You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
机器学习作为人工智能领域的核心组成,是非显式的计算机程序学习数据经验以优化自身算法,以学习处理任务的过程。一个经典的机器学习的定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.(一个计算机程序在处理任务T上的指标表现P可以随着学习经验E积累而提高。)
4.1 机器学习简介
机器学习看似高深的术语,其实就在生活中,古语有云:“一叶落而知天下秋”,意思是从一片树叶的凋落,就可以知道秋天将要到来。这其中蕴含了朴素的机器学习的思想,揭示了可以通过学习对“落叶”特征的经验,预判秋天的到来。

机器学习作为人工智能领域的核心组成,是非显式的计算机程序学习数据经验以优化自身算法,以学习处理任务的过程。一个经典的机器学习的定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.(一个计算机程序在处理任务T上的指标表现P可以随着学习经验E积累而提高。)
如图4.1 ,任务T即是机器学习系统如何正确处理数据样本。
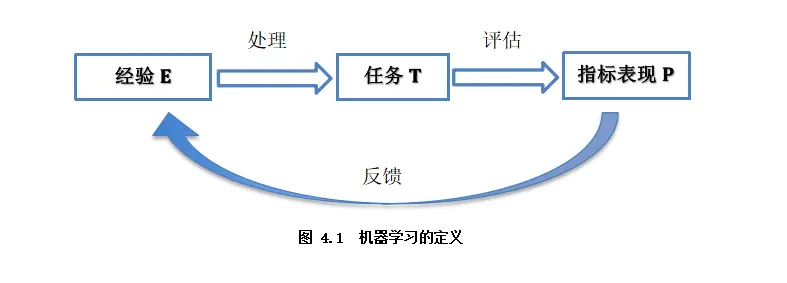
指标表现P即是衡量任务正确处理的情况。
经验E可以体现在模型学习处理任务后的自身的参数值。模型参数意义即如何对各特征的有效表达以处理任务。
进一步的,机器学习的过程一般可以概括为:计算机程序基于给定的、有限的学习数据出发(常基于每条数据样本是独立同分布的假设),选择某个的模型方法(即假设要学习的模型属于某个函数的集合,也称为假设空间),通过算法更新模型的参数值(经验),以优化处理任务的指标表现,最终学习出较优的模型,并运用模型对数据进行分析与预测以完成任务。由此可见,机器学习方法有四个要素:
我们通过将机器学习方法归纳为四个要素及其相应地介绍,便于更好地理解各种算法原理的共性所在,而不是独立去理解各式各样的机器学习方法。
4.1.1 数据
数据是机器学习方法的基础的原料,它通常由一条条数据(每一行)样本组成,样本由描述其各个维度信息的特征及目标值标签(或无)组成。

如图4.2所示癌细胞分类任务的数据集:
4.1.2 模型
学习到“好”的模型是机器学习的直接目的。机器学习模型简单来说,即是学习数据特征与标签的关系或者学习数据特征内部的规律的一个函数。
机器学习模型可以看作是(如图4.3):首先选择某个的模型方法,再从数据样本(x,(y))中学习,优化模型参数w以调整各特征的有效表达,最终获得对应的决策函数f( x; w )。该函数将输入变量 x 在参数w作用下映射到输出预测Y,即Y= f(x; w)。
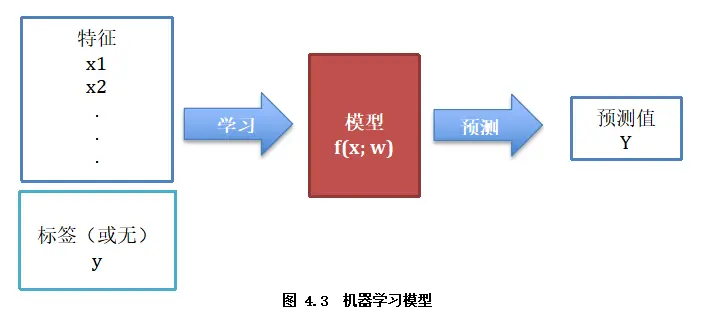
4.1.3 学习目标
学习到“好”的模型,“好”即是模型的学习目标。“好”对于模型也就是预测值与实际值之间的误差尽可能的低。具体衡量这种误差的函数称为代价函数 (Cost Function)或者损失函数(Loss Function),我们即通过以极大化降低损失函数为目标去学习模型。
对于不同的任务目标,往往也需要用不同损失函数衡量,经典的损失函数如:回归任务的均方误差损失函数及分类任务的交叉熵损失函数等。
- 均方误差损失函数
衡量模型回归预测的误差情况,我们可以简单地用所有样本的预测值减去实际值求平方后的平均值,这也就是均方误差(Mean Squared Error)损失函数。
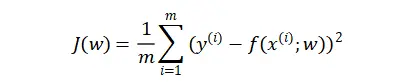
衡量分类预测模型的误差情况,常用极大似然估计法推导出的交叉熵损失函数。通过极小化交叉熵损失,使得模型预测分布尽可能与实际数据经验分布一致。
4.1.4 优化算法
有了极大化降低损失函数为目标去学习“好”模型,而如何达到这目标?我们第一反应可能是直接求解损失函数最小值的解析解,获得最优的模型参数。遗憾的是,机器学习模型的损失函数通常较复杂,很难直接求最优解。幸运的是,我们可以通过优化算法(如梯度下降算法、牛顿法等)有限次迭代优化模型参数,以尽可能降低损失函数的值,得到较优的参数值(数值解)。
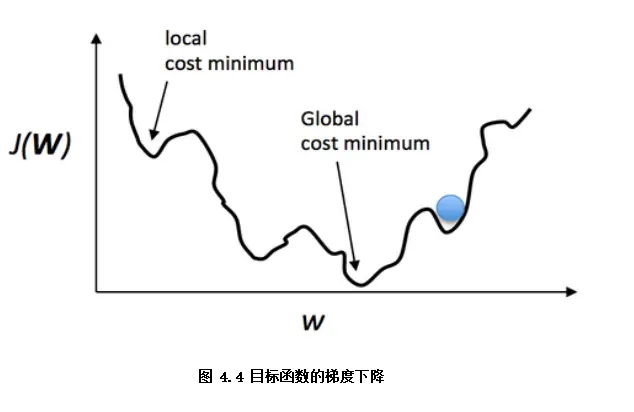
梯度下降算法如图4.4,可以直观理解成一个下山的过程,将损失函数J(w)比喻成一座山,我们的目标是到达这座山的山脚(即求解最优模型参数w使得损失函数为最小值)。
要做的无非就是“往下坡的方向走,走一步算一步”,而下坡的方向也就是J(w)负梯度的方向,在每往下走到一个位置的时候,求解当前位置的梯度,向这一步所在位置沿着最陡峭最易下山的位置再走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。
当然这样走下去,有可能我们不是走到山脚(全局最优),而是到了某一个的小山谷(局部最优),这也后面梯度下降算法的调优的地方。
对应到算法步骤:

小结
本文我们首先介绍了机器学习的基本概念,并概括机器学习的一般过程:从数据出发,通过设定了任务的学习目标,使用算法优化模型参数去达到目标。由此,重点引出了机器学习的四个组成要素(数据、模型、学习目标及优化算法),接下来我们会进一步了解机器学习算法的类别。
文章首发于算法进阶,公众号阅读原文可访问GitHub项目源码
The text was updated successfully, but these errors were encountered: