diff --git a/README b/README
deleted file mode 100644
index 2f5c7ae..0000000
--- a/README
+++ /dev/null
@@ -1,22 +0,0 @@
-GloVe: Global Vectors for Word Representation
-_____________________________________________________
-
-
-We provide an implementation of the GloVe model for learning word representations, as well as some auxiliary tools to construct word-word cooccurrence matrices from large corpora.
-
-Please see the project page for more information:
-http://nlp.stanford.edu/projects/glove/
-
-This package includes four main tools:
-1) vocab_count
-Constructs unigram counts from a corpus, and optionally thresholds the resulting vocabulary based on total vocabulary size or minimum frequency count. This file should already consist of whitespace-separated tokens. Use something like the Stanford Tokenizer (http://nlp.stanford.edu/software/tokenizer.shtml) first on raw text.
-2) cooccur
-Constructs word-word cooccurrence statistics from a corpus. The user should supply a vocabulary file, as produced by 'vocab_count', and may specify a variety of parameters, as described by running './cooccur'.
-3) shuffle
-Shuffles the binary file of cooccurrence statistics produced by 'cooccur'. For large files, the file is automatically split into chunks, each of which is shuffled and stored on disk before being merged and shuffled togther. The user may specify a number of parameters, as described by running './shuffle'.
-4) glove
-Train the GloVe model on the specified cooccurrence data, which typically will be the output of the 'shuffle' tool. The user should supply a vocabulary file, as given by 'vocab_count', and may specify a number of other parameters, which are described by running './glove'.
-
-The package also provides a demo script 'demo.sh'. It downloads a small corpus, consisting of the first 100M characters of Wikipedia, collects unigram counts, constructs and shuffles cooccurrence data, and trains a simple version of the GloVe model. It also runs a word analogy evaluation script in python.
-
-All work contained in this package is licensed under the Apache License, Version 2.0. See the include LICENSE file.
diff --git a/README.md b/README.md
new file mode 100644
index 0000000..9313c73
--- /dev/null
+++ b/README.md
@@ -0,0 +1,45 @@
+## GloVe: Global Vectors for Word Representation
+
+frog nearest neighbors | Litoria | Leptodactylidae | Rana | Eleutherodactylus
+-------------------------|:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:|
+ frogs toad litoria leptodactylidae rana lizard eleutherodactylus |  |  |  | 
+
+We provide an implementation of the GloVe model for learning word representations. Please see the [project page](http://nlp.stanford.edu/projects/glove/) for more information.
+
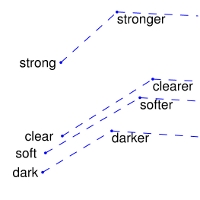
+man -> woman | city -> zip | comparative -> superlative
+:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:|
+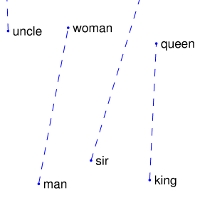 | 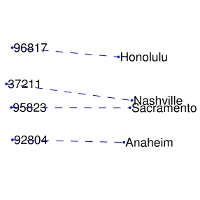 | 
+
+## Download pre-trained word vectors
+Pre-trained word vectors are made available under the Public Domain Dedication
+and License
+
+
+ - Wikipedia 2014 + Gigaword 5 (6B tokens, 400K vocab, uncased, 50d, 100d, 200d, & 300d vectors, 822 MB download): glove.6B.zip
+ - Common Crawl (42B tokens, 1.9M vocab, uncased, 300d vectors, 1.75 GB download): glove.42B.300d.zip
+ - Common Crawl (840B tokens, 2.2M vocab, cased, 300d vectors, 2.03 GB download): glove.840B.300d.zip
+ - Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased, 25d, 50d, 100d, & 200d vectors, 1.42 GB download): glove.twitter.27B.zip Ruby script for preprocessing Twitter data
+
+