(.+?)
.*",
"\\1", ifelse(grepl("First version publication date", wpText),
wpText, ""))),
format = "%d %b %Y")
tmpThisDate <- as.Date(trimws(
sub(".+This version publication date.*?(.+?)
.*",
"\\1", ifelse(grepl("This version publication date", wpText),
wpText, ""))),
format = "%d %b %Y")
tmpChanges <- trimws(
gsub("[ ]+", " ", gsub("[\n\r]", "", gsub("<[a-z/]+>", "", sub(
".+Version creation reas.*?- .
\");'", "php xml not found, ctrLoadQueryIntoDb() will not work "), "phpjson" = c("php -r 'json_encode(\"
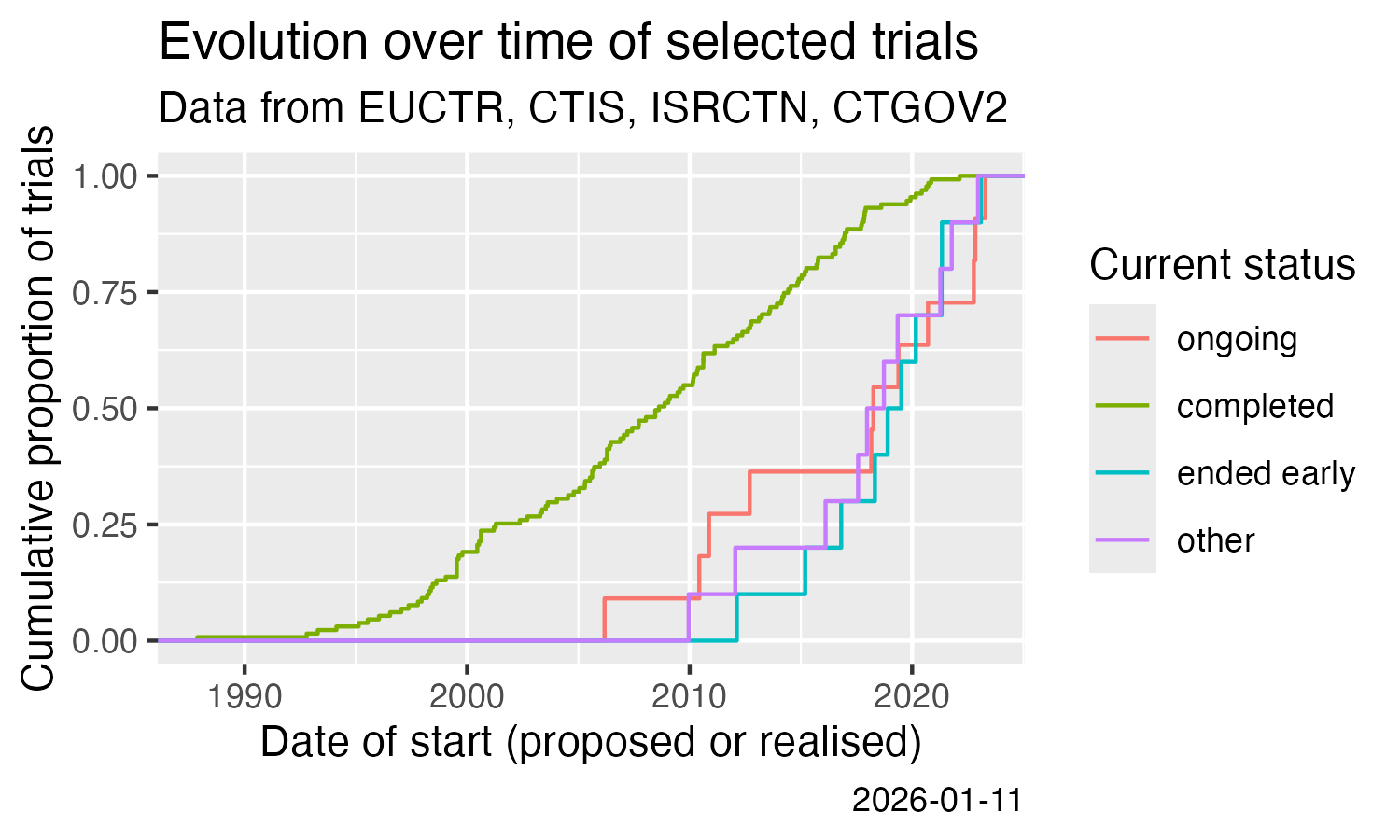
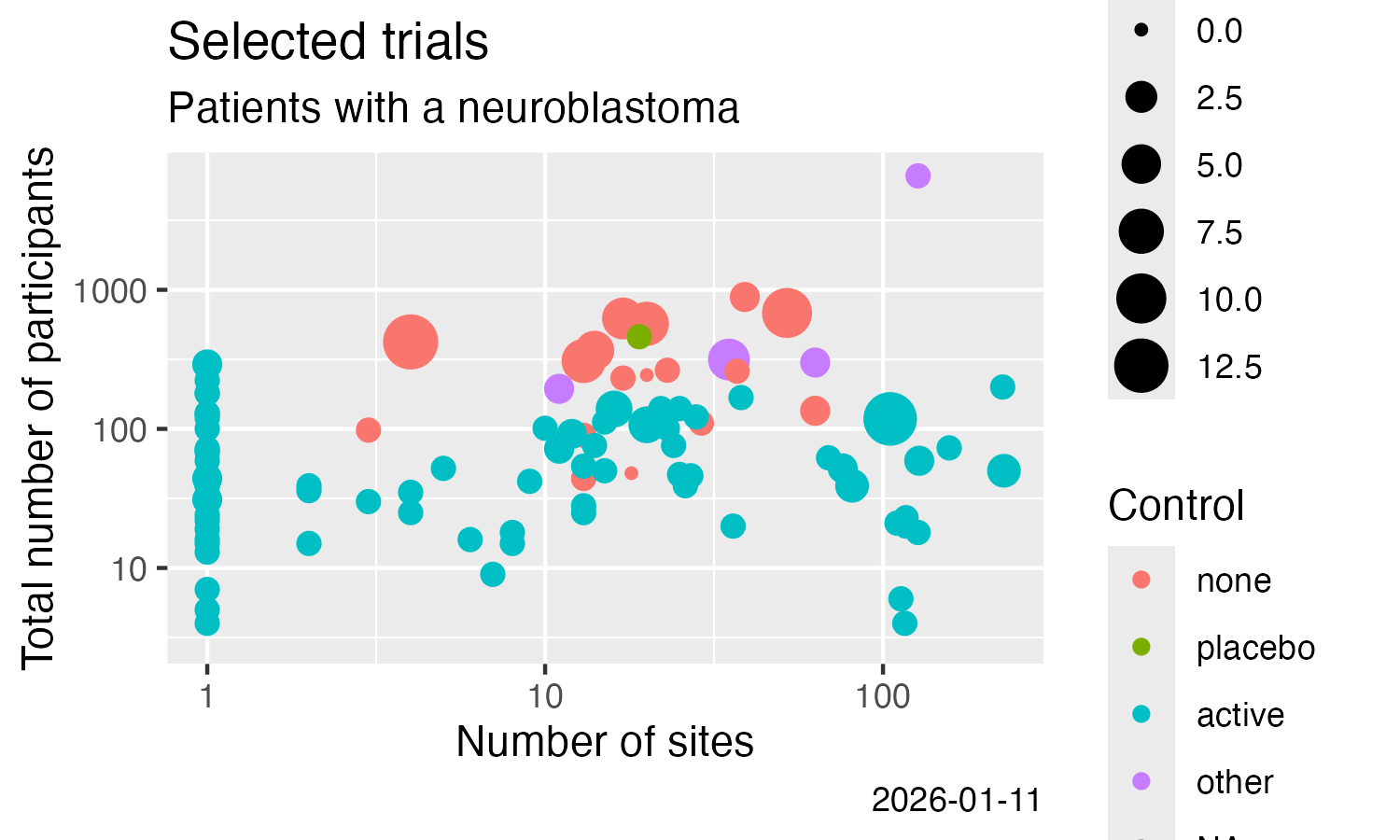
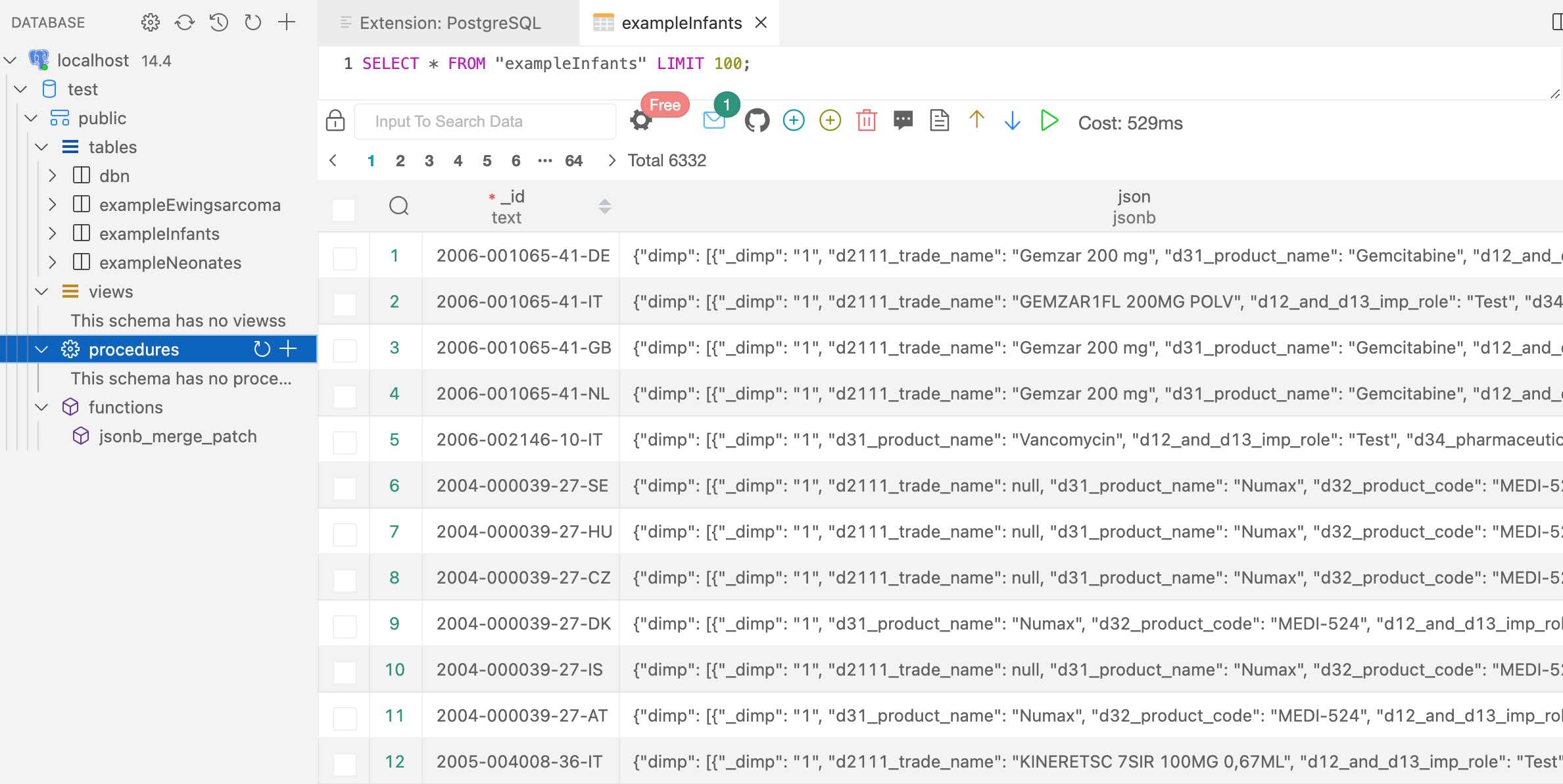
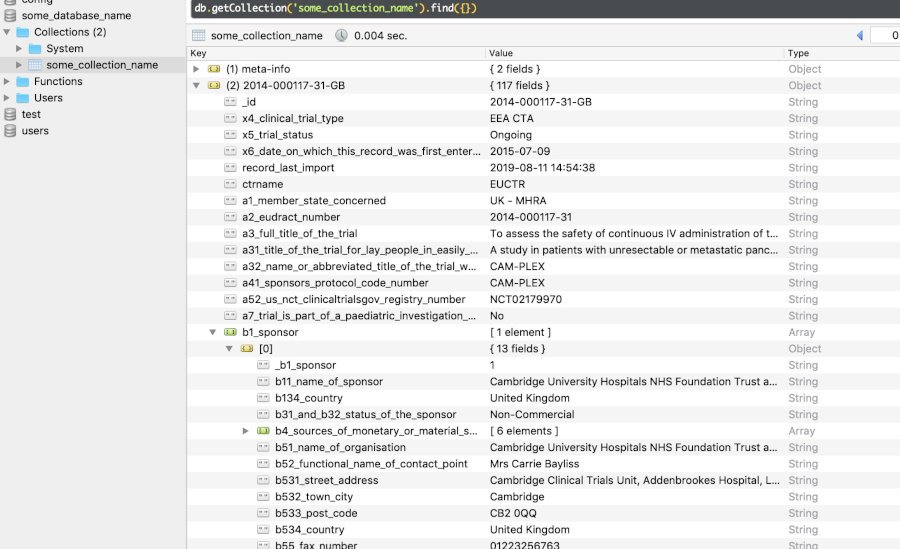
License
YEAR: 2017-2023 COPYRIGHT HOLDER: Ralf Herold
Copyright (c) 2023 Ralf Herold
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.