jdk17
javafx-sdk-20 refer to https://openjfx.io/openjfx-docs/#introduction
Stack BackTrace for C++: https://github.com/NEWPLAN/newplan_toolkit/backtrace
EMMA Coverage Tool: https://emma.sourceforge.net/
transformers == 4.30.2
torch == 1.12.1
- Please find the data noise breakdown here:
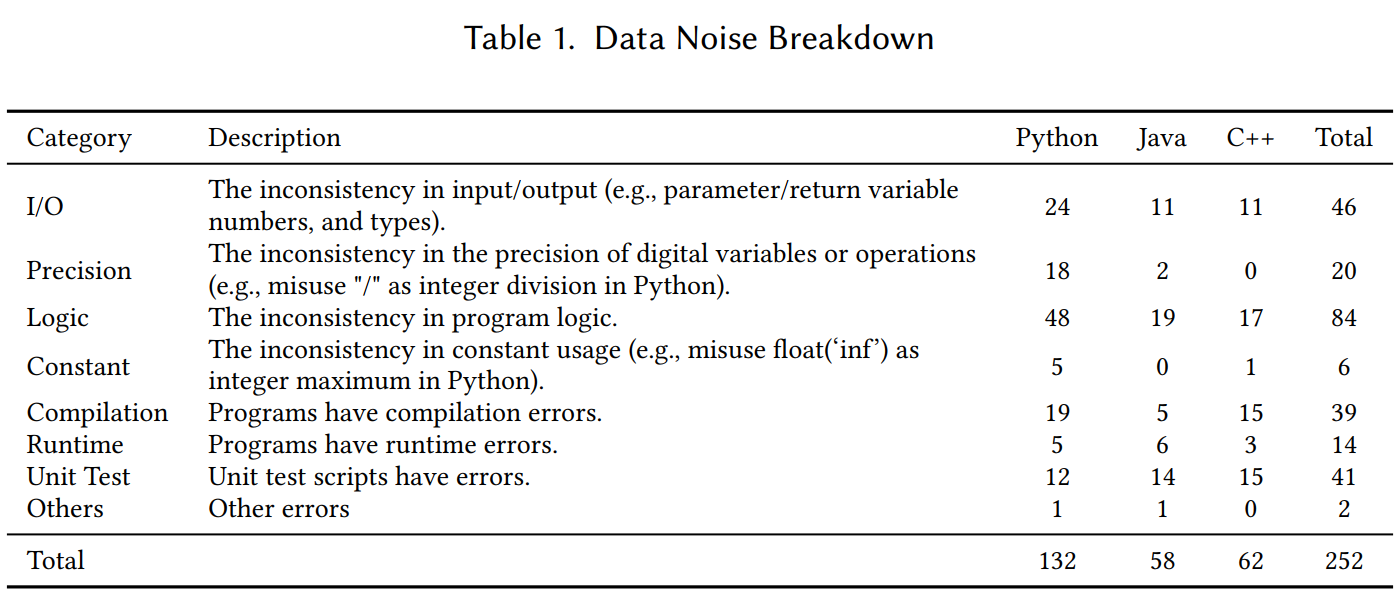
- Please find the tmp.java file here: tmp.pdf.
- Please find the statistical test results here: statistical test.pdf.
- Please find the OJ experimental results in the folder
oj_samples, which is reported in the threats to validity section.

./cleaned_data/testable_samples.jsonl: cleaned dataset used in this work, including parallel functions of Java, Python, and C++../cleaned_data/transcoder_evaluation_gfg: test cases associated with the cleaned dataset.
-
Test Case Generation Phase
- generate inputs with LLMs (taking GPT3.5 as an example)
python gpt3_5.py --dst_lang ${dst_lang} --obj 0 --k ${test_case_num} --k ${sample_k}- collect test cases
python process_valid_inputs.py --model ${model_name} --dst_lang ${dst_lang} -
Translation Augmentation Phase
- translation augmentation (taking GPT3.5 as an example)
python gpt3_5.py --src_lang ${src_lang} --dst_lang ${dst_lang} --obj 3 --k ${sample_k} --test_case_num ${test_case_num}- post-process translated programs.
python process_translation.py --src_lang ${src_lang} --dst_lang ${dst_lang} --suffix ${suffix}- translation evaluation
python fetch_feedbacks.py --model ${model_name} --src_lang ${src_lang} --dst_lang ${dst_lang} --test_case_num ${test_case_num} round ${round} -
Translation Repair Phase
- error info analysis
python process_feedbacks.py --src_lang ${src_lang} --dst_lang ${dst_lang} --round ${round} --test_case_num ${test_case_num}- program repair
python gpt3_5.py --src_lang ${src_lang} --dst_lang ${dst_lang} --obj 4 --k ${sample_k} --test_case_num ${test_case_num}- post-process repaired programs.
python process_translation.py --src_lang ${src_lang} --dst_lang ${dst_lang} --suffix ${suffix} -
Evaluation
- evaluation for computational accuracy
python evaluation_CA.py --model ${model_name} --src_lang ${src_lang} --dst_lang ${dst_lang} --k ${CA@k} --timeout ${timeout} --suffix ${suffix}- evaluation for exact match accuracy
python evaluation_EM.py --model ${model_name} --src_lang ${src_lang} --dst_lang ${dst_lang} --suffix ${suffix}