# DLRover
DLRover: An Automatic Distributed Deep Learning System
[](https://github.com/intelligent-machine-learning/easydl/actions/workflows/main.yml)
[](https://codecov.io/gh/intelligent-machine-learning/dlrover)
[](https://pypi.org/project/dlrover/)
DLRover makes the distributed training of large AI models easy, stable, fast and green.
It can automatically train the Deep Learning model on the distributed cluster.
It helps model developers to focus on model arichtecture, without taking care of
any engineering stuff, say, hardware acceleration, distributed running, etc.
Now, it provides automated operation and maintenance for deep learning
training jobs on K8s/Ray. Major features as
- **Fault-Tolerance**, single node failover without restarting the entire job.
- **Auto-Scaling**, Automatically scale up/down resources at both
node level and CPU/memory level.
- **Dynamic data sharding**, dynamic dispatch training data to each worker
instead of dividing equally, faster worker more data.
- **Automatic Resource Optimization**, Automatically optimize the job resource
to improve the training performance and resources utilization.
## Latest News
- [2023/11] [ATorch supporting efficient and easy-to-use model training is released.](atorch/README.md)
- [2023/10] [AGD: an Auto-switchable Optimizer using Stepwise Gradient Difference as Preconditioning Matrix, NeurIPS 2023.](atorch/docs/README-AGD.md)
- [2023/09] [Weighted Sharpness-Aware Minimization (WSAM) has been accepted by KDD'23.](atorch/docs/README-WSAM.md)
- [2023/08] [DLRover improves the stability of pre-trained model training over thousands of GPUs.](docs/blogs/stabilize_llm_training_cn.md)
- [2023/04] [DLRover auto-scales nodes of a DeepRec distributed training job.](docs/blogs/deeprec_autoscale_cn.md)
## Why DLRover?
### Fault Tolerance to Reduce the Downtime of a Large Scale Training Job
DLRover can restore the training when the process fails without stopping the
training job. The actions to restore training in DLRover are:
1. Automatically diagnose the failure reason.
2. Restart the process not the node due to software errors.
3. Restart the failed nodes due to hardward errors.
For detail, we can see [experiments](docs/tech_report/fault_tolerance_exps.md)
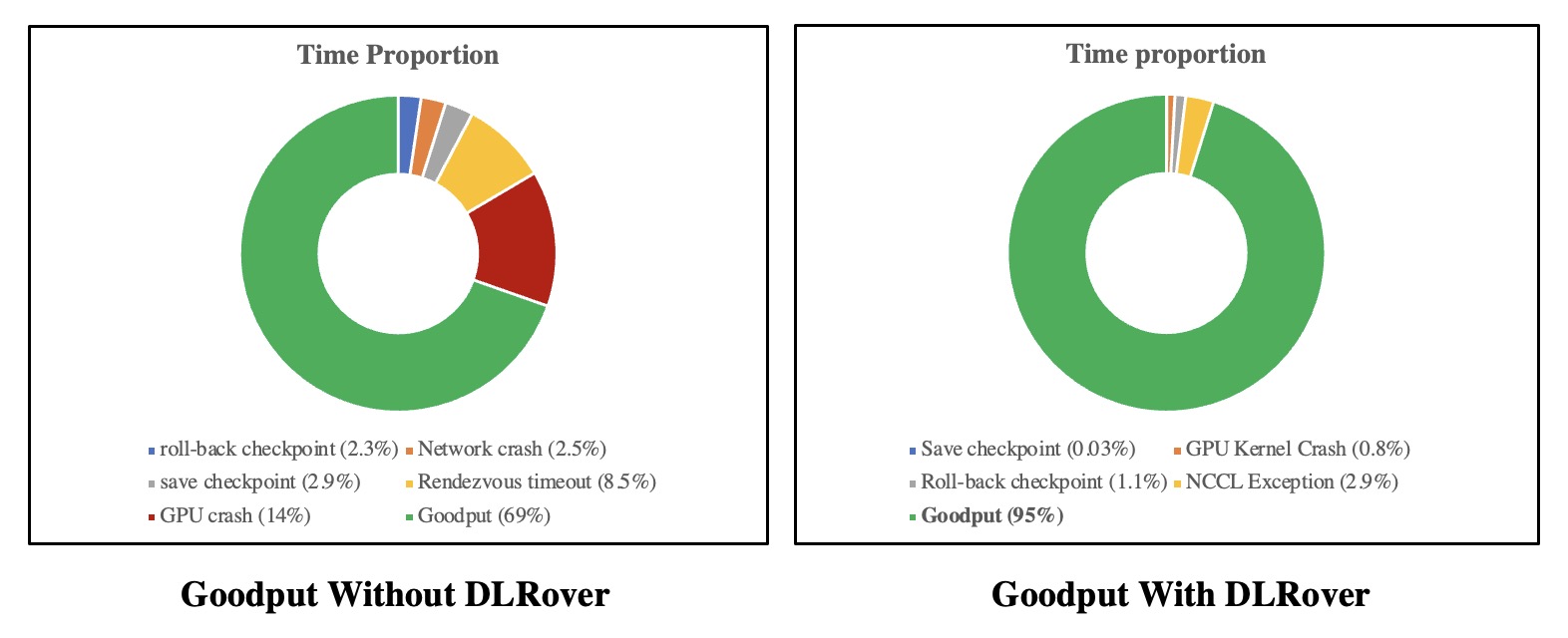
of fault-tolerance and elasticity. With fault tolerance, the goodput of GLM-65B training
on thousands of GPUs increased from 69% to 95%**. The goodput is the time spent computing
useful new steps over the elapsed time of the training job.
The downtime details are shown:
#### Fault Tolerance and Flash Checkpoint to Reduce Downtime of PyTorch Training
In addition to fault tolerance, DLRover provides the [flash checkpoint](docs/blogs/flash_checkpoint.md) to
save/load checkpoint in seconds. With flash checkpoint, the training can
frequently save checkpoints and reduce the roll-back step to resume training
from the latest checkpoint when a failure happens. The actions of flash checkpoint are:
1. Asynchronously persist the checkpoint to the storage.
2. Persist the checkpoint to the storage once the training process fails.
3. Load the checkpoint from the host memory after the training process restarts.
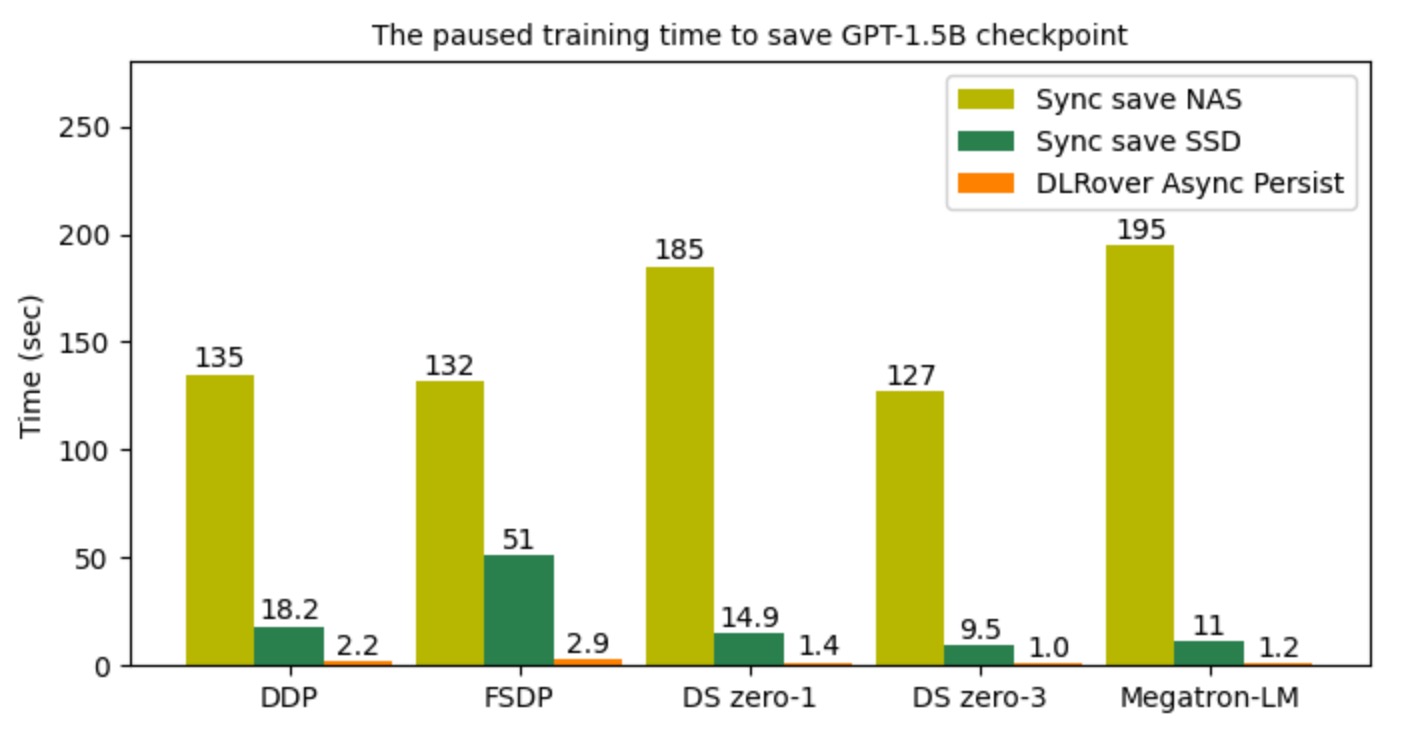
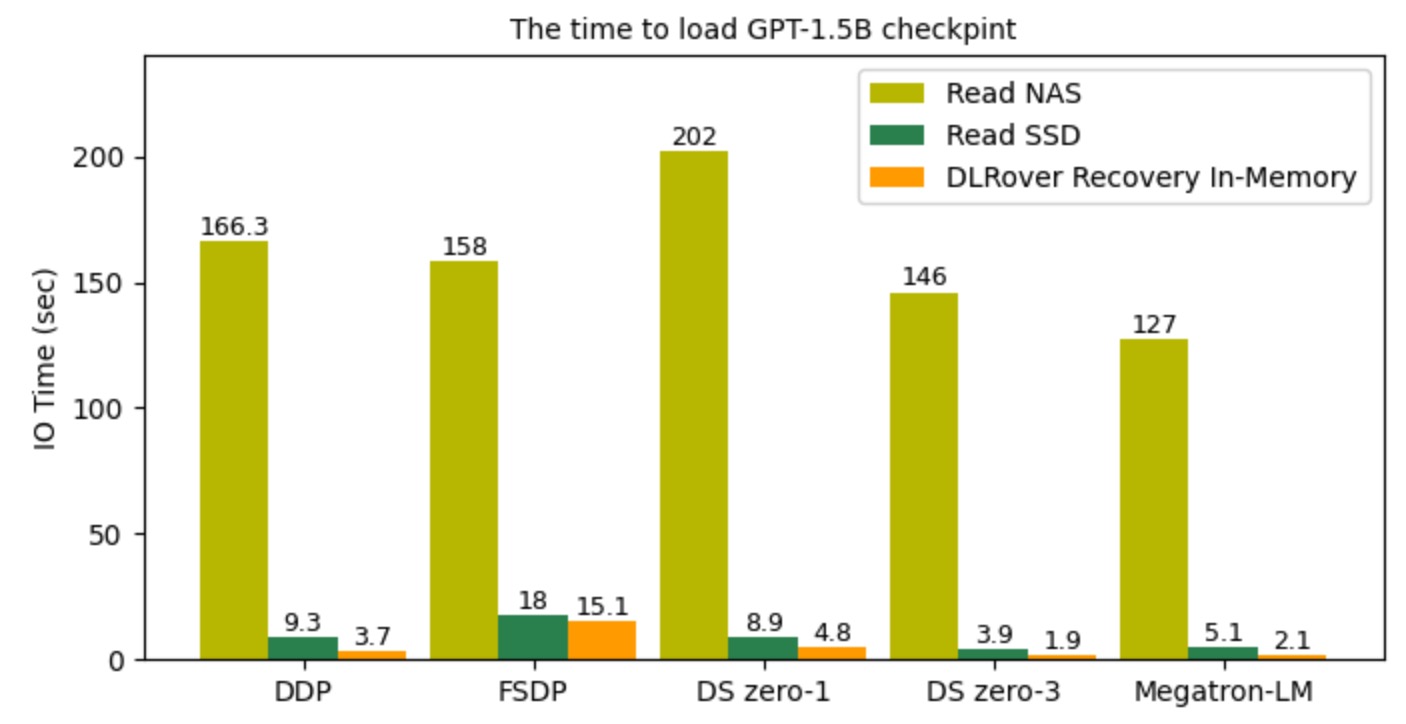 The Performance of DLRover Flash Checkpoint to Save/Load GPT2-1.5B.
The Performance of DLRover Flash Checkpoint to Save/Load GPT2-1.5B.
The figure illustrates that the I/O time to read checkpoint files
when resuming training processes. With DLRover Flash Checkpoint,
recovery could be completed in the order of seconds by loading checkpoints directly from shared memory,
which is much faster compared to loading checkpoints from SSD and NAS.
#### Fault Tolerance Improves the Stability of TensorFlow PS Training
DLRover can recover failed parameter servers and workers to resume training.
1. DLRover can automatically launch a Pod with more memory to recover the OOM node.
2. DLRover can reassign the training data of a failed worker to other workers.
3. DLRover can automatically scale up the parameter servers to fit the model size.
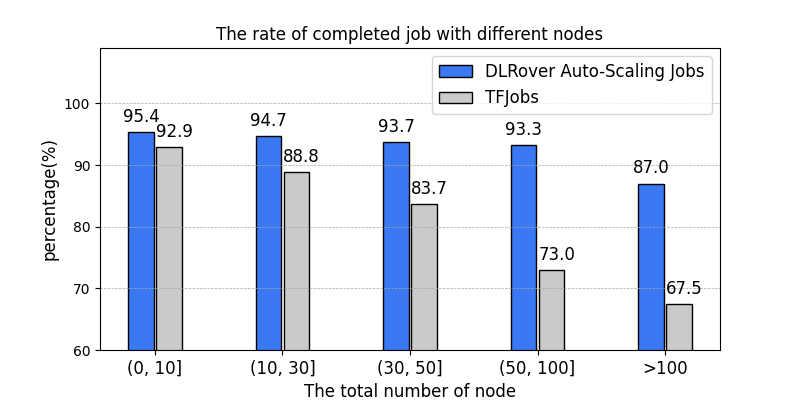
In AntGroup, DLRover manages hundreds of DL training jobs every day on the customized Kubernetes cluster in AntGroup.
Except for the failed job resulting from code errors, **the rate of completed jobs increase from 89%
with tf-operator in KubeFlow to 95%**. Other unrecoverable failure reasons of a job are data error,
NaN loss of the model, network breakdown, and so on.
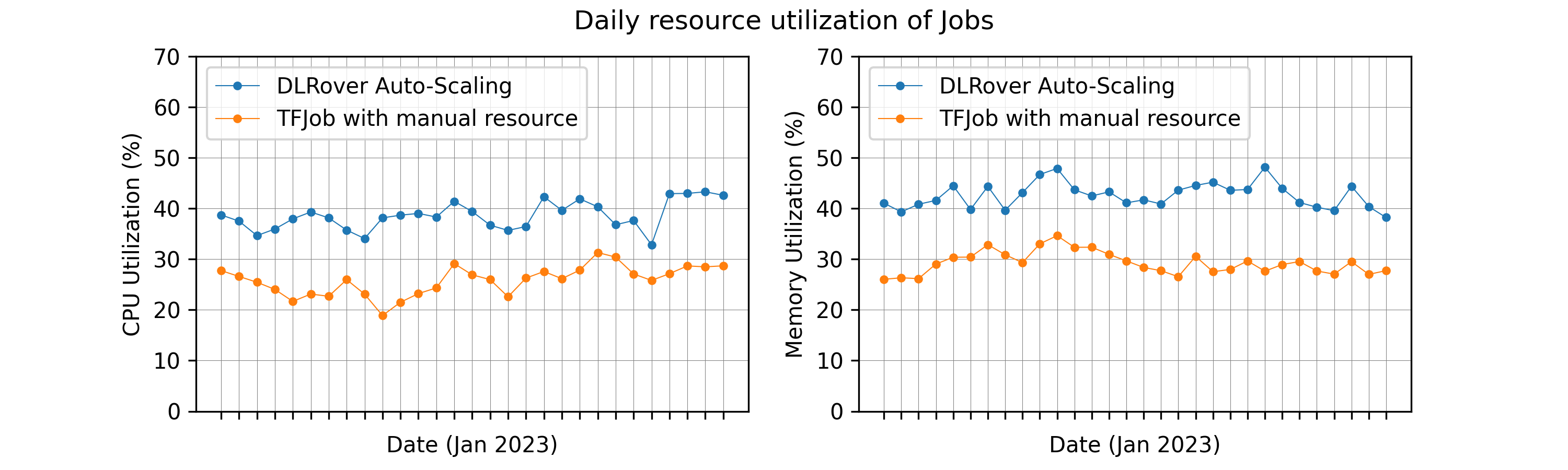
### Auto-Scaling to Improve Training Performance and Resource Utilization
DLRover automatically scales up/down resources (for parameter servers or workers) at the runtime of a training job.
By monitoring the workload of nodes and throughput, DLRover can diagnose the bottleneck of the resource configuration.
The common bottleneck contains node straggler, the unbalanced workload of PS, insufficient CPU cores of nodes,
and the insufficient number of nodes. DLRover can improve the training performance by dynamic resource adjustment.
In order to improve the training througphput, users prefer to
configure their jobs with over-provision resources to
avoid any potential risk from insufficient resources.
This usually ends up in huge resource waste. DLRover Auto-Scaling
can allocate resources by the demand of model training to reduce
the waste of resources.
### Dynamic Data Sharding For Elasticity and Fault-tolerance
Dynamic data sharding splits the dataset into many small shards and each shard only
contains a few batches of training samples. The worker will get a shard only when it using up
samples of the last one. With the dynaic sharding, DLRover can
- recover the shard if the worker fails before using up samples of the shard.
- mitigate the worker straggler by assigning more shards to the fast worker.
### Integration to Offline and Online Deep Learning
With the data source transparency provided by dynamic data sharding, DLRover can be integrated with
offline training which consumes batch data, and also supports online learning with real-time streaming data.
(fed with a message queue like RocketMQ/Kafka/Pulsar/...,
or executed as a training sink node inside Flink/Spark/Ray/...)
By practice, DLRover is an ideal component to build an end-to-end industrial online learning system,
[estimator.md](docs/tutorial/estimator.md) provides a detailed example implemented with `tf.estimator.Estimator`.
## How to Use DLRover to Train Your Models?
We can use `dlrover-run` to run the training script which
`torchrun` or `torch.distributed.run` can run.
### Local Run to Train a PyTorch Model
We run DLRover locally like
```bash
pip install dlrover[torch]
dlrover-run --standalone --nproc_per_node=$NUM_TRAINERS train_scripts.py
```
### Distributed Run to Train a PyTorch Model
#### Run in a DLRover ElasticJob
Firstly, the user need to deploy the DLRover elasticjob controller in a kubernetes
cluster by followding the [tutorial](docs/deployment/controller.md). Then, we need
to install `dlrover[torch]` and execute `dlrover-run` in
the command of the Pod container like the example [torch_mnist_job.yaml](examples/pytorch/mnist/elastic_job.yaml).
```bash
pip install dlrover[torch] && \
dlrover-run --network-check --nnodes=$NODE_NUM --nproc_per_node=$NUM_TRAINERS train_scripts.py
```
`--nnodes` is the number of nodes and `--nproc_per_node` is the number of process
on each node. They are the same as the arguments of [torchrun](https://pytorch.org/docs/stable/elastic/run.html).
#### Run in other k8s Jobs
We can also use `dlrover-run` in other k8s jobs like [kubeflow/PyTorchJob](https://www.kubeflow.org/docs/components/training/pytorch/).
We need to set the `NODE_RANK` and `DLROVER_MASTER_ADDR` before `dlrover-run`.
For example, the `PyTorchJob` has set the `RANK`, `MASTER_ADDR` and `MASTER_PORT`
into environments. We can run `dlrover-run` like
```bash
NODE_RANK=$RANK DLROVER_MASTER_ADDR=$MASTER_ADDR:$MASTER_PORT \
dlrover-run --network-check --nnodes=$NODE_NUM --nproc_per_node=$NUM_TRAINERS train_script.py
```
**Note**:
- `dlrover-run` extends `torchrun` which dynamically configures `MASTER_ADDR` and `MASTER_PORT`
for training processes. We can use the static `MASTER_ADDR` and `MASTER_PORT` of PyTorchJob as the address
of DLRover job master.
- The elastic scheduling of DLRover to restore or scale up/down Pods
is not enabled without DLRover ElasticJob.
### Train a TensorFlow Model
We can use DLRover to train a TensorFlow by the following steps:
- Use TensorFlow estimator to develop the TensorFlow model.
- Define the input of `tf.dataset` in a training configuration of DLRover.
- Define your reader to read samples from the dataset file.
We can refer to the [estimator.md](docs/tutorial/estimator.md) to train
a model with DLRover.
## What's Next?
- Multi-node in-memory redundant backup checkpoint to fast failure recovery.
- Fine-grained automatic distributed training for GPU Synchronous jobs
- hybrid-parallel mode
- adapted hyper parameters adjustment with dynamic resources
- more strategies for Fine-grained scenarioes
- Full stack solution for Online Deep Learning
- High performance extension library for Tensorflow/Pytorch to speed up training
- ...
## Contributing
Please refer to the [DEVELOPMENT](docs/developer_guide.md)
## Quick Start
[Train a PyTorch Model on Kubernetes.](docs/tutorial/torch_elasticjob_on_k8s.md)
[Train a GPT Model on Kubernetes.](docs/tutorial/torch_ddp_nanogpt.md)
[Use DLRover to find slow/fault nodes.](docs/tutorial/check_node_health.md)
[Train a TensorFlow Estimator on Kubernetes.](docs/tutorial/tf_ps_on_cloud.md)