Some questions regarding the DiscoBox paper #18
Comments
|
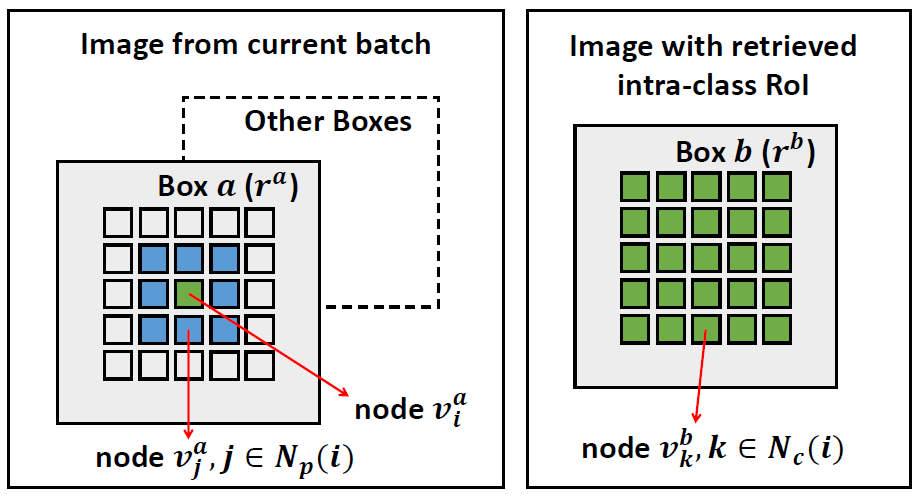
|
@Chrisding Could you please also let me know what dense correspondence means here? |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
|
|
@Chrisding Could you please also let me know what dense correspondence means here? |
Thanks for the nice work and it runs smoothly with Docker. I have some questions with paper and hope you can give me some help.
The text was updated successfully, but these errors were encountered: