# DAIR-V2X and OpenDAIRV2X: Towards General and Real-World Cooperative Autonomous Driving
## Table of Contents:
1. [Highlights](#high)
2. [News](#news)
3. [Dataset Download](#dataset)
4. [Getting Started](#start)
5. [Major Features](#features)
6. [Benchmark](#benchmark)
7. [Citation](#citation)
8. [Contaction](#contaction)
## Highlights
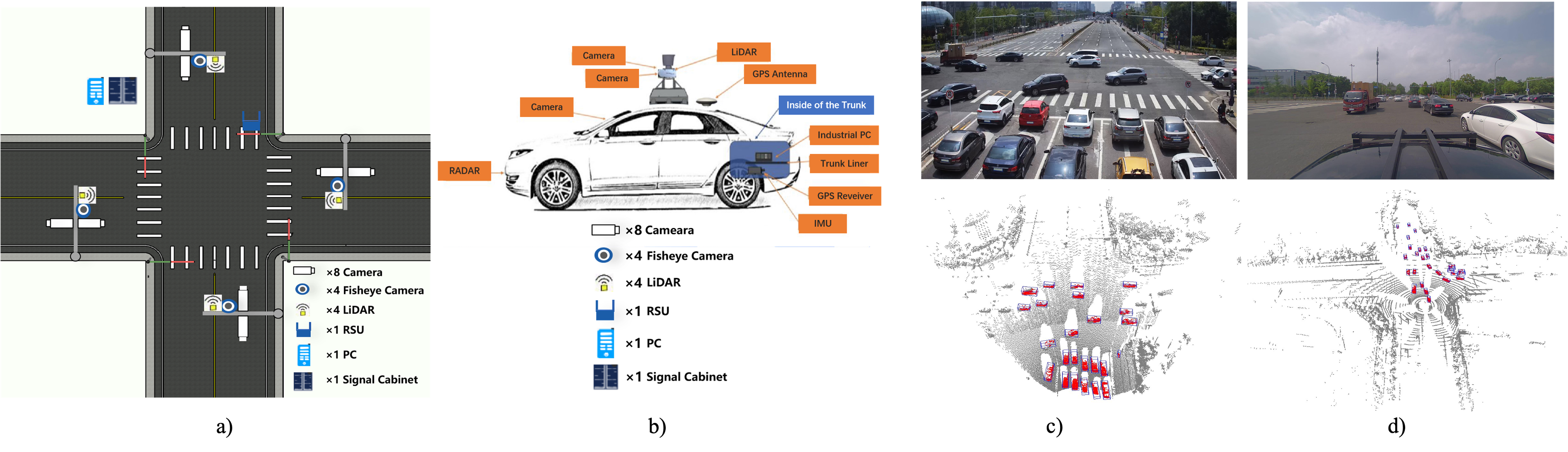
- DAIR-V2X: The first real-world dataset for research on vehicle-to-everything autonomous driving. It comprises a total of 71,254 frames of image data and 71,254 frames of point cloud data.
- OpenDAIR-V2X: An open-sourced framework for supporting the research on vehicle-to-everything autonomous driving.
## News
* [2023.03] 🔥 Our new dataset "V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting" has been accepted by CVPR2023. Congratulations! We will release the dataset sooner. Please follow [DAIR-V2X-Seq](https://github.com/AIR-THU/DAIR-V2X-Seq) for the latest news.
* [2023.03] 🔥 We have released training code for our [FFNET](https://github.com/haibao-yu/FFNet-VIC3D), and our OpenDAIRV2X now supports evaluating [FFNET](https://github.com/haibao-yu/FFNet-VIC3D).
* [2022.11] We have held the first [VIC3D Object Detection challenge](https://aistudio.baidu.com/aistudio/competition/detail/522/0/introduction).
* [2022.07] We have released the OpenDAIRV2X codebase v1.0.0.
The current version can faciliate the researchers to use the DAIR-V2X dataset and reproduce the benchmarks.
* [2022.03] Our Paper "DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection" has been accepted by CVPR2022.
Arxiv version could be seen [here](https://arxiv.org/abs/2204.05575).
* [2022.02] DAIR-V2X dataset is availale [here](https://thudair.baai.ac.cn/index).
It can be unlimitedly downloaded within mainland China.
## Dataset Download
- [DAIR-V2X-I](https://thudair.baai.ac.cn/roadtest)
- [DAIR-V2X-V](https://thudair.baai.ac.cn/cartest)
- [DAIR-V2X-C](https://thudair.baai.ac.cn/coop-forecast)
## Getting Started
Please refer to [getting_started.md](docs/get_started.md) for Installation, Evaluation, Benchmark and Training etc for VIC3D.
## Major Features
- **Support Train/Evaluation for VIC3D**
It will directly support model training and evaluation for VIC3D.
Now the model inference and model training are mainly based on MMDetection3D, which is not quite convenient to carry the VICAD research.
- [x] Evaluation (Model inference is based on MMDetection3D)
- [x] Training based on MMDetection3D
- [ ] Direct Evaluation with DAIR-V2X Framework
- [ ] Direct Training with DAIR-V2X Framework
- **Support different fusion methods for VIC3D**
It will directly support different fusion methods including early fusion/feature fusion/late fusion.
Now it supports early fusion and late fusion.
- [x] Early Fusion
- [x] Early Fusion
- [x] Late Fusion
- **Support multi-modality/single-modality detectors for VIC3D**
It will directly support different modaility detectors including image-modality detector, pointcloud-modality detector and image-pointcloud fusion detector.
Now it supports image-modality detector ImvoxelNet, pointcloud-modality detector PointPillars.
- [x] Image-modality
- [x] Pointcloud-modality
- [ ] Multi-modality
- **Support Cooperation-view/single-view detectors for VIC3D**
It directly supports different view's detectors for VIC3D, including infrastructure-view detector,
vehicle-view detector, vehicle-infrastrucure cooperation-view detector.
- [x] Infrastructure-view
- [x] Vehicle-view
- [x] Cooperation-view
## Benchmark
You can find more benchmark in [SV3D-Veh](configs/sv3d-veh), [SV3D-Inf](configs/sv3d-inf), and [VIC3D](configs/vic3d). We provide part of the VIC3D Benchmark in following table.
| Modality | Fusion | Model | Dataset | AP-3D (IoU=0.5) | | | | AP-BEV (IoU=0.5) | | | | AB |
| :-------: | :-----: | :--------: | :-------: | :----: | :----: | :----: | :-----: | :-----: | :---: | :----: | :-----: | :----: |
| | | | | Overall | 0-30m | 30-50m | 50-100m | Overall | 0-30m | 30-50m | 50-100m | |
| Image | VehOnly | ImvoxelNet | VIC-Sync | 9.13 | 19.06 | 5.23 | 0.41 | 10.96 | 21.93 | 7.28 | 0.78 | 0 |
| | Late-Fusion | ImvoxelNet | VIC-Sync | 18.77 | 33.47 | 9.43 | 8.62 | 24.85 | 39.49 | 14.68 | 14.96 | 309.38|
|Pointcloud | VehOnly | PointPillars | VIC-Sync | 48.06 | 47.62 | 63.51 | 44.37 | 52.24 | 30.55 | 66.03 | 48.36 | 0 |
| | Early Fusion | PointPillars | VIC-Sync | 62.61 | 64.82 | 68.68 | 56.57 | 68.91 | 68.92 | 73.64 | 65.66 | 1382275.75 |
| | Late-Fusion | PointPillars | VIC-Sync | 56.06 | 55.69 | 68.44 | 53.60 | 62.06 | 61.52 | 72.53 | 60.57 | 478.61 |
| | Late-Fusion | PointPillars |VIC-Async-2| 52.43 | 51.13 | 67.09 | 49.86 | 58.10 | 57.23 | 70.86 | 55.78 | 478.01 |
| | TCLF | PointPillars |VIC-Async-2| 53.37 | 52.41 | 67.33 | 50.87 | 59.17 | 58.25 | 71.20 | 57.43 | 897.91 |
## Citation
If you find this project useful in your research, please consider cite:
```
@inproceedings{dair-v2x,
title={Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3d object detection},
author={Yu, Haibao and Luo, Yizhen and Shu, Mao and Huo, Yiyi and Yang, Zebang and Shi, Yifeng and Guo, Zhenglong and Li, Hanyu and Hu, Xing and Yuan, Jirui and Nie, Zaiqing},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={21361--21370},
year={2022}
}
```
## Contaction
If any questions and suggenstations, please email to dair@air.tsinghua.edu.cn.
## Related Resources
[](https://awesome.re)
- [DAIR-V2X-Seq](https://github.com/AIR-THU/DAIR-V2X-Seq) (:rocket:Ours!)
- [FFNET](https://github.com/haibao-yu/FFNet-VIC3D) (:rocket:Ours!)
- [mmdet3d](https://github.com/open-mmlab/mmdetection3d)
- [pypcd](https://github.com/dimatura/pypcd)