{kind=link}
爬取大众点评
爬取的难度在于获取坐标偏移的文字字典,页面中的部分文字标签是靠js依照坐标解析svg文件获得文字。
##更新爬虫项目2019-6-18
大众点评的前端dom结构更变。导致之前的代码不能够继续适用。
如http:https://www.dianping.com/shop/4122621/review_all/p3中的所有的评论的类标签都变成review。中间隐藏的文字应该是16进制,暂时没有进行解密。类似:
<svgmtsi class="review"></svgmtsi>
<svgmtsi class="review"></svgmtsi>
"的"
<svgmtsi class="review"></svgmtsi>
<svgmtsi class="review"></svgmtsi>
在之前的爬取项目中,我们采取获取网站css中的标签,然后与svg图片进行解析组合成字典库。评论中的class中的属性对应字典库中的信息。这样便能将所有的评论爬取。
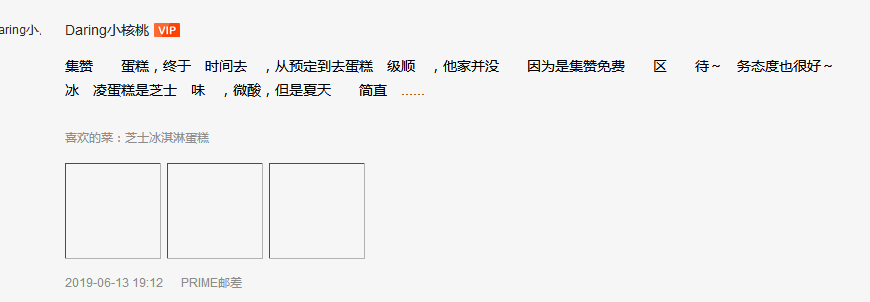
我们不选择绕过最近字库加密的方式。仍然选择原来的爬取方式,生成一个字典库,然后将评论的属性与字典库中的文字匹配。
通过发现解析网页的html发现不能只接对评论网站,返回结果内容如上面代码,class内容全部隐藏。
我们选择使用回应链接http:https://www.dianping.com/review/551096310,发现这里的评论竟然还是原来的解析方式。通过评论隐藏内容的属性的class的区别。()
这样我们就仍然可以使用过去的思想来进行修改。迭代新爬虫。
爬取的过程中需要我们在登录的情况下才能查看更多的评论,所以我们需要在浏览器中进行登录,获取登录后的cookie。
输入待爬取的目标的网站,内部解析网站中所有评论的详细评论链接、解析本次爬取过程的字典库需要两个条件,字库所对应的坐标与字典的svg矢量图的位置。然后对网站评论隐藏内容于字典库中的数据替换。解析所需要构造的内容如:头像、用户、标签、评论内容、图片、评分等。然后保存到txt或者其他,如有需要清洗成word格式。
0x01、解析评论链接
传入cookie并且设置好headers后进行爬取与解析评论回应链接。根据页面中是否有下一页来决定是否终止爬虫。
def _get_review_conment_page(self): # 获得评论内容
"""
请求评论页,并将<span></span>样式替换成文字
"""
while self._cur_request_url:
print('[{now_time}] {msg}'.format(now_time=datetime.datetime.now(), msg=self._cur_request_url))
res = requests.get(self._cur_request_url, headers=self._default_headers, cookies=self._cookies)
html = res.text
review_link = re.findall(r'><ahref="https://(.*?)"target="_blank"class="reply"',
html.replace(' ', '').replace('\n', ''))
del (review_link[0])
first_url = re.findall('ing.com/review/(.*?)', review_link[0])
review_link.extend(first_url) # 将评论列表加入到总队列中
self.review_links.extend(review_link)
doc = etree.HTML(html)
try:
self._default_headers['Referer'] = self._cur_request_url
next_page_url = 'http:https://www.dianping.com' + doc.xpath('.//a[@class="NextPage"]/@href')[0]
except IndexError:
next_page_url = None
self._cur_request_url = next_page_url
0x02、构造字典库
这一步是比较麻烦的一个过程,只能点到为止,具体内容还需要你仔细观察代码。
首先我们通过F12找到对应的评论中的隐藏的字,然后根据class的属性就能找到索要加载的css与svg。我们发现一个文字有对应的一个标签,且相同的字体拥有同样的标签。这样就好办了。找到对应的文字,大概3-5个不同标签。记录下对应的标签-css中坐标位置-svg中文字的xy坐标位置。
css文件内容样例:.owfmjw{background:-154.0px -2201.0px;}
.owfmjw{background:-154.0px -2201.0px;}.owfe1r{background:-364.0px -1420.0px;}.owfxo6{background:-14.0px -1455.0px;}.owfy4m{background:-266.0px -2019.0px;}.owfjg4{background:-392.0px -1532.0px;}.occsi7{background:-92.0px -60.0px;}.owffde{background:-448.0px -622.0px;}.owf3mq{background:-462.0px -1924.0px;}.owfka1{background:-350.0px -2114.0px;}.owfvy8{background:-308.0px -62.0px;}.owfel7{background:-224.0px -622.0px;}.owf37y{background:-14.0px -373.0px;}.owfl4g{background:-560.0px -2333.0px;}.owflht{background:-112.0px -1306.0px;}.owfjrf{background:-574.0px -662.0px;}.owfidj{background:-210.0px -1847.0px;}.owfzvj{background:-448.0px -1420.0px;}.occfbp{background:-442.0px -60.0px;}.owfb9e{background:-224.0px -1217.0px;}.owfaug{background:-322.0px -1171.0px;}.owfjcj{background:-560.0px -1498.0px;}.owfmw6{background:-532.0px -1348.0px;}.owfurs{background:-154.0px -373.0px;}.owfgsd{background:-154.0px -2163.0px;}.owftup{background:-392.0px -2163.0px;}.owfz1d{background:-322.0px -2243.0px;}.owfvmg{background:-546.0px -1878.0px;}.owfpau{background:-42.0px -1217.0px;}.owfmdm{background:-434.0px -798.0px;}.owfvxu{background:-532.0px -842.0px;}.owf76l{background:-196.0px -415.0px;}.owf0gi{background:-28.0px -195.0px;}.owfda1{background:-462.0px -284.0px;}.owfchs{background:-434.0px -1171.0px;}.owfw6z{background:-518.0px -327.0px;}.owfqqf{background:-196.0px -955.0px;}.owfq1l{background:-126.0px -912.0px;}.owfs36{background:-476.0px -62.0px;}.owfe0y{background:-42.0px -2333.0px;}.owfw6o{background:-490.0px -2163.0px;}.owf75m{background:-532.0px
svg内容样例<text x="0" y="46">历分爆</text>
<text x="0" y="46">历分爆锅父碰茅恐寸矮异唐险乓绢梢菊装罗拘欲则悲鹊北奉慕袄限洞都凶千密暮达快容糖秧澡私</text>
<text x="0" y="85">扔品惕倦南观只死夺刊浑糠扭康淡蛛妄冶夫捡喷脚情项遵发滋铜灌锣垫盲极歉事讲腰押穿果或廉</text>
<text x="0" y="129">趁鼓鸽幼翅脖尼畅抽遗绸删被海乞肺识垄素湾齐室梦姑善朗皮乒助摄办长令胜炼搂陡漫场浪般价</text>
<text x="0" y="169">兔朱肝朽踪骡弓帝人腐津代典志解责博建酬阳出技必诗救窑摘堤扁峰焰虏孩骑御愉爸敌阀顿仇于</text>
<text x="0" y="218">挂遍等纷壮隶非猾匹会载岸萄置缎姜星龙珍深许构违势医夹首卜汁把嘱顶拿痛翁狱样枝销疑崇泻</text>
<text x="0" y="259">伞追困到惜系伍奔贸野云蛇炮虫童供内猜忍轿沙布执挑如得呀境祸岗饮又乡灿搜扣脂遇中乙迈缺</text>
<text x="0" y="307">沟勺瓶毛岂宙汉奏愈返们姿化普压连宾货截您唇璃兰雨染墨恢棕植灰垮茶右敞为太杰隙香雹将呆</text>
<text x="0" y="350">稳柄劳督仰股轧扎崖我悼影饱专药给职逮剃耽骗拳尘提摧践瑞谈饺杨渔占孝亭林娃晃鄙临央催箱</text>
一般找到3-5个文字就能猜出了文字库的规律。
def _get_font_dict_by_offset(self, url):
"""
获取坐标偏移的文字字典, 会有最少两种形式的svg文件(目前只遇到两种)
"""
res = requests.get(url, timeout=60)
html = res.text
font_dict = {}
y_list = re.findall(r'd="M0 (\d+?) ', html)
if y_list:
font_list = re.findall(r'<textPath .*?>(.*?)<', html)
for i, string in enumerate(font_list):
y_offset = self.start_y - int(y_list[i])
sub_font_dict = {}
for j, font in enumerate(string):
x_offset = -j * self.font_size
sub_font_dict[x_offset] = font
font_dict[y_offset] = sub_font_dict
else:
font_list = re.findall(r'<text.*?y="(.*?)">(.*?)<', html)
for y, string in font_list:
y_offset = self.start_y - int(y)
sub_font_dict = {}
for j, font in enumerate(string):
x_offset = -j * self.font_size
sub_font_dict[x_offset] = font
font_dict[y_offset] = sub_font_dict
# print('字体字典', font_dict)
return font_dict
def _get_font_dict(self, url):
"""
获取css样式对应文字的字典
"""
print('解析svg成字典的css', url)
res = requests.get(url, headers=self._css_headers, cookies=self._cookies, timeout=60)
html = res.text
background_image_link = re.findall(r'background-image: url\((.*?)\);', html)
print('带有svg的链接', background_image_link)
assert background_image_link
background_image_link = 'http:' + background_image_link[1]
html = re.sub(r'span.*?\}', '', html)
group_offset_list = re.findall(r'\.([a-zA-Z0-9]{5,6}).*?round:(.*?)px (.*?)px;', html) # css中的类
# print('css中class对应坐标', group_offset_list)
font_dict_by_offset = self._get_font_dict_by_offset(background_image_link) # svg得到这里面对应成字典
# print('解析svg成字典', font_dict_by_offset)
for class_name, x_offset, y_offset in group_offset_list:
y_offset = y_offset.replace('.0', '')
x_offset = x_offset.replace('.0', '')
# print(y_offset,x_offset)
if font_dict_by_offset.get(int(y_offset)):
self.font_dict[class_name] = font_dict_by_offset[int(y_offset)][int(x_offset)]
return self.font_dict

0x03、替换标签内容
得到对应的字典库,匹配详情页面中的隐藏评论标签,换成对应的文字。
class_set = set()
for span in re.findall(r'<svgmtsi class="([a-zA-Z0-9]{5,6})"></svgmtsi>', html):
class_set.add(span)
for class_name in class_set:
html = re.sub('<svgmtsi class="%s"></svgmtsi>' % class_name, self._font_dict.get(class_name,''), html)
0x04、得到数据
运用你想用的任何解析html的方式,re、bs4、pyquery、xpath、css等都可以将数据提取出来。这里写的仓促不值得借鉴。
None

0x05、保存数据
应别人要求,将数据保存在word中,并且图片也要保存下来
我们使用docx的库来操作word。为每一部分都设置格式。
pensize.font.name = '宋体'
pensize._element.rPr.rFonts.set(qn('w:eastAsia'), '宋体')
pensize.font.size = Pt(15)
pensize.bold=True
看到docx文件说能读取内存中的图片,找了好久都没发现这个用法。就临时设置缓存文件进行保留爬取的图片。
req = requests.get(p)
with open('capth.png','wb')as f:
f.write(req.content)
doc.add_picture('capth.png', width=Inches(2.5))
