Lasso Versus Ridge Versus Elastic Net
Linear Regression
Linear regression describes the relationship between a dependent variable and an independent variable. Think of this as an X variable and a Y variable.
What are some assumptions of a linear regression model?
The relationship between the two variables is linear.
All variables are multivariate normal.
There isn’t much multicollinearity among the dependent variables. A good way to test this is variance inflation.
There is little to no autocorrelation in the data. If you are unfamiliar with autocorrelation, autocorrelation occurs when the residuals of the variables in the model are not independent of each other.
There is homoscedasticity. That is, the size of the error does not vary by the sizes of the independent variables. The error does not increase substantially if your variables get larger or smaller.
The residuals of the linear regression should be normally distributed around a mean of 0.
What are some approaches to solving this problem?
We want to find a line that best captures the essence of the data provided. Why? In the context of machine learning, we want to find a line that predicts the values of Y based upon values of X. The two variables to measure the effectiveness of your model are bias and variance.
Bias- the error or difference between points provided and points captured on your line in your training set
Variance- error from sensitivity to small fluctuations in the training set
Underfit Model
We can find a line that captures a general direction but does not capture many of the points. Since it does not capture many of the points well, it has a high bias or high error. Since it does not grasp many of the points in the graph, it also has a low variance. This would be called an underfit model.
Good Fit Model
We can find a line that captures the general direction of the points but might not capture every point in the graph. This would be a good fit model.
Overfit Model
Lastly, we can find a line that captures every single point in the graph. This would be called an overfit model.
Below are good images to describe the differences in models.
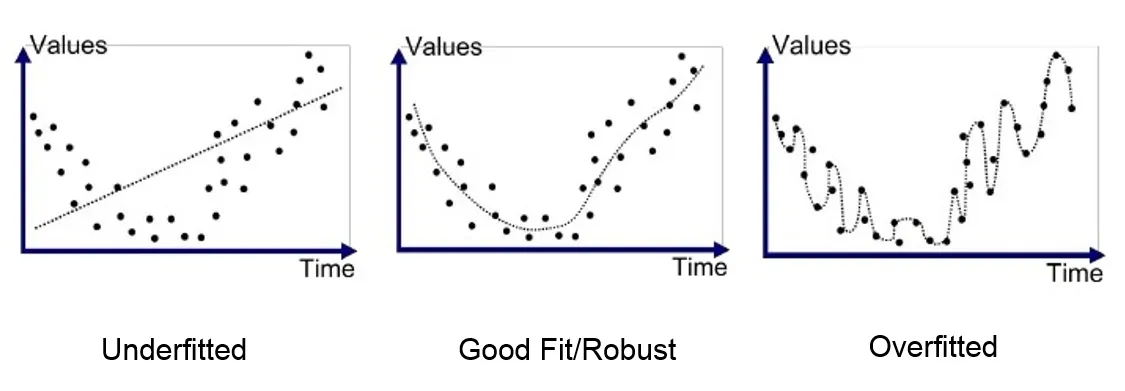
Bias-Variance Trade-off
This situation above describes the bias-variance tradeoff. Bias measures the error between what the model captures and what the available data is showing. Variance is the error from sensitivity to small fluctuations in the available data. That is, a model with high variance effectively captures random noise in the available data rather than the intended outputs. We ideally want to find a line that has low bias and low variance.

Why would a line with high variance be a bad thing?
After all, wouldn’t a line that captures every point be the ideal line? Sadly no. This line captures the peculiar nuances of the sample data well but it will not necessarily perform as well on unseen data. These nuances of the sample data are the outliers and other unique characteristics of the sample data, characteristics that might not be very true on unseen data.
What are some solutions to prevent overfitting on sample data?
While there are a number of solutions to prevent or reduce overfitting on sample data, in this article I will talk about Lasso, Ridge, and Elastic Net.
Reducing Overfit with regularization
Lasso, Ridge, and Elastic Net models are forms of regularized linear techniques found in General Linear Models.
Why is regularization important?
Regularization favors simpler models to more complex models to prevent your model from overfitting to the data. How so? They address the following concerns within a model: variance-bias tradeoff, multicollinearity, sparse data handling(i.e. the situation where there are more observations than features), feature selection, and an easier interpretation of the output.
Lasso
Lasso stands for Least Absolute Shrinkage Selector Operator. Lasso assigns a penalty to the coefficients in the linear model using the formula below and eliminates variables with coefficients that zero. This is called shrinkage or the process where data values are shrunk to a central point such as a mean.
Lasso Formula: Lasso = Sum of Error + Sum of the absolute value of coefficients
L = ∑( Ŷi– Yi)² + λ∑ |β|
Looking at the formula, Lasso adds a penalty equal to the absolute value of the magnitude of the coefficients multiplied by lambda. The value of lambda also plays a key role in how much weight you assign to the penalty for the coefficients. This penalty reduces the value of many coefficients to zero, all of which are eliminated.
What is the significance of adding a penalty to coefficients in lasso?
Lasso adds a penalty to coefficients the model overemphasizes. This reduces the degree of overfitting that occurs within the model.
What are some limitations of the Lasso model?
Lasso does not work well with multicollinearity. If you are unfamiliar, multicollinearity occurs when some of the dependent variables are correlated with each other. Why? Lasso might randomly choose one of the multicollinear variables without understanding the context. Such an action might eliminate relevant independent variables.
Ridge
Ridge assigns a penalty that is the squared magnitude of the coefficients to the loss function multiplied by lambda. As Lasso does, ridge also adds a penalty to coefficients the model overemphasizes. The value of lambda also plays a key role in how much weight you assign to the penalty for the coefficients. The larger your value of lambda, the more likely your coefficients get closer and closer to zero. Unlike lasso, the ridge model will not shrink these coefficients to zero.
Ridge Formula: Sum of Error + Sum of the squares of coefficients
L = ∑( Ŷi– Yi)² + λ∑ β²
What are some limitations of Ridge?
Ridge does not eliminate coefficients in your model even if the variables are irrelevant. This can be negative if you have more features than observations.
Elastic Net
Elastic Net combines characteristics of both lasso and ridge. Elastic Net reduces the impact of different features while not eliminating all of the features.
The formula as you can see below is the sum of the lasso and ridge formulas.
Elastic Net Formula: Ridge + Lasso
L = ∑( Ŷi– Yi)² + λ∑ β² + λ∑ |β|
To conclude, Lasso, Ridge, and Elastic Net are excellent methods to improve the performance of your linear model. This includes if you are running a neural network, a collection of linear models. Lasso will eliminate many features, and reduce overfitting in your linear model. Ridge will reduce the impact of features that are not important in predicting your y values. Elastic Net combines feature elimination from Lasso and feature coefficient reduction from the Ridge model to improve your model’s predictions.