/path/to/flink/conf/
flink-conf.yaml
jobmanager.rpc.address: 10.0.0.1
/path/to/flink/
conf/slaves
10.0.0.2 10.0.0.3
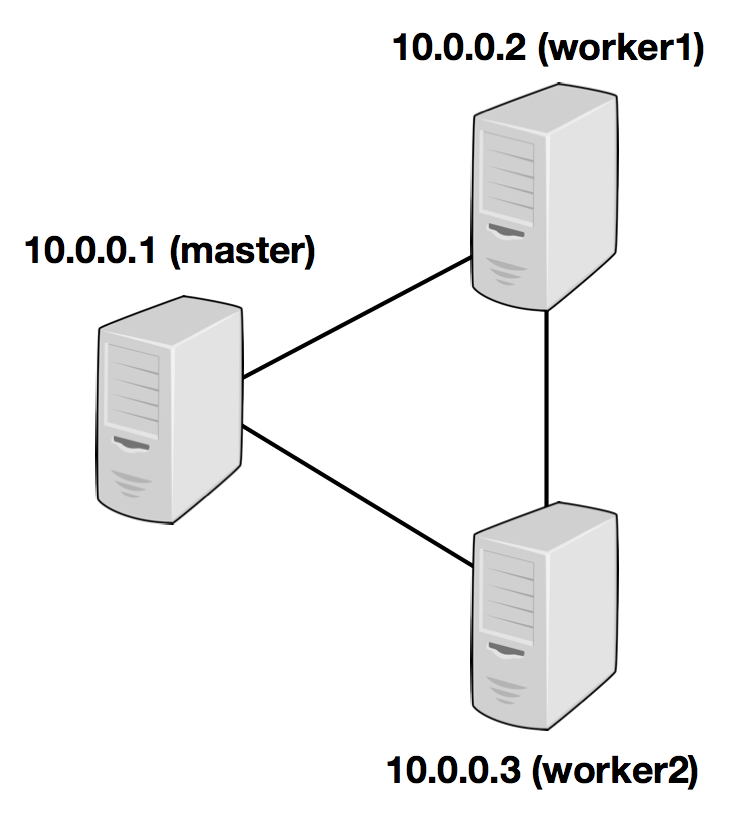
## Start 1. Go to the download directory. 2. Unpack the downloaded archive. 3. Start Flink. ~~~bash $ cd ~/Downloads # Go to download directory $ tar xzf flink-*.tgz # Unpack the downloaded archive $ cd flink-{{site.FLINK_VERSION_SHORT}} $ bin/start-local.sh # Start Flink ~~~ Check the __JobManager's web frontend__ at [http://localhost:8081](http://localhost:8081) and make sure everything is up and running. ## Run Example Run the __Word Count example__ to see Flink at work. * __Download test data__: ~~~bash $ wget -O hamlet.txt http://www.gutenberg.org/cache/epub/1787/pg1787.txt ~~~ * You now have a text file called _hamlet.txt_ in your working directory. * __Start the example program__: ~~~bash $ bin/flink run ./examples/flink-java-examples-{{site.FLINK_VERSION_SHORT}}-WordCount.jar file://`pwd`/hamlet.txt file://`pwd`/wordcount-result.txt ~~~ * You will find a file called __wordcount-result.txt__ in your current directory. ## Cluster Setup __Running Flink on a cluster__ is as easy as running it locally. Having __passwordless SSH__ and __the same directory structure__ on all your cluster nodes lets you use our scripts to control everything. 1. Copy the unpacked __flink__ directory from the downloaded archive to the same file system path on each node of your setup. 2. Choose a __master node__ (JobManager) and set the `jobmanager.rpc.address` key in `conf/flink-conf.yaml` to its IP or hostname. Make sure that all nodes in your cluster have the same `jobmanager.rpc.address` configured. 3. Add the IPs or hostnames (one per line) of all __worker nodes__ (TaskManager) to the slaves files in `conf/slaves`. You can now __start the cluster__ at your master node with `bin/start-cluster.sh`. The following __example__ illustrates the setup with three nodes (with IP addresses from _10.0.0.1_ to _10.0.0.3_ and hostnames _master_, _worker1_, _worker2_) and shows the contents of the configuration files, which need to be accessible at the same path on all machines:
/path/to/flink/conf/
flink-conf.yaml
jobmanager.rpc.address: 10.0.0.1
/path/to/flink/
conf/slaves
10.0.0.2 10.0.0.3