Combining the Azure Cosmos DB, the industry's first globally-distributed, multi-model database service, and HDInsight not only allows you to accelerate real-time big data analytics, but also allows you to benefit from a Lambda Architecture while simplifying its operations.

For a quick overview of the various notebooks and components for our Lambda Architecture samples, please refer to the Channel 9 video Real-time Analytics with Azure Cosmos DB and Apache Spark.
- Azure Cosmos DB Collection(s)
- HDI (Apache Spark 2.1) cluster
- Spark Connector: We are currently using the 1.0 version of the connector.
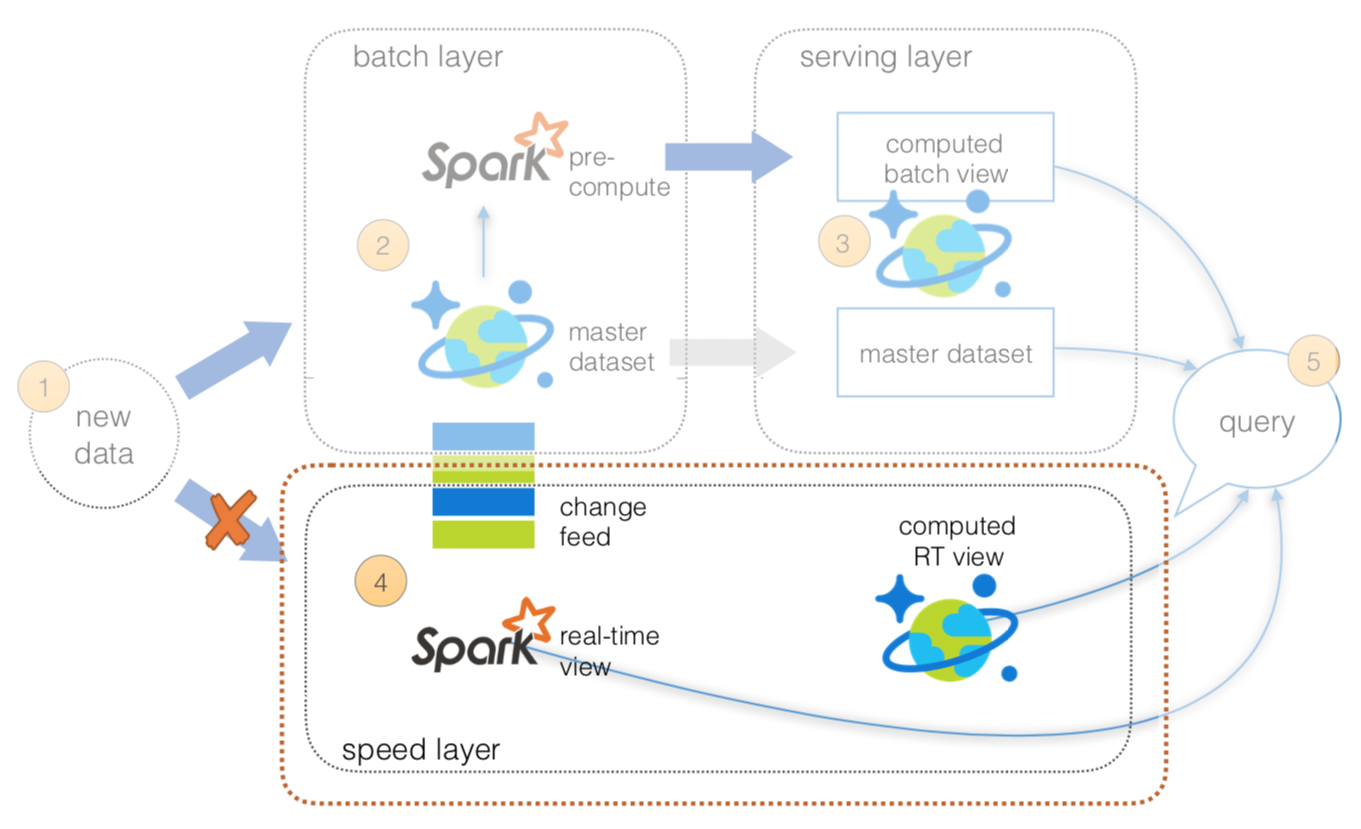
A Lambda Architecture is a generic, scalable, and fault-tolerant data processing architecture to address batch and speed latency scenarios as described by Nathan Marz.
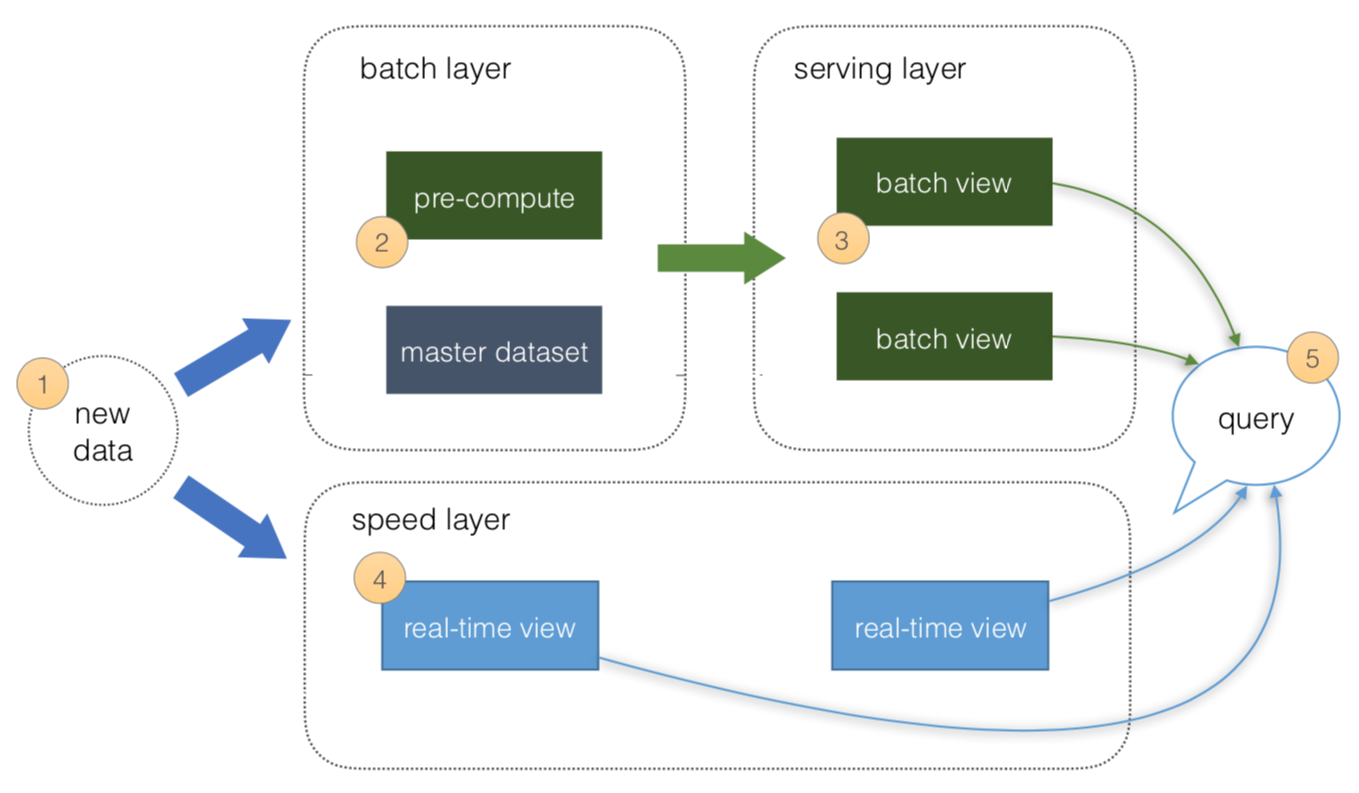
The basic principles of a Lambda Architecture is described in the preceding diagram as per https://lambda-architecture.net.
- All data is pushed into both the batch layer and speed layer.
- The batch layer has a master dataset (immutable, append-only set of raw data) and pre-compute the batch views.
- The serving layer has batch views so data for fast queries.
- The speed layer compensates for processing time (to serving layer) and deals with recent data only.
- All queries can be answered by merging results from batch views and real-time views or pinging them individually.
From an operations perspective, maintaining two streams of data while ensuring correct state for the data can be a complicated endeavor. To simplify this, we can utilize Azure Cosmos DB Change Feed to keep state for the batch layer while revealing the Azure Cosmos DB Change log via the Change Feed API for your speed layer.
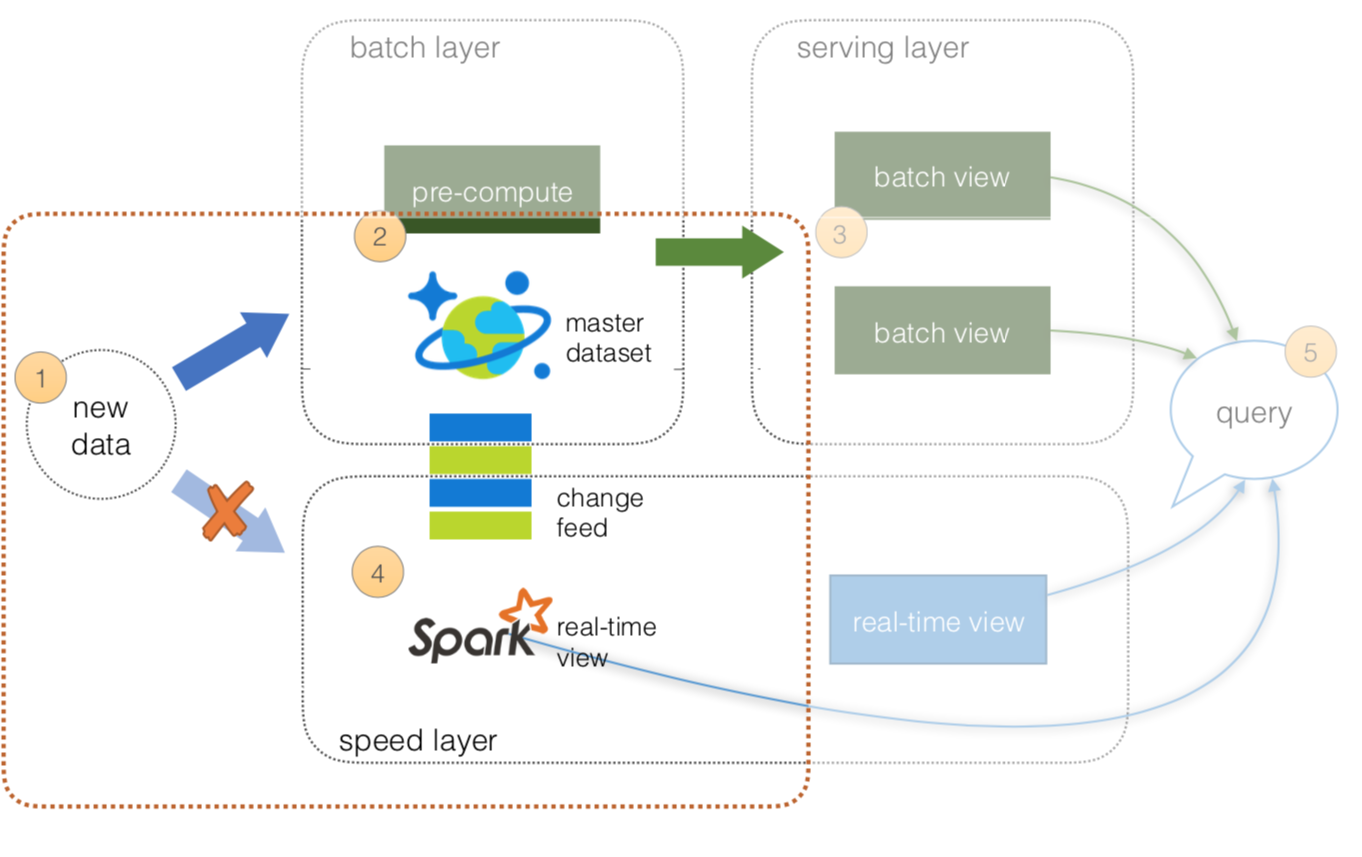
- All data is pushed only into Azure Cosmos DB thus you can avoid multi-casting issues.
- The batch layer has a master dataset (immutable, append-only set of raw data) and pre-compute the batch views.
- The serving layer will be discussed in the next section.
- The speed layer utilizes HDInsight (Apache Spark) that will read the Azure Cosmos DB Change Feed. This allows you to persist your data as well as to query and process it concurrently.
- All queries can be answered by merging results from batch views and real-time views or pinging them individually.
To run a quick prototype of the Azure Cosmos DB Change Feed as part of the speed layer, we can test it out using Twitter data as part of the Stream Processing Changes using Azure Cosmos DB Change Feed and Apache Spark example. To jump start your Twitter output, please refer to the code sample in Stream feed from Twitter to Cosmos DB. With the above example, you're loading Twitter data into Azure Cosmos DB and you can then setup your HDInsight (Apache Spark) cluster to connect to the change feed. For more inforamtion on how to setup this configuration, please refer to Apache Spark to Azure Cosmos DB Connector Setup.
Below is the code snippet on how to configure spark-shell to run a Structred Streaming job to connect to Azure Cosmos DB Change Feed to review the real-time Twitter data stream to perform a running interval count.
// Import Libraries
import com.microsoft.azure.cosmosdb.spark._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.codehaus.jackson.map.ObjectMapper
import com.microsoft.azure.cosmosdb.spark.streaming._
import java.time._
// Configure connection to Azure Cosmos DB Change Feed
val sourceConfigMap = Map(
"Endpoint" -> "[COSMOSDB ENDPOINT]",
"Masterkey" -> "[MASTER KEY]",
"Database" -> "[DATABASE]",
"Collection" -> "[COLLECTION]",
"ConnectionMode" -> "Gateway",
"ChangeFeedCheckpointLocation" -> "checkpointlocation",
"changefeedqueryname" -> "Streaming Query from Cosmos DB Change Feed Interval Count")
// Start reading change feed as a stream
var streamData = spark.readStream.format(classOf[CosmosDBSourceProvider].getName).options(sourceConfigMap).load()
// Start streaming query to console sink
val query = streamData.withColumn("countcol", streamData.col("id").substr(0, 0)).groupBy("countcol").count().writeStream.outputMode("complete").format("console").start()
For complete code samples, please refer to azure-cosmosdb-spark/lambda/samples including:
The output of this of this is a spark-shell console continiously running a structured steraming job performing an interval count against the Twitter data from the Azure Cosmos DB Change Feed.

For more information on Azure Cosmos DB Change Feed, please refer to:
- Working with the change feed support in Azure Cosmos DB
- Introducing the Azure CosmosDB Change Feed Processor Library
- Stream Processing Changes: Azure CosmosDB change feed + Apache Spark
Since the data is loaded into Azure Cosmos DB (where the change feed is being used for the speed layer), this is where the master dataset (an immutable, append-only set of raw data) resides. From this point onwards, we can use HDInsight (Apache Spark) to perform our pre-compute from batch layer to serving layer.
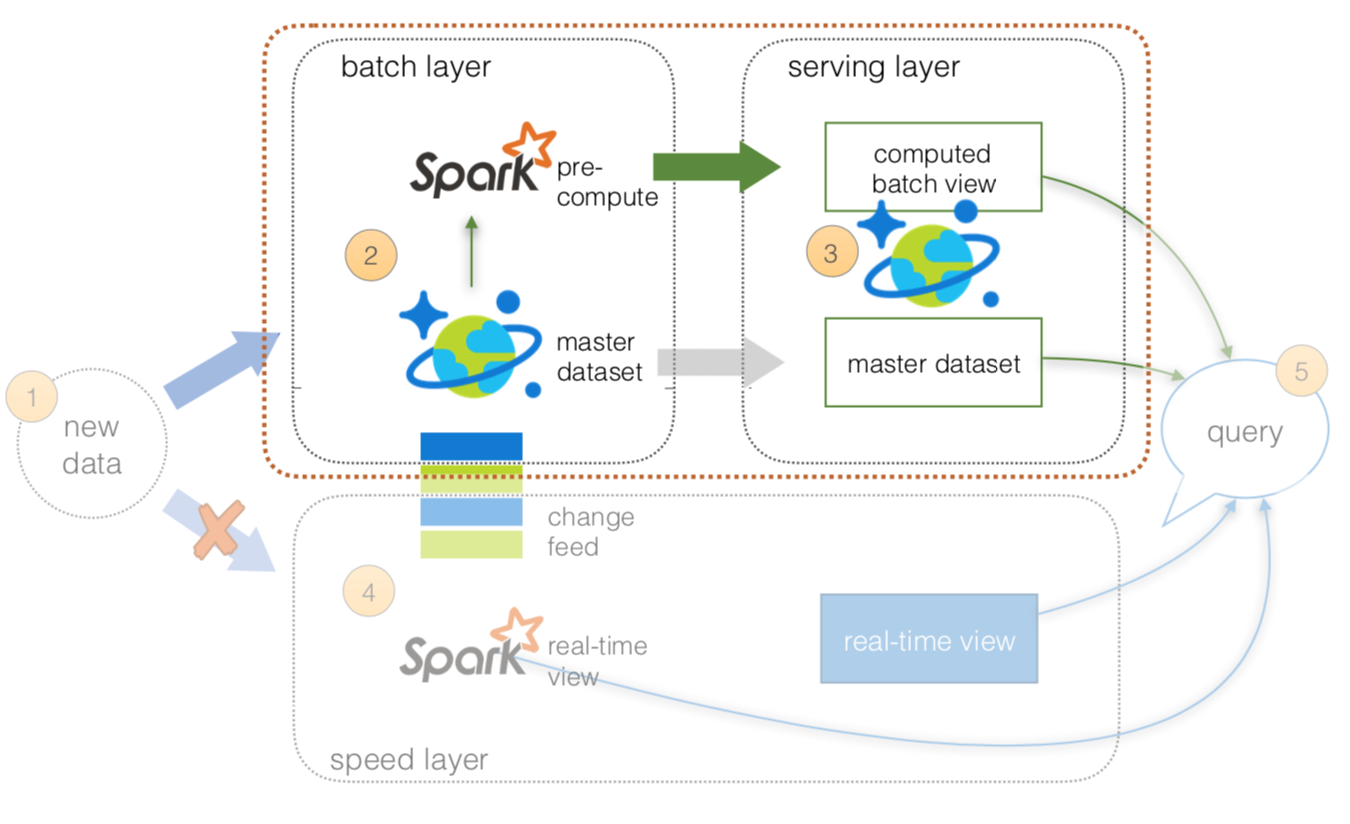
- All data pushed into only Azure Cosmos DB (avoid multi-cast issues)
- The batch layer has a master dataset (immutable, append-only set of raw data) stored in Azure Cosmos DB. Using HDI Spark, you can pre-compute your aggregations to be stored in your computed batch views.
- The serving layer is an Azure Cosmos DB database with collections for master dataset and computed batch view.
- The speed layer will be discussed next slide.
- All queries can be answered by merging results from batch views and real-time views or pinging them individually.
To showcase how to execute pre-calculated views against your master dataset from Apache Spark to Azure Cosmos DB, below are code snippets from the notebooks Lambda Architecture Re-architected - Batch Layer and Lambda Architecture Re-architected - Batch to Serving Layer. In this scenario, we will be using Twitter data stored in Cosmos DB.
- Let's start by creating the configuration connection to our Twitter data within Azure Cosmos DB using the PySpark code below.
# Configuration to connect to Azure Cosmos DB
tweetsConfig = {
"Endpoint" : "[Endpoint URL]",
"Masterkey" : "[Master Key]",
"Database" : "[Database]",
"Collection" : "[Collection]",
"preferredRegions" : "[Preferred Regions]",
"SamplingRatio" : "1.0",
"schema_samplesize" : "200000",
"query_custom" : "[Cosmos DB SQL Query]"
}
# Create DataFrame
tweets = spark.read.format("com.microsoft.azure.cosmosdb.spark").options(**tweetsConfig).load()
# Create Temp View (to run Spark SQL statements)
tweets.createOrReplaceTempView("tweets")
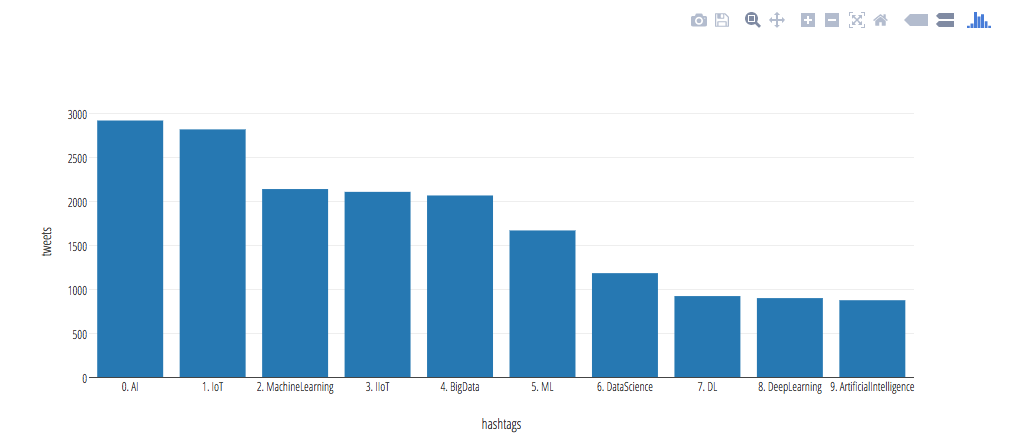
- Next, let's run the following Spark SQL statement to determine the top 10 hashtags of our set of tweets. Note, for this Spark SQL query, we're running this in a Jupyter notebook without the output bar chart directly below this code snippet.
%%sql
select hashtags.text, count(distinct id) as tweets
from (
select
explode(hashtags) as hashtags,
id
from tweets
) a
group by hashtags.text
order by tweets desc
limit 10
- Now that you have your query, let's save it back to a collection by using the Spark Connector to save the output data into a different collection. In this example, we will use Scala to showcase the connection. Similar to the previous example, creating the configuration connection to save our Apache Spark DataFrame to a different Azure Cosmos DB collection.
val writeConfigMap = Map(
"Endpoint" -> "[Endpoint URL]",
"Masterkey" -> "[Master Key]",
"Database" -> "[Database]",
"Collection" -> "[New Collection]",
"preferredRegions" -> "[Preferred Regions]",
"SamplingRatio" -> "1.0",
"schema_samplesize" -> "200000"
)
// Configuration to write
val writeConfig = Config(writeConfigMap)
- After specifying the
SaveMode(i.e. whether to Overwrite or Append documents), we createtweets_bytagsDataFrame similar to the Spark SQL query in the previous example. With thetweets_bytagsDataFrame created, you can save it using thewritemethod using the previously specifiedwriteConfig.
// Import SaveMode so you can Overwrite, Append, ErrorIfExists, Ignore
import org.apache.spark.sql.{Row, SaveMode, SparkSession}
// Create new DataFrame of tweets tags
val tweets_bytags = spark.sql("select hashtags.text as hashtags, count(distinct id) as tweets from ( select explode(hashtags) as hashtags, id from tweets ) a group by hashtags.text order by tweets desc")
// Save to Cosmos DB (using Append in this case)
tweets_bytags.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
This last statement now has saved your Spark DataFrame into a new Azure Cosmos DB collection; from a lambda architecture perspective, this is your batch view within the serving layer.
For complete code samples, please refer to azure-cosmosdb-spark/lambda/samples including:
As previously noted, using Azure Cosmos DB Change Feed allows us to simplfy the operations between the batch and speed layers. In this architecture, we are using Apache Spark (via HD Insight) to perform our structured streaming queries against the data. But you may also want to temporarily persist the results of your structured streaming queries so other systems can access this data.
To do this, we can create a separate Cosmos DB collection to save the results of your structured streaming queries. This allows you to have other systems access this information not just Apache Spark. As well with the Cosmos DB Time-to-Live (TTL) feature, you can configure your documents to be automatically deleted after a set duration. For more information on the Azure Cosmos DB TTL feature, please refer to Expire data in Azure Cosmos DB collections automatically with time to live
// Import Libraries
import com.microsoft.azure.cosmosdb.spark._
import com.microsoft.azure.cosmosdb.spark.schema._
import com.microsoft.azure.cosmosdb.spark.config.Config
import org.codehaus.jackson.map.ObjectMapper
import com.microsoft.azure.cosmosdb.spark.streaming._
import java.time._
// Configure connection to Azure Cosmos DB Change Feed
val sourceCollectionName = "[SOURCE COLLECTION NAME]"
val sinkCollectionName = "[SINK COLLECTION NAME]"
val configMap = Map(
"Endpoint" -> "[COSMOSDB ENDPOINT]",
"Masterkey" -> "[COSMOSDB MASTER KEY]",
"Database" -> "[DATABASE NAME]",
"Collection" -> sourceCollectionName,
"ChangeFeedCheckpointLocation" -> "changefeedcheckpointlocation")
val sourceConfigMap = configMap.+(("changefeedqueryname", "Structured Stream replication streaming test"))
// Start to read the stream
var streamData = spark.readStream.format(classOf[CosmosDBSourceProvider].getName).options(sourceConfigMap).load()
val sinkConfigMap = configMap.-("collection").+(("collection", sinkCollectionName))
// Start the stream writer to new collection
val streamingQueryWriter = streamData.writeStream.format(classOf[CosmosDBSinkProvider].getName).outputMode("append").options(sinkConfigMap).option("checkpointLocation", "streamingcheckpointlocation")
var streamingQuery = streamingQueryWriter.start()
As noted in the previous sections, we can simplify our Lambda Architecture by using Azure Cosmos DB, the Cosmos DB Change Feed to avoid the need to multi-cast your data between the batch and speed layers, Apache Spark on HDInsight, and the Spark Connector for Azure Cosmos DB.
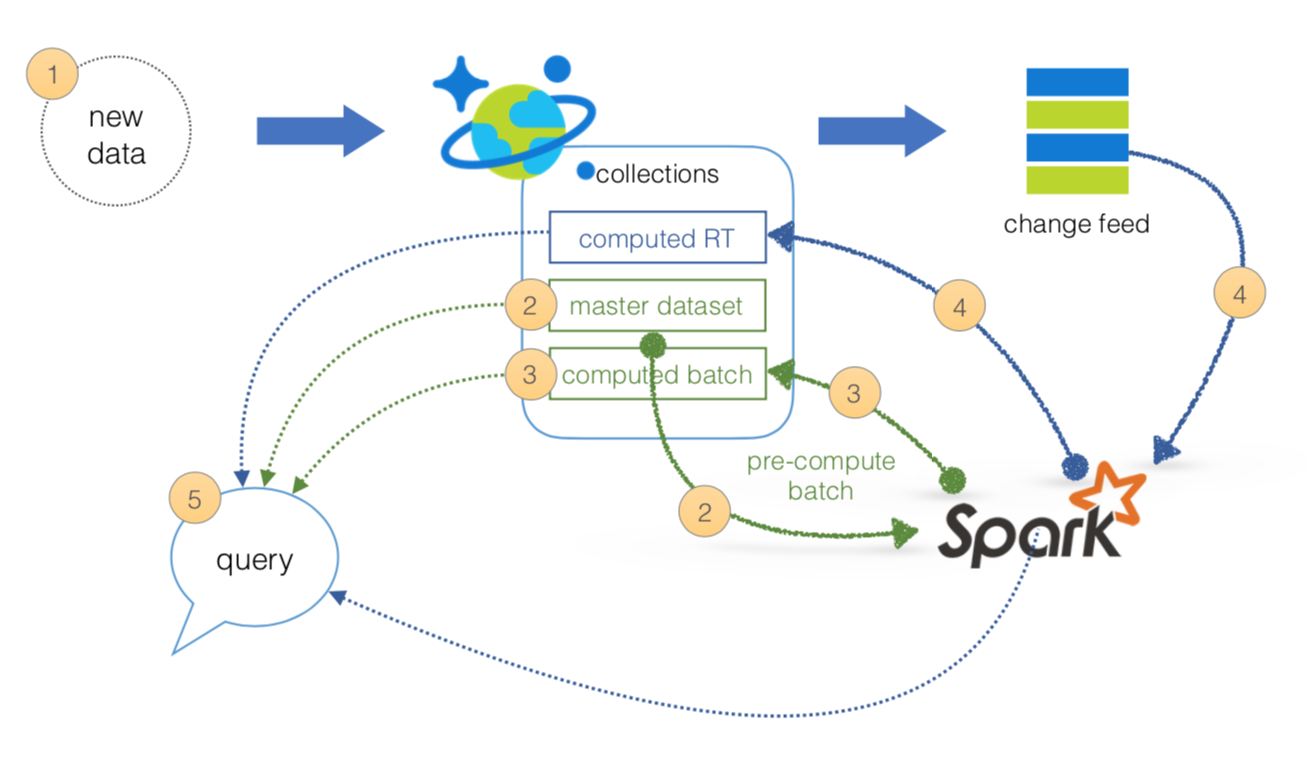
With this design, we need only two two managed services that together will address the batch, serving, and speed layers of our Lambda Architecture simplifying not only the operations but also the data flow.
- All data pushed into Cosmos DB layer for processing
- The batch layer has a master dataset (immutable, append-only set of raw data) and pre-compute the batch views
- The serving layer has batch views so data for fast queries.
- The speed layer compensates for processing time (to serving layer) and deals with recent data only.
- All queries can be answered by merging results from batch views and real-time views.
The samples included are
- We will use the Stream feed from Twitter to CosmosDB as our mechanism to push new data into Cosmos DB.
- The batch layer is comprised of the master dataset (an immutable, append-only set of raw data) and the ability to pre-compute batch views of the data that will be pushed into the serving layer
- The serving layer is comprised of pre-computed data resulting in batch views (e.g. aggregations, specific slicers, etc.) for fast queries.
- The speed layer is comprised of Spark utilizing Cosmos DB change feed to read and act on immediately. The data can also be saved to computed RT so that other systems can query the processed real-time data as opposed to running a real-time query themselves.
- The Streaming Query from Cosmos DB Change Feed scala script is to be used by spark-shell to execute a streaming query from Cosmos DB Change Feed to compute an interval count.
- The Streaming Tags Query from Cosmos DB Change Feed scala script is to be used by spark-shell to execute a streaming query from Cosmos DB Change Feed to compute an interval count by tags.
If you haven't already, download the Spark to Azure Cosmos DB connector from the azure-cosmosdb-spark GitHub repository and explore the additional resources in the repo:
- Lambda Architecture
- Distributed Aggregations Examples
- Sample Scripts and Notebooks
- Structured Streaming Demos
- Change Feed Demos
- Stream Processing Changes using Azure Cosmos DB Change Feed and Apache Spark
You might also want to review the Apache Spark SQL, DataFrames, and Datasets Guide and the Apache Spark on Azure HDInsight article.