Sentiment Analysis for reviews using IMDB Dataset with CNN and LSTM
- get data: download IMDB Dataset and Glove embeddings.
- Clone and unzip this repo.
- modify variables
dataset_dirandglove_dirinsaverData.pywith your absolute path to dataset and embedding directory. - Run
saverData.py, this will load your dataset and embedding, saving them in numpy format. - Run one of the following:
mainBIDIRLSTM.py,mainCNNnonstatic.py,mainCNNrand.py,mainCNNstatic.py,mainDOBLE.py,mainLSTM.py
| - | Time |
|---|---|
| CPU | ~ 6 H |
| GPU | ~ 10 m |
Sentiment Analysis is the process of determining whether a piece of writing is positive, negative or neutral. It’s also known as opinion mining, deriving the opinion or attitude of a speaker. A common use case for this technology is to discover how people feel about a particular topic. In this case, the goal is to determine if a movie review is either positive or negative using various deep learning techniques.
I chose the IMDB dataset (Maas et al., 2011) which contains 50,000 sentences split equally into training and testing sets. Each training instance contains an entire review written by one individual.
I also loaded pre-trained word embeddings from GloVe composed of 400K vocab using 300D vectors.
Word embedding is a technique where words are encoded as real-valued vectors in a high-dimensional space, where the similarity between words in terms of meaning translates to closeness in the vector space. One simple way to understand this is to look at the following image:

When we inspect these visualizations it becomes apparent that the vectors capture some general, and in fact quite useful, semantic information about words and their relationships to one another.
Using PCA to reduce 300D word embeddings to 50D and then t-sne to 3D:

This project was implemented using Keras framework with Tensorflow backend.
After loading text data, and embedding file, I create an embedding_matrix with as many entries as unique words in training data (111525 unique tokens), where each row is the equivalent embedding representation. If the word is not present in the embedding file, it's representation would be simply a vector of zeros.
Moreover, I needed to PAD each review to a fixed length. I decided MAX_SEQUENCE_LENGTH to be 500 based on following plots:
 |
 |
|---|---|
| Box and Whisker | Histogram |
The mean number of word per review is 230 with a variance of 171. Using MAX_SEQUENCE_LENGTH = 500 you can cover the majority of reviews and remove the outliers with too many words.
Essentially three different architectures were used:
- Only CNN (non-static/static/random)
- Only LSTM (and BiDirectional LSTM)
- Both CNN and LSTM
Using trainable word embedding.
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedding_layer = Embedding(len(word_index)+1, EMBEDDING_DIM, weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH, trainable=True)
x = embedding_layer(sequence_input)
x = Dropout(0.5)(x)
x = Conv1D(200, 5, activation='relu', kernel_regularizer=regularizers.l2(0.01))(x)
x = MaxPooling1D(pool_size=2)(x)
x = Dropout(0.5)(x)
x = Conv1D(200, 5, activation='relu', kernel_regularizer=regularizers.l2(0.01))(x)
x = Flatten()(x)
x = Dropout(0.5)(x)
x = Dense(180,activation='sigmoid', kernel_regularizer=regularizers.l2(0.05))(x)
x = Dropout(0.5)(x)
prob = Dense(1, activation='sigmoid')(x)
model = Model(sequence_input, prob)
optimizer = optimizers.Adam(lr=0.00035)
model.compile(loss='binary_crossentropy',optimizer=optimizer, metrics=['accuracy', 'mae'])
Using non trainable word embedding.
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedding_layer = Embedding(len(word_index)+1, EMBEDDING_DIM, weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH, trainable=False)
x = embedding_layer(sequence_input)
x = Dropout(0.3)(x)
x = Conv1D(25, 5, activation='relu')(x)
x = MaxPooling1D(pool_size=2)(x)
x = Dropout(0.3)(x)
x = Conv1D(20, 5, activation='relu')(x)
x = Flatten()(x)
x = Dropout(0.3)(x)
x = Dense(120,activation='sigmoid')(x)
x = Dropout(0.3)(x)
prob = Dense(1, activation='sigmoid')(x)
model = Model(sequence_input, prob)
optimizer = optimizers.Adam(lr=0.001)
model.compile(loss='binary_crossentropy',optimizer=optimizer, metrics=['accuracy', 'mae'])Total params: 34,023,686
Trainable params: 565,886
Non-trainable params: 33,457,800
Without using word embedding.
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedding_layer = Embedding(len(word_index)+1, EMBEDDING_DIM, input_length=MAX_SEQUENCE_LENGTH, trainable=True)
filtersize_list = [3, 8]
number_of_filters_per_filtersize = [10, 10]
pool_length_list = [2, 2]
dropout_list = [0.5, 0.5]
input_node = Input(shape=(MAX_SEQUENCE_LENGTH, EMBEDDING_DIM))
conv_list = []
for index, filtersize in enumerate(filtersize_list):
nb_filter = number_of_filters_per_filtersize[index]
pool_length = pool_length_list[index]
conv = Conv1D(filters=nb_filter, kernel_size=filtersize, activation='relu')(input_node)
drop = Dropout(0.3)(conv)
pool = MaxPooling1D(pool_length=pool_length)(conv)
flatten = Flatten()(pool)
conv_list.append(flatten)
out = Merge(mode='concat')(conv_list)
graph = Model(input=input_node, output=out)
model = Sequential()
model.add(embedding_layer)
model.add(Dropout(dropout_list[0], input_shape=(MAX_SEQUENCE_LENGTH, EMBEDDING_DIM)))
model.add(graph)
model.add(Dense(50))
model.add(Activation('relu'))
model.add(Dropout(dropout_list[1]))
model.add(Dense(1, activation='sigmoid'))
optimizer = optimizers.Adam(lr=0.0004)
model.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['acc'])Total params: 5,779,421
Trainable params: 5,779,421
Non-trainable params: 0

sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedding_layer = Embedding(len(word_index)+1, EMBEDDING_DIM, weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH, trainable=False)
x = embedding_layer(sequence_input)
x = Dropout(0.3)(x)
x = LSTM(100)(x)
prob = Dense(1, activation='sigmoid')(x)
model = Model(sequence_input, prob)
model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy'])
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedding_layer = Embedding(len(word_index)+1, EMBEDDING_DIM, weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH, trainable=False)
x = embedding_layer(sequence_input)
x = Dropout(0.3)(x)
x = Bidirectional(LSTM(100))(x)
x = Dropout(0.3)(x)
prob = Dense(1, activation='sigmoid')(x)
model = Model(sequence_input, prob)
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedding_layer = Embedding(len(word_index)+1, EMBEDDING_DIM, weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH, trainable=False)
x = embedding_layer(sequence_input)
x = Dropout(0.3)(x)
x = Conv1D(200, 5, activation='relu')(x)
x = MaxPooling1D(pool_size=2)(x)
x = LSTM(100)(x)
x = Dropout(0.3)(x)
prob = Dense(1, activation='sigmoid')(x)
model = Model(sequence_input, prob)
optimizer = optimizers.Adam(lr=0.0004)
model.compile(loss='binary_crossentropy',optimizer=optimizer, metrics=['accuracy'])
Learning curves values for accuracy and loss are calculated during training using a validation set (10% of training set).
 |
 |
|---|---|
| Accuracy | Loss |
On entire Test Set: Accuracy = 89.96%
 |
 |
|---|---|
| Accuracy | Loss |
On entire Test Set: Accuracy = 88.98%
 |
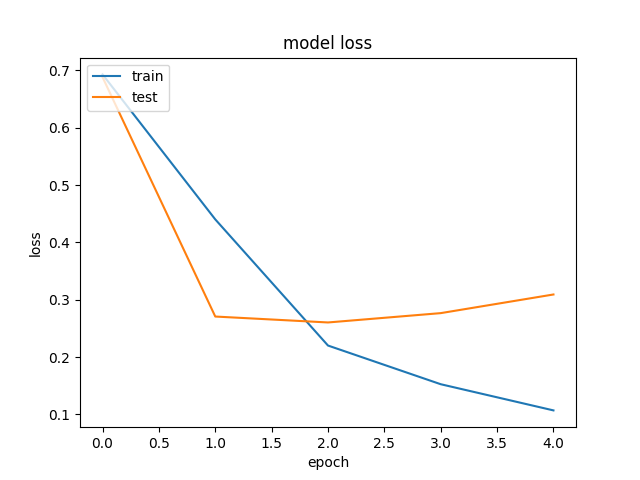 |
|---|---|
| Accuracy | Loss |
On entire Test Set: Accuracy = 87.72%
 |
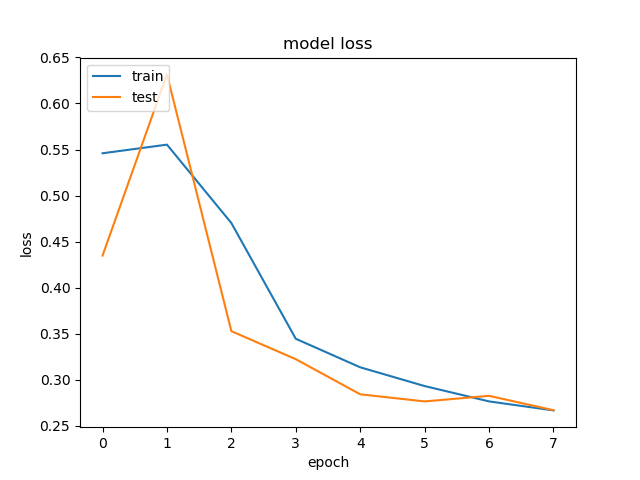 |
|---|---|
| Accuracy | Loss |
On entire Test Set: Accuracy = 88.92%
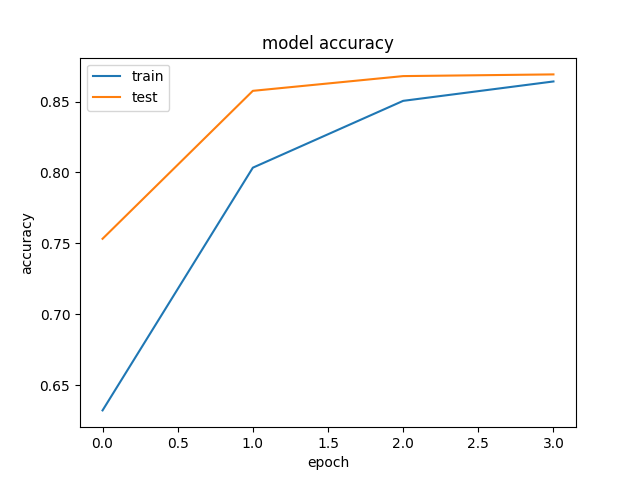 |
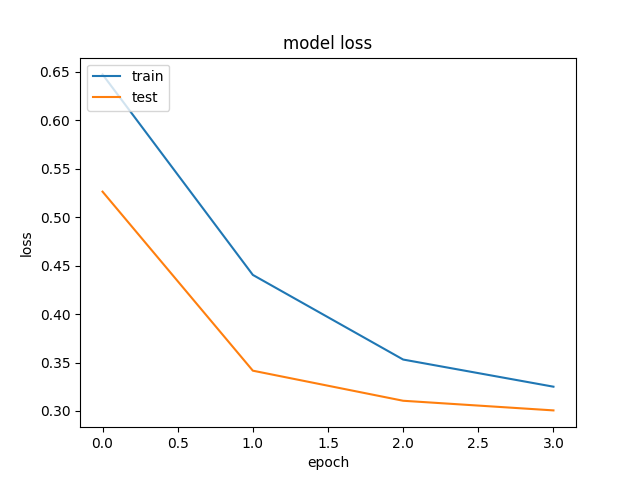 |
|---|---|
| Accuracy | Loss |
On entire Test Set: Accuracy = 87.96%
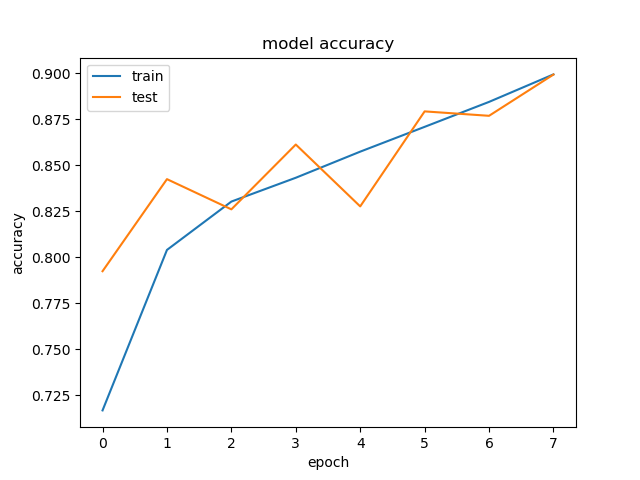 |
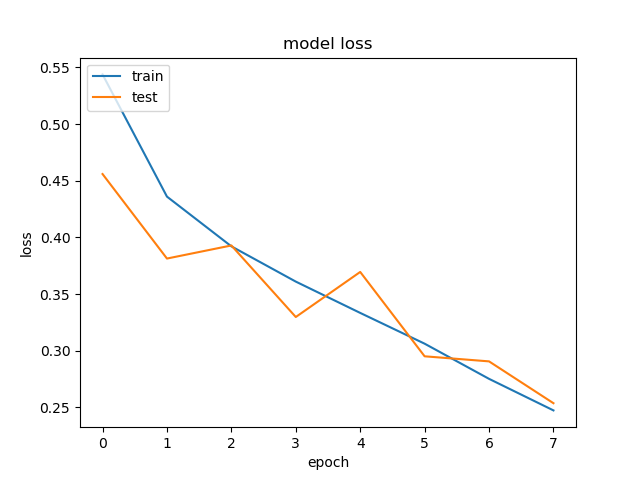 |
|---|---|
| Accuracy | Loss |
On entire Test Set: Accuracy = 90.14%
[1]: https://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/
[2]: https://machinelearningmastery.com/predict-sentiment-movie-reviews-using-deep-learning/
[3]: https://machinelearningmastery.com/predict-sentiment-movie-reviews-using-deep-learning/
[4]: Takeru Miyato, Andrew M. Dai and Ian Goodfellow (2016) -"Virtual Adversarial Training for Semi-Supervised Text Classification"- https://pdfs.semanticscholar.org/a098/6e09559fa6cc173d5c5740aa17030087f0c3.pdf
[5] Isaac Caswell, Onkur Sen and Allen Nie - "Exploring Adversarial Learning on Neural Network Models for Text Classification" - https://nlp.stanford.edu/courses/cs224n/2015/reports/20.pdf
[6] Yoon Kim - "Convolutional Neural Networks for Sentence Classification" - https://aclweb.org/anthology/D14-1181
[7] Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher - "Learning Word Vectors for Sentiment Analysis" - https://www.aclweb.org/anthology/P11-1015