- Download the mean SMPL parameters (initialization)
wget https://people.eecs.berkeley.edu/~kanazawa/cachedir/hmr/neutral_smpl_mean_params.h5
Store this inside hmr/models/, along with the neutral SMPL model
(neutral_smpl_with_cocoplus_reg.pkl).
- Download the pre-trained resnet-50 from Tensorflow
wget http:https://download.tensorflow.org/models/resnet_v2_50_2017_04_14.tar.gz && tar -xf resnet_v2_50_2017_04_14.tar.gz
- In
src/do_train.sh, replace the path ofPRETRAINEDto the path of this model (resnet_v2_50.ckpt).
Download these datasets somewhere.
- LSP and LSP extended
- COCO we used 2014 Train. You also need to install the COCO API for python.
- MPII
- MPI-INF-3DHP
- Human3.6M
For Human3.6M, download the pre-computed tfrecords here.
Note that this is 11GB! I advice you do this in a directly outside of the HMR code base.
The distribution of pre-computed Human3.6M tfrecord ended as of April 4th 2019, following their license agreement. The distribution of the data was not permitted at any time by the license or by the copyright holders. If you have obtained the data through our link prior to this date, please note that you must follow the original license agreement. Please download the
dataset directly from their website and follow their license agreement.
If you use the datasets above, please cite the original papers and follow the individual license agreement.
We provide the MoShed data using the neutral SMPL model. Please note that usage of this data is for non-comercial scientific research only.
If you use any of the MoSh data, please cite:
article{Loper:SIGASIA:2014,
title = {{MoSh}: Motion and Shape Capture from Sparse Markers},
author = {Loper, Matthew M. and Mahmood, Naureen and Black, Michael J.},
journal = {ACM Transactions on Graphics, (Proc. SIGGRAPH Asia)},
volume = {33},
number = {6},
pages = {220:1--220:13},
publisher = {ACM},
address = {New York, NY, USA},
month = nov,
year = {2014},
url = {http:https://doi.acm.org/10.1145/2661229.2661273},
month_numeric = {11}
}
All the data has to be converted into TFRecords and saved to a DATA_DIR of
your choice.
- Make
DATA_DIRwhere you will save the tf_records. For ex:
mkdir ~/hmr/tf_datasets/
-
Edit
prepare_datasets.sh, with paths to where you downloaded the datasets, and setDATA_DIRto the path to the directory you just made. -
From the root HMR directly (where README is), run
prepare_datasets.sh, which calls the tfrecord conversion scripts:
sh prepare_datasets.sh
This takes a while! If there is an issue consider running line by line.
- Move the downloaded human36m tf_records
tf_records_human36m.tar.gzinto thedata_dir:
tar -xf tf_records_human36m.tar.gz
- In
do_train.shand/orsrc/config.py, setDATA_DIRto the path where you saved the tf_records.
Finally we can start training!
A sample training script (with parameters used in the paper) is in
do_train.sh.
Update the path to in the beginning of this script and run:
sh do_train.sh
The training write to a log directory that you can specify.
Setup tensorboard to this directory to monitor the training progress like so:
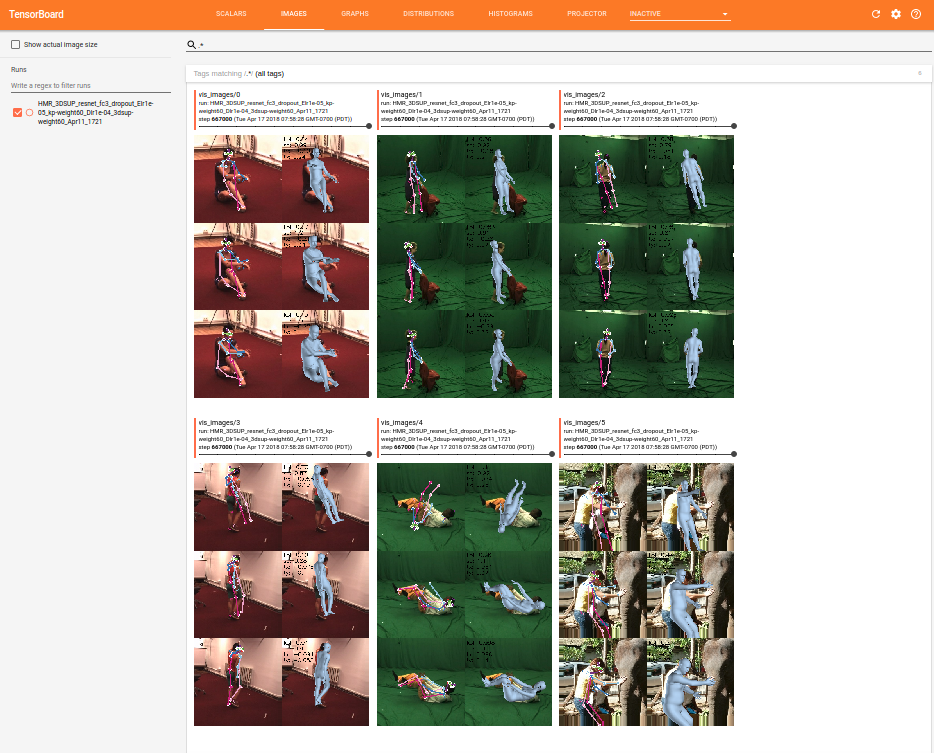
It's important to visually monitor the training! Make sure that the images loaded look right.
Provided is an evaluation code for Human3.6M. It uses the test tf_records,
provided with the training tf_records available above and [here]
As of April 4th 2019, we do not make pre-computed tfrecords available for
Human3.6M due to the request from the authors of Human3.6M. Please download the
dataset directly from their website.
To evaluate a model, run
python -m src.benchmark.evaluate_h36m --batch_size=500
--load_path=<model_to_eval.ckpt> --tfh36m_dir <path to tf_records_human36m_wjoints/>
for example for the provided model, use:
python -m src.benchmark.evaluate_h36m --batch_size=500
--load_path=models/model.ckpt-667589 --tfh36m_dir <path to tf_records_human36m_wjoints/>
This writes intermediate output to a temp directory, which you can specify by pred_dir With the provided model, this outputs errors per action and overall MPE for P1 (corresponding to Table 2 in paper -- this retrained model gets slightly lower MPJPE and a comparable PA-MPJPE):
MPJPE: 86.20, PA-MPJPE: 58.47, Median: 79.47, PA-Median: 52.95
Run it with --vis option, it visualizes the top/worst 30 results.