-
Notifications
You must be signed in to change notification settings - Fork 1
/
setup.py
142 lines (116 loc) · 5.66 KB
/
setup.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
from setuptools import setup
setup(
name="timetomodel",
description="Sane handling of time series data for forecast modelling - with production usage in mind.",
author="Seita BV",
author_email="[email protected]",
url="https://github.com/seitabv/timetomodel",
keywords=["time series", "forecasting"],
version="0.7.3",
install_requires=[
"pandas >= 1.4.0",
"statsmodels",
"scikit-learn",
"matplotlib",
"numpy",
"scipy",
"pytz",
"python-dateutil >= 2.5",
"SQLAlchemy",
],
tests_require=["pytest"],
packages=["timetomodel", "timetomodel.utils"],
include_package_data=True,
classifiers=[
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :: Scientific/Engineering :: Information Analysis",
],
long_description="""\
# timetomodel
Time series forecasting is a modern data science & engineering challenge.
We noticed that these two worlds, data science and engineering of time series forecasting, are not very compatible.
Often, work from the data scientist has to be re-implemented by engineers to be used in production.
`timetomodel` was created to change that. It describes the data treatment of a model, and also automates common data treatment tasks like building data for training and testing.
As a *data scientist*, experiment with a model in your notebook.
Load data from static files (e.g. CSV) and try out lags, regressors and so on.
Compare plots and mean square errors of the models you developed.
As an *engineer*, take over the model description and use it in your production code.
Often, this would entail not much more than changing the data source (e.g from CSV to a column in the database).
`timetomodel` is supposed to wrap around any fit/predict type model, e.g. from statsmodels or scikit-learn (some work needed here to ensure support).
## Features
Here are some features for both data scientists and engineers to enjoy:
* Describe how to load data for outcome and regressor variables. Load from Pandas objects, CSV files, Pandas pickles or databases via SQLAlchemy.
* Create train & test data, including lags.
* Timezone awareness support.
* Custom data transformations, after loading (e.g. to remove duplicate) or only for forecasting (e.g. to apply a BoxCox transformation).
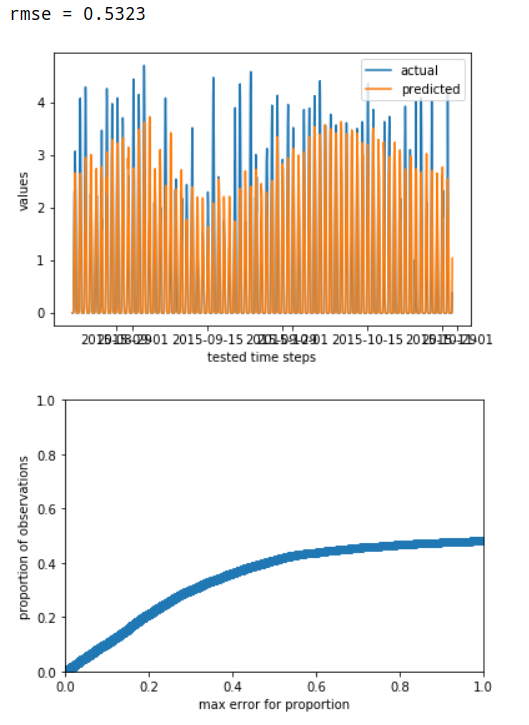
* Evaluate a model by RMSE, and plot the cumulative error.
* Support for creating rolling forecasts.
## Installation
``pip install timetomodel``
## Example
Here is an example where we describe a solar time series problem, and use ``statsmodels.OLS``, a linear regression model, to forecast one hour ahead:
import pandas as pd
import pytz
from datetime import datetime, timedelta
from statsmodels.api import OLS
from timetomodel import speccing, ModelState, create_fitted_model, evaluate_models
from timetomodel.transforming import BoxCoxTransformation
from timetomodel.forecasting import make_rolling_forecasts
data_start = datetime(2015, 3, 1, tzinfo=pytz.utc)
data_end = datetime(2015, 10, 31, tzinfo=pytz.utc)
#### Solar model - 1h ahead ####
# spec outcome variable
solar_outcome_var_spec = speccing.CSVFileSeriesSpecs(
file_path="data.csv",
time_column="datetime",
value_column="solar_power",
name="solar power",
feature_transformation=BoxCoxTransformation(lambda2=0.1)
)
# spec regressor variable
regressor_spec_1h = speccing.CSVFileSeriesSpecs(
file_path="data.csv",
time_column="datetime",
value_column="irradiation_forecast1h",
name="irradiation forecast",
feature_transformation=BoxCoxTransformation(lambda2=0.1)
)
# spec whole model treatment
solar_model1h_specs = speccing.ModelSpecs(
outcome_var=solar_outcome_var_spec,
model=OLS,
frequency=timedelta(minutes=15),
horizon=timedelta(hours=1),
lags=[lag * 96 for lag in range(1, 8)], # 7 days (data has daily seasonality)
regressors=[regressor_spec_1h],
start_of_training=data_start + timedelta(days=30),
end_of_testing=data_end,
ratio_training_testing_data=2/3,
remodel_frequency=timedelta(days=14) # re-train model every two weeks
)
solar_model1h = create_fitted_model(solar_model1h_specs, "Linear Regression Solar Horizon 1h")
# solar_model_1h is now an OLS model object which can be pickled and re-used.
# With the solar_model1h_specs in hand, your production code could always re-train a new one,
# if the model has become outdated.
# For data scientists: evaluate model
evaluate_models(m1=ModelState(solar_model1h, solar_model1h_specs))
# For engineers a): Change data sources to use database (hinted)
solar_model1h_specs.outcome_var = speccing.DBSeriesSpecs(query=...)
solar_model1h_specs.regressors[0] = speccing.DBSeriesSpecs(query=...)
# For engineers b): Use model to make forecasts for an hour
forecasts, model_state = make_rolling_forecasts(
start=datetime(2015, 11, 1, tzinfo=pytz.utc),
end=datetime(2015, 11, 1, 1, tzinfo=pytz.utc),
model_specs=solar_model1h_specs
)
# model_state might have re-trained a new model automatically, by honoring the remodel_frequency
""",
long_description_content_type="text/markdown",
)