KTransformers is a flexible, Python-centric framework designed with extensibility at its core. By implementing and injecting an optimized module with a single line of code, users gain access to a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and even a simplified ChatGPT-like web UI.
Our vision for KTransformers is to serve as a flexible platform for experimenting with innovative LLM inference optimizations. Please let us know if you need any other features.
- Aug 28, 2024: Support 1M context under the InternLM2.5-7B-Chat-1M model, utilizing 24GB of VRAM and 150GB of DRAM. The detailed tutorial is here.
- Aug 28, 2024: Decrease DeepseekV2's required VRAM from 21G to 11G.
- Aug 15, 2024: Update detailed TUTORIAL for injection and multi-GPU.
- Aug 14, 2024: Support llamfile as linear backend.
- Aug 12, 2024: Support multiple GPU; Support new model: mixtral 8*7B and 8*22B; Support q2k, q3k, q5k dequant on gpu.
- Aug 9, 2024: Support windows native.
Ktransformers.long.context.mp4
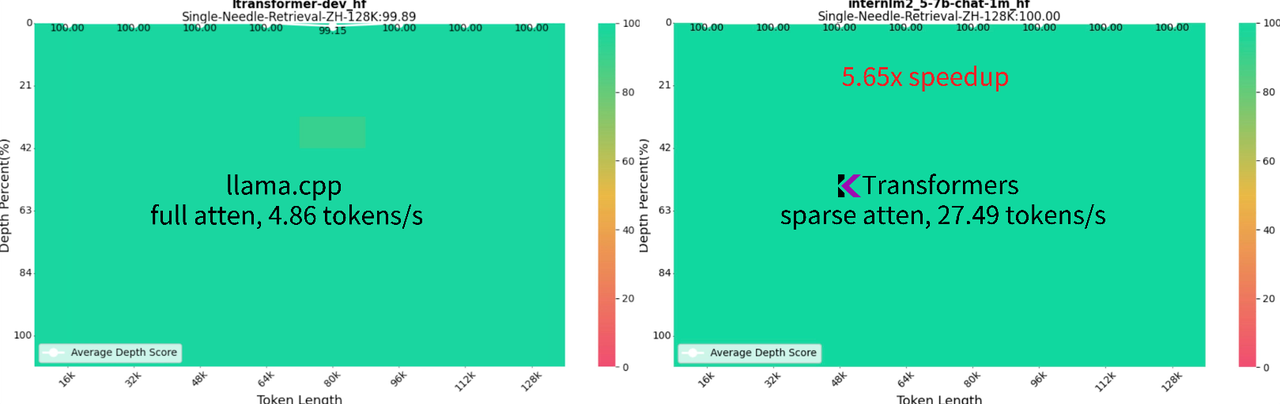
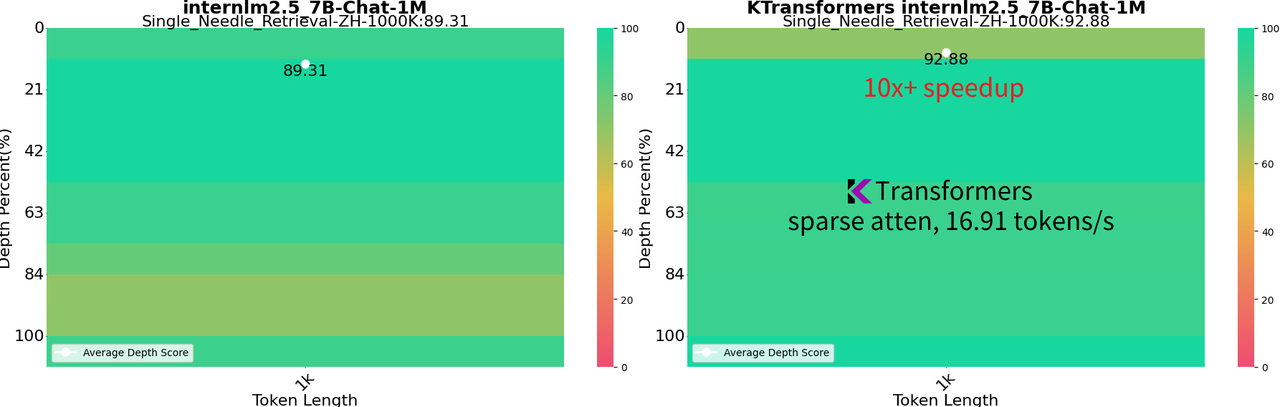
- 1M Context InternLM 2.5 7B: Operates at full bf16 precision, utilizing 24GB VRAM and 150GB DRAM, which is feasible on a local desktop setup. It achieves a 92.88% success rate on the 1M "Needle In a Haystack" test and 100% on the 128K NIAH test.
-
Enhanced Speed: Reaches 16.91 tokens/s for generation with a 1M context using sparse attention, powered by llamafile kernels. This method is over 10 times faster than full attention approach of llama.cpp.
-
Flexible Sparse Attention Framework: Offers a flexible block sparse attention framework for CPU offloaded decoding. Compatible with SnapKV, Quest, and InfLLm. Further information is available here.
ktransformers_vs_llama.cpp.mp4
- Local 236B DeepSeek-Coder-V2: Running its Q4_K_M version using only 21GB VRAM and 136GB DRAM, attainable on a local desktop machine, which scores even better than GPT4-0613 in BigCodeBench.
- Faster Speed: Achieving 126 tokens/s for 2K prompt prefill and 13.6 tokens/s for generation through MoE offloading and injecting advanced kernels from Llamafile and Marlin.
- VSCode Integration: Wrapped into an OpenAI and Ollama compatible API for seamless integration as a backend for Tabby and various other frontends.
ktransformers-tabby.mp4
More advanced features will coming soon, so stay tuned!
Some preparation:-
CUDA 12.1 and above, if you didn't have it yet, you may install from here.
# Adding CUDA to PATH export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH export CUDA_PATH=/usr/local/cuda
-
Linux-x86_64 with gcc, g++ and cmake
sudo apt-get update sudo apt-get install gcc g++ cmake ninja-build
-
We recommend using Conda to create a virtual environment with Python=3.11 to run our program.
conda create --name ktransformers python=3.11 conda activate ktransformers # you may need to run ‘conda init’ and reopen shell first -
Make sure that PyTorch, packaging, ninja is installed
pip install torch packaging ninja
-
Use a Docker image, see documentation for Docker
-
You can install using Pypi (for linux):
pip install ktransformers --no-build-isolationfor windows we prepare a pre compiled whl package in ktransformers-0.1.1+cu125torch24avx2-cp311-cp311-win_amd64.whl, which require cuda-12.5, torch-2.4, python-3.11, more pre compiled package are being produced.
-
Or you can download source code and compile:
-
init source code
git clone https://github.com/kvcache-ai/ktransformers.git cd ktransformers git submodule init git submodule update -
[Optional] If you want to run with website, please compile the website before execute
bash install.sh -
Compile and install (for Linux)
bash install.sh -
Compile and install(for Windows)
install.bat
-
-
If you are developer, you can make use of the makefile to compile and format the code.
the detailed usage of makefile is here
Note that this is a very simple test tool only support one round chat without any memory about last input, if you want to try full ability of the model, you may go to RESTful API and Web UI. We use the DeepSeek-V2-Lite-Chat-GGUF model as an example here. But we also support other models, you can replace it with any other model that you want to test.
# Begin from root of your cloned repo!
# Begin from root of your cloned repo!!
# Begin from root of your cloned repo!!!
# Download mzwing/DeepSeek-V2-Lite-Chat-GGUF from huggingface
mkdir DeepSeek-V2-Lite-Chat-GGUF
cd DeepSeek-V2-Lite-Chat-GGUF
wget https://huggingface.co/mzwing/DeepSeek-V2-Lite-Chat-GGUF/resolve/main/DeepSeek-V2-Lite-Chat.Q4_K_M.gguf -O DeepSeek-V2-Lite-Chat.Q4_K_M.gguf
cd .. # Move to repo's root dir
# Start local chat
python -m ktransformers.local_chat --model_path deepseek-ai/DeepSeek-V2-Lite-Chat --gguf_path ./DeepSeek-V2-Lite-Chat-GGUF
# If you see “OSError: We couldn't connect to 'https://huggingface.co' to load this file”, try:
# GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/DeepSeek-V2-Lite
# python ktransformers.local_chat --model_path ./DeepSeek-V2-Lite --gguf_path ./DeepSeek-V2-Lite-Chat-GGUFIt features the following arguments:
-
--model_path(required): Name of the model (such as "deepseek-ai/DeepSeek-V2-Lite-Chat" which will automatically download configs from Hugging Face). Or if you already got local files you may directly use that path to initialize the model.Note: .safetensors files are not required in the directory. We only need config files to build model and tokenizer.
-
--gguf_path(required): Path of a directory containing GGUF files which could that can be downloaded from Hugging Face. -
--optimize_rule_path(required except for Qwen2Moe and DeepSeek-V2): Path of YAML file containing optimize rules. There are two rule files pre-written in the ktransformers/optimize/optimize_rules directory for optimizing DeepSeek-V2 and Qwen2-57B-A14, two SOTA MoE models. -
--max_new_tokens: Int (default=1000). Maximum number of new tokens to generate. -
--cpu_infer: Int (default=10). The number of CPUs used for inference. Should ideally be set to the (total number of cores - 2).
| Model Name | Model Size | VRAM | Minimum DRAM | Recommended DRAM |
|---|---|---|---|---|
| DeepSeek-V2-q4_k_m | 133G | 11G | 136G | 192G |
| DeepSeek-V2.5-q4_k_m | 133G | 11G | 136G | 192G |
| DeepSeek-V2.5-IQ4_XS | 117G | 10G | 107G | 128G |
| Qwen2-57B-A14B-Instruct-q4_k_m | 33G | 8G | 34G | 64G |
| DeepSeek-V2-Lite-q4_k_m | 9.7G | 3G | 13G | 16G |
| Mixtral-8x7B-q4_k_m | 25G | 1.6G | 51G | 64G |
| Mixtral-8x22B-q4_k_m | 80G | 4G | 86.1G | 96G |
| InternLM2.5-7B-Chat-1M | 15.5G | 15.5G | 8G(32K context) | 150G (1M context) |
More will come soon. Please let us know which models you are most interested in.
Be aware that you need to be subject to their corresponding model licenses when using DeepSeek and QWen.
Click To Show how to run other examples
-
Qwen2-57B
pip install flash_attn # For Qwen2 mkdir Qwen2-57B-GGUF && cd Qwen2-57B-GGUF wget https://huggingface.co/Qwen/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/qwen2-57b-a14b-instruct-q4_k_m.gguf?download=true -O qwen2-57b-a14b-instruct-q4_k_m.gguf cd .. python -m ktransformers.local_chat --model_name Qwen/Qwen2-57B-A14B-Instruct --gguf_path ./Qwen2-57B-GGUF # If you see “OSError: We couldn't connect to 'https://huggingface.co' to load this file”, try: # GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/Qwen/Qwen2-57B-A14B-Instruct # python ktransformers/local_chat.py --model_path ./Qwen2-57B-A14B-Instruct --gguf_path ./DeepSeek-V2-Lite-Chat-GGUF
-
DeepseekV2
mkdir DeepSeek-V2-Chat-0628-GGUF && cd DeepSeek-V2-Chat-0628-GGUF # Download weights wget https://huggingface.co/bartowski/DeepSeek-V2-Chat-0628-GGUF/resolve/main/DeepSeek-V2-Chat-0628-Q4_K_M/DeepSeek-V2-Chat-0628-Q4_K_M-00001-of-00004.gguf -o DeepSeek-V2-Chat-0628-Q4_K_M-00001-of-00004.gguf wget https://huggingface.co/bartowski/DeepSeek-V2-Chat-0628-GGUF/resolve/main/DeepSeek-V2-Chat-0628-Q4_K_M/DeepSeek-V2-Chat-0628-Q4_K_M-00002-of-00004.gguf -o DeepSeek-V2-Chat-0628-Q4_K_M-00002-of-00004.gguf wget https://huggingface.co/bartowski/DeepSeek-V2-Chat-0628-GGUF/resolve/main/DeepSeek-V2-Chat-0628-Q4_K_M/DeepSeek-V2-Chat-0628-Q4_K_M-00003-of-00004.gguf -o DeepSeek-V2-Chat-0628-Q4_K_M-00003-of-00004.gguf wget https://huggingface.co/bartowski/DeepSeek-V2-Chat-0628-GGUF/resolve/main/DeepSeek-V2-Chat-0628-Q4_K_M/DeepSeek-V2-Chat-0628-Q4_K_M-00004-of-00004.gguf -o DeepSeek-V2-Chat-0628-Q4_K_M-00004-of-00004.gguf cd .. python -m ktransformers.local_chat --model_name deepseek-ai/DeepSeek-V2-Chat-0628 --gguf_path ./DeepSeek-V2-Chat-0628-GGUF # If you see “OSError: We couldn't connect to 'https://huggingface.co' to load this file”, try: # GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/DeepSeek-V2-Chat-0628 # python -m ktransformers.local_chat --model_path ./DeepSeek-V2-Chat-0628 --gguf_path ./DeepSeek-V2-Chat-0628-GGUF
| model name | weights download link |
|---|---|
| Qwen2-57B | Qwen2-57B-A14B-gguf-Q4K-M |
| DeepseekV2-coder | DeepSeek-Coder-V2-Instruct-gguf-Q4K-M |
| DeepseekV2-chat | DeepSeek-V2-Chat-gguf-Q4K-M |
| DeepseekV2-lite | DeepSeek-V2-Lite-Chat-GGUF-Q4K-M |
Start without website:
ktransformers --model_path deepseek-ai/DeepSeek-V2-Lite-Chat --gguf_path /path/to/DeepSeek-V2-Lite-Chat-GGUF --port 10002Start with website:
ktransformers --model_path deepseek-ai/DeepSeek-V2-Lite-Chat --gguf_path /path/to/DeepSeek-V2-Lite-Chat-GGUF --port 10002 --web TrueOr you want to start server with transformers, the model_path should include safetensors
ktransformers --type transformers --model_path /mnt/data/model/Qwen2-0.5B-Instruct --port 10002 --web TrueAccess website with url https://localhost:10002/web/index.html#/chat :
More information about the RESTful API server can be found here. You can also find an example of integrating with Tabby here.
At the heart of KTransformers is a user-friendly, template-based injection framework. This allows researchers to easily replace original torch modules with optimized variants. It also simplifies the process of combining multiple optimizations, allowing the exploration of their synergistic effects.
Given that vLLM already serves as a great framework for large-scale deployment optimizations, KTransformers is particularly focused on local deployments that are constrained by limited resources. We pay special attention to heterogeneous computing opportunities, such as GPU/CPU offloading of quantized models. For example, we support the efficient Llamafile and Marlin kernels for CPU and GPU, respectively. More details can be found here.
To utilize the provided kernels, users only need to create a YAML-based injection template and add the call to `optimize_and_load_gguf` before using the Transformers model.with torch.device("meta"):
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)
optimize_and_load_gguf(model, optimize_rule_path, gguf_path, config)
...
generated = prefill_and_generate(model, tokenizer, input_tensor.cuda(), max_new_tokens=1000)In this example, the AutoModel is first initialized on the meta device to avoid occupying any memory resources. Then, optimize_and_load_gguf iterates through all sub-modules of the model, matches rules specified in your YAML rule file, and replaces them with advanced modules as specified.
After injection, the original generate interface is available, but we also provide a compatible prefill_and_generate method, which enables further optimizations like CUDAGraph to improve generation speed.
A detailed tutorial of the injection and multi-GPU using DeepSeek-V2 as an example is given here.
Below is an example of a YAML template for replacing all original Linear modules with Marlin, an advanced 4-bit quantization kernel.
- match:
name: "^model\\.layers\\..*$" # regular expression
class: torch.nn.Linear # only match modules matching name and class simultaneously
replace:
class: ktransformers.operators.linear.KTransformerLinear # optimized Kernel on quantized data types
device: "cpu" # which devices to load this module when initializing
kwargs:
generate_device: "cuda"
generate_linear_type: "QuantizedLinearMarlin"Each rule in the YAML file has two parts: match and replace. The match part specifies which module should be replaced, and the replace part specifies the module to be injected into the model along with the initialization keywords.
You can find example rule templates for optimizing DeepSeek-V2 and Qwen2-57B-A14, two SOTA MoE models, in the ktransformers/optimize/optimize_rules directory. These templates are used to power the local_chat.py demo.
If you are interested in our design principles and the implementation of the injection framework, please refer to the design document.
The development of KTransformer is based on the flexible and versatile framework provided by Transformers. We also benefit from advanced kernels such as GGUF/GGML, Llamafile, and Marlin. We are planning to contribute back to the community by upstreaming our modifications.
KTransformer is actively maintained and developed by contributors from the MADSys group at Tsinghua University and members from Approaching.AI. We welcome new contributors to join us in making KTransformer faster and easier to use.