


llmc 是一个即插即用的工具,旨在通过最先进的压缩算法进行大型语言模型的压缩,以提高效率并减小模型大小,同时不牺牲性能。
英文文档在这里.
中文文档在这里.
社区:
-
**2024年7月16号:**🔥我们现在已经支持了大模型稀疏算法Wanda/Naive(Magnitude)和层间混合bit量化!
-
**2024年7月14号:**🔥我们现在已经支持了旋转类量化算法QuaRot!
-
2024年7月4日: 📱 我们提供了公开的讨论渠道. 如果您有任何问题,可以加入我们的社区:
-
2024年5月13日: 🍺🍺🍺 我们发布了量化基准论文:
LLM-QBench:大型语言模型训练后量化的最佳实践基准.
Ruihao Gong*, Yang Yong*, Shiqiao Gu*, Yushi Huang*, Yunchen Zhang, Xianglong Liu📧, Dacheng Tao
(* 表示共同第一作者, 📧 表示通讯作者.)
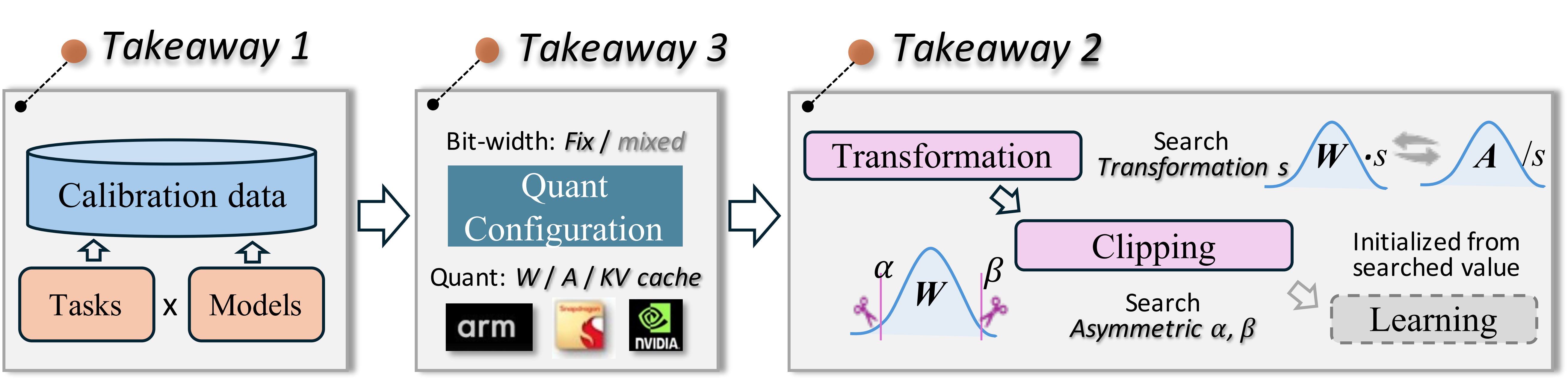
我们模块化并公正地基准测试了量化技术,考虑到校准成本、推理效率和量化精度。在多种模型和数据集上进行的近 600 项实验提供了三个洞见: 关于校准数据、算法流程和量化配置选择。基于这些洞见,设计了一个最佳的大型语言模型 PTQ 流程,实现了在各种场景下最佳的精确度和效率性能平衡。
-
2024年3月7日: 🚀 我们发布了强大且高效的大型语言模型压缩工具的量化部分。值得注意的是,我们的基准论文即将发布😊。

- 量化大型语言模型,如 Llama2-70B、OPT-175B,并在仅一个 A100/H100/H800 GPU上评估其 PPL💥。
- 为用户提供选择的最新的与原论文代码仓库精度对齐的压缩算法,并且用户可以在一个大型语言模型上依次使用多个算法💥。
- 由我们工具通过特定压缩算法导出的转换模型(
save_trans模式在quant部分的配置)可以通过多个后端进行简单量化,得到经过特定压缩算法优化的模型,相应的后端可以进行推断💥。 - 我们的压缩模型(
save_lightllm模式在quant部分的[配置](#
配置))具有较低的内存占用,可以直接通过Lightllm进行推断💥。
-
克隆此仓库并安装包:
# 安装包 cd llmc pip install -r requirements.txt
-
准备模型和数据。
# 在从huggingface下载LLM后,按以下方式准备校准和评估数据: cd tools python download_calib_dataset.py --save_path [校准数据路径] python download_eval_dataset.py --save_path [评估数据路径]
-
选择一个算法来量化你的模型:
# 这是一个关于 Awq 的例子: cd scripts # 修改 bash 文件中的 llmc 路径,``llmc_path``。你也可以选择``llmc/configs/quantization/Awq/``中的一个配置来量化你的模型,或者通过更改``--config``参数在 run_awq_llama.sh 中使用我们提供的配置。 bash run_awq_llama.sh
为了帮助用户设计他们的配置,我们现在解释我们在llmc/configs/下提供的所有配置中的一些通用配置:
-
model:model: # 用``llmc/models/*.py``中的类名替换。 type: Llama # 用你的模型路径替换。 path: model path torch_dtype: auto
-
calib:# 注意:一些算法不需要``calib``,如 naive... 所以,你可以移除这部分。 calib: # 用之前下载的校准数据名称替换,例如,pileval、c4、wikitext2 或 ptb。 name: pileval download: False # 用之前下载的某个校准数据的路径替换,例如,pileval、c4、wikitext2 或 ptb。 path: calib data path n_samples: 128 bs: -1 seq_len: 512 # 用``llmc/data/dataset/specified_preproc.py``中的函数名称替换。 preproc: general seed: *seed
-
eval:# 如果你想评估你的预训练/转换/假量化模型的 PPL。 eval: # 你可以评估预训练、转换、假量化模型,并设置你想要评估的位置。 eval_pos: [pretrain, transformed, fake_quant] # 用之前下载的评估数据的名称替换,例如,c4、wikitext2、ptb 或 [c4, wikitext2]。 name: wikitext2 download: False path: eval data path # 对于 70B 模型评估,bs 可以设置为 20,并且可以将 inference_per_block 设置为 True。 # 对于 7B / 13B 模型评估,bs 可以设置为 1,并且可以将 inference_per_block 设置为 False。 bs: 1 inference_per_block: False seq_len: 2048
-
save:save: # 如果``save_trans``为 True,这意味着你想要导出转换模型,例如,参数修改的模型,其性能和结构与原始模型相同,用户可以对转换模型进行简单量化,以获得与特定算法量化模型相同的性能。 save_trans: False # 如果``save_lightllm``为 True,这意味着你想要导出真实的量化模型,例如,低位权重和权重及激活量化参数。 save_lightllm: False # 如果``save_fake``为 True,意味着你想要导出假量化模型,例如,去量化的权重和激活量化参数。 save_fake: False save_path: ./save
-
quant:quant: # 用``llmc/compression/quantization/*.py``中的类名替换。 method: OmniQuant # 仅权重量化没有``act``部分。 weight: bit: 8 symmetric: True # 量化粒度:per_channel, per_tensor, per_head(不推荐)。 granularity: per_channel group_size: -1 # 校准算法:learnble, mse, 以及 minmax(默认)。 calib_algo: learnable # 使用直通估计(Stright-Through Estimation),这对于可学习的校准算法是必需的。 ste: True act: bit: 8 symmetric: True # 量化粒度:per_token, per_tensor granularity: per_token ste: True # 静态量化(校准期间的量化)或动态量化(推理期间的量化)。 static: True # 这部分是为特定算法设计的,用户可以参考我们提供的算法来设计他们自己的算法。 special: let: True lwc_lr: 0.01 let_lr: 0.005 use_shift: False alpha: 0.5 deactive_amp: True epochs: 20 wd: 0 # 如果 quant_out 为 True,使用前一个量化块的输出作为后续块的校准数据。 quant_out: True
✅ BLOOM
✅ LLaMA
✅ LLaMA V2
✅ OPT
✅ Falcon
✅ Mistral
✅ LLaMA V3
你可以参考 llmc/models/*.py 下的文件添加你自己的模型类型。
✅ Naive
✅ AWQ
✅ GPTQ
✅ OS+
✅ AdaDim
✅ QUIK
✅ SpQR
✅ DGQ
✅ OWQ
✅ HQQ
✅ QuaRot
✅ Naive(Magnitude)
✅ Wanda
-
QuIP
-
QuIP#
-
AQLM
注意: 一些特定算法如 QUIK、SpQR,需要特殊硬件或内核支持,不能通过多个后端进行简单量化,然后利用这些后端进行推断。然而,用户仍然可以使用我们的工具评估这些算法在其研究中的性能。
-
SparseGPT
-
LLM-Pruner
这部分即将推出🚀。
-
压缩模型的端到端示例,然后利用多个后端,例如 Lightllm, TensorRT-LLM,进行推断。
-
不同算法的
quant部分中的special文档。 -
用户自己添加新算法的文档。
更详细的文档即将推出🚀。
我们的代码参考了以下仓库:
- https://github.com/mit-han-lab/llm-awq
- https://github.com/mit-han-lab/smoothquant
- https://github.com/OpenGVLab/OmniQuant
- https://github.com/IST-DASLab/gptq
- https://github.com/ModelTC/Outlier_Suppression_Plus
- https://github.com/IST-DASLab/QUIK
- https://github.com/Vahe1994/SpQR
- https://github.com/ilur98/DGQ
- https://github.com/xvyaward/owq
- https://github.com/TimDettmers/bitsandbytes
- https://github.com/mobiusml/hqq
- https://github.com/locuslab/wanda
如果您认为我们的 LLM-QBench 论文/llmc 工具对您的研究有用或相关,请务必引用我们的论文:
@misc{llmc,
author = {llmc contributors},
title = {llmc: Towards Accurate and Efficient LLM Compression},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/ModelTC/llmc}},
}
@misc{gong2024llmqbench,
title={LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models},
author={Ruihao Gong and Yang Yong and Shiqiao Gu and Yushi Huang and Yunchen Zhang and Xianglong Liu and Dacheng Tao},
year={2024},
eprint={2405.06001},
archivePrefix={arXiv},
primaryClass={cs.LG}
}