
Dagster is a cloud-native data pipeline orchestrator for the whole development lifecycle, with integrated lineage and observability, a declarative programming model, and best-in-class testability.
It is designed for developing and maintaining data assets, such as tables, data sets, machine learning models, and reports.
With Dagster, you declare—as Python functions—the data assets that you want to build. Dagster then helps you run your functions at the right time and keep your assets up-to-date.
Here is an example of a graph of three assets defined in Python:
from dagster import asset
from pandas import DataFrame, read_html, get_dummies
from sklearn.linear_model import LinearRegression
@asset
def country_populations() -> DataFrame:
df = read_html("https://tinyurl.com/mry64ebh")[0]
df.columns = ["country", "pop2022", "pop2023", "change", "continent", "region"]
df["change"] = df["change"].str.rstrip("%").str.replace("−", "-").astype("float")
return df
@asset
def continent_change_model(country_populations: DataFrame) -> LinearRegression:
data = country_populations.dropna(subset=["change"])
return LinearRegression().fit(get_dummies(data[["continent"]]), data["change"])
@asset
def continent_stats(country_populations: DataFrame, continent_change_model: LinearRegression) -> DataFrame:
result = country_populations.groupby("continent").sum()
result["pop_change_factor"] = continent_change_model.coef_
return resultThe graph loaded into Dagster's web UI:
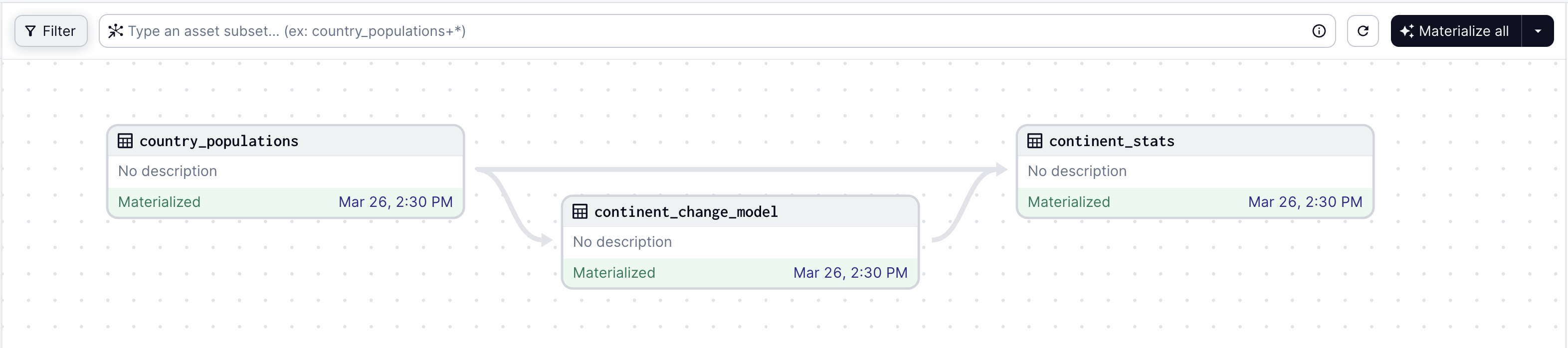
Dagster is built to be used at every stage of the data development lifecycle - local development, unit tests, integration tests, staging environments, all the way up to production.
If you're new to Dagster, we recommend reading about its core concepts or learning with the hands-on tutorial.
Dagster is available on PyPI and officially supports Python 3.8 through Python 3.12.
pip install dagster dagster-webserverThis installs two packages:
dagster: The core programming model.dagster-webserver: The server that hosts Dagster's web UI for developing and operating Dagster jobs and assets.
Running on Using a Mac with an Apple silicon chip? Check the install details here.
You can find the full Dagster documentation here, including the 'getting started' guide.

Identify the key assets you need to create using a declarative approach, or you can focus on running basic tasks. Embrace CI/CD best practices from the get-go: build reusable components, spot data quality issues, and flag bugs early.
Put your pipelines into production with a robust multi-tenant, multi-tool engine that scales technically and organizationally.
Maintain control over your data as the complexity scales. Centralize your metadata in one tool with built-in observability, diagnostics, cataloging, and lineage. Spot any issues and identify performance improvement opportunities.
Dagster provides a growing library of integrations for today’s most popular data tools. Integrate with the tools you already use, and deploy to your infrastructure.

Connect with thousands of other data practitioners building with Dagster. Share knowledge, get help, and contribute to the open-source project. To see featured material and upcoming events, check out our Dagster Community page.
Join our community here:
- 🌟 Star us on GitHub
- 📥 Subscribe to our Newsletter
- 🐦 Follow us on Twitter
- 🕴️ Follow us on LinkedIn
- 📺 Subscribe to our YouTube channel
- 📚 Read our blog posts
- 👋 Join us on Slack
- 🗃 Browse Slack archives
- ✏️ Start a GitHub Discussion
For details on contributing or running the project for development, check out our contributing guide.
Dagster is Apache 2.0 licensed.