Avis等,(编辑)(1993)Pharmaceutical Dosage Forms:Parenteral Medications(药物剂型:胃肠外药物)Dekker,New York;Lieberman等,(编辑)(1990)Pharmaceutical Dosage Forms: Tablets(药物剂型:片剂)Dekker,New York;和Lieberman等,(编辑)(1990),Pharmaceutical Dosage Forms:Disperse Systems(药物剂型:分 散系统)Dekker,New York。
在本发明的实施方案中,术语“炎性疾病”或“医学炎性疾病”包括银屑病(如指甲银屑病、头皮银屑病、斑块型银屑病、脓疱型银屑病、点滴型银屑病、反相银屑病、红皮病型关节炎或银屑病性关节炎)、强直性脊柱炎、阑尾炎、消化性溃疡、胃溃疡和十二指肠溃疡、腹膜炎、胰腺炎、炎性肠病、结肠炎、溃疡性结肠炎、伪膜性肠炎、急性结肠炎、缺血性结肠炎、憩室炎、会厌炎、失弛缓症、胆管炎、胆囊炎、腹部疾病、肝炎、克罗恩病(如回结肠炎、回肠炎、胃十二指肠克罗恩病、空肠回肠炎或克罗恩(肉芽肿)结肠炎)、肠炎、惠普尔病、哮喘、过敏、过敏性休克、免疫复合物病、器官缺血、再灌注损伤、器官坏死、花粉热、脓毒症、败血症、内毒素性休克、恶病质、高热、嗜酸细胞性肉芽肿、肉芽肿病、肉状瘤病、脓毒性流产、附睾炎、阴道炎、前列腺炎和尿道炎、支气管炎、肺气肿、鼻炎、囊性纤维化、肺炎、成人呼吸窘迫综合征、黑肺病、肺泡炎、细支气管炎、咽炎、胸膜炎、鼻窦炎、皮炎、特应性皮炎、皮肌炎、晒伤、风疹疣、风疹块、狭窄、再狭窄、血管炎、脉管炎、心内膜炎、动脉炎、动脉粥样硬化、血栓性静脉炎、心包炎、心肌炎、心肌缺血、结节性多动脉炎、风湿热、脑膜炎、脑炎、多发性硬化、神经炎、神经痛、葡萄膜炎(如前型、后型、中间型或弥散型)、关节炎和关节痛、骨髓炎、筋膜炎、佩吉特病、痛风、牙周病、类风湿性关节炎(如多关节过程的青少年类风湿性关节炎或银屑病关节炎)、滑膜炎、重症肌无力、甲状腺炎、系统性红斑狼疮、肺出血-肾炎综合征、白塞综合征、同种异体移植物排斥或移植物抗宿主病。
本发明还包括治疗或预防受试者寄生虫、病毒或细菌感染的方法,给予受试者治疗有效量的趋化因子、多聚体或其融合物,如MCP1、MCP1多聚体或其融合物(如与体内半衰期延长部分(如PEG或Ig)融合)或其药用组合物(如包含药学上可接受的载体),任选与其联合的是治疗有效量的其它治疗剂。在本发明的实施方案中,感染是单纯疱疹病毒感染(如HSV1或HSV2)、人嗜T淋巴细胞病毒(HTLV;如I型)感染、HIV感染、HIV神经病变、脑膜炎、肝炎(A、B或C等)、脓毒性关节炎、腹膜炎、肺炎、会厌炎、大肠杆菌(E.coli)0157:h7)、溶血性尿毒症综合征、血栓性血小板减少性紫癜、疟疾、登革出血热、利什曼病、麻风病、中毒性休克综合征、链球菌性肌炎、气性坏疽、结核分枝杆菌、鸟胞内分枝杆菌、卡氏肺囊虫肺炎、骨盆炎性疾病、睾丸炎、epidydimitis、军团菌病、莱姆病、A型流感、EB病毒、致命性嗜血细胞综合征、致命性脑炎或无菌性脑膜炎。
本发明还包括治疗或预防受试者癌症或恶性肿瘤(如乳腺癌、卵巢癌、胃癌、子宫内膜癌、唾液腺癌、肺癌、肾癌、结肠癌、结肠直肠癌、甲状腺癌、胰腺癌、前列腺癌或膀胱癌)的方法,给予受试者治疗有效量的趋化因子、多聚体或其融合物,如MCP1、MCP1多聚体或其融合物(如与体内半衰期延长部分(如PEG或Ig)融合)或其药用组合物(如包含药学上可接受的载体),任选与其联合的是治疗有效量的其它治疗剂。
本发明还包括治疗或预防受试者任何心血管或循环系统疾病的方法,给予受试者治疗有效量的趋化因子、多聚体或其融合物,如MCP1、MCP1多聚体或其融合物(如与体内半衰期延长部分(如PEG或Ig)融合)或其药用组合物(如包含药学上可接受的载体),任选与其联合的是治疗有效量的其它治疗剂。在本发明的实施方案中,所述疾病或病症是心脏顿抑综合征、心肌梗死、充血性心力衰竭、中风、缺血性中风、出血、动脉硬化、动脉粥样硬化、再狭窄、糖尿病动脉硬化性疾病、高血压、动脉性高血压、肾血管性高血压、晕厥、休克、心血管系统梅毒、心力衰竭、肺心病、原发性肺动脉高压、心律失常、心房异位搏动、房扑、房颤(持续或阵发性)、灌注后综合征、心肺分流术炎症反应、紊乱性或多源性房性心动过速、规则的窄QRS心动过速、特殊心律失常、室颤、His束心律失常、房室传导阻滞、束支传导阻滞、心肌缺血性疾病、冠心病、心绞痛、心肌梗死、心肌病、扩张型充血性心肌病、限制性心肌病、心脏瓣膜病、心内膜炎、心包疾病、心脏肿瘤、主动脉和外周动脉瘤、主动脉夹层、大动脉炎症、腹主动脉及其分支闭塞、外周血管疾病、闭塞性动脉疾病、外周动脉硬化性疾病、闭塞性血栓性脉管炎、功能性外周动脉疾病、雷诺氏现象和疾病、手足发绀、红斑性肢痛病、静脉疾病、静脉血栓形成、静脉曲张、动静脉瘘、淋巴水肿、脂肪水肿、不稳定心绞痛、再灌注损伤、泵后综合征和缺血性再灌注损伤。
包含趋化因子、其多聚体或融合物如MCP1或其多聚体或融合物(如MCP1-Ig)的药用组合物可用常规药学上可接受的赋形剂和添加剂与常规方法制备。此类药学上可接受的赋形剂和添加剂包括非毒性可相容的填充剂、粘合剂、崩解剂、缓冲剂、防腐剂、抗氧化剂、润滑剂、调味剂、增稠剂、着色剂、乳化剂等。涉及所有给药途径,包括但不限于胃肠外(如皮下、静脉内、腹膜内、瘤内或肌内)和非胃肠外(如口服、经皮、鼻内、眼内、舌下、吸入、直肠和体表)。
可将注射剂制备成常规形式,如液体溶液或混悬液、适合在注射前成为液体溶液或混悬液的固体形式,或者作为乳液。注射液、溶液和乳液还可包含一种或多种赋形剂。合适的赋形剂是例如水、盐水、右旋糖、甘油或乙醇。此外,如果需要,给予的药用组合物还可包含少量非毒性辅助物质如湿润剂或乳化剂、pH缓冲剂、稳定剂、增溶剂及其它此类物质如乙酸钠、单月桂酸脱水山梨醇酯、油酸三乙醇胺酯和环糊精。
用于胃肠外制剂的药学上可接受的载体包括水性溶媒、非水性溶媒、抗微生物剂、等渗剂、缓冲剂、抗氧化剂、局麻药、悬浮剂和分散剂、乳化剂、掩蔽剂(sequestering)或螯合剂及其它药学上可接受的物质。
水性溶媒的实例包括氯化钠注射液、林格氏注射液、等渗右旋糖注射液、无菌水注射液、右旋糖和乳酸盐林格氏注射液。非水性胃肠外溶媒包括蔬菜来源的不挥发油、棉籽油、玉米油、芝麻油和花生油。通常将抑制细菌或抑制真菌浓度的抗微生物剂加入包装在多剂量容器中的胃肠外制剂内,所述抗微生物剂包括苯酚或甲酚、汞制剂、苯甲醇、三氯叔丁醇、对羟苯甲酸甲酯和对羟苯甲酸丙酯、柳硫汞、苯扎氯铵和苄索氯铵。等渗剂包括氯化钠和右旋糖。缓冲剂包括磷酸盐和枸橼酸盐。抗氧化剂包括硫酸氢钠。局麻药包括盐酸普鲁卡因。悬浮剂和分散剂包括羧甲基纤维素钠、羟丙基甲基纤维素和聚乙烯吡咯烷酮。乳化剂包括聚山梨醇酯80(TWEEN-80)。金属离子的隐蔽剂或螯合剂包括EDTA。药用载体还包括乙醇、聚乙二醇和丙二醇,用作水混溶性溶媒;和氢氧化钠、盐酸、枸橼酸或乳酸,用于调节pH。
胃肠外给药的制剂可包括准备注射的无菌溶液、准备在使用前与溶剂合并的无菌干燥可溶性制品如冻干粉剂(包括皮下注射用片)、准备注射的无菌混悬液、准备在使用前即时与溶媒合并的无菌干燥不溶性制品以及无菌乳液。溶液可以是水性或非水性。
本文还涉及植入延缓释放或持续释放系统,以便维持恒定的剂量水平。简言之,在该实施方案中,使趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体(如MCP1-Ig)分散在固体内部基质中,所述基质如聚甲基丙烯酸甲酯、聚甲基丙烯酸丁酯、增塑或未增塑的聚氯乙烯、增塑尼龙、增塑聚对苯二甲酸乙酯、天然橡胶、聚异戊二烯、聚异丁烯、聚丁二烯、聚乙烯、乙烯-乙酸乙烯酯共聚物、硅酮橡胶、聚二甲基硅氧烷、碳酸硅酮共聚物、亲水聚合物如丙烯酸和甲基丙烯酸酯的水凝胶、胶原、交联聚乙烯醇和交联部分水解的聚乙酸乙烯酯,被包围在不溶于体液的外聚合物膜中,所述外聚合物膜为如聚乙烯、聚丙烯、乙烯/丙烯共聚物、乙烯/丙烯酸乙酯共聚物、乙烯/乙酸乙烯酯共聚物、硅酮橡胶、聚二甲基硅氧烷、氯丁橡胶、氯化聚乙烯、聚氯乙烯、与乙酸乙烯酯的氯乙烯共聚物、偏二氯乙烯、乙烯和丙烯、离子聚合物聚对苯二酸乙烯酯、丁基橡胶、氯醇橡胶、乙烯/乙烯醇共聚物、乙烯/乙酸乙烯酯/乙烯醇三聚物和乙烯/乙烯氧基乙醇共聚物。在释放率控制步骤中,活性成分通过外聚合物膜弥散。此类胃肠外组合物包含的活性化合物的百分数高度取决于其具体特性,以及趋化因子或其多聚体或融合物如MCP1或其融合物或多聚体的活性以及受试者的需要。
可调节趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体的浓度以便注射的有效量可产生所需药理学作用。精确剂量特别取决于如本领域已知的患者或动物的年龄、体重和疾病。
将包含趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体的单位剂量胃肠外制剂包装在安瓿、小瓶或带针头的注射器内。如本领域已知和实施,所有胃肠外给药的制剂都必须无菌。此类制剂形成本发明的一部分。
可将趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体配制成可复原为溶液、乳液及其它混合物给药的冻干粉剂。还可将粉剂复原和配制为固体或凝胶。
通过使趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体或其药学上可接受的衍生物溶于合适溶剂中,制备无菌、冻干粉剂。所述溶剂可包括改善稳定性的赋形剂或者另一种粉剂或用粉剂制备的复原溶液的药学组分。可使用的赋形剂包括但不限于右旋糖、脱水山梨醇、果糖、玉米糖浆、木糖醇、甘油、葡萄糖、蔗糖或其它合适赋形剂。所述溶剂还可包含缓冲剂如枸橼酸盐、磷酸钠或磷酸钾或本领域技术人员已知的其它此类缓冲剂,在一个实施方案中,约为中性pH。接着在本领域技术人员已知的标准条件下先后将溶液无菌过滤和冻干,得到所需制剂。在一个实施方案中,将所得溶液分配在小瓶内低压冻干。每个瓶可容纳单剂量或多剂量的趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体。可将冻干粉剂贮存在适当条件下,如约4℃至室温。
用注射用水将冻干粉剂重新配制,得到用于胃肠外给药的制剂。重新配制时,可将冻干粉剂加入无菌水或另一种合适载体中。精确的量取决于所选化合物。这样的量可按照经验确定。
通过用如与三氯氟甲烷、二氯氟甲烷、二氯四氟乙烷或任何其它生物学相容性推进气体一起的如含三油酸脱水山梨醇酯或油酸的气雾剂,可吸入给药;还可以用包含趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体本身或与赋形剂联合的粉剂形式系统。
在实施方案中,将趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体配制为口服给药的固体剂型,在一个实施方案中,配制为胶囊剂或片剂。片剂、丸剂、胶囊剂、锭剂等可包含一种或多种下列成分或性质相似的化合物:粘合剂、润滑剂、稀释剂、助流剂、崩解剂、着色剂、甜味剂、调味剂、湿润剂、催吐包衣和薄膜包衣。粘合剂实例包括微晶纤维素、西黄蓍胶、葡萄糖溶液、阿拉伯胶浆、明胶溶液、糖蜜、聚乙烯吡咯烷酮、聚维酮、交聚维酮、蔗糖和淀粉糊。润滑剂包括滑石、淀粉、硬脂酸镁或硬脂酸钙、石松和硬脂酸。稀释剂包括例如乳糖、蔗糖、淀粉、高岭土、盐、甘露醇和磷酸二钙。助流剂包括但不限于胶体二氧化硅。崩解剂包括交联羧甲基纤维素钠、羧甲基淀粉钠、海藻酸、玉米淀粉、马铃薯淀粉、膨润土、甲基纤维素、琼脂和羧甲基纤维素。着色剂包括例如任何得到批准认证的水溶性FD和C染料、其混合物;和悬浮在氢氧化铝上的水不溶性FD和C染料。甜味剂包括蔗糖、乳糖、甘露醇和人造甜味剂如糖精和任何数量的喷雾干燥香料。调味剂包括提取自植物如水果的天然调味剂和产生令人愉快的感觉的合成化合物混合物(例如但不限于薄荷和水杨酸甲酯)。湿润剂包括单硬脂酸丙二醇酯、单油酸脱水山梨醇酯、单月桂酸二甘醇酯和聚氧乙烯月桂醚。催吐包衣包括脂肪酸、脂肪、蜡、虫胶、含铵虫胶和邻苯二甲酸乙酸纤维素。薄膜包衣包括羟乙基纤维素、羧甲基纤维素钠、聚乙二醇4000和邻苯二甲酸乙酸纤维素。
本发明范围包括给药方法,所述方法包括给予与例如一种或多种其它治疗剂联合的趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体或其药用组合物,以及包含与其它治疗剂联合的趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体的组合物。在实施方案中,其它治疗剂是给予受试者后治疗或预防受试者炎性疾病的药物。任何此类药物的给药和剂量通常根据核准药物的产品信息表列出的方案确定,参阅Physicians′Desk Reference 2003(Physicians′Desk Reference,第57版);Medical Economics Company;ISBN:1563634457;第57版(2002年11月)以及本领域熟知的治疗方案。
术语“联合”表示可将趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体和其它治疗剂配制为单纯组合物同时递送或者单独配制为两种或多种组合物(如药剂盒)。而且,可在不同于其它组分的给药时间将各组分给予受试者;例如,可在给定时间段内以几种间隔非同时(如单独或按顺序)进行每次给药。而且,可以相同或不同途径(如口服、静脉内、皮下)将单独组分给予受试者。
“其它治疗剂”是给予受试者时,产生所需或有益的治疗作用,如预防、消除或减少与指定疾病(如炎性疾病)有关的症状进展或严重度的除了趋化因子、多聚体或其融合物之外的任何药物。其它治疗剂可以是例如抗炎剂或镇痛剂。
可与趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体联合给药或合并的其它治疗剂包括一种或多种非甾体抗炎药(NSAID)如阿司匹林、双氯芬酸、二氟尼柳、依托度酸、非诺洛芬、夫洛非宁、氟比洛芬、布洛芬、吲哚美辛、酮洛芬、酮咯酸、甲氯芬那酸、甲芬那酸、美洛昔康、萘丁美酮、萘普生、噁丙嗪、保泰松、吡罗昔康、双水杨酸酯、舒林酸、替诺昔康、噻洛芬酸或托美丁。
可与趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体联合给药或合并的其它治疗剂包括一种或多种外用药,如蒽林、卡泊三烯、水杨酸、煤焦油、他扎罗汀、表面类固醇(如丙酸氯倍他索、丙酸氯倍他索、二丙酸倍他米松、丙酸氯倍他索、二乙酸二氟拉松、丙酸氯倍他索、丙酸卤贝他索、安西奈德、二丙酸倍他米松、二丙酸倍他米松、糠酸莫米松、二乙酸二氟拉松、哈西奈德、氟轻松、二乙酸二氟拉松、二丙酸倍他米松、二乙酸二氟拉松、去羟米松、去羟米松、曲安奈德、丙酸氟替卡松、安西奈德、二丙酸倍他米松、二乙酸二氟拉松、氟轻松、戊酸倍他米松、二乙酸二氟拉松、二丙酸倍他米松、去羟米松、戊酸倍他米松、曲安奈德、氟羟可舒松、氟轻松、糠酸莫米松、曲安奈德、氟轻松、苯甲酸倍他米松、戊酸氢化可的松、氟羟可舒松、丙酸氟替卡松、泼尼卡酯、地奈德、二丙酸倍他米松、曲安奈德、氢化可的松、氟轻松、苯甲酸倍他米松、戊酸倍他米松、戊酸氢化可的松、二丙酸阿氯米松、地奈德、氟轻松、地奈德、戊酸倍他米松、或者氢化可的松、地塞米松、甲基泼尼松龙和泼尼松龙的混合物)、凡士林、芦荟、油状麦片、泻盐或死海盐。
可与趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体联合给药或合并的其它治疗剂包括一种或多种alefacept、依那西普、环孢菌素、甲氨蝶呤、阿曲汀、异维甲酸、羟基脲、霉酚酸酯、柳氮磺吡啶或6-硫鸟嘌呤。
可与趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体联合给药或合并的其它治疗剂包括一种或多种阿那白滞素、注射金、青霉胺、硫唑嘌呤、氯喹、羟基氯喹、柳氮磺吡啶或口服金(如金诺芬、硫代苹果酸金钠或金硫葡糖)。
可与趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体联合给药或合并的其它治疗剂包括一种或多种美沙拉嗪、柳氮磺吡啶、布地奈德、甲硝唑、环丙沙星、硫唑嘌呤、6-巯基嘌呤或膳食补充剂钙、叶酸盐或维生素B12。
可与趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体联合给药或合并的其它治疗剂包括一种或多种COX2抑制剂如塞来考昔 罗非考昔伐地考昔
罗非考昔伐地考昔 罗美昔布(PrexigeTM)或艾托考昔
罗美昔布(PrexigeTM)或艾托考昔
可与趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体联合给药或合并的其它治疗剂包括一种或多种抗体如依法利珠单抗 阿达木单抗
阿达木单抗 英夫利昔单抗
英夫利昔单抗 或ABX-IL8。
或ABX-IL8。
在本发明的实施方案中,将趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体与光疗联合给予受试者特别是患银屑病的受试者。在此类实施方案中,使受试者暴露于日光、UVB光、PUVA(补骨脂素加紫外线A)、PUVA(补骨脂素-UVA)或激光。PUVA用紫外线A光联合补骨脂素治疗银屑病,补骨脂素是使皮肤对光线更敏感的口服或外用药物。激光发出高度聚焦的光束,主要影响银屑病皮肤,但不明显暴露健康皮肤。一种激光类型XTRAC准分子激光使用高度聚焦的紫外线B光。另一种用于银屑病的激光类型是脉冲染料激光,用黄光脉冲--与UVB或XTRAC使用的紫外线不同--破坏银屑病斑中生长的一些血液细胞。用脉冲染料激光治疗通常需要几个月,每三周安排一次。
剂量和给药
本发明组合物治疗性给药的经典方案在本领域众所周知。例如可以通过任何胃肠外(如皮下注射、肌内注射、静脉内注射)或非胃肠外途径(如口服、经鼻)给予本发明的药用组合物。
可口服给予本发明的丸剂和胶囊剂。可将注射组合物用本领域已知的医疗设备给药;例如用皮下注射针注射。
也可将本发明的注射药用组合物用无针头的皮下注射设备给药;如公开于美国专利号5,399,163、5,383,851、5,312,335、5,064,413、4,941,880、4,790,824或4,596,556的设备。
在实施方案中,如果可能,根据Physicians′Desk Reference 2003(Physicians′Desk Reference,第57版);Medical Economics Company;ISBN:1563634457;第57版(November 2002)给予与趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体联合给药的“其它治疗剂”(如抗炎剂)的日剂量。但是,临床医生可改变适当剂量以补偿接受治疗受试者的具体特征,例如根据所给予化合物或趋化因子、多聚体或其融合物(如MCP1-Ig)的功效、副作用、年龄、体重、疾病、一般健康状态和反应。
本发明提供治疗或预防受试者炎性疾病的方法,给予受试者治疗有效量的趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体,与其任选联合的是治疗有效量的其它治疗剂。术语“治疗有效量”指引起组织、系统、受试者或宿主的生物学或医学反应的治疗剂或物质(如MCP1-Ig)的量,所述反应为给药者(如研究者、医生或兽医)所寻求,包括例如目标疾病或其任何症状任何程度(包括在受试者中预防疾病)的缓解、逆转、消除或终止或减缓进展。在本发明的实施方案中,趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体(如MCP1-Ig;如包含SEQ ID NO:8、9、10、11或12列出的任何氨基酸序列的多肽)的治疗有效量或剂量为约0.1mpk(mg每公斤体重)-约10mpk(如0.25、0.5、0.75、1、2、3、4、5、6、7、8、9、10mpk),每天、每2天、每4天或每5天1次或每周1次。
例如,可以每天3次、每天2次、每天1次、每周3次、每周2次或每周1次、每2周或每3、4、5、6、7或8周1次给予本发明组合物。而且,可用更短或更长时间(如1周、1月、1年、5年)给予组合物。
可调节剂量方案以优化所需反应(如治疗反应)。例如,可根据治疗情况的紧迫性减少或增加剂量。例如,可根据药物功效、疾病进展或持续性或其任何症状或者患者年龄、体重、身高、既往病史、现用药物和交叉反应的可能性、过敏反应、敏感性和不良反应,由本领域技术人员(如医生或兽医)调节剂量。
具有本领域普通技能的医生或兽医很容易确定和给出有效量所需药用组合物的处方。例如,医生或兽医可将趋化因子、多聚体或其融合物如MCP1或其融合物或多聚体或其药用组合物的起始剂量定在低于获得所需治疗作用需要的水平,逐渐增加剂量直至获得所需作用。
例如,医生或兽医可通过多种方法监测银屑病进展,从而可改变给药方案。监测银屑病的方法包括例如皮肤活检或刮除和培养皮肤斑块,监测受试者皮肤上病变的扩散情况,或者用X-线检查银屑病关节炎(如果出现关节疼痛并持续存在)。
例如,医生或兽医可通过多种方法监测类风湿性关节炎进展,从而可改变给药方案。监测类风湿性关节炎的方法包括例如关节X-线、检测血液类风湿因子、检测提高的红细胞沉降率(ESR)、全血细胞计数以检测低红细胞压积(贫血)或异常血小板计数、验血以检测C-反应蛋白或滑膜液分析。
例如,医生或兽医可通过多种方法监测克罗恩病进展,从而可改变给药方案。监测克罗恩病的方法包括例如监测受试者或患者报道症状的严重度、乙状结肠镜检查、结肠镜检查、ERCP(内窥镜逆行胰胆管造影)、超声内镜、囊内窥镜、X-线平片、X-线造影片、CT扫描或白细胞扫描。
例如,医生或兽医可通过多种方法监测葡萄膜炎进展,从而可改变给药方案。监测葡萄膜炎的方法包括例如用裂隙灯显微镜和眼底镜检查眼部、检查视力和眼内压。
例如,医生或兽医可通过多种方法监测溃疡性结肠炎进展,从而可改变给药方案。监测溃疡性结肠炎的方法包括例如常规检查、结肠镜检查、直肠或结肠活检、粪便检测潜血或脓液、验血以检查白细胞水平或X-线检查。
实施例
提供下列实施例以更清楚地描述本发明,不应视为限制本发明的范围。在实施例部分公开的任何方法或组合物构成本发明的一部分。
实施例1:人MCP1-小鼠Ig重链γ1(铰链-CH2-CH3)融合物的设计、构建、表达和纯化
构建体的设计
hMCP1-mIg(NH2-人MCP1-小鼠Ig重链γ1(铰链-CH2-CH3)-COOH):将BamH1位点作为接头引入cDNA,在MCP1与IgH链接合处插入二肽Gly-Ser。预期产物形成预测分子量为68,993的二聚体。
hMCP1-hIgG4(NH2-人MCP1-人IgH链γ4(铰链-CH2-CH3)-COOH):将BamH1位点作为接头引入cDNA,在MCP1与IgH链接合处插入二肽Gly-Ser。预期产物形成预测分子量为69,146的二聚体。
hMCP1-hIgG4单体变异体(NH2-人MCP1-人Ig重链γ4(铰链-CH2-CH3)-COOH):两个半胱氨酸残基被丝氨酸残基代替以消除分子内二硫键。将BamH1位点作为接头引入cDNA,在MCP1与IgH链接合处插入二肽Gly-Ser。预期产物形成预测分子量为34,543的二聚体。
hMCP1-hIgG1(NH2-人MCP1-人IgH链γ1(铰链-CH2-CH3)-COOH):将BamH1位点作为接头引入cDNA,在MCP1与IgH链接合处插入二肽Gly-Ser。预期产物形成预测分子量为70,000的二聚体。
hMCP1-hIgG1单体变异体(NH2-人MCP1-人Ig重链γ1(铰链-CH2-CH3)-COOH):三个半胱氨酸残基被丝氨酸残基代替以消除分子内二硫键。将BamH1位点作为接头引入cDNA,在MCP1与IgH链接合处插入二肽Gly-Ser。预期产物形成预测分子量为34,955的二聚体。
表达和纯化。在本实施例中,使MCP1-Ig在哺乳动物细胞中表达和分泌,然后从细胞生长培养基分离。用SDS-PAGE分析分析分离的蛋白质。
通过逆转录聚合酶链式反应(RT-PCR)克隆人MCP1的cDNA(参阅基因库检索号NM_002982)和来自小鼠Ig恒定区的部分cDNA(参阅基因库检索号BC057688)(包括铰链、CH2和CH3区的编码序列)。通过标准分子生物学操作使MCP1-Ig cDNA作为Hind3-Not1片段克隆入哺乳动物表达载体pCDNA3.1(+)(Invitrogen,Carlsbad,CA)内,得到pcDNA3.1(+)hMCP1mIgG质粒。
使CHO-K1(ATCC CRL-9618)细胞保持在补充5%胎牛血清的D-MEM/F-12培养基(Invitrogen,Carlsbad,CA)中。按照制造商提出的方案用Lipofectamine 2000转染试剂盒(Invitrogen,Carlsbad,CA)将质粒DNA导入CHO-K1细胞内。在转染后48小时,将G418(Invitrogen)以1mg/ml加入培养基内,选择稳定转染的细胞。在转染后约10-14天,出现耐G418细胞的菌落。然后将细胞收集,以每孔3个细胞、每孔1个细胞和每孔0.3个细胞的频率通过有限稀释在96孔组织培养板内转染。在约7-10天出现单细胞衍生的克隆,用小鼠IgG1(Bethyl,Montgomery,TX)特异性酶联免疫吸附测定(ELISA)检测条件培养基。通过将产率标化为细胞数再次检测最高滴度克隆的表达水平。选择每升产生大于40mg的克隆制备(克隆52)。
在无血清条件下制备hMCP1-mIg蛋白质。使克隆52细胞逐渐戒除血清(weaned)适应由IS-CHO V基础培养基(Irvine Scientific,Irvine,CA)组成的无蛋白质培养基的混悬培养液。每升无蛋白质培养基包含8mM谷氨酰胺(Invitrogen,Gaithersburg,MD)、10ml 100×HT(Invitrogen)、1ml CD-脂质(Invitrogen)、8ml 45%葡萄糖(Sigma,St.Louis,MO)、20ml GSEM(Sigma)、各1ml痕量元素A(Trace ElementA)和痕量元素B(Trace Element B)(Cellgro,Herndon,VA)。制备时,将1升体积细胞以0.5×106/ml密度接种在3升振荡烧瓶内。在7.5%CO2存在下,使烧瓶在37℃恒温以75rpm速度振荡。使谷氨酰胺浓度保持在约300毫克/升,葡萄糖浓度保持在1-2克/升。大约第14天收集条件培养基,这时细胞活力为约20%。使条件培养基通过2-微米过滤单元过滤,然后根据制造商提出的方案用Affi-凝胶蛋白-A亲和柱(BioRad,Hercules,CA)处理。在还原条件下用SDS-聚丙烯酰胺凝胶电泳(SDS-PAGE)分析纯化的蛋白质。用SimplyBlue SafeStain(Invitrogen)将凝胶染色后观察到单一条带,估计大小为约34千道尔顿。估计该产物的纯度大于99%。
实施例2:细胞迁移测定
在本实施例中,证明人MCP1-mIg的存在可阻碍THP-1人单核细胞沿重组人MCP1梯度迁移的能力。
使THP-1细胞(ATCC TIB202)保持在补充10%胎牛血清、1mM丙酮酸钠、4.5g/升葡萄糖、1.5g/l碳酸氢钠、10mM HEPES、0.05mMβ-巯基乙醇和青霉素/链霉素的RPMI1640中。按照制造商说明书用具有5μm滤器的96孔ChemoTx微量板(NeuroProbe,Gathersburg,MD)进行细胞迁移测定。将重组人MCP1(rhMCP1)(R & D Systems,Minneapolis,MN)置于底室。将hMCP1-mIg或同种型对照IgG置于顶室和底室。使细胞分配在顶孔中。将微量板置于37℃增湿CO2(5%)培养箱中2小时,让细胞向底室的人MCP1迁移。按照制造商方案通过CellTiter-Glo Luminiscent Cell Viability Assay Kit(Promega,Madison,WI)将细胞迁移定量为相对发光单位(RLU)。用趋化因子试剂存在下的迁移RLU减去自发迁移RLU计算细胞迁移。用最高细胞迁移数作为100%计算相对迁移%。
hMCP1-mIg和rhMCP1的近似EC50值分别为约0.5nM和0.05nM(表1,左和中列)。3nM的hMCP1-mIg明显降低THP-1细胞沿rhMCP1梯度迁移的能力(表1,右列)。
表1.hMCP1-mIg和重组人MCP1(rhMCP1)对THP-1人单核细胞迁移的作用。
细胞迁移相对%
浓度(nM)单独hMCP1-mIg单独rhMCP1 3nM rhMCP1+hMCP1-mIg


实施例3:胶原诱发的关节炎测定
用II型牛胶原(BCII)(Elastin Products,Owensville,MO)、Difco不完全弗氏佐剂和结核分支杆菌(MBT,H37RA株,Sigma,St.Louis,MO)使12-13周龄雄性B10.RIII小鼠免疫。在4℃使BCII溶于0.01M乙酸(60mg BCII在25ml 0.01M乙酸中)中过夜。使结核分枝杆菌与Difco不完全弗氏佐剂(1mg/ml)混合制备完全弗氏佐剂(CFA)。然后使1体积BCII和1体积CFA混合乳化。所述乳液包含1200μg/ml BCII和0.5mg/ml结核分支杆菌。
在小鼠背部5个位点(包括尾基部的1个位点)皮内注射使其免疫。每只小鼠接受总体积为0.25ml的乳液,相当于300μg BCII/只小鼠。
在免疫后16天对小鼠关节炎的症状和严重度进行评分,分成15组,以便每组具有相同数目的关节炎小鼠。按照以下0-4级进行评分:
0=正常
1=发红
2=一个或多个足趾肿胀
3=全爪肿胀
4=关节强直
加强免疫前4天和第0、2、4、7和9天进行评分。在这几天还通过测径器测量评估肿胀程度。
还加强免疫接种:使BCII在0.01M乙酸(12.5mg BCII在25ml0.01M乙酸中)中溶解过夜。在免疫后20天(加强免疫接种第0天)用100μg BCII/0.2ml/只小鼠腹膜内注射对小鼠加强免疫。
在磷酸盐缓冲液中制备2mg/ml hMCP1-mIg(SEQ ID NO:8)和mIgG1(TC31-27F11,SP-BioPharma,Palo Alto,CA),在指定时间点腹膜内给予小鼠。首次剂量为20毫克每公斤体重(mpk)。后续剂量为10mpk。
在结束时采集血清样品测定抗胶原抗体(IgG2a)。
表2的平均疾病评分和表3的足爪肿胀值表明在hMCP1-mIg处理组小鼠观察到的保护作用。
用ELISA测定抗胶原IgG2a的血浆水平。在4℃将测定板用ELISA级II型牛胶原(Chondrex,Redmond,WA)以50μl/ml包被过夜。将板用PBS洗涤,然后在4℃用1% BSA封闭过夜。简单洗涤后,将样品以1:10,000稀释,与以40pg/ml开始2倍连续稀释的标准品(USBiologicals,Swampscott,MA)一起置于板上。将板在4℃培养过夜。洗涤后,将100μl过氧化物酶缀合的抗IgG(Abcam,Cambridge,MA)(1:500稀释)加入各孔内,在室温下培养2小时。将板洗涤,将100μlTMB(Sigma)加入各孔内。在490nM读板。
在hMCP1-mIg处理的动物中,与同种型对照(mIgG1)处理的动物相比,抗胶原IgG2a抗体的水平受到抑制(表4)。
表2.小鼠胶原关节炎的关节炎评分(均数±SEM)。
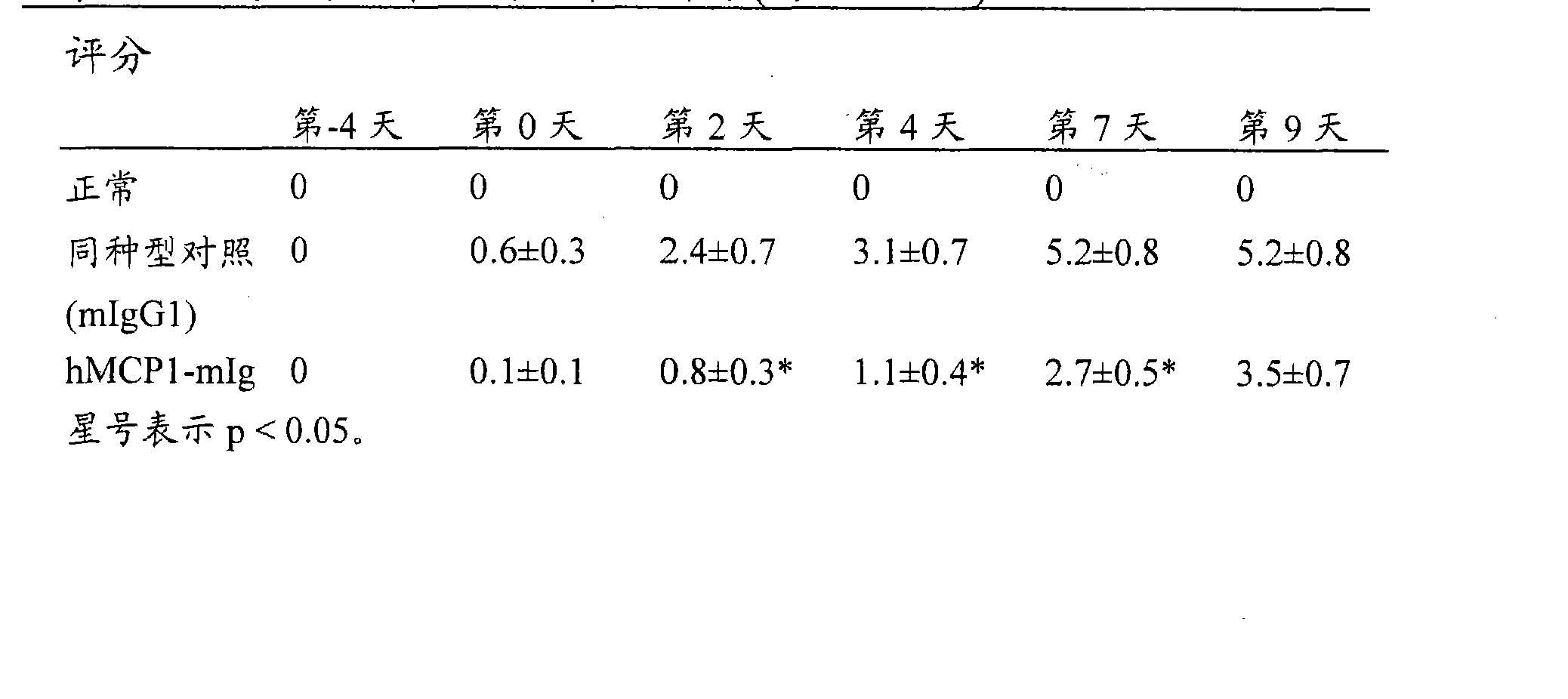
表3.小鼠胶原关节炎的足爪肿胀程度(均数±SEM)。
足爪肿胀程度(mm)

星号表示hMCP1-mIg处理组与同种型对照组的足爪大小相比p<0.05。
表4.在第9天抗胶原IgG2a的血浆水平。

数据用均数和标准误差表示。
实施例4:受体结合测定
在本实施例中,测定hMCP1(R & D Systems)和hMCP1-mIg(SEQID NO:8)与CCR2受体结合的能力。
用来自公开序列的寡核苷酸序列通过RT-PCR,用人外周血单核细胞产生全长人CCR2 cDNA(基因库检索号NM_000648)。还用来自公开序列的寡核苷酸序列通过RT-PCR,用小鼠脾细胞产生全长小鼠CCR2 cDNA(基因库检索号NM_009915)。
使鼠类IL-3依赖性前B细胞Ba/F3保持在补充10%胎牛血清、2mM L-谷氨酰胺、100μg/ml链霉素和100ug/ml青霉素、50μM2-巯基乙醇和2μg/ml重组小鼠IL-3(Biosource International,Camarillo,CA)的RPMI 1640培养基(Invitrogen,Gaithersburg,MD)中。按照Chou等描述于British J.Pharmacology 137:663(2002)的电穿孔方案,通过用pME18Sneo-hCCR2或mCCR2质粒稳定地转染Ba/F3小鼠前B细胞,建立表达人CCR2和小鼠CCR2的重组Ba/F3细胞。在1mg/ml遗传霉素(Invitrogen)的存在下选择稳定的转染体。
按照先前Chou等,2002的描述制备细胞膜。简言之,使细胞沉淀,再悬浮于细胞溶解缓冲液(10mMHEPES,pH 7.5)和 蛋白酶抑制剂(Boehringer Mannheim,Indianapolis,IN)中,在冰上孵育5分钟。将细胞转移至4639细胞破碎仪(Parr Instrument,Moline,IL)中,在冰上用1500psi氮破碎30分钟。以500g离心5分钟除去大分子碎片,然后以100,000g离心30分钟使上清液中的细胞膜沉积。使膜再悬浮于含10%蔗糖的细胞溶解缓冲液中,贮存在-80℃。放射性标记的人MCP1(比活性=2200Ci/mmol)购自Perkin-Elmer(Boston,MA)。
蛋白酶抑制剂(Boehringer Mannheim,Indianapolis,IN)中,在冰上孵育5分钟。将细胞转移至4639细胞破碎仪(Parr Instrument,Moline,IL)中,在冰上用1500psi氮破碎30分钟。以500g离心5分钟除去大分子碎片,然后以100,000g离心30分钟使上清液中的细胞膜沉积。使膜再悬浮于含10%蔗糖的细胞溶解缓冲液中,贮存在-80℃。放射性标记的人MCP1(比活性=2200Ci/mmol)购自Perkin-Elmer(Boston,MA)。
在CCR2受体结合测定中,结合反应在下列条件下进行:50mMHEPES、10mM NaCl、1mM CaCl2、10mM MgCl2、0.1%牛血清白蛋白、2μg细胞膜和160μg麦胚凝集素SPA珠(Amersham,Piscataway,NJ)、30pM放射性碘化的人MCP1以及指定浓度的竞争剂。在室温下不断摇动培养反应混合物。用1450 Microbeta Trilux counter(Wallac,Gaithersburg,MD)测量膜结合的放射性标记的rhMCP1。用GraphPadPrism 4软件(San Diego,CA)计算EC50和Ki值。
与放射性标记的rhMCP1竞争性结合含CCR2细胞的膜的hMCP1-mIg的效能比未标记rhMCP1小5-12倍(表5)。
表5.放射性碘化rhMCP1对CCR2结合的抑制

实施例5:MCP1-Ig融合物的表达、纯化和鉴定
在本实施例中,将融合物表达和纯化并鉴定。
hMCP-1-hIg融合蛋白变异体。使人MCP1-hIg变异体蛋白在哺乳动物细胞中表达、分泌,然后从细胞生长培养基分离。用上文关于纯化hMCP-1-mIg的相同方案进行纯化。用SDS-PAGE分析分离的蛋白质。
用逆转录聚合酶链式反应(RT-PCR)克隆人MCP1的cDNA(参阅基因库检索号NM_002982)和人免疫球蛋白重链γ1同种型(参阅基因库检索号019046)或γ4同种型(参阅基因库检索号BC025985)恒定区的部分cDNA(两种情况下都包括铰链、CH2和CH3区的编码序列)。为了产生γ1和γ4变异体的单体形式,用丝氨酸残基代替铰链区的半胱氨酸残基。
将对应于hMCP1-hIg变异体的cDNA作为Hind3-Not1片段分别克隆入哺乳动物表达载体pCDNA3.1(+)(Invitrogen,Carlsbad,CA)中,通过标准分子生物学操作产生pcDNA3.1(+)hMCP1-hIgG质粒。
将相应质粒稳定转染入CHO-K1细胞内表达hMCP-1-hIg变异体。转染、选择稳定克隆、组织培养和产物纯化的方案类似于hMCP-1-mIg实施例所述。
如hMCP-1-mIg实施例,用THP-1细胞膜测定hMCP-1-hIg变异体对CCR2受体的结合亲和力。估计二聚体形式hMCP-1-hIg(γ1)的变异体Ki值为16.8pM,单体形式hMCP-1-hIg(γ1)的变异体Ki值为28.8pM,二聚体形式hMCP-1-hIg(γ4)的变异体Ki值为51.9pM,单体形式hMCP-1-hIg(γ4)的变异体Ki值为90.1pM。相比之下,在相同实验测定hMCP-1的Ki值为65.7pM。
通过THP-1细胞趋化测定还确定变异体的相对功效。该方案类似于hMCP-1-mIg实施例所述。二聚体形式hMCP-1-hIg(γ1)的估计EC50值为50pM,单体形式hMCP-1-hIg(γ1)的估计EC50值为90pM,二聚体形式hMCP-1-hIg(γ4)的估计EC50值为500pM,单体形式hMCP-1-hIg(γ4)的估计EC50值为500pM。相比之下,在相同实验测定hMCP-1的EC50值为200-400pM。
通过趋化性测定用THP-1细胞确定hMCP-1-hIg变异体使CCR2脱敏的能力。该方案类似于hMCP-1-mIg实施例所述。在向hMCP-1迁移测试之前,使细胞与各种变异体hMCP-1-hIg培养30分钟。在低至1nM Ig-融合蛋白,用二聚体或单体形式hMCP-1-hIg(γ1)预处理之后,THP-1细胞的迁移完全停止。当细胞分别与1nM二聚体或单体形式hMCP-1-hIg(γ4)预孵育时,hMCP-1的EC50值增加2-4倍。当与10nM二聚体或单体形式hMCP-1-hIg(γ4)预孵育时,hMCP-1的EC50值增加30倍以上。
hMCP-1-mIg的纯化。为了大规模纯化(200mg以上)hMCP-1-mIg(用于下文提出的EAE和抗胶原抗体诱发的关节炎模型),用来自GEHealthcare(Uppsala,Sweden)的rProA Sepharose FF或MabSelect树脂进行ProA亲和层析。用高盐缓冲液使亲和柱平衡,所述缓冲液由10mM pH 7.2磷酸钠和125mM NaCl的氯化钠组成。将条件培养基装入柱内,然后用上文提出的相同缓冲液洗涤10床体积。将装有样品的柱用5床体积含10mM,pH 7.2磷酸钠的磷酸盐缓冲液洗涤。用5床体积0.1M pH 2.9的乙酸进行产物洗脱。立即用1M Tris碱使pH达到7.2中和洗脱液。调节pH之后,用Stericup Express GP Plus 0.22μm(Millipore,Bedford MA)过滤汇集液。
根据需要用Q Sepharose HiTRAPFF(GE Healthcare)任选进行阴离子交换层析除去少量杂质。平衡和洗涤缓冲液由10mM pH 7.2磷酸钠和125mM NaCl氯化钠组成。产物处于流穿液(flow-through)中。
用含10K再生纤维素的Amicon Stir Cell,Model 8050(Millipore)浓缩产物。
hMCP-1-mIg的药代动力学。用C57B6小鼠进行hMCP-1-mIg的药代动力学研究。将单剂量hMCP-1-mIg以10毫克/公斤体重静脉内、腹膜内或皮下注射三组小鼠。在30分钟至7天的时间点收集血清样品。用抗hMCP-1抗体(R&D Systems,Minneapolis,MN)作为捕获抗体,用辣根过氧化物酶缀合的抗小鼠IgG1抗体(Bethyl,Montgomery,TX)作为检测抗体,通过酶联免疫吸附测定(ELISA)检测hMCP-1-mIg的残留水平。结果显示血清半衰期为3-5天。在第7天hMCP-1-mIg的剩余水平为约10nM。
hMCP-1-mIg对急性和复发性EAE的作用。在SJL小鼠诱发实验性自身免疫性脑脊髓炎(EAE)。在第0天皮下注射2mg/mL完全弗氏佐剂(CFA)中的100μg/mL PLP139-151肽(HCLGKWLGHPDKF(SEQ ID NO:29);Biosynthesis;Lewisville,TX)和静脉内注射100ng百日咳毒素,使小鼠免疫。在第3、5天或第3、5、7天用10毫克/公斤体重(mpk)小鼠IgG1同种型对照抗体(SP-Biopharma)或人MCP-1-小鼠Ig(hMCP-1-mIg)融合蛋白处理小鼠。然后监测小鼠的体重和临床病征。如下记录疾病评分:1=尾部跛行,2=后肢虚弱,3=部分后肢麻痹,4=全部后肢麻痹和5=濒死。
通过对分离自脊髓的细胞进行流式细胞测定,监测细胞对中枢神经系统的侵入。每组用n=3只小鼠。对小鼠灌注含肝素的等渗缓冲液以从CNS除去外周血。收集脑和脊髓以分离CNS单核细胞。挤压细胞使其通过金属丝筛网,与胶原酶和DNA酶孵育以释放单核细胞。然后使细胞混悬液通过percoll梯度离心。通过台盼蓝细胞计数测定细胞回收率,用FACS分析建立细胞分布曲线。分别用与抗CD45、CD11b(用于炎性巨噬细胞)和CD4(用于活化T细胞)缀合的BD染料使细胞染色。抗体购自BD Biosciences(San Jose,CA)。用cell quest软件(BDBiosciences,San Jose,CA)在Facscaliber上分析染色的细胞。
表6显示的结果表明hMCP-1-mIg在EAE模型中的保护作用。该保护作用显示与脊髓巨噬细胞数的减少有关。
表6.hMCP-1-mIg融合蛋白处理抑制EAE

*临床评分数据为这两项研究的合并数据。多数小鼠在临床前取得以进行早期机理研究,未包括在内。
表7.hMCP-1-mIg融合蛋白抑制巨噬细胞侵入CNS内
组别 给药方案 CNS分析 处理 炎性巨 噬活化T细
10mpk 细胞* 胞**
A d3,5 d5 hMCP1-mIgG1 1.87E+04 6.29E+04
mIgG1 2.25E+04 3.76E+04
B d3,5 d6 hMCP1-mIgG1 1.75E+04 7.26E+05
mIgG1 4.73E+04 4.12E+05
C d3,5 d6 hMCP1-mIgG1 1.62E+05 6.28E+04
mIgG1 3.35E+05 9.20E+04
D d3,5,7 d12 hMCP1-mIgG1 0.69E+05 1.29E+05
mIgG1 2.36E+05 3.72E+05
*炎性巨噬细胞群定义为:CD45hi/CD11b+/CD4-
**活化T细胞定义为:CD45hi/CD11b-/CD4+
实施例6:hMCP-1-mIg对抗胶原抗体诱发的关节炎的作用
在本实施例中,测定hMCP-1-mIg减少抗胶原抗体诱发的关节炎的能力。
通过将800μg Chemicon’s arthrogen CIA抗体(Chemicon,Temecula,CA)合剂静脉内注入年龄匹配的雄性B10RIII小鼠诱发抗体诱发的关节炎。在该诱发之前,皮下注射40mpk同种型对照mIgG1或hMCP-1-mIg融合蛋白处理小鼠。在第2或3天开始发病。每天对动物评分。测量每只爪的评分系统如下:1=一个关节肿胀,2=两个或多个关节肿胀,3=整个足部肿胀。每只小鼠可接受最大疾病评分为12。所得结果在下文表8列出。
表8.MCP-1 Ig融合蛋白抑制抗体诱发的关节炎
抗体诱发的关节炎中的huMCP-1Ig FP
平均疾病评分

本发明的范围不限于本文描述的具体实施方案。事实上,本领域技术人员从上述说明书中将清楚本文描述之外的本发明的各种修改。此类修改意味着落在附属权利要求的范围之内。
专利、专利申请、出版物、产品说明书和方案贯穿本申请书引用,出于各种目的其公开内容通过引用完全结合到本文中。
序列表
<110>Schering Corporation
<120>MCP1 Fusions
<130>JB06384
<140>
<141>2006-08-10
<150>60/707,731
<151>2005-08-12
<160>30
<170>PatentIn version 3.3
<210>1
<211>99
<212>PRT
<213>人(Homo sapiens)
<400>1

<210>2
<211>76
<212>PRT
<213>人(Homo sapiens)
<400>2
<210>3
<211>227
<212>PRT
<213>人工序列
<220>
<223>小鼠免疫球蛋白重链恒定区的成熟多肽序列(铰链至CH3,仅),同种型γ1
<400>3


<210>4
<211>229
<212>PRT
<213>人工序列
<220>
<223>人免疫球蛋白重链恒定区(铰链至CH3,仅),同种型γ4
<400>4

<210>5
<211>229
<212>PRT
<213>人工序列
<220>
<223>人免疫球蛋白重链恒定区(铰链至CH3,仅),同种型γ4单体变异体
<400>5

<210>6
<211>233
<212>PRT
<213>人工序列
<220>
<223>人免疫球蛋白重链恒定区(铰链至CH3,仅),同种型γ1
<400>6


<210>7
<211>233
<212>PRT
<213>人工序列
<220>
<223>人免疫球蛋白重链恒定区(铰链至CH3,仅),同种型γ1单体变异体
<400>7


<210>8
<211>305
<212>PRT
<213>人工序列
<220>
<223>人MCP-1,与小鼠IgG1融合
<400>8


<210>9
<211>307
<212>PRT
<213>人工序列
<220>
<223>成熟人MCP-1,与人IgG4融合
<400>9



<210>10
<211>307
<212>PRT
<213>人工序列
<220>
<223>成熟人MCP-1,与人IgG4单体变异体融合
<400>10


<210>11
<211>311
<212>PRT
<213>人工序列
<220>
<223>成熟人MCP-1,与人IgG1融合
<400>11


<210>12
<211>311
<212>PRT
<213>人工序列
<220>
<223>人MCP-1,与人IgG1单体变异体融合
<400>12

<210>13
<211>300
<212>DNA
<213>人(Homo sapiens)
<400>13

<210>14
<211>684
<212>DNA
<213>人工序列
<220>
<223>小鼠重链免疫球蛋白恒定区,γ1同种型,始于铰链去的氨基端,终于CH3区的羧基端
<400>14

<210>15
<211>690
<212>DNA
<213>人工序列
<220>
<223>人重链免疫球蛋白恒定区,γ4同种型,始于铰链去的氨基端,终于CH3区的羧基端
<400>15

<210>16
<211>690
<212>DNA
<213>人工序列
<220>
<223>人重链免疫球蛋白恒定区,γ4同种型,单体变异体,始于铰链区的氨基端,终于CH3区的羧基端
<400>16

<210>17
<211>702
<212>DNA
<213>人工序列
<220>
<223>人重链免疫球蛋白恒定区,γ1同种型,始于铰链去的氨基端,终于CH3区的羧基端
<400>17

<210>18
<211>702
<212>DNA
<213>人工序列
<220>
<223>人重链免疫球蛋白恒定区,γ1同种型,单体变异体,始于铰链区的氨基端,终于CH3区的羧基端
<400>18

<210>19
<211>987
<212>DNA
<213>人工序列
<220>
<223>人MCP-1(包括前导肽),与小鼠IgG1融合
<400>19

<210>20
<211>993
<212>DNA
<213>人工序列
<220>
<223>人MCP-1(包括前导肽),与人IgG4融合
<400>20
<210>21
<211>993
<212>DNA
<213>人工序列
<220>
<223>人MCP-1(包括前导序列),与人IgG4单体变异体融合
<400>21

<210>22
<211>1005
<212>DNA
<213>人工序列
<220>
<223>人MCP-1(包括前导序列),与人IgG1融合
<400>22


<210>23
<211>1005
<212>DNA
<213>人工序列
<220>
<223>人MCP-1(包括前导序列),与人IgG1单体变异体融合
<400>23


<210>24
<211>6393
<212>DNA
<213>人工序列
<220>
<223>质粒pcDNA3.1(+)hMCP1 mIgG
<400>24




<210>25
<211>6399
<212>DNA
<213>人工序列
<220>
<223>质粒pcDNA3.1(+)hMCP1 hIgG4
<400>25




<210>26
<211>6399
<212>DNA
<213>人工序列
<220>
<223>质粒pcDNA3.1(+)hMCP1 hIgG4单体变异体
<400>26




<210>27
<211>6411
<212>DNA
<213>人工序列
<220>
<223>质粒pcDNA3.1(+)hMCP1 hIgG1
<400>27

<210>28
<211>6411
<212>DNA
<213>人工序列
<220>
<223>质粒pcDNA3.1(+)hMCP1 hIgG1单体变异体
<400>28




<210>29
<211>13
<212>PRT
<213>人工序列
<220>
<223>PLP139-151肽
<400>29

<210>30
<211>148
<212>PRT
<213>鼠(Mus sp.)
<400>30


Claims (48)
1.一种分离的多肽,所述多肽包括
(1)与一种或多种半衰期延长部分融合的一种或多种趋化因子多肽;或
(2)两种或多种融合的趋化因子多肽。
2.权利要求1的多肽,其中所述趋化因子选自人MCP1和小鼠MCP1。
3.权利要求1的多肽,其中所述半衰期延长部分是聚乙二醇或免疫球蛋白。
4.权利要求1的多肽,所述多肽包括与一种或多种免疫球蛋白融合的一种或多种成熟MCP1多肽。
5.权利要求4的多肽,其中所述MCP1选自人MCP1和小鼠MCP1。
6.权利要求3的多肽,其中所述免疫球蛋白选自铰链至CH3区的γ1和γ4。
7.权利要求4的多肽,其中所述多肽包括选自下列的多肽:
(a)与小鼠IgG1融合的成熟人MCP1;
(b)与人IgG4融合的成熟人MCP1;
(c)与人IgG4单体变异体融合的成熟人MCP1;
(d)与人IgG1融合的成熟人MCP1;和
(e)与人IgG1单体变异体融合的成熟人MCP1。
8.权利要求4的多肽,其中所述多肽包含选自SEQ ID NO:8-12列出的氨基酸序列。
9.权利要求4的多肽,其中所述MCP1包含SEQ ID NO:2列出的氨基酸。
10.权利要求4的多肽,其中所述免疫球蛋白包含选自SEQ IDNO:3-7列出的氨基酸序列。
11.权利要求4的多肽,其中所述MCP1通过肽接头与免疫球蛋白融合。
12.一种药用组合物,所述药用组合物包含权利要求1的多肽和药学上可接受的载体。
13.一种组合物,包含权利要求1的多肽以及一种或多种其它治疗剂或其药用组合物。
14.权利要求13的组合物,其中其它治疗剂选自阿司匹林、双氯芬酸、二氟尼柳、依托度酸、非诺洛芬、夫洛非宁、氟比洛芬、布洛芬、吲哚美辛、酮洛芬、酮咯酸、甲氯芬那酸、甲芬那酸、美洛昔康、萘丁美酮、萘普生、噁丙嗪、保泰松、吡罗昔康、双水杨酸酯、舒林酸、替诺昔康、噻洛芬酸、托美丁、苯甲酸倍他米松、戊酸倍他米松、丙酸氯倍他索、去羟米松、氟轻松、氟羟可舒松、表面类固醇、二丙酸阿氯米松、芦荟、安西奈德、安西奈德、蒽林、二丙酸倍他米松、戊酸倍他米松、卡泊三烯、丙酸氯倍他索、煤焦油、死海盐、地奈德、地奈德、戊酸倍他米松、去羟米松、二乙酸二氟拉松、泻盐、氟轻松、氟轻松、氟羟可舒松、丙酸氟替卡松、哈西奈德、丙酸卤贝他索、戊酸氢化可的松、氢化可的松、糠酸莫米松、油状麦片、凡士林、泼尼卡酯、水杨酸、他扎罗汀、曲安奈德、氢化可的松、地塞米松、甲基泼尼松龙和泼尼松龙混合物、alefacept、依那西普、环孢菌素、甲氨蝶呤、阿曲汀、异维甲酸、羟基脲、霉酚酸酯、柳氮磺吡啶、6-硫鸟嘌呤、阿那白滞素、注射金、青霉胺、硫唑嘌呤、氯喹、羟基氯喹、柳氮磺吡啶、口服金、金诺芬、硫代苹果酸金钠、金硫葡糖、美沙拉嗪、柳氮磺吡啶、布地奈德、甲硝唑、环丙沙星、硫唑嘌呤、6-巯基嘌呤或膳食补充剂钙、叶酸盐、维生素B12、塞来考昔、罗非考昔、伐地考昔、罗美昔布、艾托考昔、依法利珠单抗、阿达木单抗、英夫利昔单抗和ABX-IL8。
15.一种分离的多核苷酸,所述多核苷酸包含编码权利要求1的多肽的核苷酸序列。
16.权利要求15的多核苷酸,其中所述核苷酸序列编码选自下列的成员:
(i)与小鼠IgG1融合的人未加工的MCP1;
(ii)与人IgG4融合的人未加工的MCP1;
(iii)与人IgG4单体变异体融合的人未加工的MCP1;
(iv)与人IgG1融合的人未加工的MCP1;和
(v)与人IgG1单体变异体融合的人未加工的MCP1。
17.权利要求15的多核苷酸,其中所述MCP1由SEQ ID NO:13列出的核苷酸序列编码。
18.权利要求15的多核苷酸,其中所述免疫球蛋白由选自SEQ IDNO:14-18的核苷酸序列编码。
19.权利要求15的多核苷酸,所述多核苷酸包含选自SEQ IDNO:19-23的核苷酸序列。
20.一种包含权利要求15的多核苷酸的分离或重组载体。
21.一种包含权利要求20的载体的分离的宿主细胞。
22.一种分离的质粒,其特征在于基本如图1显示的质粒图。
23.权利要求22的质粒,所述质粒包含SEQ ID NO:24的核苷酸序列。
24.一种分离的质粒,所述质粒包含选自SEQ ID NO:24-28的核苷酸序列。
25.一种制备MCP1-Ig多肽的方法,所述方法包括在适合所述表达的条件下,用包含编码所述多肽的多核苷酸的表达载体转化宿主细胞,并任选从宿主细胞中分离多肽。
26.权利要求25的方法,其中所述多核苷酸编码包含选自SEQ IDNO:8-12的氨基酸序列的多肽。
27.权利要求25的方法,其中所述多核苷酸是质粒pcDNA3.1(+)hMCP1 mIgG。
28.一种通过权利要求25的方法制备的分离多肽。
29.一种治疗受试者疾病的方法,通过降低趋化因子或趋化因子受体的表达或活性或者通过减少趋化因子受体携带细胞向炎性组织的迁移可治疗所述疾病,所述方法包括使受试者的趋化因子受体携带细胞对趋化因子配体脱敏。
30.权利要求29的方法,其中所述疾病选自炎性疾病、寄生虫感染、细菌感染、病毒感染、癌症、心血管疾病、循环系统疾病和肥胖症相关性胰岛素抵抗。
31.权利要求29的方法,其中通过将趋化因子配体多肽或与半衰期延长部分融合的趋化因子配体多肽全身性给予受试者使所述趋化因子受体携带细胞对趋化因子配体脱敏。
32.权利要求29的方法,其中所述趋化因子是MCP1、SDF1、MIP1β或其成熟多肽。
33.权利要求31的方法,其中所述半衰期延长部分是免疫球蛋白或其片段。
34.权利要求32的方法,其中所述MCP1包含SEQ ID NO:2列出的氨基酸序列。
35.权利要求33的方法,其中所述免疫球蛋白片段包含选自SEQID NO:3-7的氨基酸序列。
36.权利要求31的方法,其中所述多肽是包含选自SEQ ID NO:8-12的氨基酸序列的MCP1-Ig。
37.一种治疗或预防受试者炎性疾病、肥胖症相关性胰岛素抵抗、寄生虫感染、细菌感染、病毒感染、癌症或者心血管或循环系统疾病的方法,所述方法包括给予受试者多肽,所述多肽包括任选与一种或多种半衰期延长部分或其药用组合物融合的一种或多种MCP1多肽,还任选包括其它治疗剂或过程。
38.权利要求37的方法,其中所述炎性疾病选自阑尾炎、消化性溃疡、胃溃疡和十二指肠溃疡、腹膜炎、胰腺炎、炎性肠病、结肠炎、溃疡性结肠炎、伪膜性肠炎、急性结肠炎、缺血性结肠炎、憩室炎、会厌炎、失弛缓症、胆管炎、胆囊炎、腹部疾病、肝炎、克罗恩病、肠炎、惠普尔病、哮喘、过敏、过敏性休克、免疫复合物病、器官缺血、再灌注损伤、器官坏死、花粉热、脓毒症、败血症、内毒素性休克、恶病质、高热、嗜酸细胞性肉芽肿、肉芽肿病、肉状瘤病、脓毒性流产、附睾炎、阴道炎、前列腺炎和尿道炎、支气管炎、肺气肿、鼻炎、纤维化、囊性纤维化、肺炎、成人呼吸窘迫综合征、黑肺病、肺泡炎、细支气管炎、咽炎、胸膜炎、鼻窦炎、皮炎、特应性皮炎、皮肌炎、晒伤、风疹疣、风疹块、狭窄、再狭窄、血管炎、脉管炎、心内膜炎、动脉炎、动脉粥样硬化、血栓性静脉炎、心包炎、心肌炎、心肌缺血、结节性多动脉炎、风湿热、脑膜炎、脑炎、多发性硬化(MS)、神经炎、神经痛、葡萄膜炎、关节炎和关节痛、骨髓炎、筋膜炎、佩吉特病、痛风、牙周病、类风湿性关节炎、滑膜炎、重症肌无力、甲状腺炎、系统性红斑狼疮、肺出血-肾炎综合征、白塞综合征、同种异体移植物排斥和移植物抗宿主病。
39.权利要求37的方法,其中所述MCP1包含SEQ ID NO:2列出的氨基酸序列。
40.权利要求37的方法,其中所述半衰期延长部分是聚乙二醇、免疫球蛋白或其片段。
41.权利要求40的方法,其中所述免疫球蛋白片段包含选自SEQID NO:3-7的氨基酸序列。
42.权利要求37的方法,其中所述多肽是包含选自SEQ ID NO:8-12的氨基酸序列的MCP1-Ig。
43.权利要求37的方法,其中所述受试者是人。
44.权利要求37的方法,其中其它治疗剂或过程选自阿司匹林、双氯芬酸、二氟尼柳、依托度酸、非诺洛芬、夫洛非宁、氟比洛芬、布洛芬、吲哚美辛、酮洛芬、酮咯酸、甲氯芬那酸、甲芬那酸、美洛昔康、萘丁美酮、萘普生、噁丙嗪、保泰松、吡罗昔康、双水杨酸酯、舒林酸、替诺昔康、噻洛芬酸、托美丁、苯甲酸倍他米松、戊酸倍他米松、丙酸氯倍他索、去羟米松、氟轻松、氟羟可舒松、表面类固醇二丙酸阿氯米松、芦荟、安西奈德、安西奈德、蒽林、二丙酸倍他米松、戊酸倍他米松、卡泊三烯、丙酸氯倍他索、煤焦油、死海盐、地奈德、地奈德、戊酸倍他米松、去羟米松、二乙酸二氟拉松、泻盐、氟轻松、氟轻松、氟羟可舒松、丙酸氟替卡松、哈西奈德、丙酸卤贝他索、戊酸氢化可的松、氢化可的松、糠酸莫米松、油状麦片、凡士林、泼尼卡酯、水杨酸、他扎罗汀、曲安奈德、氢化可的松、地塞米松、甲基泼尼松龙和泼尼松龙混合物、alefacept、依那西普、环孢菌素、甲氨蝶呤、阿曲汀、异维甲酸、羟基脲、霉酚酸酯、柳氮磺吡啶、6-硫鸟嘌呤、阿那白滞素、可注射金、青霉胺、硫唑嘌呤、氯喹、羟基氯喹、柳氮磺吡啶、口服金、金诺芬、硫代苹果酸金钠、金硫葡糖、美沙拉嗪、柳氮磺吡啶、布地奈德、甲硝唑、环丙沙星、硫唑嘌呤、6-巯基嘌呤或膳食补充剂钙、叶酸盐、维生素B12、塞来考昔、罗非考昔、伐地考昔、罗美昔布、艾托考昔、依法利珠单抗、阿达木单抗、英夫利昔单抗、ABX-IL8和光疗。
45.一种增加趋化因子多肽在受试者机体的体内半衰期的方法,所述方法包括使多肽与免疫球蛋白或其片段或者与聚乙二醇(PEG)融合。
46.权利要求45的方法,其中所述趋化因子多肽是MCP1。
47.权利要求45的方法,其中所述MCP1包含SEQ ID NO:2列出的氨基酸序列。
48.权利要求45的方法,其中所述免疫球蛋白包含选自SEQ IDNO:3-7的氨基酸序列。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US70773105P | 2005-08-12 | 2005-08-12 | |
| US60/707,731 | 2005-08-12 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN101443357A true CN101443357A (zh) | 2009-05-27 |
Family
ID=37421010
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNA2006800374431A Pending CN101443357A (zh) | 2005-08-12 | 2006-08-10 | Mcp1融合物 |
Country Status (12)
| Country | Link |
|---|---|
| US (3) | US7713521B2 (zh) |
| EP (1) | EP1926747A1 (zh) |
| JP (2) | JP2009504158A (zh) |
| KR (1) | KR20080045158A (zh) |
| CN (1) | CN101443357A (zh) |
| AU (1) | AU2006280004A1 (zh) |
| CA (1) | CA2618951A1 (zh) |
| IL (1) | IL189414A0 (zh) |
| MX (1) | MX2008002101A (zh) |
| NO (1) | NO20081294L (zh) |
| WO (1) | WO2007021807A1 (zh) |
| ZA (1) | ZA200801606B (zh) |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103857406A (zh) * | 2011-06-01 | 2014-06-11 | 莫尔豪斯医学院 | 趋化因子-免疫球蛋白融合多肽、组合物及其制备和使用方法 |
| US9249204B2 (en) | 2011-06-01 | 2016-02-02 | Jyant Technologies, Inc. | Chemokine-immunoglobulin fusion polypeptides, compositions, method of making and use thereof |
| CN105920585A (zh) * | 2016-06-13 | 2016-09-07 | 浙江生创精准医疗科技有限公司 | Mcp-1单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN105920579A (zh) * | 2016-06-13 | 2016-09-07 | 浙江生创精准医疗科技有限公司 | Gro单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN105944086A (zh) * | 2016-06-13 | 2016-09-21 | 浙江生创精准医疗科技有限公司 | Il-8单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN105944085A (zh) * | 2016-06-13 | 2016-09-21 | 浙江生创精准医疗科技有限公司 | Il-6单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN105944082A (zh) * | 2016-06-13 | 2016-09-21 | 浙江生创精准医疗科技有限公司 | 骨保护素单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN114796264A (zh) * | 2021-01-27 | 2022-07-29 | 北京北工大科技园有限公司 | 金络合物在制备治疗新型冠状病毒肺炎的药物中的应用 |
| CN115192584A (zh) * | 2022-06-09 | 2022-10-18 | 南方科技大学 | 一种纳米药物及其制备方法和应用 |
| WO2023016284A1 (zh) * | 2021-08-11 | 2023-02-16 | 南京北恒生物科技有限公司 | 工程化免疫细胞及其用途 |
Families Citing this family (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2007815A2 (en) * | 2006-03-31 | 2008-12-31 | Biotherapix Molecular Medicines S.L.U. | Mono- and bifunctional molecules with ability to bind to g protein-coupled receptors |
| EP2056857B1 (en) * | 2006-07-24 | 2013-08-21 | Yeda Research And Development Co. Ltd. | Pharmaceutical compositions comprising ccl2 for use in the treatment of inflammation |
| EP2074428B1 (en) * | 2006-09-29 | 2015-07-01 | Roche Diagnostics GmbH | Assessing the risk of disease progression for a patient with rheumatoid arthritis |
| WO2011084357A1 (en) | 2009-12-17 | 2011-07-14 | Schering Corporation | Modulation of pilr to treat immune disorders |
| US8524217B2 (en) | 2010-05-11 | 2013-09-03 | Merck Sharp & Dohme Corp. | MCP1-Ig fusion variants |
| MX356517B (es) | 2011-06-28 | 2018-06-01 | Inhibrx Llc | Polipéptidos de fusión de serpina y métodos de uso de los mismos. |
| US10400029B2 (en) | 2011-06-28 | 2019-09-03 | Inhibrx, Lp | Serpin fusion polypeptides and methods of use thereof |
| CA2858389A1 (en) * | 2011-12-15 | 2013-06-20 | The Royal Institution For The Advancement Of Learning/Mcgill University | Soluble igf receptor fc fusion proteins and uses thereof |
| EP3071600B1 (en) * | 2013-11-20 | 2020-06-17 | Regeneron Pharmaceuticals, Inc. | Aplnr modulators and uses thereof |
| EP3096776B1 (en) | 2014-01-22 | 2020-12-02 | Antagonis Biotherapeutics GmbH | Novel glycosaminoglycan-antagonising fusion proteins and methods of using same |
| WO2016069574A1 (en) * | 2014-10-27 | 2016-05-06 | Inhibrx Lp | Serpin fusion polypeptides and methods of use thereof |
| US11566082B2 (en) | 2014-11-17 | 2023-01-31 | Cytiva Bioprocess R&D Ab | Mutated immunoglobulin-binding polypeptides |
| EP3253797A4 (en) * | 2015-02-03 | 2018-10-03 | Jyant Technologies, Inc. | Chemokine-immunoglobulin fusion polypeptides, compositions, method of making and use thereof |
| ES2863682T3 (es) * | 2016-01-06 | 2021-10-11 | Univ Keio | Agente antitumoral |
| KR102682118B1 (ko) | 2016-04-29 | 2024-07-08 | 주식회사유한양행 | Ccl3 변이체를 포함하는 융합 단백질 및 이의 용도 |
| EP3455240A1 (en) | 2016-05-11 | 2019-03-20 | GE Healthcare BioProcess R&D AB | Method of storing a separation matrix |
| US10703774B2 (en) | 2016-09-30 | 2020-07-07 | Ge Healthcare Bioprocess R&D Ab | Separation method |
| US10730908B2 (en) | 2016-05-11 | 2020-08-04 | Ge Healthcare Bioprocess R&D Ab | Separation method |
| JP7031934B2 (ja) | 2016-05-11 | 2022-03-08 | サイティバ・バイオプロセス・アールアンドディ・アクチボラグ | 分離マトリックス |
| US10889615B2 (en) | 2016-05-11 | 2021-01-12 | Cytiva Bioprocess R&D Ab | Mutated immunoglobulin-binding polypeptides |
| US11753438B2 (en) | 2016-05-11 | 2023-09-12 | Cytiva Bioprocess R&D Ab | Method of cleaning and/or sanitizing a separation matrix |
| US10654887B2 (en) | 2016-05-11 | 2020-05-19 | Ge Healthcare Bio-Process R&D Ab | Separation matrix |
| ES2874974T3 (es) | 2016-05-11 | 2021-11-05 | Cytiva Bioprocess R & D Ab | Matriz de separación |
| KR102065150B1 (ko) | 2018-04-27 | 2020-01-10 | (주)케어젠 | 이소트레티노인-펩타이드 결합체를 유효성분으로 포함하는 비만의 예방 또는 치료용 조성물 |
| US11464464B2 (en) * | 2020-07-24 | 2022-10-11 | International Business Machines Corporation | Internal and external proximate scanning |
Family Cites Families (94)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4588585A (en) * | 1982-10-19 | 1986-05-13 | Cetus Corporation | Human recombinant cysteine depleted interferon-β muteins |
| US4751180A (en) * | 1985-03-28 | 1988-06-14 | Chiron Corporation | Expression using fused genes providing for protein product |
| IL92938A (en) | 1989-01-01 | 1998-08-16 | Us Commerce | A polypeptide that has a mutagenic activity on monocytes and AND that encodes it |
| IL92937A0 (en) * | 1989-01-31 | 1990-09-17 | Us Health | Human derived monocyte attracting protein,pharmaceutical compositions comprising it and dna encoding it |
| US6869924B1 (en) * | 1989-01-31 | 2005-03-22 | The United States Of America As Represented By The Department Of Health And Human Services | Human derived monocyte attracting purified protein product useful in a method of treating infection and neoplasms in a human body, and the cloning of full length cDNA thereof |
| US5225538A (en) * | 1989-02-23 | 1993-07-06 | Genentech, Inc. | Lymphocyte homing receptor/immunoglobulin fusion proteins |
| US5098833A (en) * | 1989-02-23 | 1992-03-24 | Genentech, Inc. | DNA sequence encoding a functional domain of a lymphocyte homing receptor |
| US5116964A (en) * | 1989-02-23 | 1992-05-26 | Genentech, Inc. | Hybrid immunoglobulins |
| US6406697B1 (en) * | 1989-02-23 | 2002-06-18 | Genentech, Inc. | Hybrid immunoglobulins |
| US5216131A (en) * | 1989-02-23 | 1993-06-01 | Genentech, Inc. | Lymphocyte homing receptors |
| US6767535B1 (en) * | 1989-05-12 | 2004-07-27 | Dana-Farber Cancer Institute, Inc. | Suppressing tumor formation using cells expressing JE/monocyte chemoattractant protein-1 |
| US6787645B1 (en) * | 1989-05-12 | 2004-09-07 | Dana-Farber Cancer Institute, Inc. | DNA encoding human JE cytokine |
| US5179078A (en) * | 1989-05-12 | 1993-01-12 | Dana Farber Cancer Institute | Method of suppressing tumor formation in vivo |
| US5212073A (en) * | 1989-05-12 | 1993-05-18 | Genetics Institute, Inc. | Process for producing human JE cytokine |
| ES2096749T3 (es) * | 1990-12-14 | 1997-03-16 | Cell Genesys Inc | Cadenas quimericas para vias de transduccion de señal asociada a un receptor. |
| WO1992019737A1 (en) | 1991-05-09 | 1992-11-12 | Dainippon Pharmaceutical Co., Ltd. | Process for producing a monocyte chemotactic factor polypeptide and a strain for the production thereof |
| US5846717A (en) * | 1996-01-24 | 1998-12-08 | Third Wave Technologies, Inc. | Detection of nucleic acid sequences by invader-directed cleavage |
| US5605671A (en) * | 1992-10-05 | 1997-02-25 | The Regents Of The University Of Michigan | Radiolabeled neutrophil activating peptides for imaging |
| WO1994009128A1 (en) * | 1992-10-22 | 1994-04-28 | Mallinckrodt Medical, Inc. | Therapeutic treatment for inhibiting vascular restenosis |
| EP0708838A1 (en) | 1993-07-29 | 1996-05-01 | PHARMACIA & UPJOHN COMPANY | Use of heparanase to identify and isolate anti-heparanase compound |
| US5510264A (en) | 1993-09-28 | 1996-04-23 | Insight Biotech Inc. | Antibodies which bind meningitis related homologous antigenic sequences |
| US5739103A (en) * | 1993-11-12 | 1998-04-14 | Dana-Farber Cancer Institute | Chemokine N-terminal deletion mutations |
| US5459128A (en) * | 1993-11-12 | 1995-10-17 | Dana-Farber Cancer Institute | Human monocyte chemoattractant protein-1 (MCP-1) derivatives |
| JPH09508358A (ja) | 1994-01-14 | 1997-08-26 | マリンクロット・メディカル・インコーポレテイッド | 血管再狭窄を抑止するための医療的処置 |
| CN1144845A (zh) | 1995-03-01 | 1997-03-12 | 中国人民解放军军事医学科学院生物工程研究所 | 新型人粒细胞巨噬细胞集落刺激因子的融合蛋白 |
| SK16497A3 (en) * | 1995-06-07 | 1998-05-06 | Icos Corp | Macrophage derived chemokine and chemokine analogs |
| US6498015B1 (en) * | 1995-06-07 | 2002-12-24 | Icos Corporation | Methods of identifying agents that modulate the binding between MDC and an MDC receptor |
| US6737513B1 (en) * | 1996-06-07 | 2004-05-18 | Icos Corporation | Macrophage derived chemokine (MDC) and chemokine analogs and assay to identify modulators of MDC activity, and therapeutic uses for same |
| CA2152141A1 (en) | 1995-06-19 | 1996-12-20 | Ian-Clark Lewis | Monocyte chemoattractant protein (mcp)-1 antagonists |
| US6403782B1 (en) * | 1995-06-22 | 2002-06-11 | President And Fellows Of Harvard College | Nucleic acid encoding eotaxin |
| US6706471B1 (en) * | 1996-01-24 | 2004-03-16 | Third Wave Technologies, Inc. | Detection of nucleic acid sequences by invader-directed cleavage |
| US6780982B2 (en) * | 1996-07-12 | 2004-08-24 | Third Wave Technologies, Inc. | Charge tags and the separation of nucleic acid molecules |
| WO1998039446A2 (en) * | 1997-03-07 | 1998-09-11 | Human Genome Sciences, Inc. | 70 human secreted proteins |
| US6878687B1 (en) * | 1997-03-07 | 2005-04-12 | Human Genome Sciences, Inc. | Protein HMAAD57 |
| EP0973898A2 (en) | 1997-04-10 | 2000-01-26 | Genetics Institute, Inc. | SECRETED EXPRESSED SEQUENCE TAGS (sESTs) |
| GB9715660D0 (en) | 1997-07-25 | 1997-10-01 | Zeneca Ltd | Proteins |
| US6989435B2 (en) | 1997-09-11 | 2006-01-24 | Cambridge University Technical Services Ltd. | Compounds and methods to inhibit or augment an inflammatory response |
| US6569418B1 (en) * | 1997-12-11 | 2003-05-27 | University Of Maryland Biotechnology Institute | Immuno-modulating effects of chemokines in DNA vaccination |
| US6485910B1 (en) * | 1998-02-09 | 2002-11-26 | Incyte Genomics, Inc. | Ras association domain containing protein |
| US6607879B1 (en) * | 1998-02-09 | 2003-08-19 | Incyte Corporation | Compositions for the detection of blood cell and immunological response gene expression |
| EP1346731B1 (en) | 1998-07-22 | 2006-12-06 | Osprey Pharmaceuticals Limited | Conjugates for treating inflammatory disorders and associated tissue damage |
| CA2333901A1 (en) | 1998-08-03 | 2000-02-24 | East Carolina University | Low adenosine anti-sense oligonucleotide agent, composition, kit and treatments |
| AU1208200A (en) | 1998-10-15 | 2000-05-01 | Genetics Institute Inc. | Secreted expressed sequence tags (sests) |
| US20040248169A1 (en) * | 1999-01-06 | 2004-12-09 | Chondrogene Limited | Method for the detection of obesity related gene transcripts in blood |
| JP4712975B2 (ja) | 1999-01-12 | 2011-06-29 | ケンブリッジ エンタープライズ リミティド | 炎症反応を阻害又は増強するための組成物及び方法 |
| US20040031072A1 (en) * | 1999-05-06 | 2004-02-12 | La Rosa Thomas J. | Soy nucleic acid molecules and other molecules associated with transcription plants and uses thereof for plant improvement |
| US20020009730A1 (en) * | 1999-11-17 | 2002-01-24 | Alex Chenchik | Human stress array |
| AU2074101A (en) * | 1999-12-08 | 2001-06-18 | Millennium Pharmaceuticals, Inc. | Compositions, kits, and methods for identification, assessment, prevention, and therapy of cervical cancer |
| AU2596901A (en) | 1999-12-21 | 2001-07-03 | Millennium Pharmaceuticals, Inc. | Compositions, kits, and methods for identification, assessment, prevention, and therapy of breast cancer |
| US20040002068A1 (en) * | 2000-03-01 | 2004-01-01 | Corixa Corporation | Compositions and methods for the detection, diagnosis and therapy of hematological malignancies |
| US20030078396A1 (en) * | 2000-03-01 | 2003-04-24 | Corixa Corporation | Compositions and methods for the detection, diagnosis and therapy of hematological malignancies |
| AU4347701A (en) * | 2000-03-01 | 2001-09-12 | Corixa Corp | Compositions and methods for the detection, diagnosis and therapy of hematological malignancies |
| CA2343602A1 (en) | 2000-04-18 | 2001-10-18 | Genset | Est's and encoded human proteins |
| WO2001089582A1 (fr) * | 2000-05-26 | 2001-11-29 | Takeda Chemical Industries, Ltd. | Prophylactiques de l'hypertension pulmonaire et remèdes |
| AU2001286890A1 (en) | 2000-08-28 | 2002-03-13 | Genaissance Pharmaceuticals, Inc. | Haplotypes of the scya2 gene |
| US20030175704A1 (en) * | 2000-10-04 | 2003-09-18 | Lasek Amy K. W. | Genes expressed in lung cancer |
| US20020137081A1 (en) * | 2001-01-08 | 2002-09-26 | Olga Bandman | Genes differentially expressed in vascular tissue activation |
| WO2002068579A2 (en) | 2001-01-10 | 2002-09-06 | Pe Corporation (Ny) | Kits, such as nucleic acid arrays, comprising a majority of human exons or transcripts, for detecting expression and other uses thereof |
| WO2002060317A2 (en) * | 2001-01-30 | 2002-08-08 | Corixa Corporation | Compositions and methods for the therapy and diagnosis of pancreatic cancer |
| WO2002066510A2 (en) | 2001-02-20 | 2002-08-29 | K.U. Leuven Research And Development | Regakine-1 |
| US20040265808A1 (en) * | 2001-04-05 | 2004-12-30 | Teresa Garcia | Genes involved in osteogenesis, and methods of use |
| US20070021360A1 (en) | 2001-04-24 | 2007-01-25 | Nyce Jonathan W | Compositions, formulations and kit with anti-sense oligonucleotide and anti-inflammatory steroid and/or obiquinone for treatment of respiratory and lung disesase |
| AU2002305236A1 (en) | 2001-04-24 | 2002-11-05 | Epigenesis Pharmaceuticals, Inc. | Composition, formulations and kits for treatment of respiratory and lung disease with anti-sense oligonucleotides and a bronchodilating agent |
| US20030166903A1 (en) * | 2001-04-27 | 2003-09-04 | Anna Astromoff | Genes associated with vascular disease |
| US7171311B2 (en) | 2001-06-18 | 2007-01-30 | Rosetta Inpharmatics Llc | Methods of assigning treatment to breast cancer patients |
| US20040077835A1 (en) * | 2001-07-12 | 2004-04-22 | Robin Offord | Chemokine receptor modulators, production and use |
| US20030099974A1 (en) * | 2001-07-18 | 2003-05-29 | Millennium Pharmaceuticals, Inc. | Novel genes, compositions, kits and methods for identification, assessment, prevention, and therapy of breast cancer |
| CA2451168A1 (en) * | 2001-10-30 | 2003-05-08 | Ortho-Clinical Diagnostics, Inc. | Methods for assessing and treating leukemia |
| WO2003037376A1 (fr) | 2001-11-02 | 2003-05-08 | Kensuke Egashira | Prophylactiques et/ou remedes pour le traitement de l'arteriosclerose apres transplantation dans le cas de rejet de greffe |
| US20030129214A1 (en) * | 2002-01-10 | 2003-07-10 | University Of Washington | Methods of enhancing the biocompatibility of an implantable medical device |
| AU2003224761A1 (en) | 2002-03-26 | 2003-10-13 | Centocor, Inc. | Mcp-1 mutant proteins, antibodies, compositions, methods and uses |
| GB0207624D0 (en) | 2002-04-02 | 2002-05-15 | Cancer Res Ventures Ltd | Chemokine and uses thereof |
| US7425324B2 (en) | 2002-04-10 | 2008-09-16 | Laboratoires Serono Sa | Antagonists of MCP proteins |
| AU2002364707A1 (en) | 2002-04-23 | 2003-11-10 | Duke University | Atherosclerotic phenotype determinative genes and methods for using the same |
| JP2003310272A (ja) | 2002-04-26 | 2003-11-05 | Toshio Tanaka | 血管拡張薬応答遺伝子の発現量変化を指標にした血管拡張物質の探索方法 |
| CN1665931A (zh) * | 2002-05-31 | 2005-09-07 | 西根控股有限公司 | 从膜转运序列衍生的自身聚集或自身团聚嵌合蛋白 |
| RU2339647C2 (ru) * | 2002-08-19 | 2008-11-27 | Астразенека Аб | Антитела против моноцитарного хемоаттрактантного белка-1 (мср-1) и их применение |
| CN1435433A (zh) | 2002-08-30 | 2003-08-13 | 龚小迪 | 长效广谱的趋化因子受体抑制物 |
| AU2002951346A0 (en) | 2002-09-05 | 2002-09-26 | Garvan Institute Of Medical Research | Diagnosis of ovarian cancer |
| WO2004031233A2 (en) | 2002-10-04 | 2004-04-15 | Applied Research Systems Ars Holding N.V. | Novel chemokine-like polypeptides |
| US7595430B2 (en) * | 2002-10-30 | 2009-09-29 | University Of Kentucky Research Foundation | Methods and animal model for analyzing age-related macular degeneration |
| AU2003284357A1 (en) * | 2002-11-01 | 2004-06-07 | Genentech, Inc. | Compositions and methods for the treatment of immune related diseases |
| US20040157253A1 (en) * | 2003-02-07 | 2004-08-12 | Millennium Pharmaceuticals, Inc. | Methods and compositions for use of inflammatory proteins in the diagnosis and treatment of metabolic disorders |
| WO2004078777A2 (en) | 2003-03-04 | 2004-09-16 | Biorexis Pharmaceutical Corporation | Dipeptidyl-peptidase protected proteins |
| US7749714B2 (en) | 2003-03-12 | 2010-07-06 | Rappaport Family Institute For Research In The Medical Sciences | Compositions and methods for diagnosing and treating prostate cancer |
| WO2004092368A1 (ja) | 2003-03-13 | 2004-10-28 | Banyu Pharmaceutical Co., Ltd. | 肥満又は痩せの検査方法 |
| JP2004307427A (ja) | 2003-04-10 | 2004-11-04 | Kensuke Egashira | 腎虚血再灌流傷害の治療・改善・予防剤 |
| EP1473304A1 (de) | 2003-05-02 | 2004-11-03 | BOEHRINGER INGELHEIM PHARMA GMBH & CO. KG | Verfahren zur Herstellung eines N-terminal modifizierten chemotaktischen Faktors |
| ATE462432T1 (de) * | 2003-05-05 | 2010-04-15 | Probiodrug Ag | Glutaminylcyclase-hemmer |
| KR20110059664A (ko) * | 2003-05-05 | 2011-06-02 | 프로비오드룩 아게 | 글루타미닐 및 글루타메이트 사이클라제의 이펙터의 용도 |
| WO2004113522A1 (en) | 2003-06-18 | 2004-12-29 | Direvo Biotech Ag | New biological entities and the pharmaceutical or diagnostic use thereof |
| US20090111146A1 (en) * | 2003-09-02 | 2009-04-30 | National Institute Of Advanced Industrial Science | Antibody Drug |
| AR046594A1 (es) * | 2003-10-16 | 2005-12-14 | Applied Research Systems | Usos terapeuticos de variantes de quemoquina |
| CA2544924A1 (en) * | 2003-11-05 | 2005-05-19 | Centocor, Inc. | Methods and compositions for treating mcp-1 related pathologies |
-
2006
- 2006-08-10 US US11/502,064 patent/US7713521B2/en not_active Expired - Fee Related
- 2006-08-10 WO PCT/US2006/031155 patent/WO2007021807A1/en active Application Filing
- 2006-08-10 CN CNA2006800374431A patent/CN101443357A/zh active Pending
- 2006-08-10 CA CA002618951A patent/CA2618951A1/en not_active Abandoned
- 2006-08-10 EP EP06801106A patent/EP1926747A1/en not_active Withdrawn
- 2006-08-10 AU AU2006280004A patent/AU2006280004A1/en not_active Abandoned
- 2006-08-10 MX MX2008002101A patent/MX2008002101A/es active IP Right Grant
- 2006-08-11 KR KR1020087004698A patent/KR20080045158A/ko not_active Application Discontinuation
- 2006-08-11 JP JP2008526188A patent/JP2009504158A/ja active Pending
-
2008
- 2008-02-10 IL IL189414A patent/IL189414A0/en unknown
- 2008-02-18 ZA ZA200801606A patent/ZA200801606B/xx unknown
- 2008-03-11 NO NO20081294A patent/NO20081294L/no unknown
- 2008-06-17 JP JP2008158568A patent/JP2008239633A/ja not_active Withdrawn
-
2009
- 2009-11-18 US US12/621,228 patent/US7972591B2/en not_active Expired - Fee Related
-
2011
- 2011-05-02 US US13/098,641 patent/US8282914B2/en not_active Expired - Fee Related
Cited By (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9493531B2 (en) | 2011-06-01 | 2016-11-15 | Jyant Technologies, Inc. | Chemokine-immunoglobulin fusion polypeptides, compositions, method of making and use thereof |
| US9249204B2 (en) | 2011-06-01 | 2016-02-02 | Jyant Technologies, Inc. | Chemokine-immunoglobulin fusion polypeptides, compositions, method of making and use thereof |
| CN108219001A (zh) * | 2011-06-01 | 2018-06-29 | 吉安特科技公司 | 趋化因子-免疫球蛋白融合多肽、组合物及其制备和使用方法 |
| US9783588B2 (en) | 2011-06-01 | 2017-10-10 | Jyant Technologies, Inc. | Chemokine-immunoglobulin fusion polypeptides, compositions, method of making and use thereof |
| CN103857406A (zh) * | 2011-06-01 | 2014-06-11 | 莫尔豪斯医学院 | 趋化因子-免疫球蛋白融合多肽、组合物及其制备和使用方法 |
| CN105944086B (zh) * | 2016-06-13 | 2017-08-25 | 浙江生创精准医疗科技有限公司 | Il‑8单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN105944082A (zh) * | 2016-06-13 | 2016-09-21 | 浙江生创精准医疗科技有限公司 | 骨保护素单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN105944085A (zh) * | 2016-06-13 | 2016-09-21 | 浙江生创精准医疗科技有限公司 | Il-6单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN105944086A (zh) * | 2016-06-13 | 2016-09-21 | 浙江生创精准医疗科技有限公司 | Il-8单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN105944082B (zh) * | 2016-06-13 | 2017-08-25 | 浙江生创精准医疗科技有限公司 | 骨保护素单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN105920579A (zh) * | 2016-06-13 | 2016-09-07 | 浙江生创精准医疗科技有限公司 | Gro单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN105920585A (zh) * | 2016-06-13 | 2016-09-07 | 浙江生创精准医疗科技有限公司 | Mcp-1单独或与其他细胞因子联合在治疗肝纤维化中的用途 |
| CN114796264A (zh) * | 2021-01-27 | 2022-07-29 | 北京北工大科技园有限公司 | 金络合物在制备治疗新型冠状病毒肺炎的药物中的应用 |
| WO2022160327A1 (zh) * | 2021-01-27 | 2022-08-04 | 北京工业大学 | 金络合物在制备治疗新型冠状病毒肺炎的药物中的应用 |
| WO2023016284A1 (zh) * | 2021-08-11 | 2023-02-16 | 南京北恒生物科技有限公司 | 工程化免疫细胞及其用途 |
| CN115192584A (zh) * | 2022-06-09 | 2022-10-18 | 南方科技大学 | 一种纳米药物及其制备方法和应用 |
Also Published As
| Publication number | Publication date |
|---|---|
| ZA200801606B (en) | 2010-07-28 |
| US20110206669A1 (en) | 2011-08-25 |
| KR20080045158A (ko) | 2008-05-22 |
| US7972591B2 (en) | 2011-07-05 |
| US20070036750A1 (en) | 2007-02-15 |
| US8282914B2 (en) | 2012-10-09 |
| US7713521B2 (en) | 2010-05-11 |
| IL189414A0 (en) | 2008-06-05 |
| MX2008002101A (es) | 2008-04-19 |
| AU2006280004A1 (en) | 2007-02-22 |
| EP1926747A1 (en) | 2008-06-04 |
| WO2007021807A1 (en) | 2007-02-22 |
| WO2007021807A8 (en) | 2008-06-05 |
| JP2009504158A (ja) | 2009-02-05 |
| JP2008239633A (ja) | 2008-10-09 |
| CA2618951A1 (en) | 2007-02-22 |
| US20100172904A1 (en) | 2010-07-08 |
| NO20081294L (no) | 2008-05-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN101443357A (zh) | Mcp1融合物 | |
| US8524217B2 (en) | MCP1-Ig fusion variants | |
| ES2149772T5 (es) | Receptores humanos pf4a y su utilizacion. | |
| De Souza et al. | SH2 domains from suppressor of cytokine signaling-3 and protein tyrosine phosphatase SHP-2 have similar binding specificities | |
| JP3902728B2 (ja) | レセプターに基づくアンタゴニストならびに作製および使用の方法 | |
| US5840869A (en) | DNA encoding interleukin-4 receptors | |
| JP6480970B2 (ja) | デュアルv領域抗体様タンパク質の使用 | |
| BRPI0111191B1 (pt) | moléculas mutantes de ctla4 solúveis, método para sua produção e seus usos | |
| LT5063B (lt) | Tirpi ctla4 molekulė, skirta reumatinių ligų gydymui | |
| US8058397B2 (en) | Family of immunoregulators designated leukocyte immunoglobulin-like receptors (LIR) | |
| Chevigné et al. | Engineering and screening the N-terminus of chemokines for drug discovery | |
| JP3749529B2 (ja) | セレクチン変異体 | |
| US20030166073A1 (en) | Family of immunoregulators designated leukocyte immunoglobulin-like receptors (LIR) | |
| CN110506050A (zh) | γC细胞因子活性的稳定调节剂 | |
| CA2208016A1 (en) | Anti-inflammatory cd14 peptides | |
| US9561274B2 (en) | Treatment and prevention of cancer with HMGB1 antagonists | |
| SK287523B6 (sk) | Použitie CC chemokínového mutanta, farmaceutický prostriedok s obsahom chemokínového mutanta, skrátený a mutovaný humánny RANTES a spôsob jeho výroby | |
| Giblin et al. | CXCL17 binds efficaciously to glycosaminoglycans with the potential to modulate chemokine signaling | |
| KR20030036835A (ko) | Ige 수용체 길항제 | |
| EP2007815A2 (en) | Mono- and bifunctional molecules with ability to bind to g protein-coupled receptors | |
| EA010420B1 (ru) | Молекулы-антагонисты цитокинов | |
| Strong et al. | Synthetic chemokines directly labeled with a fluorescent dye as tools for studying chemokine and chemokine receptor interactions | |
| WO2023120643A1 (ja) | Cxcr3発現細胞遊走活性が増強したcxcr3リガンド。 | |
| WO2003087157A9 (en) | Differentially expressed genes involved in angiogenesis, the proteins encoded thereby, and methods of using the same | |
| GB2626983A (en) | Protein |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C02 | Deemed withdrawal of patent application after publication (patent law 2001) | ||
| WD01 | Invention patent application deemed withdrawn after publication |
Open date: 20090527 |