-
-
Notifications
You must be signed in to change notification settings - Fork 1
/
update_readme.sh
304 lines (223 loc) · 15.9 KB
/
update_readme.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
#!/bin/bash
# Updates the README.md content and statistics.
update_readme() {
cat << EOF > README.md
# Jarelllama's Scam Blocklist
${BLOCKLIST_DESCRIPTION}
The [automated retrieval](https://github.com/jarelllama/Scam-Blocklist/actions/workflows/build_deploy.yml) is done daily at 19:00 UTC.
This blocklist aims to be an alternative to blocking all newly registered domains (NRDs) seeing how many, but not all, NRDs are malicious. A variety of sources are integrated to detect new malicious domains within a short time span of their registration date.
## Download
| Format | Syntax |
| --- | --- |
| [Adblock Plus](https://raw.githubusercontent.com/jarelllama/Scam-Blocklist/main/lists/adblock/scams.txt) | \|\|scam.com^ |
| [Wildcard Domains](https://raw.githubusercontent.com/jarelllama/Scam-Blocklist/main/lists/wildcard_domains/scams.txt) | scam.com |
## Statistics
[](https://github.com/jarelllama/Scam-Blocklist/actions/workflows/build_deploy.yml)
[](https://github.com/jarelllama/Scam-Blocklist/actions/workflows/test_functions.yml)
\`\`\` text
Total domains: $(grep -cF '||' lists/adblock/scams.txt)
Light version: $(grep -cF '||' lists/adblock/scams_light.txt)
New domains from each source: *
Today | Yesterday | Excluded | Source
$(print_stats 'Emerging Threats') phishing
$(print_stats 'Google Search')
$(print_stats 'Jeroengui phishing') feed
$(print_stats 'Jeroengui scam') feed
$(print_stats Manual) Entries
$(print_stats PhishStats)
$(print_stats 'PhishStats (NRDs)')
$(print_stats Regex) Matching (NRDs)
$(print_stats aa419.org)
$(print_stats dnstwist) (NRDs)
$(print_stats fakewebsitebuster.com)
$(print_stats guntab.com)
$(print_stats petscams.com)
$(print_stats scam.directory)
$(print_stats scamadviser.com)
$(print_stats stopgunscams.com)
$(print_stats)
* The new domain numbers reflect what was retrieved, not
what was added to the blocklist.
* The Excluded % is of domains not included in the
blocklist. Mostly dead, whitelisted, and parked domains.
\`\`\`
> [!IMPORTANT]
All data retrieved are publicly available and can be viewed from their respective [sources](https://github.com/jarelllama/Scam-Blocklist/blob/main/SOURCES.md).<br>
Any data hidden behind account creation/commercial licenses is never used.
<details>
<summary>Domains over time (days)</summary>
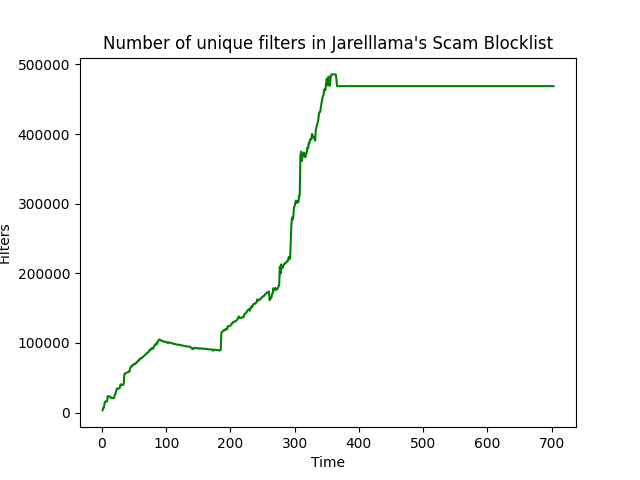
Courtesy of iam-py-test/blocklist_stats.
</details>
## Light version
Targeted at list maintainers, a light version of the blocklist is available in the [lists](https://github.com/jarelllama/Scam-Blocklist/tree/main/lists) directory.
<details>
<summary>Details about the light version</summary>
<ul>
<li>Intended for collated blocklists cautious about size</li>
<li>Only includes sources whose domains can be filtered by date registered/reported</li>
<li>Only includes domains retrieved/reported from February 2024 onwards, whereas the full list goes back further historically</li>
<li>Note that dead and parked domains that become alive/unparked are not added back into the light version (due to limitations in the way these domains are recorded)</li>
</ul>
Sources excluded from the light version are marked in SOURCES.md.
<br>
<br>
The full version should be used where possible as it fully contains the light version and accounts for resurrected/unparked domains.
</details>
## Other blocklists
### NSFW Blocklist
Created from requests, a blocklist for NSFW domains is available in Adblock Plus format here:
[nsfw.txt](https://raw.githubusercontent.com/jarelllama/Scam-Blocklist/main/lists/adblock/nsfw.txt)
<details>
<summary>Details about the NSFW Blocklist</summary>
<ul>
<li>Domains are automatically retrieved from the Tranco Top Sites Ranking daily</li>
<li>Dead domains are removed daily</li>
<li>Note that resurrected domains are not added back into the blocklist</li>
<li>Note that parked domains are not checked for in this blocklist</li>
</ul>
Total domains: $(grep -cF '||' lists/adblock/nsfw.txt)
<br>
<br>
This blocklist does not just include adult videos, but also NSFW content of the artistic variety (rule34, illustrations, etc).
</details>
### Malware Blocklist
A blocklist for malicious domains extracted from Proofpoint's [Emerging Threats](https://rules.emergingthreats.net/) rulesets can be found here: **[jarelllama/Emerging-Threats](https://github.com/jarelllama/Emerging-Threats)**
Parts of the rulesets are integrated into the Scam Blocklist as well.
## Sources
### Retrieving scam domains using Google Search API
Google provides a [Search API](https://developers.google.com/custom-search/v1/overview) to retrieve JSON-formatted results from Google Search. A list of search terms almost exclusively found in scam sites is used by the API to retrieve domains. See the list of search terms here: [search_terms.csv](https://github.com/jarelllama/Scam-Blocklist/blob/main/config/search_terms.csv)
#### Details
Scam sites often do not have long lifespans; malicious domains may be replaced before they can be manually reported. By programmatically searching Google using paragraphs from real-world scam sites, new domains can be added as soon as Google crawls the site. This requires no manual reporting.
The list of search terms is proactively maintained and is mostly sourced from investigating new scam site templates seen on [r/Scams](https://www.reddit.com/r/Scams/).
\`\`\` text
Active search terms: $(csvgrep -c 2 -m 'y' -i "$SEARCH_TERMS" | tail -n +2 | wc -l)
API calls made today: $(mawk "/${TODAY},Google Search/" "$SOURCE_LOG" | csvcut -c 10 | mawk '{sum += $1} END {print sum}')
Domains retrieved today: $(sum "$TODAY" 'Google Search')
\`\`\`
### Retrieving phishing NRDs using dnstwist
New phishing domains are created daily, and unlike other sources that rely on manual reporting, [dnstwist](https://github.com/elceef/dnstwist) can automatically detect new phishing domains within days of their registration date.
dnstwist is an open-source detection tool for common cybersquatting techniques like [Typosquatting](https://en.wikipedia.org/wiki/Typosquatting), [Doppelganger Domains](https://en.wikipedia.org/wiki/Doppelganger_domain), and [IDN Homograph Attacks](https://en.wikipedia.org/wiki/IDN_homograph_attack).
#### Details
dnstwist uses a list of common phishing targets to find permutations of the targets' domains. The target list is a handpicked compilation of cryptocurrency exchanges, delivery companies, etc. collated while wary of potential false positives. The list of phishing targets can be viewed here: [phishing_targets.csv](https://github.com/jarelllama/Scam-Blocklist/blob/main/config/phishing_targets.csv)
The generated domain permutations are checked for matches in a newly registered domains (NRDs) feed comprising domains registered within the last 30 days. Each permutation is tested for alternate top-level domains (TLDs) using the 15 most prevalent TLDs from the NRD feed at the time of retrieval.
\`\`\` text
Active targets: $(mawk -F ',' '$5 != "y"' "$PHISHING_TARGETS" | tail -n +2 | wc -l)
Domains retrieved today: $(sum "$TODAY" dnstwist)
\`\`\`
### Regarding other sources
All sources used presently or formerly are credited here: [SOURCES.md](https://github.com/jarelllama/Scam-Blocklist/blob/main/SOURCES.md)
The domain retrieval process for all sources can be viewed in the repository's code.
## Automated filtering process
* The domains collated from all sources are filtered against an actively maintained whitelist (scam reporting sites, forums, vetted stores, etc.)
* The domains are checked against the [Tranco Top Sites Ranking](https://tranco-list.eu/) for potential false positives which are then vetted manually
* Common subdomains like 'www' are stripped. The list of subdomains checked for can be viewed here: [subdomains.txt](https://github.com/jarelllama/Scam-Blocklist/blob/main/config/subdomains.txt)
* Only domains are included in the blocklist; URLs are stripped down to their domains and IP addresses are manually checked for resolving DNS records
* Redundant rules are removed via wildcard matching. For example, 'abc.example.com' is a wildcard match of 'example.com' and, therefore, is redundant and removed. Wildcards are occasionally added to the blocklist manually to further optimize the number of entries
Entries that require manual verification/intervention are sent in a Telegram notification for fast remediations.
The full filtering process can be viewed in the repository's code.
## Dead domains
Dead domains are removed daily using AdGuard's [Dead Domains Linter](https://github.com/AdguardTeam/DeadDomainsLinter).
Dead domains that are resolving again are included back into the blocklist.
\`\`\` text
Dead domains removed today: $(grep -cF "${TODAY},dead" "$DOMAIN_LOG")
Resurrected domains added today: $(grep -cF "${TODAY},resurrected" "$DOMAIN_LOG")
\`\`\`
## Parked domains
From initial testing, [9%](https://github.com/jarelllama/Scam-Blocklist/commit/84e682fea95866670dd99f5c98f350bc7377011a) of the blocklist consisted of [parked domains](https://www.godaddy.com/resources/ae/skills/parked-domain) that inflated the number of entries. Because these domains pose no real threat (besides the obnoxious advertising), they are removed from the blocklist daily.
A list of common parked domain messages is used to automatically detect these domains. This list can be viewed here: [parked_terms.txt](https://github.com/jarelllama/Scam-Blocklist/blob/main/config/parked_terms.txt)
If these parked sites no longer contain any of the parked messages, they are assumed to be unparked and are added back into the blocklist.
> [!TIP]
For list maintainers interested in integrating the parked domains as a source, the list of daily-updated parked domains can be found here: [parked_domains.txt](https://github.com/jarelllama/Scam-Blocklist/blob/main/data/parked_domains.txt) (capped to newest 8000 entries)
\`\`\` text
Parked domains removed today: $(grep -cF "${TODAY},parked" "$DOMAIN_LOG")
Unparked domains added today: $(grep -cF "${TODAY},unparked" "$DOMAIN_LOG")
\`\`\`
## As seen in
* [Fabriziosalmi's Hourly Updated Domains Blacklist](https://github.com/fabriziosalmi/blacklists)
* [Hagezi's Threat Intelligence Feeds](https://github.com/hagezi/dns-blocklists?tab=readme-ov-file#closed_lock_with_key-threat-intelligence-feeds---increases-security-significantly-recommended-)
* [Sefinek24's blocklist generator and collection](https://blocklist.sefinek.net/)
* [T145's Black Mirror](https://github.com/T145/black-mirror)
* [The oisd blocklist](https://oisd.nl/)
* [doh.tiar.app privacy DNS](https://doh.tiar.app/)
* [dnswarden privacy-focused DNS](https://dnswarden.com/)
* [file-git.trli.club](https://file-git.trli.club/)
* [iam-py-test/my_filters_001](https://github.com/iam-py-test/my_filters_001)
## Resources / See also
* [AdGuard's Dead Domains Linter](https://github.com/AdguardTeam/DeadDomainsLinter): simple tool to check adblock filtering rules for dead domains
* [AdGuard's Hostlist Compiler](https://github.com/AdguardTeam/HostlistCompiler): simple tool that compiles hosts blocklists and removes redundant rules
* [Elliotwutingfeng's repositories](https://github.com/elliotwutingfeng?tab=repositories): various original blocklists
* [Google's Shell Style Guide](https://google.github.io/styleguide/shellguide.html): Shell script style guide
* [Grammarly](https://grammarly.com/): spelling and grammar checker
* [Jarelllama's Blocklist Checker](https://github.com/jarelllama/Blocklist-Checker): generate a simple static report for blocklists or see previous reports of requested blocklists
* [Legality of web scraping](https://www.quinnemanuel.com/the-firm/publications/the-legal-landscape-of-web-scraping/): the law firm of Quinn Emanuel Urquhart & Sullivan's memoranda on web scraping
* [ShellCheck](https://github.com/koalaman/shellcheck): static analysis tool for Shell scripts
* [Tranco](https://tranco-list.eu/): research-oriented top sites ranking hardened against manipulation
* [VirusTotal](https://www.virustotal.com/): analyze suspicious files, domains, IPs, and URLs to detect malware (also includes WHOIS lookup)
* [iam-py-test/blocklist_stats](https://github.com/iam-py-test/blocklist_stats): statistics on various blocklists
## Appreciation
Thanks to the following people for the help, inspiration, and support!
[@T145](https://github.com/T145) - [@bongochong](https://github.com/bongochong) - [@hagezi](https://github.com/hagezi) - [@iam-py-test](https://github.com/iam-py-test) - [@sefinek24](https://github.com/sefinek24) - [@sjhgvr](https://github.com/sjhgvr)
## Contributing
You can contribute to this project in the following ways:
* [Sponsorship](https://github.com/sponsors/jarelllama)
* Star this repository
* [Code](https://github.com/jarelllama/Scam-Blocklist/blob/main/scripts) reviews
* Report domains and false positives
* Report false negatives in the [whitelist](https://github.com/jarelllama/Scam-Blocklist/blob/main/config/whitelist.txt)
* Suggest [search terms](https://github.com/jarelllama/Scam-Blocklist/blob/main/config/search_terms.csv) for the Google Search source
* Suggest [phishing targets](https://github.com/jarelllama/Scam-Blocklist/blob/main/config/phishing_targets.csv) for the dnstwist and Regex Matching sources
* Suggest new [sources](https://github.com/jarelllama/Scam-Blocklist/blob/main/SOURCES.md)
* Suggest [parked terms](https://github.com/jarelllama/Scam-Blocklist/blob/main/config/parked_terms.txt) for the parked domains detection
* Report false positives in the [parked domains](https://github.com/jarelllama/Scam-Blocklist/blob/main/data/parked_domains.txt) file
EOF
}
readonly FUNCTION='bash scripts/tools.sh'
readonly SEARCH_TERMS='config/search_terms.csv'
readonly PHISHING_TARGETS='config/phishing_targets.csv'
readonly SOURCE_LOG='config/source_log.csv'
readonly DOMAIN_LOG='config/domain_log.csv'
TODAY="$(date -u +"%d-%m-%y")"
YESTERDAY="$(date -ud yesterday +"%d-%m-%y")"
# Function 'print_stats' is an echo wrapper that returns the formatted
# statistics for the given source.
# $1: source to process (default is all sources)
print_stats() {
printf "%5s |%10s |%8s%% | %s" \
"$(sum "$TODAY" "$1")" "$(sum "$YESTERDAY" "$1")" \
"$(sum_excluded "$1" )" "${1:-All sources}"
}
# Note that csvkit is used in the following functions as the Google Search
# search terms may contain commas which makes using mawk complicated.
# Function 'sum' is an echo wrapper that returns the total sum of domains
# retrieved by the given source for that particular day.
# $1: day to process
# $2: source to process (default is all sources)
sum() {
# Print dash if no runs for that day found
! grep -qF "$1" "$SOURCE_LOG" && { printf "-"; return; }
# grep used here as mawk has issues with brackets after whitespaces
grep "${1},${2}.*,saved$" "$SOURCE_LOG" | csvcut -c 5 \
| mawk '{sum += $1} END {print sum}'
}
# Function 'sum_excluded' is an echo wrapper that returns the percentage of
# excluded domains out of the raw count retrieved by the given source.
# $1: source to process (default is all sources)
sum_excluded() {
# Get required columns of the source (includes unsaved)
grep -F "$1" "$SOURCE_LOG" | csvcut -c 4,6,7,8 > rows.tmp
raw_count="$(mawk -F ',' '{sum += $1} END {print sum}' rows.tmp)"
# Return if raw count is 0 to avoid divide by zero error
(( raw_count == 0 )) && { printf "0"; return; }
white_count="$(mawk -F ',' '{sum += $2} END {print sum}' rows.tmp)"
dead_count="$(mawk -F ',' '{sum += $3} END {print sum}' rows.tmp)"
parked_count="$(mawk -F ',' '{sum += $4} END {print sum}' rows.tmp)"
excluded_count="$(( white_count + dead_count + parked_count ))"
printf "%s" "$(( excluded_count * 100 / raw_count ))"
}
# Entry point
trap 'find . -maxdepth 1 -type f -name "*.tmp" -delete' EXIT
# Install csvkit
command -v csvgrep &> /dev/null || pip install -q csvkit
$FUNCTION --format-all
update_readme