You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
在信号处理、图像处理和其它工程/科学领域,卷积都是一种使用广泛的技术,卷积神经网络(CNN)这种模型架构就得名于卷积计算。但是,深度学习领域的“卷积”本质上是信号/图像处理领域内的互相关(cross-correlation),互相关与卷积实际上还是有些差异的。 卷积是分析数学中一种重要的运算。简单定义f , g 是可积分的函数,两者的卷积运算如下:
其定义是两个函数中一个函数(g)经过反转和位移后再相乘得到的积的积分。如下图,函数 g 是过滤器。它被反转后再沿水平轴滑动。在每一个位置,我们都计算 f 和反转后的 g 之间相交区域的面积。这个相交区域的面积就是特定位置出的卷积值。
互相关是两个函数之间的滑动点积或滑动内积。互相关中的过滤器不经过反转,而是直接滑过函数 f,f 与 g 之间的交叉区域即是互相关。
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
import keras
import os
# 数据,切分为训练和测试集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
展示数据集,共有10类图像:
# 展示数据集
import matplotlib.pyplot as plt
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[y_train[i][0]])
plt.show()
一、卷积神经网络简介
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算的前馈神经网络,是基于图像任务的平移不变性(图像识别的对象在不同位置有相同的含义)设计的,擅长应用于图像处理等任务。在图像处理中,图像数据具有非常高的维数(高维的RGB矩阵表示),因此训练一个标准的前馈网络来识别图像将需要成千上万的输入神经元,除了显而易见的高计算量,还可能导致许多与神经网络中的维数灾难相关的问题。

对于高维图像数据,卷积神经网络利用了卷积和池化层,能够高效提取图像的重要“特征”,再通过后面的全连接层处理“压缩的图像信息”及输出结果。对比标准的全连接网络,卷积神经网络的模型参数大大减少了。

二、卷积神经网络的“卷积”
2.1 卷积运算的原理
在信号处理、图像处理和其它工程/科学领域,卷积都是一种使用广泛的技术,卷积神经网络(CNN)这种模型架构就得名于卷积计算。但是,深度学习领域的“卷积”本质上是信号/图像处理领域内的互相关(cross-correlation),互相关与卷积实际上还是有些差异的。
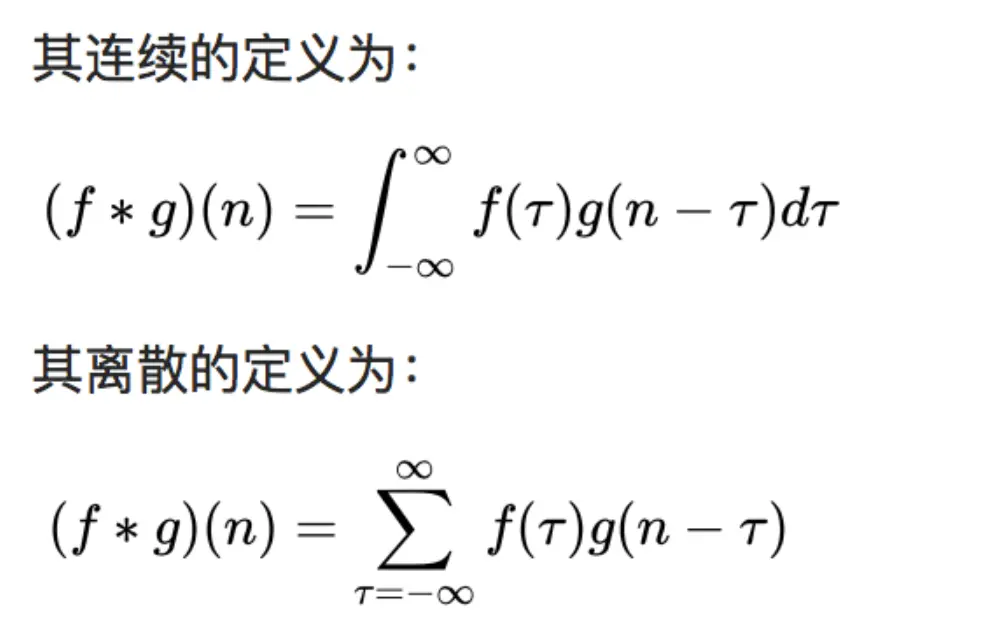
卷积是分析数学中一种重要的运算。简单定义f , g 是可积分的函数,两者的卷积运算如下:
其定义是两个函数中一个函数(g)经过反转和位移后再相乘得到的积的积分。如下图,函数 g 是过滤器。它被反转后再沿水平轴滑动。在每一个位置,我们都计算 f 和反转后的 g 之间相交区域的面积。这个相交区域的面积就是特定位置出的卷积值。

互相关是两个函数之间的滑动点积或滑动内积。互相关中的过滤器不经过反转,而是直接滑过函数 f,f 与 g 之间的交叉区域即是互相关。
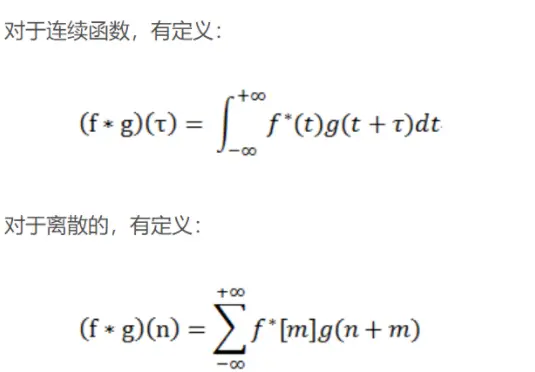
下图展示了卷积与互相关运算过程,相交区域的面积变化的差异:

在卷积神经网络中,卷积中的过滤器不经过反转。严格来说,这是离散形式的互相关运算,本质上是执行逐元素乘法和求和。但两者的效果是一致,因为过滤器的权重参数是在训练阶段学习到的,经过训练后,学习得到的过滤器看起来就会像是反转后的函数。
2.2 卷积运算的作用
CNN通过设计的卷积核(convolution filter,也称为kernel)与图片做卷积运算(平移卷积核去逐步做乘积并求和)。

如下示例设计一个(特定参数)的3×3的卷积核:
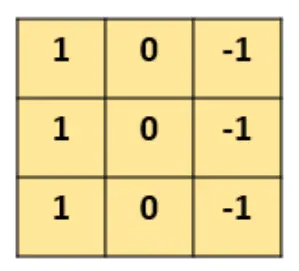
让它去跟图片做卷积,卷积的具体过程是:
可以发现,通过特定的filter,让它去跟图片做卷积,就可以提取出图片中的某些特征,比如边界特征。
进一步的,我们可以借助庞大的数据,足够深的神经网络,使用反向传播算法让机器去自动学习这些卷积核参数,不同参数卷积核提取特征也是不一样的,就能够提取出局部的、更深层次和更全局的特征以应用于决策。

卷积运算的本质性总结:过滤器(g)对图片(f)执行逐步的乘法并求和,以提取特征的过程。卷积过程可视化可访问:https://poloclub.github.io/cnn-explainer/ 或 https://github.com/vdumoulin/conv_arithmetic
三、卷积神经网络
卷积神经网络通常由3个部分构成:卷积层,池化层,全连接层。简单来说,卷积层负责提取图像中的局部及全局特征;池化层用来大幅降低参数量级(降维);全连接层用于处理“压缩的图像信息”并输出结果。

3.1 卷积层(CONV)
3.1.1 卷积层基本属性
卷积层主要功能是动态地提取图像特征,由滤波器filters和激活函数构成。一般要设置的超参数包括filters的数量、大小、步长,激活函数类型,以及padding是“valid”还是“same”。
卷积核大小(Kernel):直观理解就是一个滤波矩阵,普遍使用的卷积核大小为3×3、5×5等。在达到相同感受野的情况下,卷积核越小,所需要的参数和计算量越小。卷积核大小必须大于1才有提升感受野的作用,而大小为偶数的卷积核即使对称地加padding也不能保证输入feature map尺寸和输出feature map尺寸不变(假设n为输入宽度,d为padding个数,m为卷积核宽度,在步长为1的情况下,如果保持输出的宽度仍为n,公式,n+2d-m+1=n,得出m=2d+1,需要是奇数),所以一般都用3作为卷积核大小。
卷积核数目:主要还是根据实际情况调整, 一般都是取2的整数次方,数目越多计算量越大,相应模型拟合能力越强。
步长(Stride):卷积核遍历特征图时每步移动的像素,如步长为1则每次移动1个像素,步长为2则每次移动2个像素(即跳过1个像素),以此类推。步长越小,提取的特征会更精细。
填充(Padding):处理特征图边界的方式,一般有两种,一种是“valid”,对边界外完全不填充,只对输入像素执行卷积操作,这样会使输出特征图像尺寸变得更小,且边缘信息容易丢失;另一种是还是“same”,对边界外进行填充(一般填充为0),再执行卷积操作,这样可使输出特征图的尺寸与输入特征图的尺寸一致,边缘信息也可以多次计算。
通道(Channel):卷积层的通道数(层数)。如彩色图像一般都是RGB三个通道(channel)。
激活函数:主要还是根据实际验证,通常选择Relu。
另外的,卷积的类型除了标准卷积,还演变出了反卷积、可分离卷积、分组卷积等各种类型,可以自行验证。
3.1.2 卷积层的特点
通过卷积运算的介绍,可以发现卷积层有两个主要特点:局部连接(稀疏连接)和权值共享。
局部连接,就是卷积层的节点仅仅和其前一层的部分节点相连接,只用来学习局部区域特征。(局部连接感知结构的理念来源于动物视觉的皮层结构,其指的是动物视觉的神经元在感知外界物体的过程中起作用的只有一部分神经元。)
权值共享,同一卷积核会和输入图片的不同区域作卷积,来检测相同的特征,卷积核上面的权重参数是空间共享的,使得参数量大大减少。

由于局部连接(稀疏连接)和权值共享的特点,使得CNN具有仿射的不变性(平移、缩放等线性变换)
3.2 池化层(Pooling)
池化层可对提取到的特征信息进行降维,一方面使特征图变小,简化网络计算复杂度;另一方面进行特征压缩,提取主要特征,增加平移不变性,减少过拟合风险。 但其实池化更多程度上是一种计算性能的一个妥协,强硬地压缩特征的同时也损失了一部分信息,所以现在的网络比较少用池化层或者使用优化后的如SoftPool。
池化层设定的超参数,包括池化层的类型是Max还是Average(Average对背景保留更好,Max对纹理提取更好),窗口大小以及步长等。如下的MaxPooling,采用了一个2×2的窗口,并取步长stride=2,提取出各个窗口的max值特征(AveragePooling就是平均值):
3.3 全连接层(FC)
在经过数次卷积和池化之后,我们最后会先将多维的图像数据进行压缩“扁平化”, 也就是把 (height,width,channel) 的数据压缩成长度为 height × width × channel 的一维数组,然后再与全连接层连接(这也就是传统全连接网络层,每一个单元都和前一层的每一个单元相连接,需要设定的超参数主要是神经元的数量,以及激活函数类型),通过全连接层处理“压缩的图像信息”并输出结果。
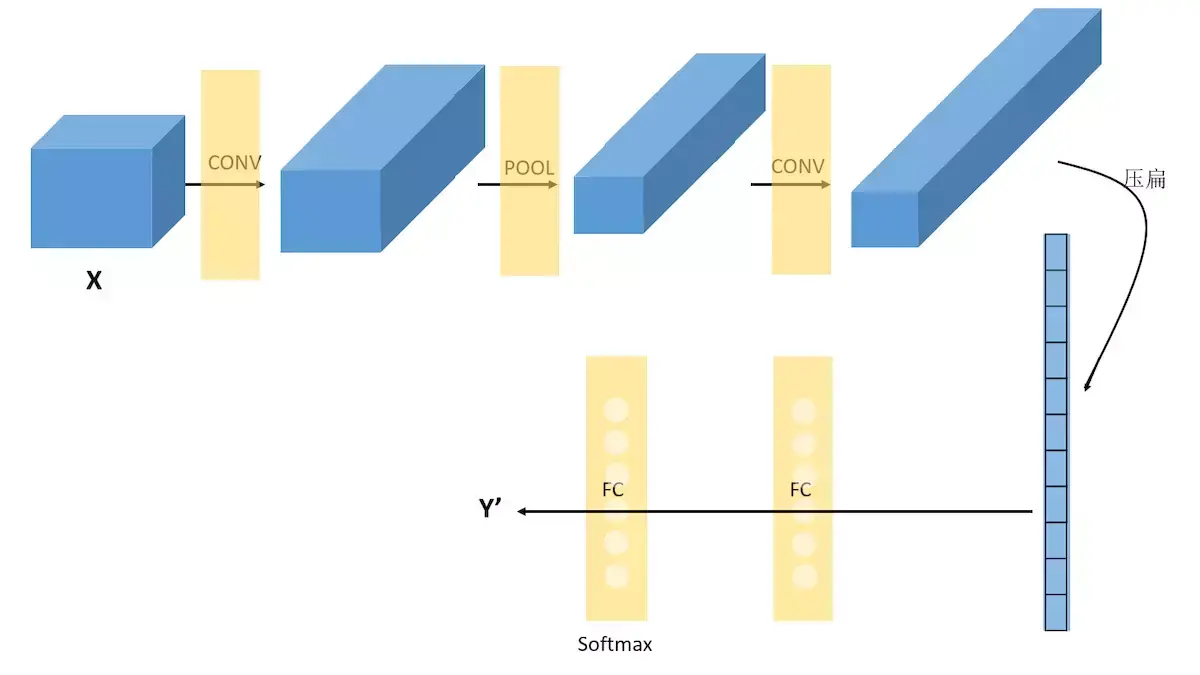
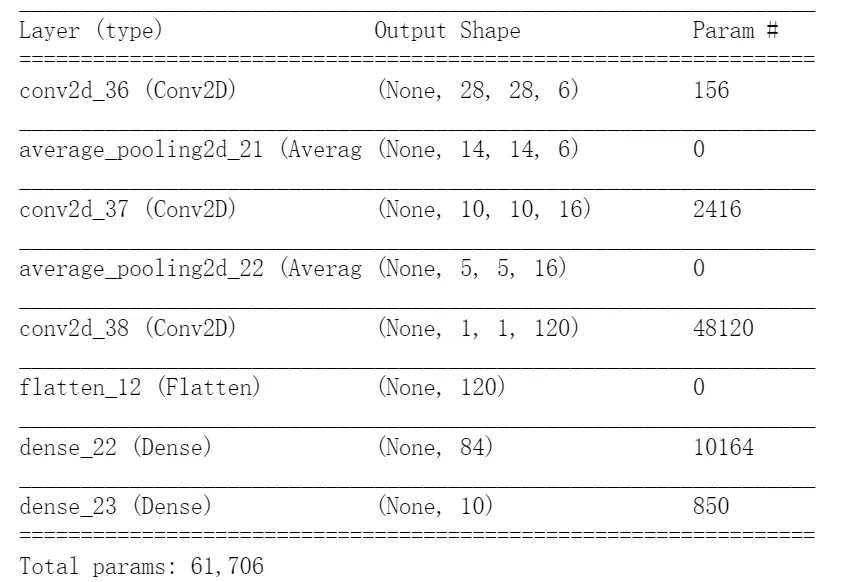
3.4 示例:经典CNN的构建(Lenet-5)
LeNet-5由Yann LeCun设计于 1998年,是最早的卷积神经网络之一。它是针对灰度图进行训练的,输入图像大小为32321,不包含输入层的情况下共有7层。下面逐层介绍LeNet-5的结构:
第一层是卷积层,用于过滤噪音,提取关键特征。使用5 * 5大小的过滤器6个,步长s = 1,padding = 0。
第二层是平均池化层,利用了图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息,降低网络训练参数及模型的过拟合程度。使用2 * 2大小的过滤器,步长s = 2,padding = 0。池化层只有一组超参数pool_size 和 步长strides,没有需要学习的模型参数。
第三层使用5 * 5大小的过滤器16个,步长s = 1,padding = 0。
第四层使用2 * 2大小的过滤器,步长s = 2,padding = 0。没有需要学习的参数。
第五层是卷积层,有120个5 * 5 的单元,步长s = 1,padding = 0。
有84个单元。每个单元与F5层的全部120个单元之间进行全连接。
Output层也是全连接层,采用RBF网络的连接方式(现在主要由Softmax取代,如下示例代码),共有10个节点,分别代表数字0到9(因为Lenet用于输出识别数字的),如果节点i的输出值为0,则网络识别的结果是数字i。
如下Keras复现Lenet-5:
四、keras实战CNN图像分类
文章首发公众号“算法进阶”,公众号阅读原文可访问文章相关代码
The text was updated successfully, but these errors were encountered: