Deep Reinforcement Learning
- Install VC++ via Microsoft Visual Studio on the Windows.
$ conda install swig
$ conda install pytorch==1.0.1 torchvision cudatoolkit=10.0 -c pytorch
$ pip install opencv-python
$ pip install --no-index -f https://github.com/Kojoley/atari-py/releases atari_py
$ pip install gym gym[box2d] gym[atari]
$ pip install gym-super-mario-bros cloudpickle- Game Playing:
LunarLander - Game Environment:
LunarLander-v2 - Implement an agent to play Atari games using Deep Reinforcement Learning.
- In this homework, you are required to implement Policy Gradient.
- Improvements to Policy Gradient:
- Variance Reduction
- Advanced Advantage Estimation
- Off-policy learning by Importance Sampling
- Natural Policy Gradient
- Trust Region Policy Optimization
- Proximal Policy Optimization
- Training Hint
- Reward normalization (More stable)
- Action space reduction
- Getting averaging reward in 30 episodes over 0 in LunarLander
- Improvements to Policy Gradient are allowed, not including Actor-Critic series.
-
Training Policy Gradient
$ python main.py --train_pg -
Training Policy Gradient with PPO
$ python main.py --train_pg --ppo
-
Testing Policy Gradient
$ python main.py --test_pg --video_dir ./results/pg -
Testing Policy Gradient with PPO
$ python main.py --test_pg --ppo --video_dir ./results/pg-ppo
-
Policy Gradient
CLICK ME




-
Policy Gradient with PPO
CLICK ME











- Policy Gradient:
Run 30 episodes, Mean: 159.41205516866356 - Policy Gradient with PPO:
Run 30 episodes, Mean: 218.51080037730148
- Learning Curve of Original Policy Gradient

- Learning Curve of Policy Gradient with Proximal Policy Optimization (PPO)

- Comparison of Original PG and PG with PPO

- Game Playing:
Assault - Game Environment:
AssaultNoFrameskip-v0 - Implement an agent to play Atari games using Deep Reinforcement Learning.
- In this homework, you are required to implement Deep Q-Learning (DQN).
- Improvements to DQN:
- Double Q-Learning
- Dueling Network
- Prioritized Replay Memory
- Multi-Step Learning
- Noisy DQN
- Distributional DQN
- Training Hint
- The action should act ε-greedily
- Random action with probability ε
- Also in testing
- Linearly decline ε from 0.9 to some small value, say 0.05
- Decline per step
- Randomness is for exploration, agent is weak at start
- Hyperparameters
- Replay Memory Size: 10000
- Perform Update Current Network Step: 4
- Perform Update Target Network Step: 1000
- Learning Rate: 1e-4
- Batch Size: 32
- The action should act ε-greedily
- Getting averaging reward in 100 episodes over 100 in Assault
- Improvements to DQN are allowed, not including Actor-Critic series.
-
Training DQN
$ python main.py --train_dqn -
Training Dual DQN
$ python main.py --train_dqn --duel_dqn -
Training Double DQN
$ python main.py --train_dqn --double_dqn -
Training Double Dual DQN
$ python main.py --train_dqn --double_dqn --duel_dqn
-
Testing DQN
$ python main.py --test_dqn --video_dir ./results/dqn -
Testing Dual DQN
$ python main.py --test_dqn --duel_dqn --video_dir ./results/duel_dqn -
Testing Double DQN
$ python main.py --test_dqn --double_dqn --video_dir ./results/double_dqn -
Testing Double Dual DQN
$ python main.py --test_dqn --double_dqn --duel_dqn --video_dir ./results/double_duel_dqn
-
DQN
CLICK ME



-
Dual DQN
CLICK ME




-
Double DQN
CLICK ME




-
Double Dual DQN
CLICK ME




















- DQN:
Run 100 episodes, Mean: 204.71 - Dual DQN:
Run 100 episodes, Mean: 193.49 - Double DQN:
Run 100 episodes, Mean: 188.83 - Double Dual DQN:
Run 100 episodes, Mean: 174.99
- Learning Curve of DQN

- Learning Curve of Dual DQN

- Learning Curve of Double DQN

- Learning Curve of Double Dual DQN

- Comparison of DQN, Dual DQN, Double DQN and Double Dual DQN

- Game Playing:
SuperMarioBros - Game Environment:
SuperMarioBros-v0 - Implement an agent to play Super Mario Bros using Actor-Critic.
- Simple Baseline: Getting averaging reward in 10 episodes over 1500 in SuperMarioBros
- Strong Baseline: Getting averaging reward in 10 episodes over 3000 in SuperMarioBros
- Training Hint
- The action should act ε-greedily
- Random action with probability ε
- Also in testing
- Linearly decline ε from 0.9 to some small value, say 0.05
- Decline per step
- Randomness is for exploration, agent is weak at start
- Hyperparameters
- Rollout Storage Size: 10
- Perform Update Network Step: 10
- Process Number: 32
- Learning Rate: 7e-4
- The action should act ε-greedily
-
Training A2C on all worlds
$ python main.py --train_mario --world 0 -
Training A2C on the world 1
$ python main.py --train_mario --world 1
-
Testing A2C trained on all worlds starting from world 1 stage 1
$ python main.py --test_mario --do_render --world 0 --video_dir ./results/a2c-all-1-1 -
Testing A2C trained on the world 1 starting from world 1 stage 1
$ python main.py --test_mario --do_render --world 1 --video_dir ./results/a2c-1-1-1 -
Testing A2C trained on all worlds for all worlds
$ python test_mario.py --test_mario --do_render --world 0 --video_dir ./results/a2c-all-all -
Testing A2C trained on the world 1 for all worlds
$ python test_mario.py --test_mario --do_render --world 1 --video_dir ./results/a2c-1-all
-
Testing A2C trained on all worlds starting from world 1 stage 1:
CLICK ME



-
Testing A2C trained on the world 1 starting from world 1 stage 1:
CLICK ME



-
Testing A2C trained on all worlds for all worlds:
CLICK ME
World\Stage 1 2 3 4 1 
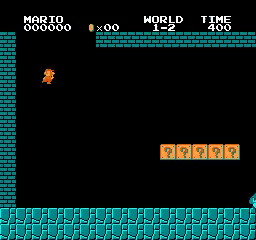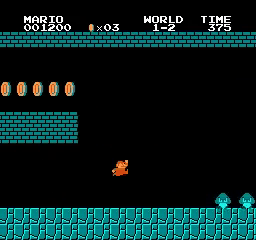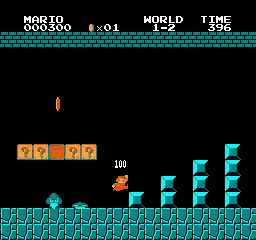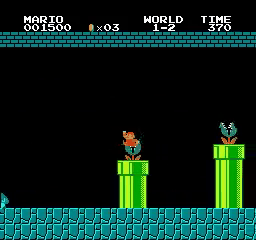
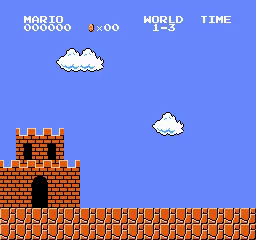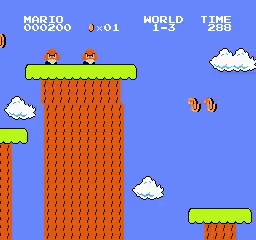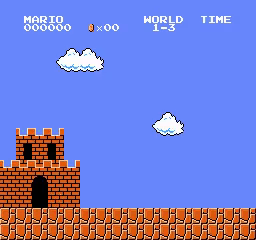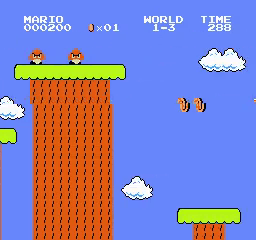

2 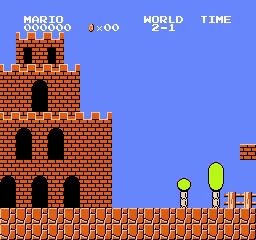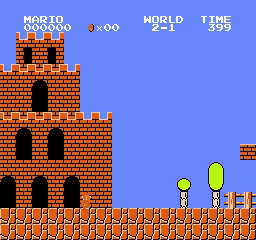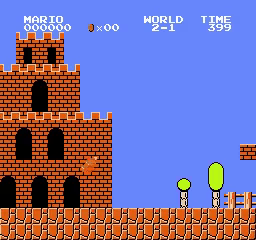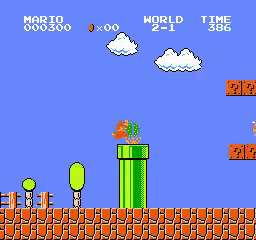
3 

4 

5 
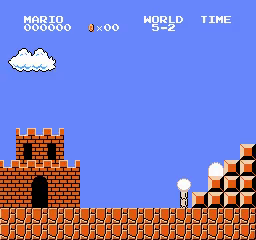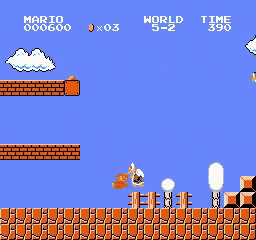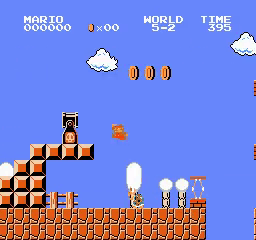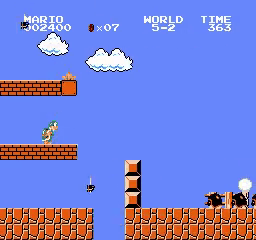
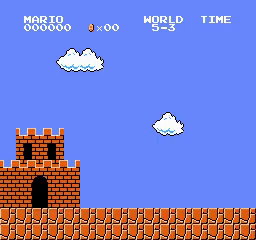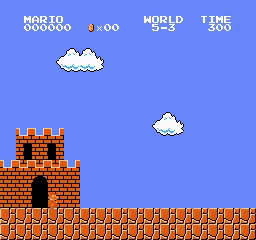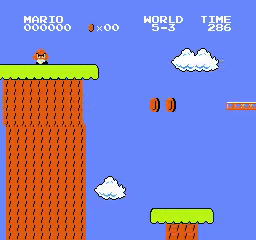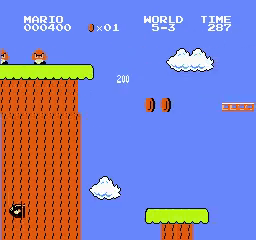
6 

7 
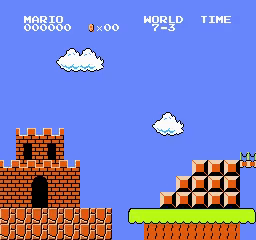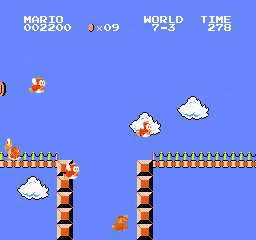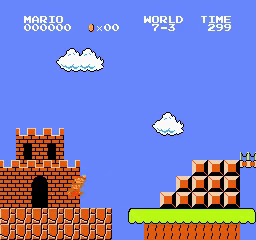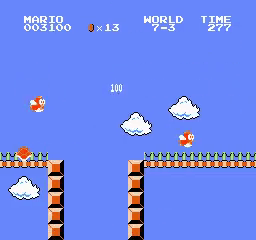
8 

-
Testing A2C trained on the world 1 for all worlds:
CLICK ME
World\Stage 1 2 3 4 1 



2 



3 



4 



5 



6 



7 



8 









































































- Testing A2C trained on all worlds starting from world 1 stage 1:
Run 10 episodes, Mean: 2798.9850000000024 - Testing A2C trained on the world 1 starting from world 1 stage 1:
Run 10 episodes, Mean: 4015.8699999999953 - Testing A2C trained on all worlds for all worlds:
Env: SuperMarioBros-1-1-v0, Run 10 episodes, Mean: 1905.400000000002 Env: SuperMarioBros-1-2-v0, Run 10 episodes, Mean: 1015.8599999999999 Env: SuperMarioBros-1-3-v0, Run 10 episodes, Mean: 551.06 Env: SuperMarioBros-1-4-v0, Run 10 episodes, Mean: 1483.6600000000005 Env: SuperMarioBros-2-1-v0, Run 10 episodes, Mean: 554.0799999999997 Env: SuperMarioBros-2-2-v0, Run 10 episodes, Mean: 1502.7600000000007 Env: SuperMarioBros-2-3-v0, Run 10 episodes, Mean: 1949.8200000000015 Env: SuperMarioBros-2-4-v0, Run 10 episodes, Mean: 979.9000000000002 Env: SuperMarioBros-3-1-v0, Run 10 episodes, Mean: 1110.5700000000002 Env: SuperMarioBros-3-2-v0, Run 10 episodes, Mean: 1585.2500000000011 Env: SuperMarioBros-3-3-v0, Run 10 episodes, Mean: 1519.740000000001 Env: SuperMarioBros-3-4-v0, Run 10 episodes, Mean: 1131.8700000000003 Env: SuperMarioBros-4-1-v0, Run 10 episodes, Mean: 1687.1000000000015 Env: SuperMarioBros-4-2-v0, Run 10 episodes, Mean: 864.7199999999997 Env: SuperMarioBros-4-3-v0, Run 10 episodes, Mean: 650.3199999999999 Env: SuperMarioBros-4-4-v0, Run 10 episodes, Mean: 455.3300000000002 Env: SuperMarioBros-5-1-v0, Run 10 episodes, Mean: 1301.7300000000002 Env: SuperMarioBros-5-2-v0, Run 10 episodes, Mean: 1092.7500000000005 Env: SuperMarioBros-5-3-v0, Run 10 episodes, Mean: 533.6999999999998 Env: SuperMarioBros-5-4-v0, Run 10 episodes, Mean: 734.4499999999999 Env: SuperMarioBros-6-1-v0, Run 10 episodes, Mean: 1940.1900000000019 Env: SuperMarioBros-6-2-v0, Run 10 episodes, Mean: 645.4399999999998 Env: SuperMarioBros-6-3-v0, Run 10 episodes, Mean: 640.0099999999998 Env: SuperMarioBros-6-4-v0, Run 10 episodes, Mean: 864.8100000000001 Env: SuperMarioBros-7-1-v0, Run 10 episodes, Mean: 1228.5000000000007 Env: SuperMarioBros-7-2-v0, Run 10 episodes, Mean: 1199.1500000000005 Env: SuperMarioBros-7-3-v0, Run 10 episodes, Mean: 1168.9500000000003 Env: SuperMarioBros-7-4-v0, Run 10 episodes, Mean: 305.9 Env: SuperMarioBros-8-1-v0, Run 10 episodes, Mean: 817.8 Env: SuperMarioBros-8-2-v0, Run 10 episodes, Mean: 507.5999999999999 Env: SuperMarioBros-8-3-v0, Run 10 episodes, Mean: 1119.13 Env: SuperMarioBros-8-4-v0, Run 10 episodes, Mean: 2574.450000000001 - Testing A2C trained on the world 1 for all worlds:
Env: SuperMarioBros-1-1-v0, Run 10 episodes, Mean: 2240.850000000001 Env: SuperMarioBros-1-2-v0, Run 10 episodes, Mean: 1582.4100000000012 Env: SuperMarioBros-1-3-v0, Run 10 episodes, Mean: 555.2499999999999 Env: SuperMarioBros-1-4-v0, Run 10 episodes, Mean: 1457.3900000000008 Env: SuperMarioBros-2-1-v0, Run 10 episodes, Mean: 453.8199999999998 Env: SuperMarioBros-2-2-v0, Run 10 episodes, Mean: 1278.5000000000007 Env: SuperMarioBros-2-3-v0, Run 10 episodes, Mean: 819.9699999999997 Env: SuperMarioBros-2-4-v0, Run 10 episodes, Mean: 253.88000000000002 Env: SuperMarioBros-3-1-v0, Run 10 episodes, Mean: 420.3499999999999 Env: SuperMarioBros-3-2-v0, Run 10 episodes, Mean: 538.7299999999998 Env: SuperMarioBros-3-3-v0, Run 10 episodes, Mean: 408.60999999999996 Env: SuperMarioBros-3-4-v0, Run 10 episodes, Mean: 288.59999999999997 Env: SuperMarioBros-4-1-v0, Run 10 episodes, Mean: 577.39 Env: SuperMarioBros-4-2-v0, Run 10 episodes, Mean: 230.07999999999998 Env: SuperMarioBros-4-3-v0, Run 10 episodes, Mean: 351.27 Env: SuperMarioBros-4-4-v0, Run 10 episodes, Mean: 216.67 Env: SuperMarioBros-5-1-v0, Run 10 episodes, Mean: 413.0299999999999 Env: SuperMarioBros-5-2-v0, Run 10 episodes, Mean: 567.9199999999997 Env: SuperMarioBros-5-3-v0, Run 10 episodes, Mean: 434.42999999999995 Env: SuperMarioBros-5-4-v0, Run 10 episodes, Mean: 243.29000000000002 Env: SuperMarioBros-6-1-v0, Run 10 episodes, Mean: 455.98 Env: SuperMarioBros-6-2-v0, Run 10 episodes, Mean: 381.4 Env: SuperMarioBros-6-3-v0, Run 10 episodes, Mean: 293.27000000000004 Env: SuperMarioBros-6-4-v0, Run 10 episodes, Mean: 464.34 Env: SuperMarioBros-7-1-v0, Run 10 episodes, Mean: 347.09000000000003 Env: SuperMarioBros-7-2-v0, Run 10 episodes, Mean: 706.6 Env: SuperMarioBros-7-3-v0, Run 10 episodes, Mean: 476.28999999999996 Env: SuperMarioBros-7-4-v0, Run 10 episodes, Mean: 285.99 Env: SuperMarioBros-8-1-v0, Run 10 episodes, Mean: 344.25 Env: SuperMarioBros-8-2-v0, Run 10 episodes, Mean: 278.83000000000004 Env: SuperMarioBros-8-3-v0, Run 10 episodes, Mean: 462.8799999999998 Env: SuperMarioBros-8-4-v0, Run 10 episodes, Mean: 168.51000000000002
- Learning Curve of A2C trained on all worlds

- Learning Curve of A2C trained on the world 1

- Comparison between the two environments

