# Rust Stream API visualized and exposed
Additional languages
Managing concurrency in real-world applications can be quite tricky. Developers must grapple with concurrency control, back pressure, error handling, and more. Thankfully, Rust provides us with the async/await mechanism, and on top of that, the [Stream API](https://docs.rs/futures/latest/futures/stream/index.html).
The Stream methods allow us to elegantly define a pipeline of asynchronous operations with a nifty abstraction addressing common use cases.
Unfortunately, elegance sometimes masks complexity. Can you look at a streaming pipeline and understand how many operations would run in parallel? What about the order? I found it trickier than it seems, so naturally, as a complete overkill, I wrote a Bevy visualization to investigate it. This investigation brought light to some truly unexpected results - so unexpected, that in some cases, you might want to reconsider using this API.
## Overview of Stream API
Let's start with a brief overview of the Stream API. The following code defines an async pipeline that iterates over integers from 0 to 10 and executes the `async_work` method with a concurrency limit of 3. The result is then filtered using the `async_predicate` method. This is awesome! With just a few lines of code, we've created a non-trivial async control flow.
```rust
async fn async_work(i32) -> i32 {...}
async fn async_predicate(i32) -> Option {...}
async fn buffered_filter_example() {
let stream = stream::iter(0..10)
.map(async_work) // async_work returns a future. The output of this stage is a stream of futures
.buffered(3) // polls stream of futures and runs at most 3 concurrently
.filter_map(async_predicate); // filters out the results of the previous stage using async_predicate function
pin!(stream);
while let Some(next) = stream.next().await {
println!("finished working on: {}", next);
}
}
```
Amm, we can already see some complex elements. For instance, why did I use `filter_map` instead of `filter`? What's this pesky `pin!(stream)` doing? I won't digress into these questions. Instead, here are some informative links:
- [Put a Pin on That](https://ohadravid.github.io/posts/2023-07-put-a-pin-on-that/)
- [How will futures::StreamExt::filter work with async closures?](https://www.reddit.com/r/rust/comments/r47iqi/how_will_futuresstreamextfilter_work_with_async/)
The goal of this investigation is to get a better understanding of the execution order, concurrency, and back pressure characteristics of such pipelines. For example, in the code above, the map method executes 3 `async_work` concurrently, but what if `async_predicate` is a long operation? will it continue to concurrently run more `async_work`? Supposedly after it completes 3 invocations, it should be able to run more while `async_predicate` runs in the background right? If so, will it take an unbounded amount of memory?
What about `filter_map`? it does not have a clear concurrency parameter. Does it runs the provided method serially? or with unlimited concurrency?
The documentation leaves some of these questions unclear. We need to see it with our own eyes.
## Experiment tool - visualizing Rust streams
I used [Bevy](https://bevyengine.org/) to visualize the flow of data in a streaming pipeline. The idea involves defining a streaming pipeline with methods that report their progress via a channel. I used Bevy's `EventWriter` to forward this information to a Bevy rendering system.
Here's how it looks:
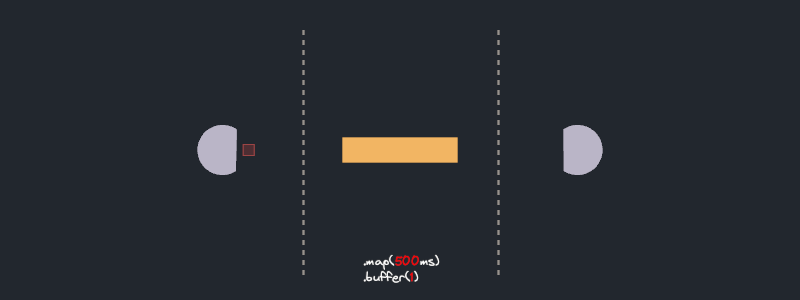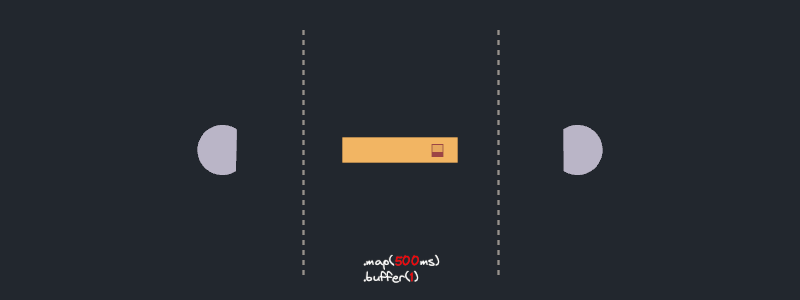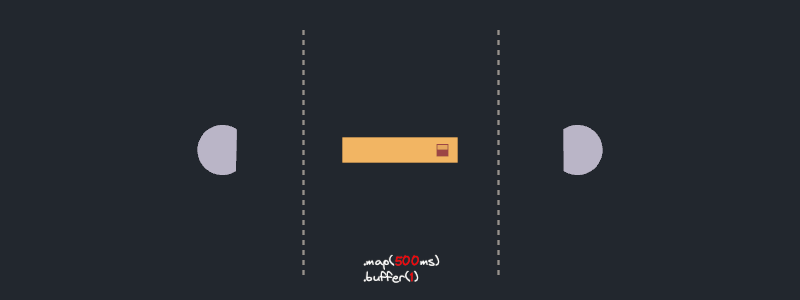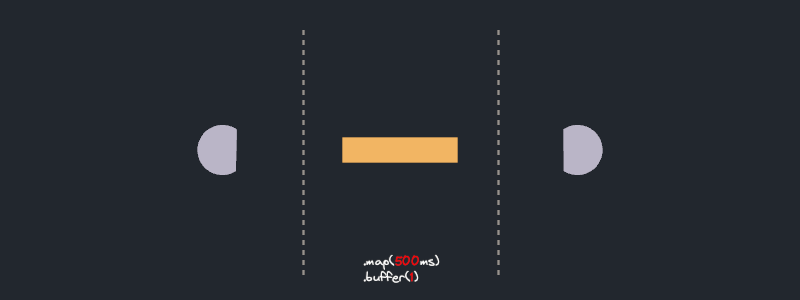
In the visualization, we see a representation of each streaming item navigating through different stages of the pipeline. Units of work start from the *source* and move to the `map(..).buffered(..)` stage. To simulate real world async work I used a small loop of `sleep()` calls. This represents real world scenarios where async methods have multiple `await` calls and allows us to visualize the future run progress.
```rust
for i in 0..5 {
tokio::time::sleep(duration / 5).await;
tx.send(/* update bevy rendering system */).unwrap();
}
```
We visualize future progress via a tiny progress bar on each item. After an item completes the `buffered` stage, it proceeds to the *sink* and finishes its journey.
It is important to note that the visualization is sourced from actual running Rust code. This isn't a simulation; it is a real-time visualization of the Rust Stream pipeline.
You can find the source code [here](https://github.com/alexpusch/rust-stream-vis).
## Experiment 1: [buffered](https://docs.rs/futures/latest/futures/stream/trait.StreamExt.html#method.buffered)
```rust
stream::iter(0..10)
.map(async_work)
.buffered(5);
```
> buffer up to at most n futures and then return the outputs in the same order as the underlying stream. No more than n futures will be buffered at any point in time
### Experiment questions
- Will the `buffered` method fetch a new unit of work from the source stream as soon as any unit of work completes, or only when the earliest unit of work completes and sent as output to the next stage?

All right! look at it purr! As expected, each item goes through `async_work`. The `.buffered(5)` step runs at most 5 futures concurrently, retaining completed features until their predecessors completes as well.
### Experiment result
The `buffered` method **does not** acquire a new unit of work once an arbitrary item completes. Instead, it only does so once the earliest item is completed and advances to the next stage. This makes sense. A different behavior would require the `buffered` method to store the results of an unbounded number of futures, which could lead to excessive memory usage.
I wonder if there's a case to be made for a `buffered_with_back_pressure(n: usize, b: usize)` method that will allow some items to be taken from the source stream, up to `b` times.
## Experiment 2: [buffer_unordered](https://docs.rs/futures/latest/futures/stream/trait.StreamExt.html#method.buffer_unordered)
```rust
stream::iter(0..10)
.map(async_work)
.buffer_unordered(5);
```
> buffer up to n futures and then return the outputs in the order in which they complete. No more than n futures will be buffered at any point in time, and less than n may also be buffered
### Experiment questions
- Will the `buffer_unordered` method take a new unit of work from the source stream as soon as any unit of work completes, or only when the earliest unit of work is completed and sent to the next stage?

Unlike `buffered`, `buffer_unordered` does not retain completed futures and immediately makes them available to the next stage upon completion.
### Experiment result
The `buffer_unordered` method **does** fetch a new unit of work as soon as any unit of work completes. Contrary to `buffered`, the unordered version does not need to retain completed future results to maintain output order. This allows it to process the stream with higher throughput.
## Experiment 3: [filter_map](https://docs.rs/futures/latest/futures/stream/trait.StreamExt.html#method.filter_map)
```rust
stream::iter(0..10)
.filter_map(async_predicate);
```
> Filters the values produced by this stream while simultaneously mapping them to a different type according to the provided asynchronous closure. As values of this stream are made available, the provided function will be run on them.
### Experiment questions
- Does the `filter` method executes features in parallel or in series?
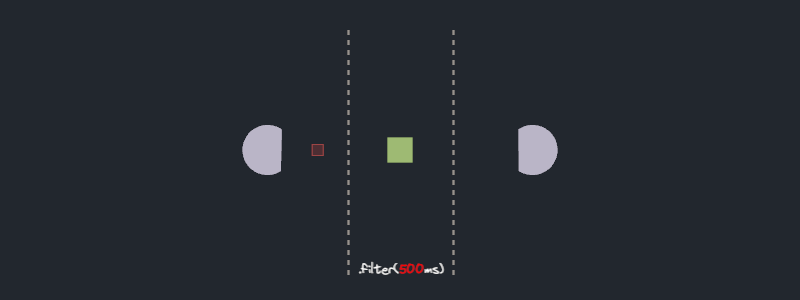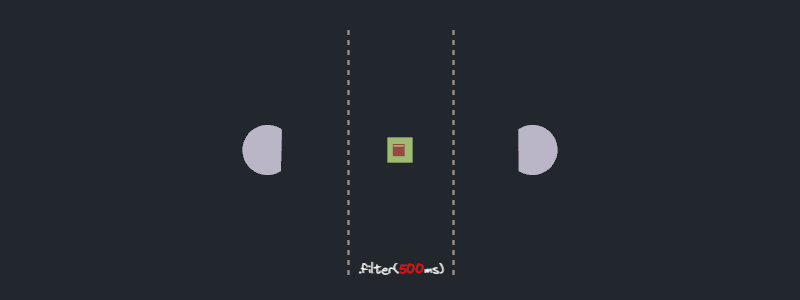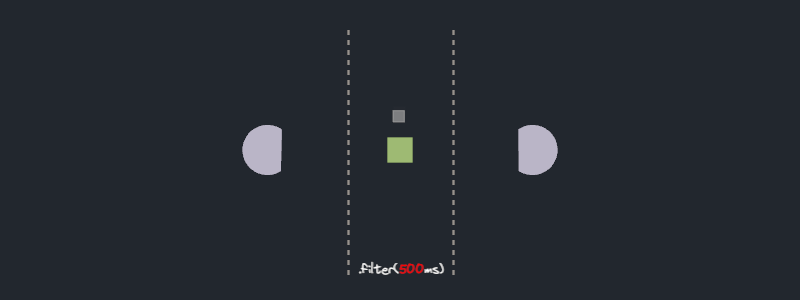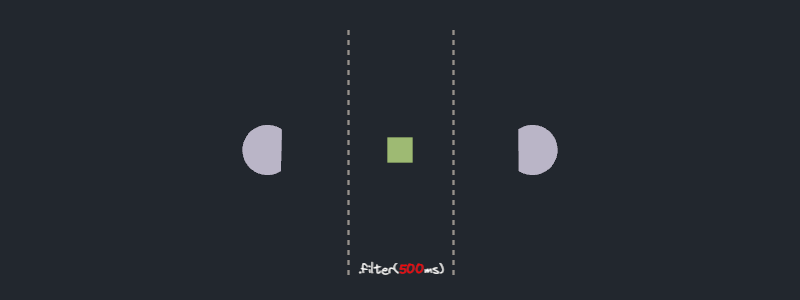
### Experiment result
No surprises here. The `filter` operator processes each future in series.
If we want to accomplish async filtering with concurrency we can use a blend of `map`, `buffered`, and `filter_map(future::ready)`. The `map().buffered()` duo would calculate the predicate concurrently while `filter_map` remove failed items from the stream
```rust
stream::iter(0..10)
.map(async_predicate)
.buffered(5)
.filter_map(future::ready); // the ready function will return the predicate result wrapped in a ready future
```
## Experiment 4: buffered + filter_map
```rust
stream::iter(0..10)
.map(async_work)
.buffered(3)
.filter_map(async_predicate);
```
### Experiment question
- How will a long-running `filter_map` step affect the concurrency of the `buffered` step?
Ok, this is unexpected! The stream does not function as I initially thought. While `async_predicate` is being executed, no `async_work` future is progressing. Even further, no new future starts to run until the first batch of five is complete. What's going on?
Let's see what happens when we replace `buffered` with `buffer_unordered`.
The situation is pretty much identical. Again, the `async_work` futures are suspended until `async_predicate` is completed.
Could it be something to do with `filter_map`? Let's attempt to stick two `buffered` steps sequentially:

Nope, the behavior remains the same.
### What's going on?
Turns out I'm not the first that encounters this difficulty. This is the same issue [Barbara battled with](https://rust-lang.github.io/wg-async/vision/submitted_stories/status_quo/barbara_battles_buffered_streams.html).
To truly grasp what's happening, we need a solid understanding of Futures, async executors, and the stream API. Resources such as [The async book](https://rust-lang.github.io/async-book) and perhaps fasterthanlime's [Understanding Rust futures by going way too deep](https://fasterthanli.me/articles/understanding-rust-futures-by-going-way-too-deep) can serve as good starting points.
I'll attempt to give you some intuition.
The first clue comes from the question - when does Rust run two futures concurrently? There's the [join!](https://docs.rs/futures/latest/futures/macro.join.html) and [select!](https://docs.rs/futures/latest/futures/macro.select.html) macros, and the ability to [spawn](https://docs.rs/tokio/latest/tokio/task/fn.spawn.html) new async tasks. However, the Stream API neither `join` nor `select` over futures created by different pipeline steps, nor does it `spawn` new tasks each time it executes a future.
### A Deeper Dive
Let's take a closer look at our example and try to analyze the control flow.
```rust
let stream = stream::iter(0..10)
.map(async_work)
.buffered(5)
.filter_map(async_predicate);
pin!(stream);
while let Some(next) = stream.next().await {
println!("finished working on: {}", next);
}
```
First we create the stream instance. Futures in Rust aren't executed until they are `await`ed. Therefore, the first line of the example has no standalone effect.
Lets look at the type definition of the `stream` variable:
```rust
FilterMap<
Buffered>, fn async_work(i32) -> impl Future