中文 | English
A production-level knowledge question-and-answer chatbot implementation based on AWS services and the Langchain framework has optimized all aspects. Supports flexible configuration plugging and unplugging of embedding models & large language models. The front and back ends are separated and easily integrated into IM tools (such as Lark).

-
Deployment documentation
-
Workshop (workshops)
workshop address (Note: Please refer to the Lark documentation for deployment. The one deployed in the workshop is an unupdated branch, which mainly helps users unfamiliar with AWS get started more easily)
-
Infrastructure diagram
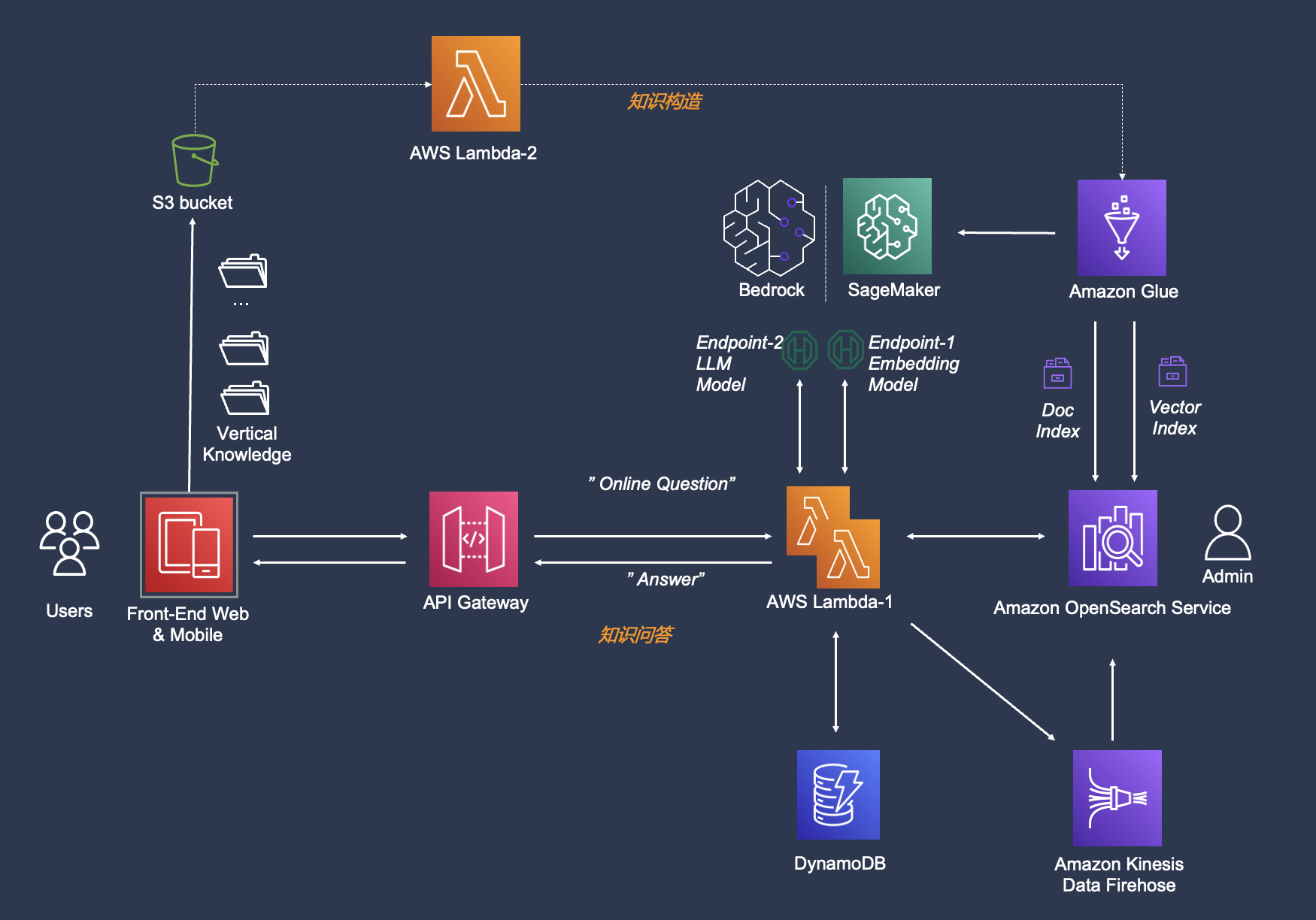

-
Work flow chart
Generally speaking, the whole process requires three major language model calls, and the sequence numbers are marked with red numbers on the image below.
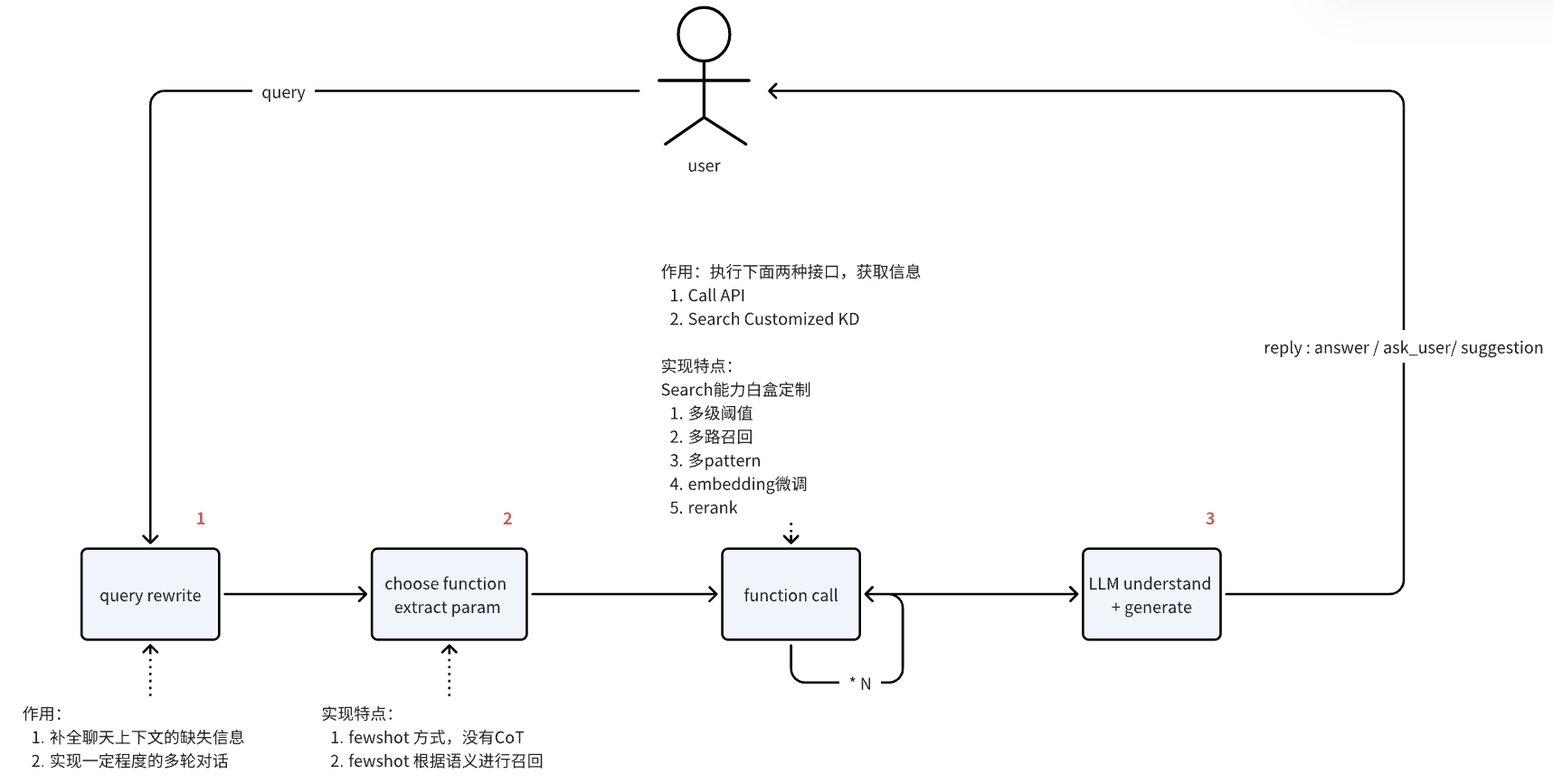

-
Code Introduction
We need to focus on the four directories code/, deploy/, docs/, and notebooks/. The code/directory is divided into 7 subdirectories according to modules, deploy/ provides examples of knowledge/fewshot files for setting up cdk deployment resources, and notebooks/ provides some notebook files for deploying, fine-tuning, and visualizing various models to help you further optimize results.
. ├── Agent_Pydantic_Lambda # Agent API implementation example (submodule) ├── ChatBotFE # front-end code (submodule) ├── code │ ├── main/ # Lambda code directory corresponding to the main logic │ ├── offline_process/ # Offline knowledge to build the corresponding execution code directory │ ├── lambda_offline_trigger/ # Lambda code directory that starts offline knowledge intake │ ├── lambda_plugins_trigger/ # Not in use │ ├── interpreton_detect/ # Intent to identify the lambda code directory │ ├── query_rewriter/ # User input to rewrite the lambda code directory │ └ ── chat_agent/ # Call the API module ├── deploy │ ├── lib/ # cdk deployment script directory │ └── gen_env.sh # Automatically generate a script for deployment variables (for workshop) ├── docs │ ├── interpretons/ # Example markup file for intent recognition │ ├── prompt_template/ # Tested Prompt template │ ├── aws_cleanroom.faq # FAQ Knowledgebase File │ ├── aws_msk.FAQ # FAQ Knowledgebase File │ ├── aws_emr.faq # FAQ Knowledgebase File │ ├── aws-overview.pdf # pdf knowledge base file │ └ ── PMC10004510.txt # txt plain text file ├── doc_preprocess/ # original file processing script │ ├── pdf_spliter.py # PDF parsing split script │ └ ──... ├── notebook/ # Various types of notebooks │ ├── embedding/ # Deploying the notebook with the embedding model │ ├── llm/ # Deploying the LLM model notebook │ ├── mutilmodal/ # Notebooks that deploy multi-modal models, including VisualGLM │ ├── guidance/ # Some notebooks for fine-tuning vector models and visualizing effects │ └ ──...
**Q1: ** How to adapt to my business context?
**A1: ** Refer to the following three steps:
-
Upload your own documents.
-
Upload your own fewshot file (reference/docs/considerons/directory) to achieve customized intent streaming.
-
Connect to your own front-end. For how to call the backend API, please refer to [Backend_API_Interface](. /backend_interface.md).
**Q2: ** How to optimize the high error rate of knowledge recall? What are the best practices for RAG?
**A2: ** See [Best Practices](. /best_practice_summary.pdf)
**Q3: ** What data formats can be imported?
**A3: ** Currently, the import of text formats such as pdf, word, txt, md, wiki, etc. is supported. For data in the FAQ format, this solution has been optimized for targeted recall. Please refer to the DOCS/ centralized FAQ format (.csv, .xlsx) below.
**Q4: ** How much does the infrastructure cost?
**A4: ** Due to data from the production environment and concurrency, only some data is given for reference based on the test environment. Most of the entire solution is a serverless architecture. Most service components (Bedrock, Glue, Lambda, etc.) are paid according to usage. In our previous experience, most service costs account for a very low proportion. Among them, SageMaker and OpenSearch account for relatively high costs (90% +). SageMaker is optional overseas, so if you don't need to deploy an independent rerank model, you don't need it. The cost of OpenSearch is related to the model. For details, refer to https://aws.amazon.com/cn/opensearch-service/pricing/,The default instance in this solution is 2 * r6g.large.search, the unit price is USD 0.167/hour, so you can adjust the instance accordingly to reduce the cost.
- What should I pay attention to when building a vector index?
-
You need to consider the alignment of knn_vector's dimension with the vector model output latitude, and the alignment of space_type with the type supported by the vector model
-
Users need to decide whether to enable ANN indexing based on the amount of data, that is (“knn”: “true”)
-
m, ef_consturtion parameters need to be adjusted according to the amount of data