Search between the objects in an image, and cut the region of the detected object.
CLIP model was proposed by the OpenAI company, to understand the semantic similarity between images and texts.
It's used for preform zero-shot learning tasks, to find objects in an image based on an input query.
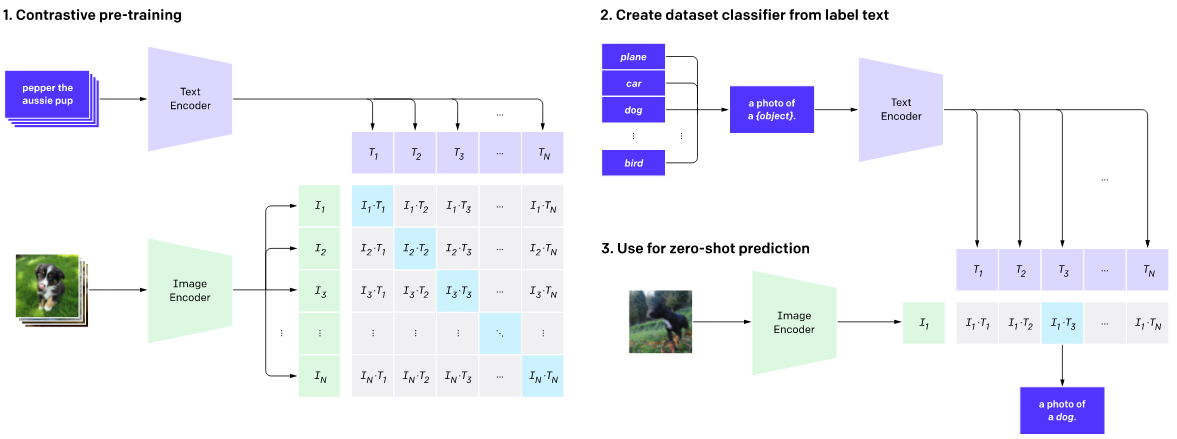
Also, YOLOv5 was used in the first step of the method, to detect the location of the objects in an image.
Demo is ready!
(Sometimes, the Streamlit website may crash! because models are heavy for it.)
Run this notebook on Google Colab and test on your images! (It works both on CPU and GPU)
Obviously object detector model only can find object classes learned from the COCO dataset. So if your results are not related to your query, maybe the object you want is not in the COCO classes.
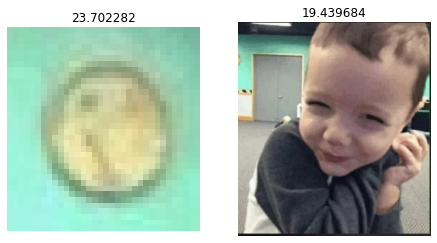
Sorted from left based on similarity.
Query: Clock

Query: wine glass


Query: woman with blue pants

