Why Safety-Gymnasium? | Documentation | Install guide | Customization | Video
Safety-Gymnasium is a highly scalable and customizable Safe Reinforcement Learning (SafeRL) library. It aims to deliver a good view of benchmarking SafeRL algorithms and a standardized set of environments. We provide a set of standard APIs which are compatible with information on constraints. Users can explore new insights via an elegant code framework and well-designed environments.
If you find Safety-Gymnasium useful, please cite it in your publications.
@inproceedings{ji2023safety,
title={Safety Gymnasium: A Unified Safe Reinforcement Learning Benchmark},
author={Jiaming Ji and Borong Zhang and Jiayi Zhou and Xuehai Pan and Weidong Huang and Ruiyang Sun and Yiran Geng and Yifan Zhong and Josef Dai and Yaodong Yang},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2023},
url={https://openreview.net/forum?id=WZmlxIuIGR}
}We have updated the environments for both the Safe Vision series and the Safe Isaac Gym series. However, due to package size constraints, we have not yet uploaded versions v1.1.0 and v1.2.0 to PyPI. As a result, users are required to manually download and install. We currently recommend using GitHub's Download zip feature to obtain our package and access the latest environments. In the future, we plan to deploy resources separately to a cloud service to accommodate PyPI. Stay tuned for further updates.
Python 3.11 is not supported for now, due to the incompatibility of pygame.
conda create -n example python=3.8
conda activate example
wget https://github.com/PKU-Alignment/safety-gymnasium/archive/refs/heads/main.zip
unzip main.zip
cd safety-gymnasium-main
pip install -e .Here we provide a table for comparison of Safety-Gymnasium and existing SafeRL Environments libraries.
| SafeRL Envs |
Engine | Vectorized Environments |
New Gym API(3) | Vision Input |
|---|---|---|---|---|
| Safety-Gym |
mujoco-py(1) |
❌ | ❌ | minimally supported |
| safe-control-gym |
PyBullet | ❌ | ❌ | ❌ |
| Velocity-Constraints(2) | N/A | ❌ | ❌ | ❌ |
| mujoco-circle |
PyTorch | ❌ | ❌ | ❌ |
| Safety-Gymnasium |
MuJoCo 2.3.0+ | ✅ | ✅ | ✅ |
(1): Maintenance (expect bug fixes and minor updates); the last commit is 19 Nov 2021. Safety-Gym depends on mujoco-py 2.0.2.7, which was updated on Oct 12, 2019.
(2): There is no official library for speed-related environments, and its associated cost constraints are constructed from info. But the task is widely used in the study of SafeRL, and we encapsulate it in Safety-Gymnasium.
(3): In the gym 0.26.0 release update, a new API of interaction was redefined.
We designed a variety of safety-enhanced learning tasks and integrated the contributions from the RL community: safety-velocity, safety-run, safety-circle, safety-goal, safety-button, etc.
We introduce a unified safety-enhanced learning benchmark environment library called Safety-Gymnasium.
Further, to facilitate the progress of community research, we redesigned Safety-Gym and removed the dependency on mujoco-py.
We built it on top of MuJoCo and fixed some bugs, more specific bug reports can refer to Safety-Gym's BUG Report.
Here is a list of all the environments we support for now:
| Category | Task | Agent | Example |
|---|---|---|---|
| Safe Navigation | Button[012] | Point, Car, Doggo, Racecar, Ant | SafetyPointGoal1-v0 |
| Goal[012] | |||
| Push[012] | |||
| Circle[012] | |||
| Safe Velocity | Velocity | HalfCheetah, Hopper, Swimmer, Walker2d, Ant, Humanoid | SafetyAntVelocity-v1 |
| Safe Vision | BuildingButton[012] | Point, Car, Doggo, Racecar, Ant | SafetyFormulaOne1-v0 |
| BuildingGoal[012] | |||
| BuildingPush[012] | |||
| FadingEasy[012] | |||
| FadingHard[012] | |||
| Race[012] | |||
| FormulaOne[012] | |||
| Safe Multi-Agent | MultiGoal[012] | Multi-Point, Multi-Ant | SafetyAntMultiGoal1-v0 |
| Multi-Agent Velocity | 6x1HalfCheetah, 2x3HalfCheetah, 3x1Hopper, 2x1Swimmer, 2x3Walker2d, 2x4Ant, 4x2Ant, 9|8Humanoid | Safety2x4AntVelocity-v0 | |
| FreightFrankaCloseDrawer(Multi-Agent) | FreightFranka | FreightFrankaCloseDrawer(Multi-Agent) | |
| FreightFrankaPickAndPlace(Multi-Agent) | |||
| ShadowHandCatchOver2UnderarmSafeFinger(Multi-Agent) | ShadowHands | ShadowHandCatchOver2UnderarmSafeJoint(Multi-Agent) | |
| ShadowHandCatchOver2UnderarmSafeJoint(Multi-Agent) | |||
| ShadowHandOverSafeFinger(Multi-Agent) | |||
| ShadowHandOverSafeJoint(Multi-Agent) | |||
| Safe Isaac Gym | FreightFrankaCloseDrawer | FreightFranka | FreightFrankaCloseDrawer |
| FreightFrankaPickAndPlace | |||
| ShadowHandCatchOver2UnderarmSafeFinger | ShadowHands | ShadowHandCatchOver2UnderarmSafeJoint | |
| ShadowHandCatchOver2UnderarmSafeJoint | |||
| ShadowHandOverSafeFinger | |||
| ShadowHandOverSafeJoint |
Here are some screenshots of the Safe Navigation tasks.

Point |

Car |

Racecar |

Doggo |

Ant |

Goal0 |

Goal1 |

Goal2 |

Button0 |
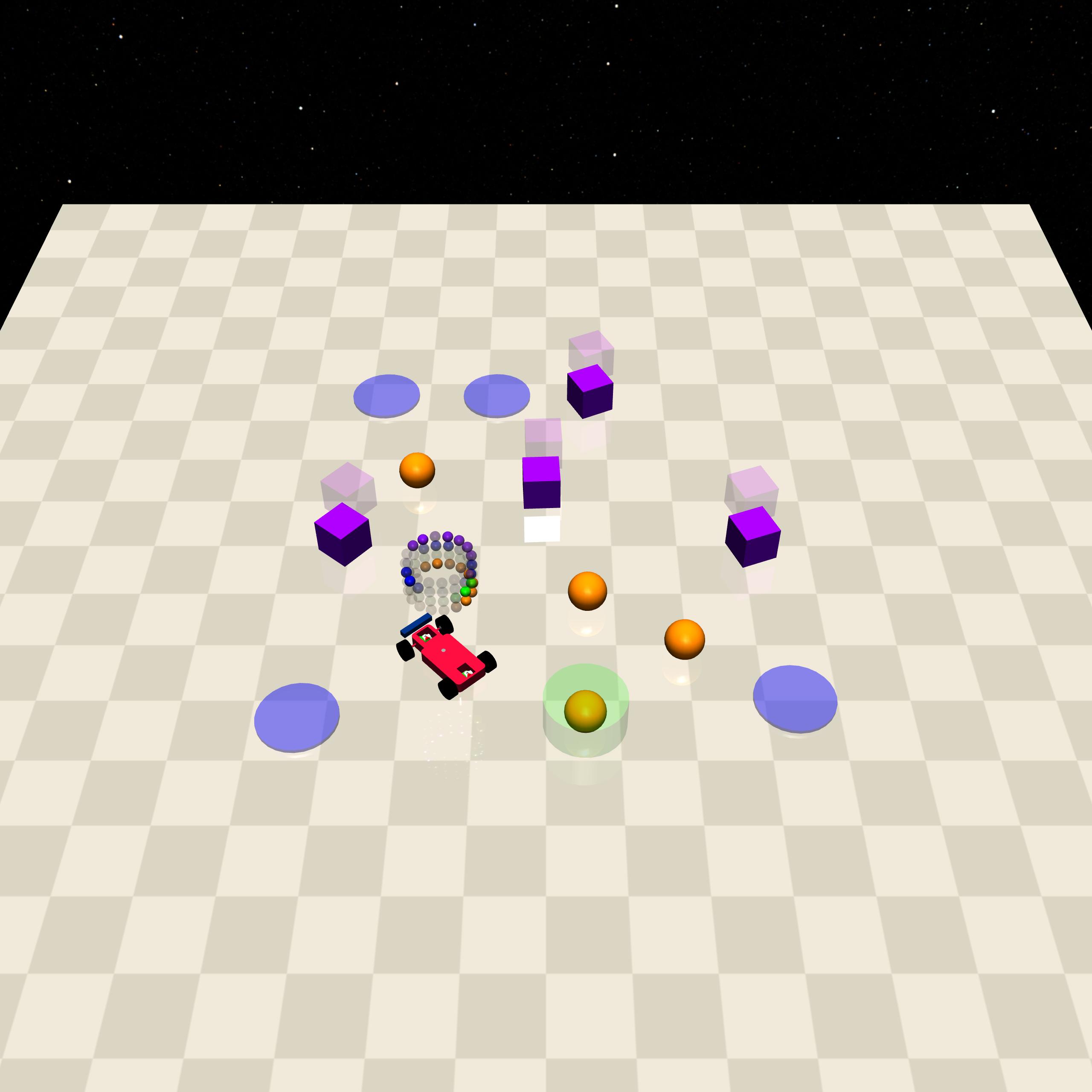
Button1 |

Button2 |

Push0 |

Push1 |

Push2 |

Circle0 |

Circle1 |

Circle2 |
Vision-based SafeRL lacks realistic scenarios.
Although the original Safety-Gym could minimally support visual input, the scenarios were too similar.
To facilitate the validation of visual-based SafeRL algorithms, we have developed a set of realistic vision-based SafeRL tasks, which are currently being validated on the baseline.
For the appetizer, the images are as follows:

Race0 |

Race1 |

Race2 |

FormulaOne0 |

FormulaOne1 |

FormulaOne2 |
Notes: We support explicitly expressing the cost based on Gymnasium APIs.
The step method returns 6 items (next_obervation, reward, cost, terminated, truncated, info) with an extra cost field.
import safety_gymnasium
env_id = 'SafetyPointGoal1-v0'
env = safety_gymnasium.make(env_id)
obs, info = env.reset()
while True:
act = env.action_space.sample()
obs, reward, cost, terminated, truncated, info = env.step(act)
if terminated or truncated:
break
env.render()We also provide two convenience wrappers for converting the Safety-Gymnasium environment to the standard Gymnasium API and vice versa.
# Safety-Gymnasium API: step returns (next_obervation, reward, cost, terminated, truncated, info)
# Gymnasium API: step returns (next_obervation, reward, terminated, truncated, info) and cost is in the `info` dict associated with a str key `'cost'`
safety_gymnasium_env = safety_gymnasium.make(env_id)
gymnasium_env = safety_gymnasium.wrappers.SafetyGymnasium2Gymnasium(safety_gymnasium_env)
safety_gymnasium_env = safety_gymnasium.wrappers.Gymnasium2SafetyGymnasium(gymnasium_env)Users can apply Gymnasium wrappers easily with:
import gymnasium
import safety_gymnasium
def make_safe_env(env_id):
safe_env = safety_gymnasium.make(env_id)
env = safety_gymnasium.wrappers.SafetyGymnasium2Gymnasium(safe_env)
env = gymnasium.wrappers.SomeWrapper1(env)
env = gymnasium.wrappers.SomeWrapper2(env, argname1=arg1, argname2=arg2)
...
env = gymnasium.wrappers.SomeWrapperN(env)
safe_env = safety_gymnasium.wrappers.Gymnasium2SafetyGymnasium(env)
return safe_envor
import functools
import gymnasium
import safety_gymnasium
def make_safe_env(env_id):
return safety_gymnasium.wrappers.with_gymnasium_wrappers(
safety_gymnasium.make(env_id),
gymnasium.wrappers.SomeWrapper1,
functools.partial(gymnasium.wrappers.SomeWrapper2, argname1=arg1, argname2=arg2),
...,
gymnasium.wrappers.SomeWrapperN,
)In addition, for all Safety-Gymnasium environments, we also provide corresponding Gymnasium environments with a suffix Gymnasium in the environment id. For example:
import gymnasium
import safety_gymnasium
safety_gymnasium.make('SafetyPointGoal1-v0') # step returns (next_obervation, reward, cost, terminated, truncated, info)
gymnasium.make('SafetyPointGoal1Gymnasium-v0') # step returns (next_obervation, reward, terminated, truncated, info)pip install safety-gymnasiumconda create -n <envname> python=3.8
conda activate <envname>
git clone https://github.com/PKU-Alignment/safety-gymnasium.git
cd safety-gymnasium
pip install -e .If you failed to render on your server, you can try:
echo "export MUJOCO_GL=osmesa" >> ~/.bashrc
source ~/.bashrc
apt-get install libosmesa6-dev
apt-get install python3-openglFor simple agents, we offer the capability to control the robot's movement via the keyboard, facilitating debugging. Simply append a Debug suffix to the task name, such as SafetyCarGoal2Debug-v0, and utilize the keys I, K, J, and L to guide the robot's movement.
For more intricate agents, you can also craft custom control logic based on specific peripherals. To achieve this, implement the debug method from the BaseAgent for the designated agent.
We construct a highly expandable framework of code so that you can easily comprehend it and design your environments to facilitate your research with no more than 100 lines of code on average.
For details, please refer to our documentation. Here is a minimal example:
# import the objects you want to use
# or you can define specific objects by yourself, just make sure obeying our specification
from safety_gymnasium.assets.geoms import Apples
from safety_gymnasium.bases import BaseTask
# inherit the basetask
class MytaskLevel0(BaseTask):
def __init__(self, config):
super().__init__(config=config)
# define some properties
self.num_steps = 500
self.agent.placements = [(-0.8, -0.8, 0.8, 0.8)]
self.agent.keepout = 0
self.lidar_conf.max_dist = 6
# add objects into environments
self.add_geoms(Apples(num=2, size=0.3))
def calculate_reward(self):
# implement your reward function
# Note: cost calculation is based on objects, so it's automatic
reward = 1
return reward
def specific_reset(self):
# depending on your task
def specific_step(self):
# depending on your task
def update_world(self):
# depending on your task
@property
def goal_achieved(self):
# depending on your taskSafety-Gymnasium is released under Apache License 2.0.