PyTorch implementation of ICLR 2018 paper Learn To Pay Attention

My implementation is based on "(VGG-att3)-concat-pc" in the paper, and I trained the model on CIFAR-100 DATASET.
I implemented two version of the model, the only difference is whether to insert the attention module before or after the corresponding max-pooling layer.
- PyTorch (>=0.4.1)
- OpenCV
- tensorboardX
NOTE If you are using PyTorch < 0.4.1, then replace torch.nn.functional.interpolate by torch.nn.Upsample. (Modify the code in utilities.py).
- Pay attention before max-pooling layers
python train.py --attn_mode before --outf logs_before --normalize_attn --log_images
- Pay attention after max-pooling layers
python train.py --attn_mode after --outf logs_after --normalize_attn --log_images
The x-axis is # iter
-
Pay attention before max-pooling layers
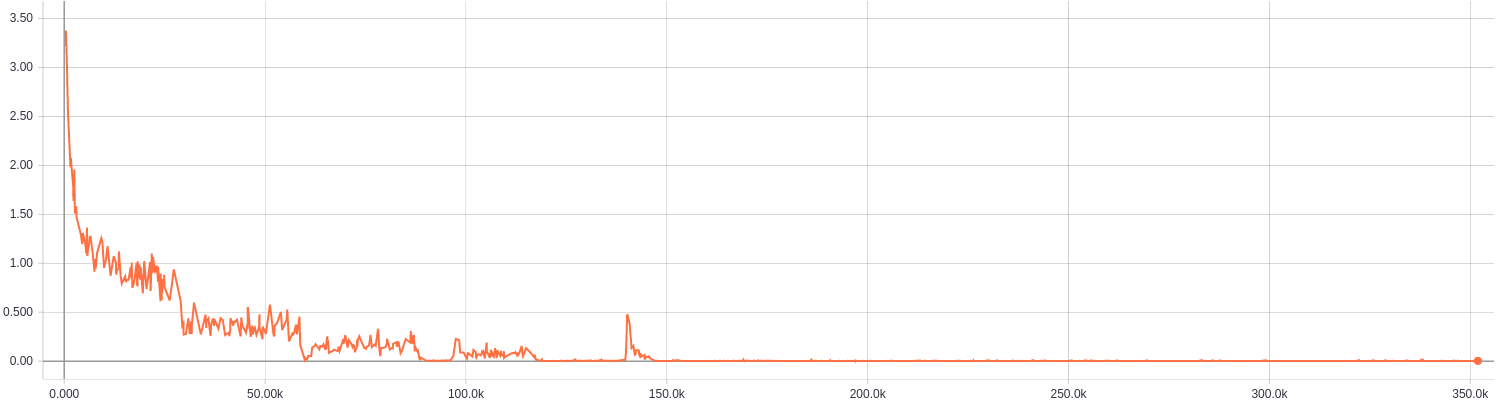
-
Pay attention after max-pooling layers

-
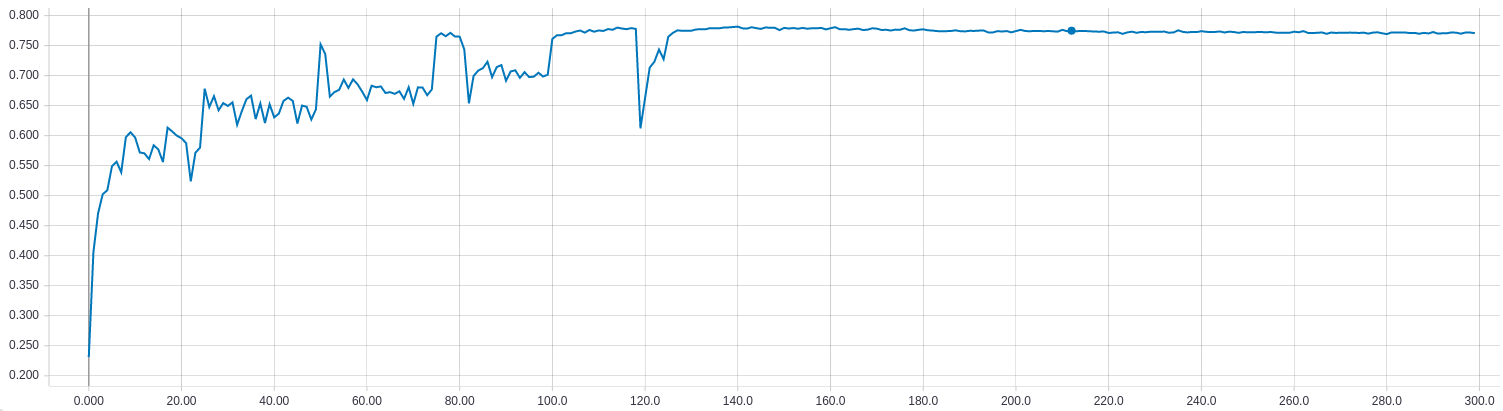
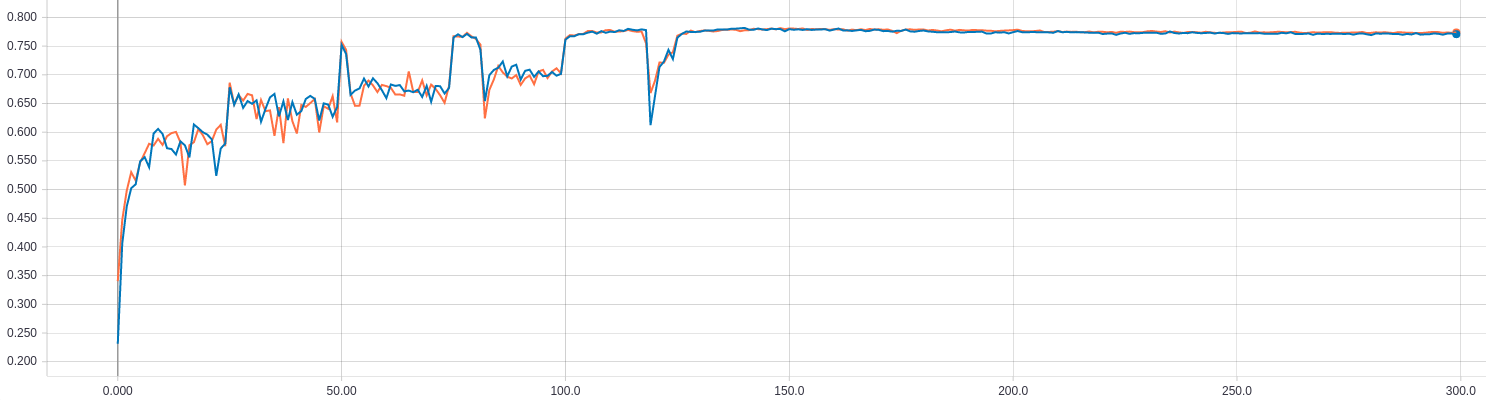
Plot in one figure
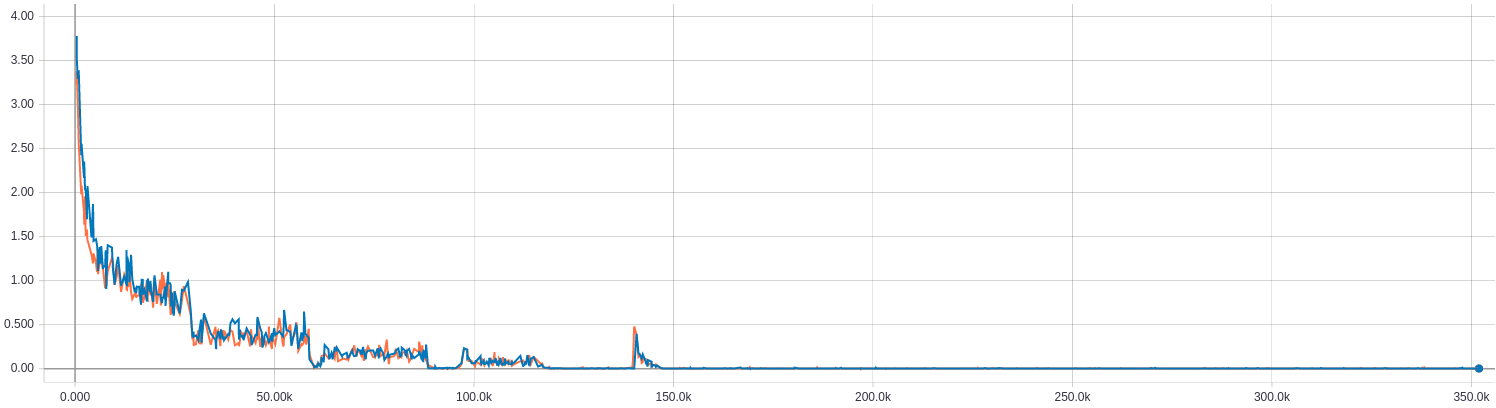



The x-axis is # epoch
-
Pay attention before max-pooling layers
-
Pay attention after max-pooling layers
-
Plot in one figure



| Method | VGG (Simonyan&Zisserman,2014) | (VGG-att3)-concat-pc (ICLR 2018) | attn-before-pooling (my code) | attn-after-pooling (my code) |
|---|---|---|---|---|
| Top-1 error | 30.62 | 22.97 | 22.62 | 22.92 |
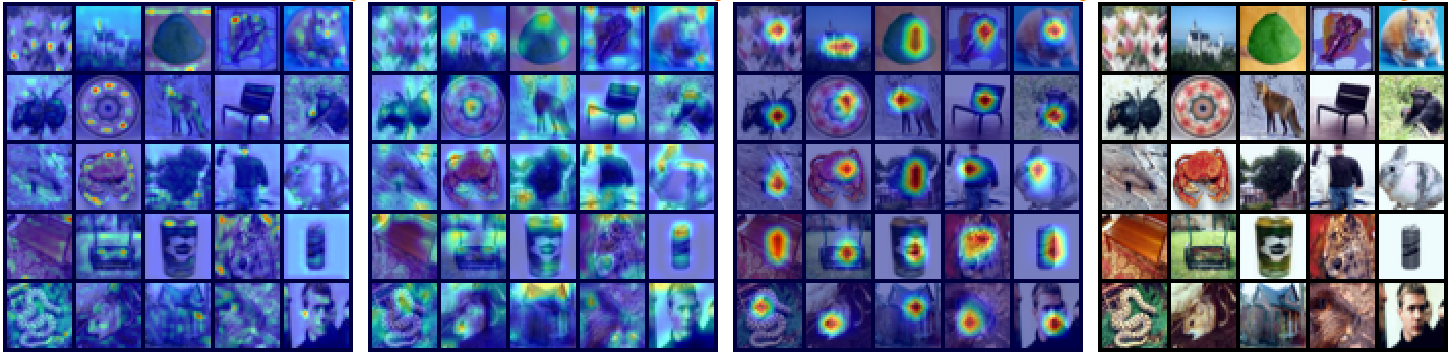
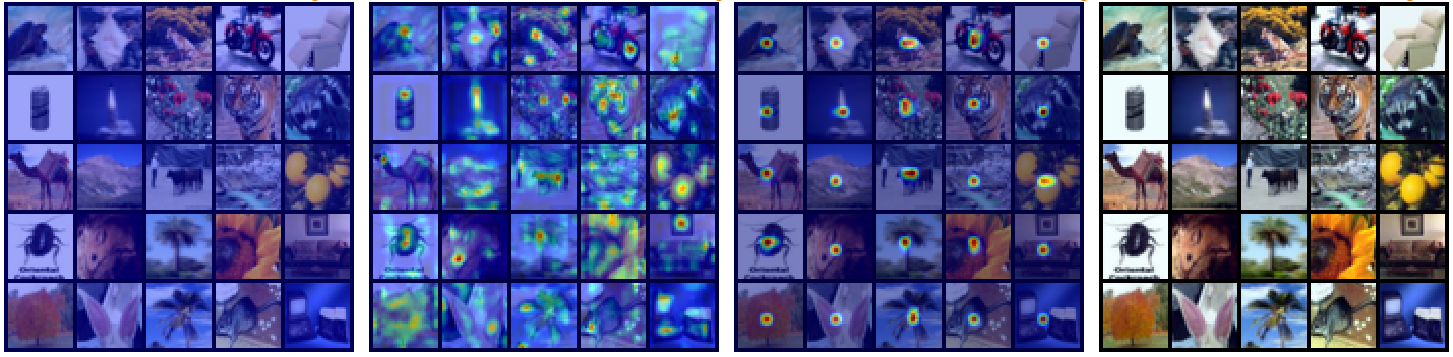
From left to right: L1, L2, L3, original images
-
Pay attention before max-pooling layers
-
Pay attention after max-pooling layers