This tool will be/is included in LearnLib v0.17
This tool introduces the concept of Systems of Procedural Automata (SPAs), an extension to DFAs to systems of DFAs that can mutually call each other. SPAs allow for an intuitive representation of procedural software systems, i.e. systems modeled after context-free languages by means of the copy-rule semantic, where terminal symbols represent internal actions and non-terminal symbols represent method invocations.
The tool provides an active learning algorithm for systems that are instrumented such that the start and the end of the procedures are observable. This instrumentation is natural to imperative and procedural software systems and is oftentimes already part of the system itself (see the pedigree XML example of the tool).
Currently, the only model both AutomataLib and LearnLib support, that is able to formalize the hierarchical call structure of software systems, is that of visibly pushdown automata (VPAs). Our proposed formalism for SPAs extends both libraries by being able to model and learn arbitrary context-free systems (the system of palindromes is a prominent example of a context-free system that is not a visibly pushdown system).
Our proposed instrumentation is very powerful. Indeed, it also enables VPA learning to cover all context-free languages. In order to illustrate the difference between SPA learning and VPA learning after instrumentation, please consider the following grammar for palindromes (which we also briefly discuss in the paper):
F -> a | a F a | b | b F b | G | ε
G -> c | c G c | F


(Click on the images for a full-sized view)
Both models shown above (for SPA on the left and for VPA on the right) were inferred via black-box testing as described in the paper. Although both models capture in essence the same information, there is a big difference in their comprehensibility: Whereas the former very intuitively reflects the underlying grammar, the latter is quite hard to understand - and, in fact, also more expensive to infer (see the quantitative results below). As the required instrumentation is very natural, we are convinced that SPA learning has quite some potential for practical application.
-
The tool requires a working JDK 8 & Maven installation. It is suggested, to use one of the major Java IDEs, which should already have out-of-the-box support for Maven projects.
-
For visualizing the automata, GraphViz is required.
The tool consists of two modules -- learner and examples.
-
The learner module contains the core components of the learning algorithm.
- The
SPALearnerclass resembles the main class of the learning algorithm and integrates into theLearningAlgorithmframework of the LearnLib. - The
InstrumentedStackAcceptorclass resembles a stack-based implementation that accepts the language of an instrumented SPA. - The
configpackage contains several predefined adapters that can be used to configure, which learning algorithms theSPALearnershould use for learning the individual sub-procedures of the system under learning. - The
viewpackage contains two different views for displaying the structure of an SPA. TheInternalViewrenders the sub-procedures as-is in the form of DFAs. TheReachabilityViewonly renders states and transitions on paths to accepting states, similar to the figures of the paper.
- The
-
The examples module holds several classes that display the usage and application of the tool. It contains several benchmarks for which we want to briefly sketch the quantitative and qualitative results in the following.
Note, for generating counterexamples in our black-box testing scenario, we (in order) generated 10000 random, well-matched, rooted words of maximum length 100, for CFG based approaches (Palindromes, Exponential) generated 10000 words of the (instrumented) context-free language and finally sampled from a manually constructed set of characteristic words to ensure termination against the correct model. The results for the quantitative evaluations are averaged over 15 learning runs.
A qualitative comparison of the palindrome examples has already been presented earlier. The following shows the quantitative comparison of the different learning scenarios.
#CEs #Queries #Symbols Hyp. size SPA [L* (classic)] 7.4 435.5 3794.7 12.0 SPA [L* (Riv. & Schap.)] 8.7 315.2 2356.1 12.0 SPA [L* (Kearns & Vaz.)] 9.2 214.1 1457.8 12.0 SPA [DiscriminationTree] 9.1 218.1 1452.5 12.0 SPA [TTT] 9.3 186.6 1265.6 12.0 VPA [DiscriminationTree] 7.9 1616.5 15176.7 11.0 VPA [TTT] 8.1 1651.9 15343.1 11.0 As can be seen, our SPA approach outperforms the VPA approach by a significant margin, even for this small of an example.
XML documents are a highly practical example, where our orchestration naturally integrates into the given structure: When interpreting XML tags as procedures, the start and end of a procedure is given by its opening and closing tag.
For our example, consider the following DTD (document type definition):
<!ELEMENT person ((mother | father)? | (father, mother) | (mother, father))> <!ELEMENT mother (person)> <!ELEMENT father (person)> <!ATTLIST person name CDATA #REQUIRED> <!ATTLIST person died CDATA #IMPLIED>Documents adhering to this DTD allow to store information about the pedigree of a person. Each person has to be identified via its
nameattribute and may optionally store information about his/her year of death (if the person died already). Furthermore, it is possible to store information about his/her ancestors via nested<mother>or<father>tags (optional and irrespective of order), which themselves hold persons again.By translating abstract queries (e.g.
PERSON name R) to concrete XML documents (i.e<person name="..."></person>), we can learn the structure of DTDs solely by asking a black-box DTD validator, if a provided XML document conforms to an (unknown, to be inferred) DTD or not. In this example, we have modeled {PERSON,MOTHER,FATHER} as call symbols representing the tags and {name,died} as internal symbols representing attributes. The following shows the inferred models: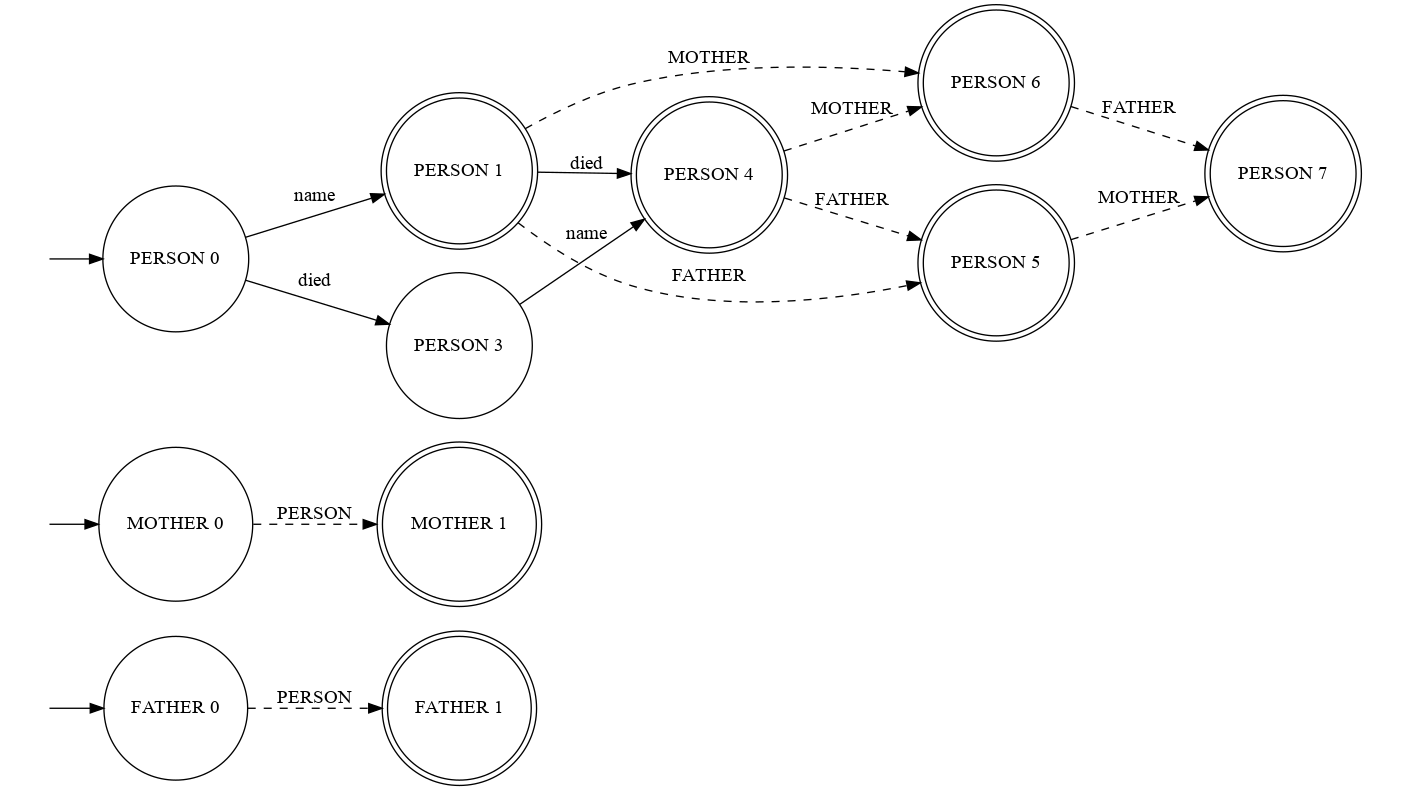
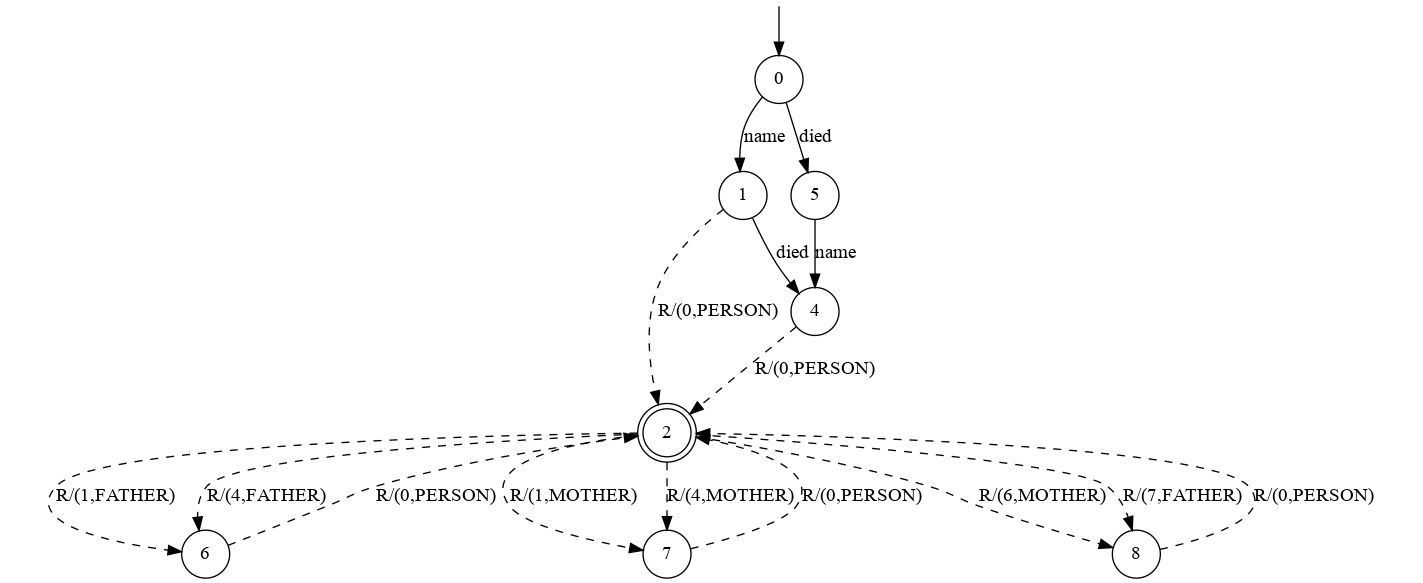
(Click on the images for a full-sized view)
As one can see, from the SPA model it is directly possible to infer the nesting structure of the different procedures (tags). Furthermore, given that attributes were modeled as internal symbols, one can deduce that the
nameattribute is mandatory, whereas thediedattribute is completely optional. One can reconstruct the structure of the (previously unknown) DTD, given the model of the SPA. In contrast to that is the VPA model, which with its explicit stack management, makes it hard to understand the key structure of the document.Regarding performance, the following table again shows that our SPA approach additionally allows to reduce the query complexity. In this case an improvement around a factor of 3-4 was achieved.
#CEs #Queries #Symbols Hyp. size SPA [L* (classic)] 8.1 492.2 6521.3 14.0 SPA [L* (Riv. & Schap.)] 8.5 344.7 4102.1 14.0 SPA [L* (Kearns & Vaz.)] 9.5 220.9 2710.8 14.0 SPA [DiscriminationTree] 9.9 234.8 2829.1 14.0 SPA [TTT] 9.5 201.4 2636.5 14.0 VPA [DiscriminationTree] 6.6 901.9 9858.1 9.0 VPA [TTT] 6.8 819.8 8812.8 9.0 Even in cases, where the structure of software systems is not necessarily context-free but exhibits a highly repetitive structure, the correct abstraction level can be beneficial for its understanding and learning performance.
Consider, for example, the following procedural system
A -> B B B B B -> C C C C C -> D D D D D -> a b cThis system exhibits a regular structure and thus can also be learned in its non-instrumented form with arbitrary regular learning algorithms. The following shows the inferred models and performance measurements for the SPA, VPA and regular (non-instrumented) configuration.

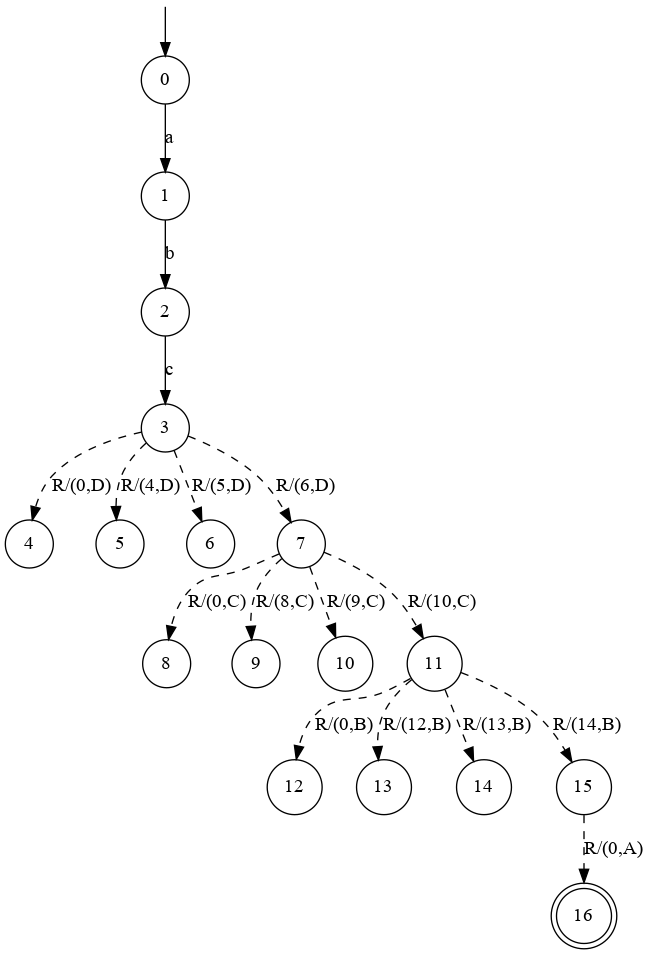

(Click on the images for a full-sized view. There are 3 images)
#CEs #Queries #Symbols Hyp. size SPA [L* (classic)] 5.0 1320.0 565376.0 23.0 SPA [L* (Riv. & Schap.)] 5.0 868.0 355863.0 23.0 SPA [L* (Kearns & Vaz.)] 5.0 856.0 347419.0 23.0 SPA [DiscriminationTree] 5.0 855.0 348077.0 23.0 SPA [TTT] 5.0 906.0 387557.0 23.0 VPA [DiscriminationTree] 2.0 22936.0 10124646.0 18.0 VPA [TTT] 2.0 22971.0 10137135.0 18.0 REG [L* (classic)] 2.0 223687.0 43264617.0 194.0 REG [Rivest/Schapire] 2.0 114007.0 21798161.0 194.0 REG [Kearns/Vazirani] 2.0 1292135.0 132508009.0 194.0 REG [DiscriminationTree] 2.0 95673.0 19383730.0 194.0 REG [TTT] 2.0 95661.0 19470481.0 194.0 Again, our SPA approach directly allows to infer the underlying structure of the system, while performing best among its competitors -- this time even an order of magnitude better. As the regular non-instrumented setup shows, even for this simple example a regular abstraction is in no way feasible for learning inherently procedural systems.





For building membership oracles and equivalence oracles based on context-free grammars (i.e. answering the membership question and iterating over words of the CFL in search for a counterexample) we use the CFG toolkit of Zhiwu Xu. The toolkit was originally downloaded from the toolkit's homepage.