- NLU以及NLG各种任务的差异?
a. Self-Attention的表达式
b. 为什么上面那个公式要对QK进行scaling
scaling后进行softmax操作可以使得输入的数据的分布变得更好,你可以想象下softmax的公式,数值会进入敏感区间,防止梯度消失,让模型能够更容易训练。
c.self-attention一定要这样表达吗?
不一定,只要可以建模相关性就可以。当然,最好是能够高速计算(矩阵乘法),并且表达能力强(query可以主动去关注到其他的key并在value上进行强化,并且忽略不相关的其他部分),模型容量够(引入了project_q/k/v,att_out,多头)
e.为什么transformer用Layer Norm?有什么用?
任何norm的意义都是为了让使用norm的网络的输入的数据分布变得更好,也就是转换为标准正态分布,数值进入敏感度区间,以减缓梯度消失,从而更容易训练。
当然,这也意味着舍弃了除此维度之外其他维度的其他信息。为什么能舍弃呢?请看下一题。
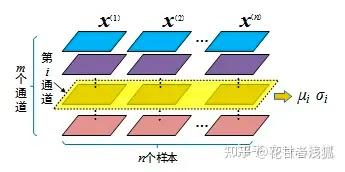
f.为什么不用BN?
首先要明确,如果在一个维度内进行normalization,那么在这个维度内,相对大小有意义的,是可以比较的; 但是在normalization后的不同的维度之间,相对大小这是没有意义的
i.transformer为什么要用三个不一样的QKV?
前面提到过,是为了增强网络的容量和表达能力。更极端点,如果完全不要project_q/k/v,就是输入x本身来做,当然可以,但是表征能力太弱了(x的参数更新得至少会很拧巴)
j.为什么要多头?
举例说明多头相比单头注意力的优势和上一问一样,进一步增强网络的容量和表达能力。你可以类比CV中的不同的channel(不同卷积核)会关注不同的信息,事实上不同的头也会关注不同的信息。