{kind=link}
爬取淘宝的数据除了xsign的key的方式,头疼的一点就是被识别、出现滑动验证码。
本开源程序原理使用代码操作webdriver,流量走到 mitmproxy进行过滤浏览器参数,这些参数会会让淘宝的js知道你使用的是webdriver,这样出现小二滑动也能轻松的过。
- python3.5
- requirements.txt
- webdriver.exe
- mongodb
- mitmproxy
windows运行
1 、 运行开启mongodb数据库,配置数据库密码
mongod.exe --dbpath 数据的路径
2 、下载mitmproxy。
- 直接下载,百度搜索下载方法,去官方下载。
- 或pip下载:
pip install mitmproxy。在python的包中site找到mitmproxy.exe、mitmdump.exe、mitmweb.exe即说明成功
3、 安装requirements.txt
我的库比较杂,最好使用虚拟环境
pip install -r requirements.txt -i https://pypi.douban.com/simple
4、 使用webdriver在代码中使用的是火狐内核的无头浏览器。在滑动验证码的时候,与过滤浏览器参数的时候发现使用火狐的方式成功率更加的高
5、 开启mitmproxy
mitmdump -p 8888 -s proxy.py (代理脚本路径)
6、 运行软件
建议在虚拟环境下运行
python TK_crawler.py
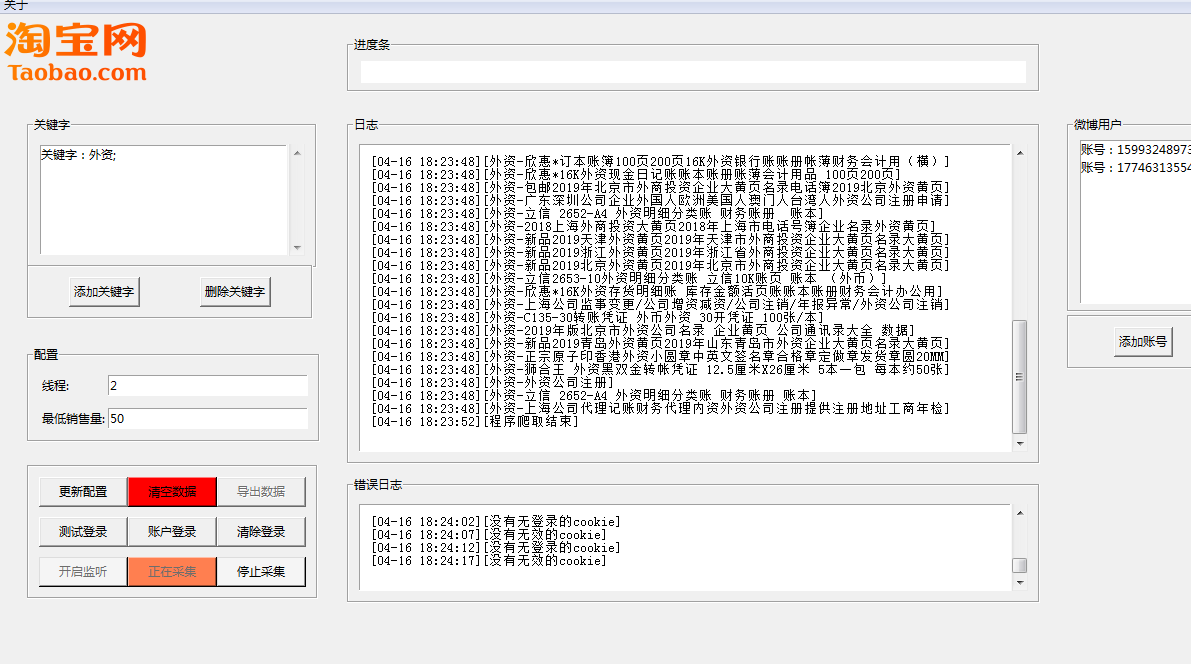
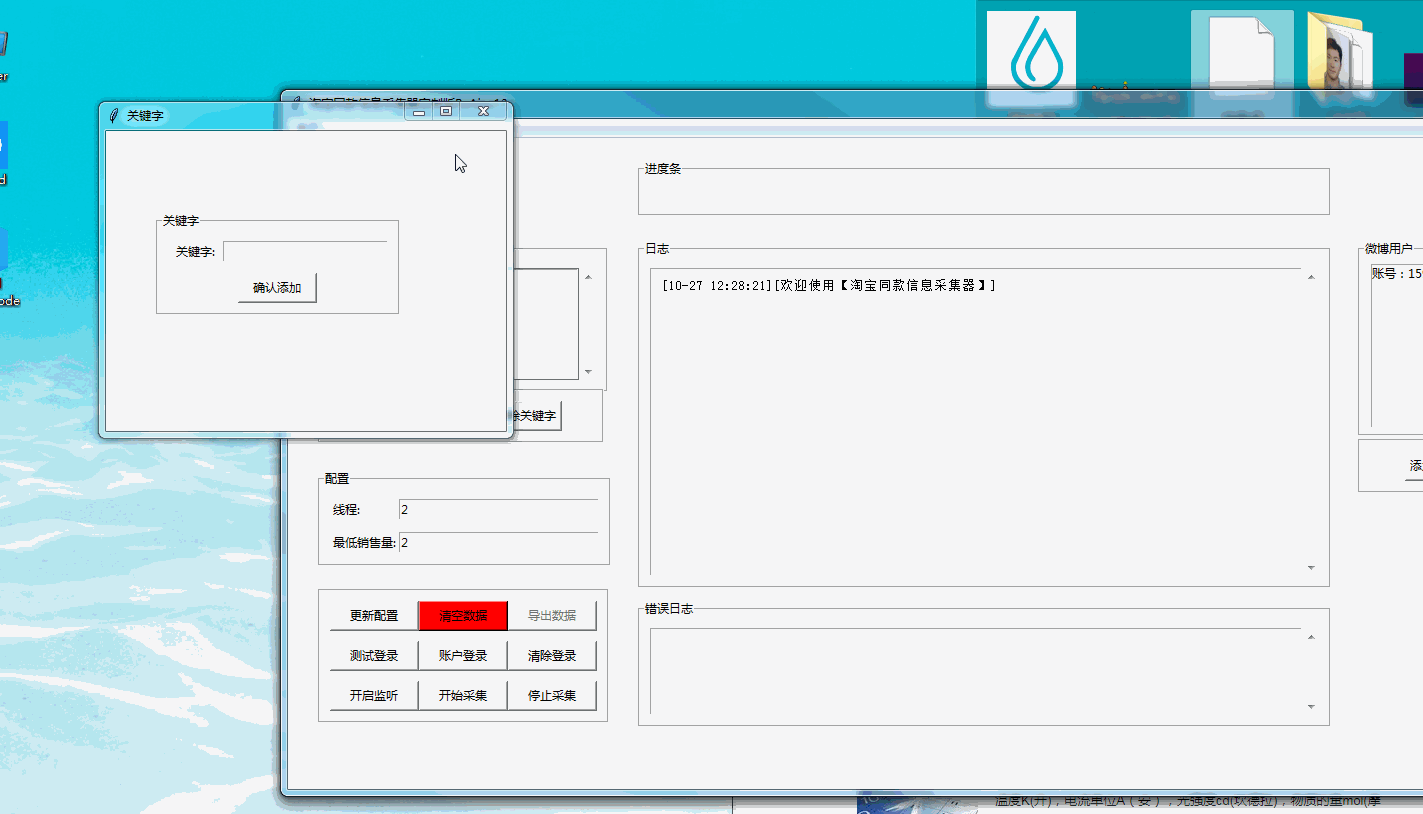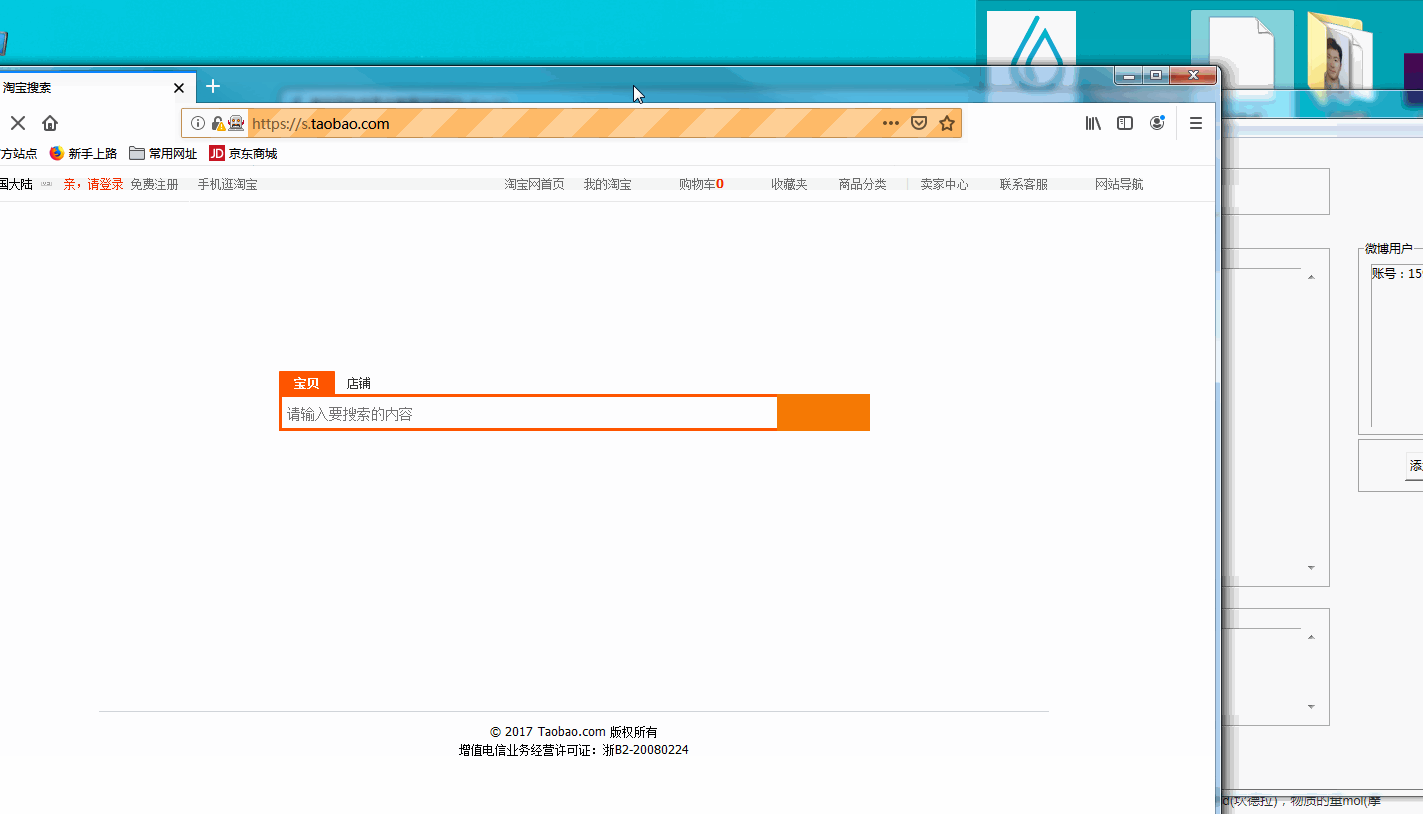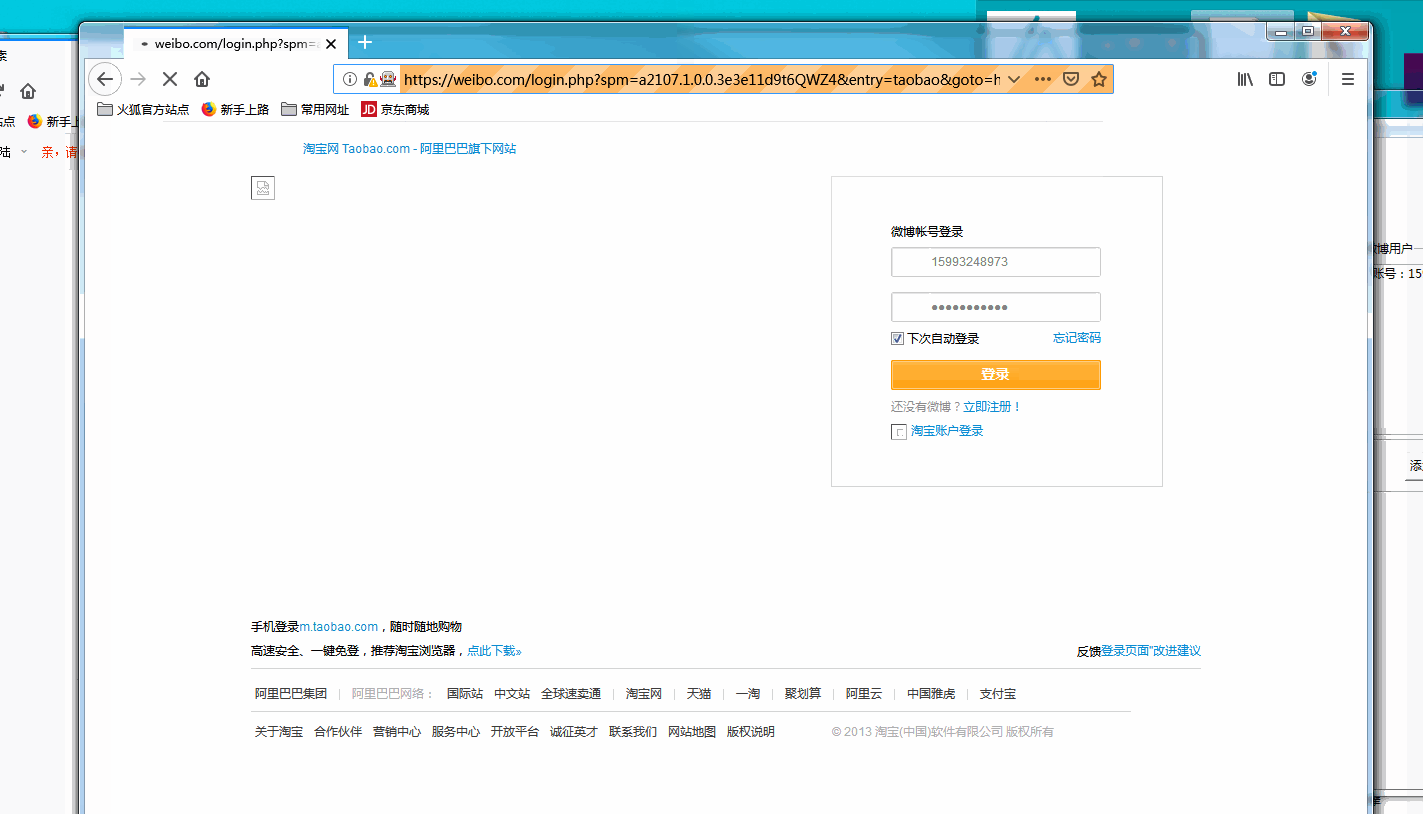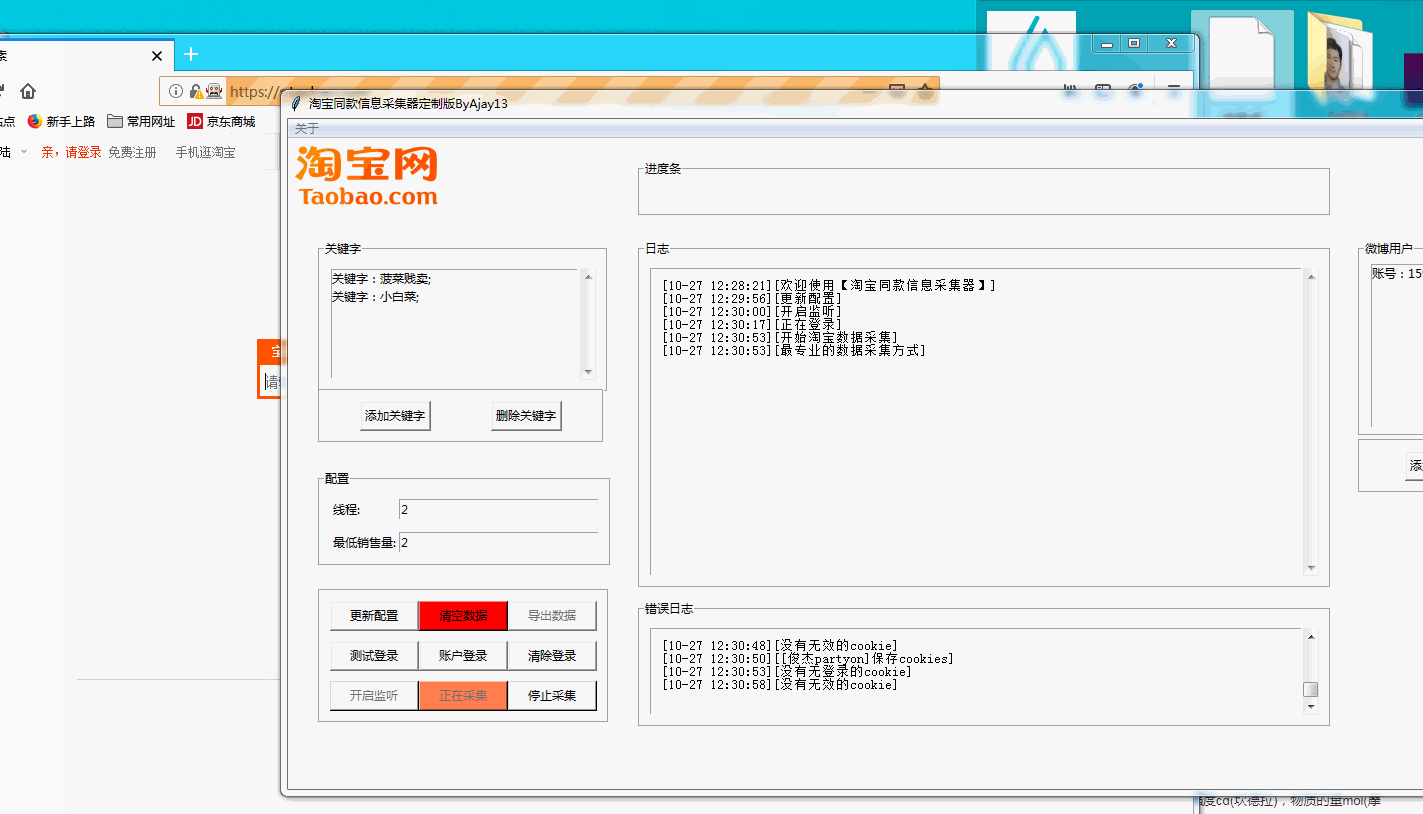
之后就能看到这个界面了,简单说明此程序是用TK写的界面,tk比较麻烦,大概半年前写的比较菜,现在再看逻辑与代码结构糟糕透了,很多公共的部分我都没封装。但是里面的功能都是可以用的。
2019年10月27日周末测试
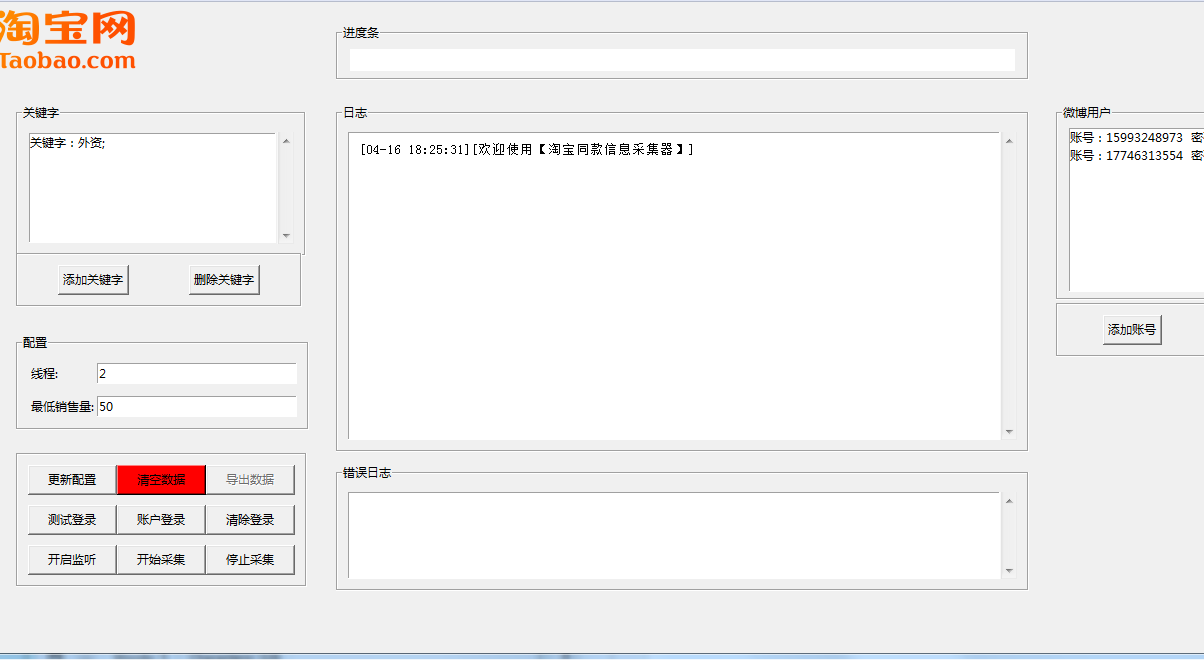
- 更新配置
- 清空数据
- 导出数据
- 测试登录
- 账户登录
- 清除登录
- 开始监听
- 开始采集
- 停止采集
更新配置
设置配置中的线程数量与最低销售数量 线程数量应该与登录账户的0.5倍与3倍之间。
清空数据
注意:清空数据将会清空所有配置数据,谨慎使用
导出数据
将导出所有采集的数据,数据文档按照关键字命名
测试登录
将打开一个无头浏览器,保证你的账户能够顺利登录,检测是否登录有异地登录验证,第一次使用,方便导入配置信息
账户登录
使用浏览器模拟账户登录,登录后保存登录信息,用于爬虫使用。如果出现验证码的情况下。系手动填写。
每次不用都登录,只要不清除登录就会一直保留上次登录的信息。如果登录间隔时间过长,登录信息失效。才需要手动清除登录信息,在进行登录。
清除登录
清除登录的信息
开启监听
为了绕过淘宝的检测。开启一个监听浏览器,然后让cookie失效时候,监听浏览器便自动去做验证,滑动验证通过的概率在60%。
开始采集
在确保账号已经登录,监听打开的情况下,开始进行采集
停止采集
此按键无效
- 开启mitmproxy代理,手动配置好浏览器代理,开启数据库服务器。
- 填写关键字,填写账号信息,填写配置信息
- 测试登录
- 账号登录
- 开启监听
- 开始采集
- 开启监听
- 开始采集
配置信息在开始采集前修改,当点击开始采集后便不能立即同步到采集的过程中
关闭浏览器 关闭软件